От обучения к логическому выводу: создание нейронной сети для распознавания изображений
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-11-14 18:43
В то время как традиционное программное обеспечение для обработки изображений полагается на алгоритмы, зависящие от конкретной задачи, программное обеспечение для глубокого обучения использует сеть для реализации обученных пользователем алгоритмов распознавания хороших и плохих изображений или областей.
К счастью, появление специализированных алгоритмов и инструментов графического пользовательского интерфейса (GUI) для обучения нейронных сетей делает его проще, быстрее и доступнее для производителей. Чего могут ожидать производители от этих графических инструментов глубокого обучения и каково это - использовать их?
Хотите узнать больше об инструментах глубокого обучения с графическим интерфейсом для приложений vision?
Посмотрите этот вебинар или узнайте больше о программном обеспечении Teledyne DALSA Vision.
Тренинг: Создание модели глубокого обучения
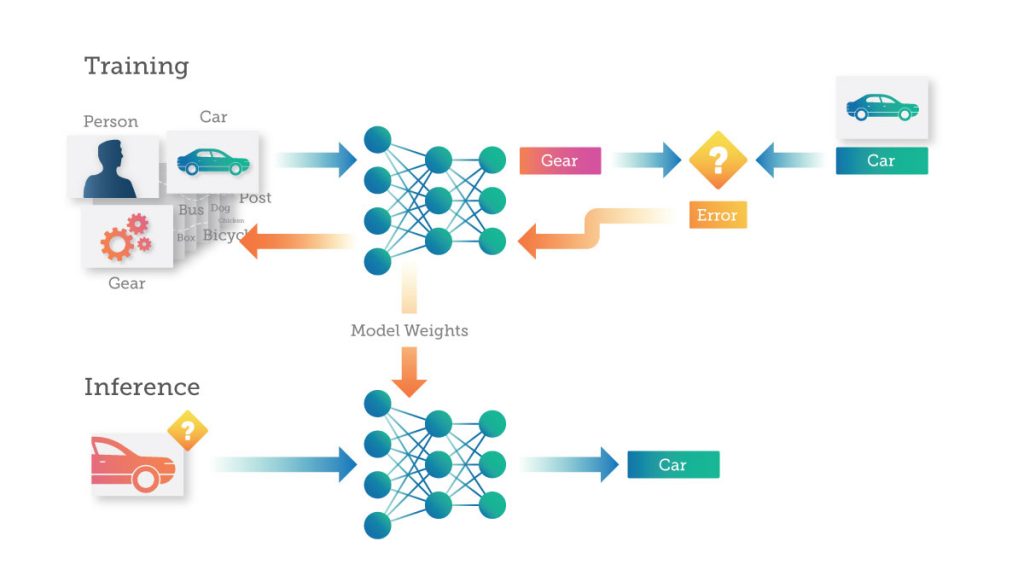
Обучение — это процесс “обучения” глубокой нейронной сети (DNN) выполнению желаемой задачи, такой как классификация изображений или преобразование речи в текст, путем подачи ей данных, на основе которых она может учиться. DNN делает прогноз о том, что представляют собой данные. Ошибки в предсказании затем передаются обратно в сеть, чтобы обновить силу связей между искусственными нейронами. Чем больше данных вы передаете DNN, тем больше он запоминает, пока DNN не начнет делать прогнозы с желаемым уровнем точности.
В качестве примера рассмотрим обучение DNN, предназначенное для идентификации изображения как одной из трех различных категорий – человека, автомобиля или механического устройства.
Как правило, специалист по обработке данных, работающий с DNN, будет иметь предварительно собранный обучающий набор данных, состоящий из тысяч изображений, каждое из которых помечено как “человек”, “автомобиль” или "снаряжение”. Это может быть готовый набор данных, такой как открытые изображения Google, который включает в себя девять миллионов изображений, почти 60 миллионов меток на уровне изображений и многое другое.

https://piratecpa.net/2022/10/nejroseti-dlya-arbitrazhnika-podborka-dlya-raboty-s-izobrazheniyami/
Способы аннотирования в Google Open Images: метки на уровне изображений, ограничительные рамки, сегментирование экземпляров и визуальные взаимосвязи.
Если приложение data scientist слишком специализировано для существующего решения, то им, возможно, потребуется создать свой собственный набор обучающих данных, собирая и маркируя изображения, которые наилучшим образом будут представлять то, что DNN необходимо изучить.
