Использование LoRa для эффективной стабильной настройки диффузии
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2023-01-26 15:08

Лора: Низкоранговая адаптация больших языковых моделей - это новый метод, внедренный исследователями Microsoft для решения проблемы тонкой настройки больших языковых моделей. Мощные модели с миллиардами параметров, такие как GPT-3, непомерно дороги для тонкой настройки, чтобы адаптировать их к конкретным задачам или областям. LoRa предлагает заморозить предварительно обученные веса модели и ввести обучаемые слои (матрицы ранговой декомпозиции) в каждый блок трансформатора. Это значительно уменьшает количество обучаемых параметров и требования к памяти графического процессора, поскольку градиенты не нужно вычислять для большинства весов модели. Исследователи обнаружили, что, сосредоточившись на блоках внимания Transformer в моделях с большим языком, качество точной настройки с помощью LoRa сравнялось с полной настройкой модели, при этом было намного быстрее и требовало меньше вычислений.
LoRa для диффузоров?
Несмотря на то, что изначально LoRa была предложена для больших языковых моделей и продемонстрирована на блоках transformer, этот метод также может быть применен в других местах. В случае точной настройки стабильной диффузии LoRa может быть применена к слоям перекрестного внимания, которые связывают представления изображений с подсказками, которые их описывают. Детали следующего рисунка (взяты из статьи о стабильной диффузии) не важны, просто обратите внимание, что желтые блоки отвечают за построение взаимосвязи между изображениями и текстовыми представлениями.
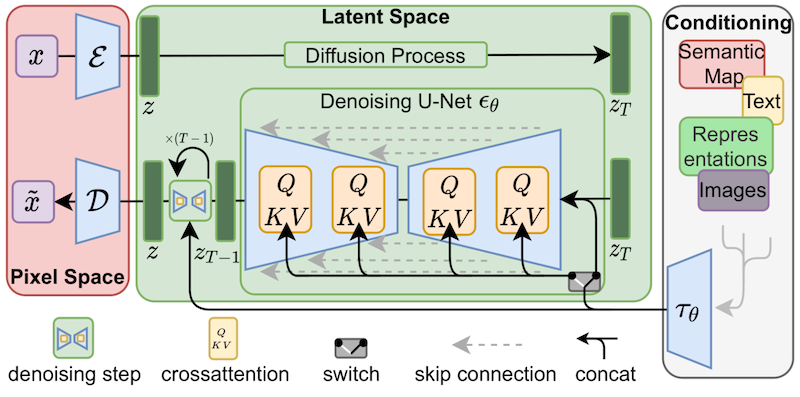
Насколько нам известно, Симо Рю (@cloneofsimo) был первым, кто предложил реализацию LoRa, адаптированную к стабильной диффузии. Пожалуйста, взгляните на их проект на GitHub, чтобы увидеть примеры и множество интересных обсуждений и идей.
Чтобы внедрить обучаемые матрицы LoRa как можно глубже в модель, так и в слои перекрестного внимания, людям раньше приходилось взламывать исходный код диффузоров оригинальными (но хрупкими) способами. Если стабильное распространение и показало нам что-то, так это то, что сообщество всегда находит способы сгибать и адаптировать модели для творческих целей, и нам это нравится! Обеспечение гибкости для манипулирования уровнями перекрестного внимания может быть полезным по многим другим причинам, таким как упрощение внедрения методов оптимизации, таких как xFormers. Другим творческим проектам, таким как Prompt-to-Prompt, не помешал бы какой-нибудь простой способ доступа к этим слоям, поэтому мы решили предоставить пользователям общий способ сделать это. Мы тестируем этот запрос на извлечение с конца декабря, и вчера он был официально запущен вместе с нашим релизом diffusers.
Мы работаем с @cloneofsimo, чтобы обеспечить поддержку обучения LoRa в диффузорах, как для Dreambooth, так и для методов полной тонкой настройки! Эти методы обеспечивают следующие преимущества:
- Обучение проходит намного быстрее, как уже обсуждалось.
- Требования к вычислениям ниже. Мы могли бы создать полностью отлаженную модель в 2080 Ti с 11 ГБ видеопамяти!
- Тренированные веса намного, намного меньше. Поскольку исходная модель заморожена и мы вводим новые слои для обучения, мы можем сохранить веса для новых слоев в виде одного файла размером ~ 3 МБ. Это примерно в тысячу раз меньше первоначального размера модели UNet!
Мы особенно взволнованы последним пунктом. Для того, чтобы пользователи могли поделиться своими потрясающими доработанными моделями или моделями мечты, они должны были поделиться полной копией окончательной модели. Другие пользователи, которые хотят опробовать их, должны загрузить точно настроенные веса в своем любимом пользовательском интерфейсе, что увеличивает совокупные затраты на хранение и загрузку. На сегодняшний день в библиотеке концепций Dreambooth зарегистрировано около 1000 моделей Dreambooth, и, вероятно, еще много не зарегистрированных в библиотеке.