В процессе обучения, когда каждое изображение передается в DNN, DNN делает прогноз (или вывод) о том, что представляет собой изображение. Каждая ошибка передается обратно в сеть, чтобы повысить ее точность при следующем прогнозировании.
Здесь нейронная сеть предсказывает, что одно изображение “автомобиля” является ”шестеренкой". Затем эта ошибка передается обратно через DNN, и соединения в сети обновляются для исправления ошибки. В следующий раз, когда то же самое изображение будет представлено DNN, у него будет больше шансов сделать правильный прогноз.
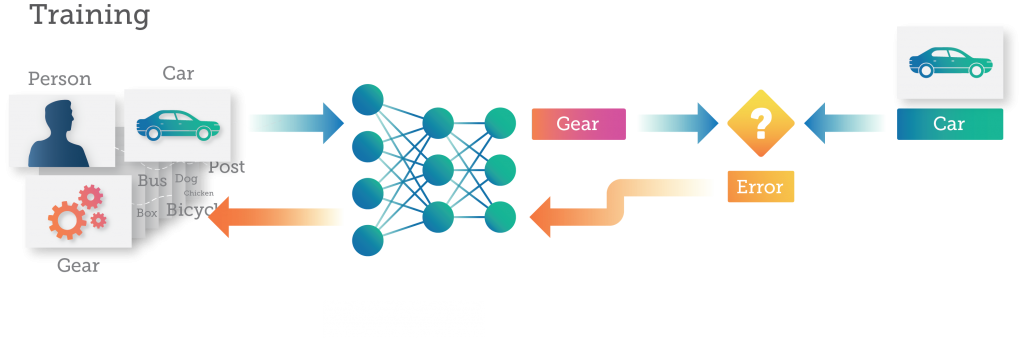
Этот процесс обучения продолжается с передачей изображений в DNN и обновлением весов для исправления ошибок, снова и снова, десятки или тысячи раз, пока DNN не сделает прогнозы с желаемой точностью. На этом этапе DNN считается “обученным”, и результирующая модель готова к использованию для классификации новых изображений.
Правильный выбор размера вашей нейронной сети
Количество входов, скрытых слоев и выходов нейронной сети сильно зависит от задачи, которую вы пытаетесь решить, и конкретного дизайна вашей нейронной сети. В процессе обучения специалист по обработке данных пытается направить модель DNN для достижения желаемой точности. Это часто требует проведения многих, возможно, сотен экспериментов, пробуя различные конструкции DNN, которые различаются по количеству нейронов и слоев.
Между входом и выходом лежат нейроны и соединения сети – скрытые слои. Для многих задач глубокого обучения достаточно 1-5 слоев нейронов, поскольку для составления прогноза оценивается лишь несколько признаков. Но с более сложными задачами, с большим количеством переменных и соображений вам нужно больше. Для работы с изображениями или речевыми данными может потребоваться нейронная сеть из десятков или сотен слоев, каждый из которых выполняет определенную функцию, и миллионы или миллиарды весов, соединяющих их.
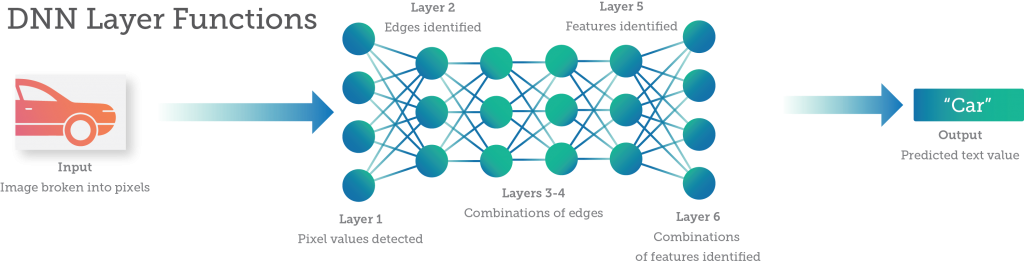
Пример упрощенного многослойного DNN с указанием типа задач, которые могут выполнять отдельные слои.