С помощью LoRa теперь можно опубликовать один файл размером 3,29 МБ, чтобы другие могли использовать вашу доработанную модель.
(привет @mishig25, первому человеку, которого я услышал, использующему dreambooth как глагол в обычном разговоре).
Тонкая настройка LoRa
Полная настройка модели стабильной диффузии раньше была медленной и трудной, и это одна из причин, почему более легкие методы, такие как Dreambooth или текстовая инверсия, стали такими популярными. С LoRa гораздо проще точно настроить модель на пользовательском наборе данных.
Diffusers теперь предоставляет скрипт тонкой настройки LoRa, который может работать всего на 11 ГБ оперативной памяти графического процессора, не прибегая к таким трюкам, как 8-разрядные оптимизаторы. Вот как вы бы использовали его для точной настройки модели с помощью Lambda Labs Pok?набор данных mon:
ee to try it out yourself! Sayak did another run on a T4 (16 GB of RAM), here's his final model, and here's a demo Space that uses it.

Для получения дополнительной информации о поддержке LoRa в диффузорах, пожалуйста, обратитесь к нашей документации – она всегда будет обновляться по мере внедрения.
Вывод
Как мы уже обсуждали, одним из главных преимуществ LoRa является то, что вы получаете отличные результаты, тренируя на порядок меньшие веса, чем исходный размер модели. Мы разработали процесс вывода, который позволяет загружать дополнительные веса поверх неизмененных весов модели стабильной диффузии. Давайте посмотрим, как это работает.
Во-первых, мы будем использовать Hub API для автоматического определения базовой модели, которая использовалась для точной настройки модели aLoRA. Отталкиваясь от модели Саяки, мы можем использовать этот код:
from huggingface_hub import model_info # LoRA weights ~3 MB model_path = "sayakpaul/sd-model-finetuned-lora-t4" info = model_info(model_path) model_base = info.cardData["base_model"] print(model_base) # CompVis/stable-diffusion-v1-4 В этом фрагменте будет напечатана модель, которую он использовал для точной настройки, а именно CompVis/stable-diffusion-v1-4. В моем случае я обучал свою модель, начиная с версии 1.5 Stable Diffusion, поэтому, если вы запустите тот же код с моей моделью LoRa, вы увидите, что на выходе получается runwayml/stable-diffusion-v1-5.
Информация о базовой модели автоматически заполняется скриптом тонкой настройки, который мы видели в предыдущем разделе, если вы используете опцию --push_to_hub. Это записывается как тег метаданных в файле README репозитория модели, как вы можете видеть здесь.
После того, как мы определим базовую модель, которую мы использовали для точной настройки с помощью LoRa, мы загрузим обычный стабильный диффузионный трубопровод. Мы настроим его с помощью многошагового планировщика DPM Solver для очень быстрого вывода:
import torch from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler pipe = StableDiffusionPipeline.from_pretrained(model_base, torch_dtype=torch.float16) pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config) И вот тут-то и происходит волшебство. Мы загружаем веса LoRa из концентратора поверх обычных весов модели, перемещаем конвейер на устройство cuda и запускаем вывод:
pipe.unet.load_attn_procs(model_path) pipe.to("cuda") image = pipe("Green pokemon with menacing face", num_inference_steps=25).images[0] image.save("green_pokemon.png") Прогулка во сне с Лорой
Dreambooth позволяет вам "обучать" новым концепциям стабильную диффузионную модель. LoRa совместима с Dreambooth, и процесс похож на тонкую настройку, с несколькими преимуществами:
- Тренировка проходит быстрее.
- Нам нужно всего несколько изображений объекта, который мы хотим обучить (обычно достаточно 5 или 10).
- Мы можем настроить кодировщик текста, если захотим, для дополнительной точности отображения темы.
Чтобы обучить Dreambooth с LoRa, вам нужно использовать этот скрипт diffusers. Пожалуйста, ознакомьтесь с README, документацией и нашим сообщением в блоге hyperparameter exploration для получения подробной информации.
Другие методы
Стремление к легкой тонкой настройке не ново. В дополнение к Dreambooth, текстовая инверсия является еще одним популярным методом, который пытается обучить новым концепциям обученную модель стабильной диффузии. Одна из основных причин использования текстовой инверсии заключается в том, что обученные веса также невелики и ими легко делиться. Однако они работают только для одного объекта (или небольшой группы из них), в то время как LoRa можно использовать для тонкой настройки общего назначения, что означает, что его можно адаптировать к новым доменам или наборам данных.
Pivotal Tuning - это метод, который пытается объединить текстовую инверсию с LoRa. Сначала вы обучаете модель новой концепции, используя методы текстовой инверсии, получая новое встраивание токена для ее представления. Затем вы тренируете встраивание этого токена с помощью LoRa, чтобы получить лучшее из обоих миров.
Мы еще не изучали Pivotal Tuning с LoRa. Кто готов принять вызов?
Paper: https://arxiv.org/abs/2106.09685
Code: https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora.py
Телеграм: t.me/ainewsline
Источник: huggingface.co