Приступаем к сбору образцов
Традиционно для обучения системы и создания модели, классифицирующей объекты с высокой степенью предсказуемости, требовались сотни или даже тысячи классифицированных вручную изображений. Но сбор и аннотирование таких сложных наборов данных оказались препятствием для разработки, препятствуя внедрению глубокого обучения в основные системы визуального контроля.
Глубокое обучение хорошо подходит для сред, в которых такие переменные, как освещение, шум, форма, цвет и текстура являются общими. Практическим примером, демонстрирующим силу глубокого обучения, является проверка царапин на текстурированных поверхностях, таких как матовый металл. Некоторые царапины менее яркие, с контрастом, близким к самому текстурированному фону. Следовательно, традиционные методы обычно не позволяют надежно обнаружить эти типы дефектов, особенно когда форма, яркость и контрастность варьируются от образца к образцу. На рисунке 1 показан контроль царапин на металлических листах. Дефекты четко отображаются с помощью изображения тепловой карты, которое выделяет пиксели в месте дефекта.

Осмотр поверхности показывает пластину из матового металла с царапинами слева, а вывод тепловой карты алгоритма классификации, который создается автоматически при обучении нейронной сети с использованием входных образцов, показывает дефекты справа. Обратите внимание, что мы добавили желтые круги, чтобы показать соответствие между необработанным изображением и тепловой картой.
Глубокая нейронная сеть, обученная с нуля, обычно требует сотен или даже тысяч образцов изображений. Однако современное программное обеспечение для глубокого обучения часто проходит предварительную подготовку, поэтому пользователям могут потребоваться всего лишь десятки дополнительных образцов, чтобы адаптировать систему к их конкретному приложению.
Напротив, приложение для проверки, созданное с использованием обычной классификации, потребовало бы сбора как “хороших”, так и “плохих” изображений для обучения. Однако с новыми алгоритмами классификации, такими как обнаружение аномалий, пользователи могут тренироваться только на хороших образцах, и для окончательного тестирования им потребуется всего несколько плохих образцов.
Хотя волшебного способа собрать образцы изображений не существует, это становится намного проще. Для сбора изображений технические специалисты могут использовать Sapera LT, бесплатный набор инструментов для сбора изображений и разработки программного обеспечения для управления (SDK) для 2D / 3D камер и захватчиков кадров Teledyne DALSA. Astrocyte, графический инструмент для обучения нейронных сетей, взаимодействует с Sapera LT, позволяя собирать изображения с камер. Пользователь, собирающий изображения компонентов печатной платы в ручном режиме, например, перемещал бы печатную плату руками, изменяя положение камеры, угол и расстояние, чтобы создать серию изображений компонентов печатной платы.
Обучение нейронной сети с помощью визуальных инструментов
Как только пользователь получит изображения, пришло время обучать нейронную сеть. Обучение выполняется в Astrocyte простым нажатием на кнопку “Тренировать”, чтобы начать процесс обучения с гиперпараметрами по умолчанию. Можно изменить гиперпараметры для достижения большей точности в конечной модели.
Чтобы проверить точность, пользователь тестирует модель с другим набором изображений и может выбрать использование диагностических инструментов, таких как матрица путаницы для модели классификации. Матрица путаницы - это таблица NxN (где N = количество классов), которая показывает показатель успешности для каждого класса. В этом примере (см. рис. 2) цветовое кодирование используется для представления точности /успешности отзыва модели, при этом зеленый цвет указывает на показатель, превышающий 90%.
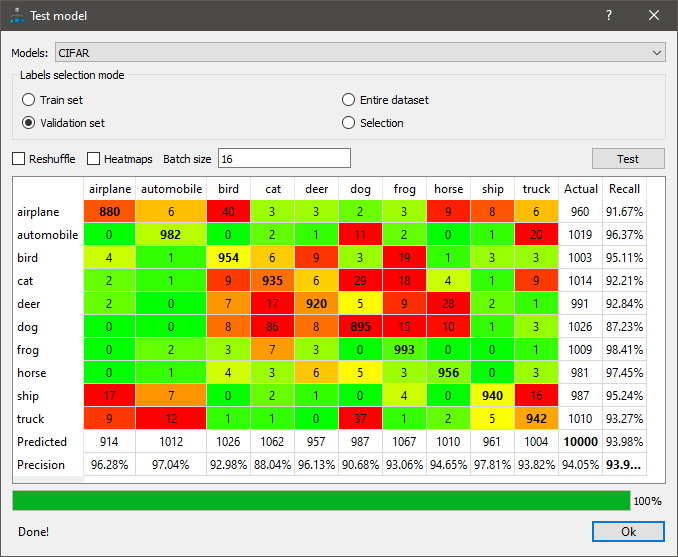
В матрице путаницы двойной щелчок по полям результатов открывает связанные изображения на вкладке изображений Астроцита для дальнейшего изучения.
Тепловые карты - еще один критически важный диагностический инструмент. Например, при обнаружении аномалий тепловая карта выделяет местоположение дефектов. Когда пользователь видит тепловую карту, он / она оценивает, является ли изображение хорошим или плохим по правильным причинам. Если изображение было хорошим, но было классифицировано как плохое, пользователь может просмотреть тепловую карту для получения более подробной информации. Нейронная сеть будет следовать тому, что пользователь предоставил в качестве входных данных.
Это использование тепловых карт в приложении для проверки винтов является хорошим примером:

Астроцит показывает окруженный дефект в правом верхнем углу через соответствующую тепловую карту. Идеальное изображение, напротив, находится в левом верхнем углу.
Тепловая карта также может показать, что модель фокусируется на детали изображения или функции, которые не имеют отношения к желаемому анализу целевой сцены или объекта на изображении. В зависимости от модуля Astrocyte доступны различные типы алгоритмов формирования тепловой карты.
Графический инструмент в действии
Лучший способ объяснить подход GUI-инструмента к глубокому обучению - это показать его. Поскольку обучение модели обнаружения аномалий является основополагающим для обучения нейронных сетей, вот краткое руководство с пошаговым подходом к использованию Astrocyte для обнаружения аномалий.
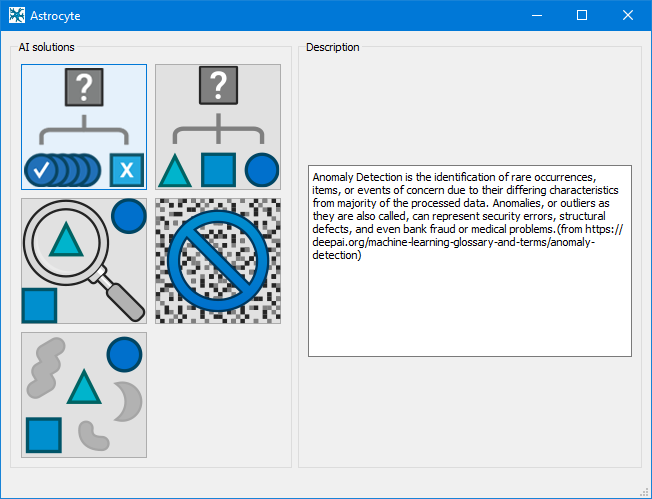
Шаг 1: Запустите приложение Astrocyte и выберите модуль обнаружения аномалий на стартовом экране.:
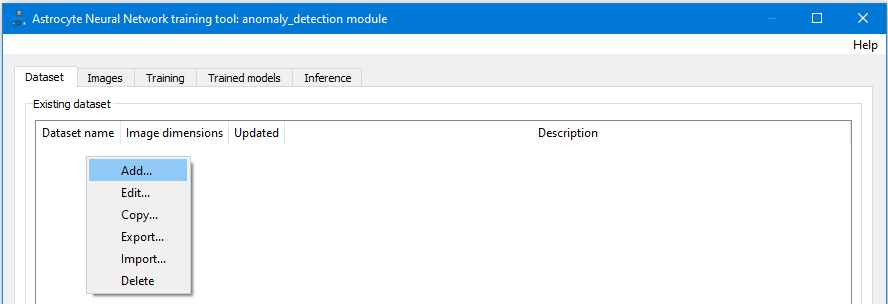
Шаг 2: На вкладке Набор данных щелкните правой кнопкой мыши и выберите Добавить набор данных.
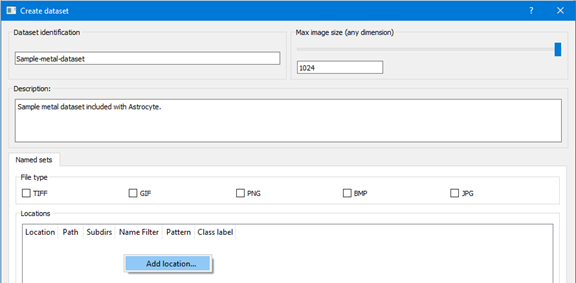
Шаг 3: Введите имя и описание набора данных, щелкните правой кнопкой мыши на панели Базы данных и выберите Добавить базу данных.
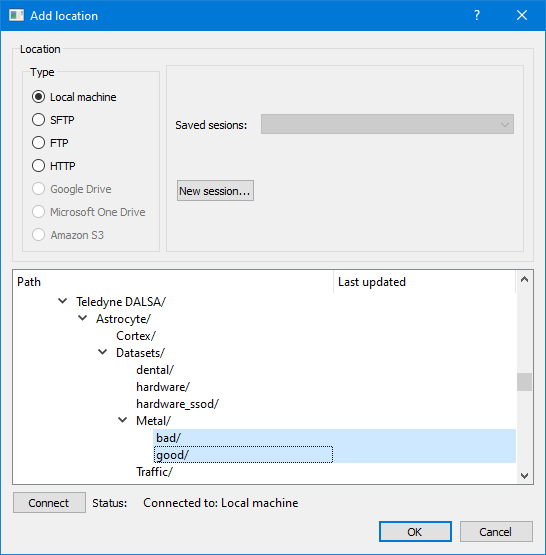
Шаг 4: В диалоговом окне "Добавить местоположение" перейдите к папке, содержащей набор обучающих изображений. Выберите как обычные (хорошие), так и аномальные (плохие) каталоги и нажмите кнопку ОК.
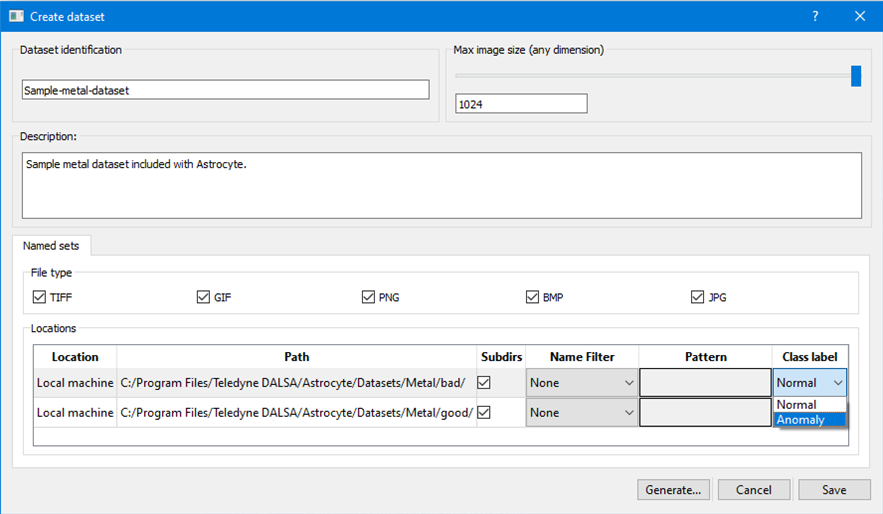
Шаг 5: Для каждого каталога назначьте метку класса, используя выпадающий список: Нормальный или аномальный. Затем нажмите кнопку Создать, чтобы добавить набор данных на внутренний сервер Astrocyte.
По завершении процесса генерации отображается диалоговое окно анализатора распределения изображений по размерам, если изображения в наборе данных имеют разные размеры; в противном случае, если все изображения имеют одинаковые размеры, они автоматически изменяются до указанного максимального размера изображения, и диалоговое окно не отображается. При необходимости исправьте изображения с помощью диалогового окна Коррекции изображений.
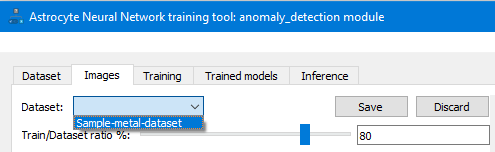
Шаг 6: На вкладке Изображения используйте раскрывающийся список Dataset, чтобы выбрать необходимый набор данных. Затем проверьте изображения и метки набора данных и внесите все необходимые изменения. Если набор данных изменен, нажмите Сохранить, чтобы обновить и сохранить набор данных на сервере Astrocyte.
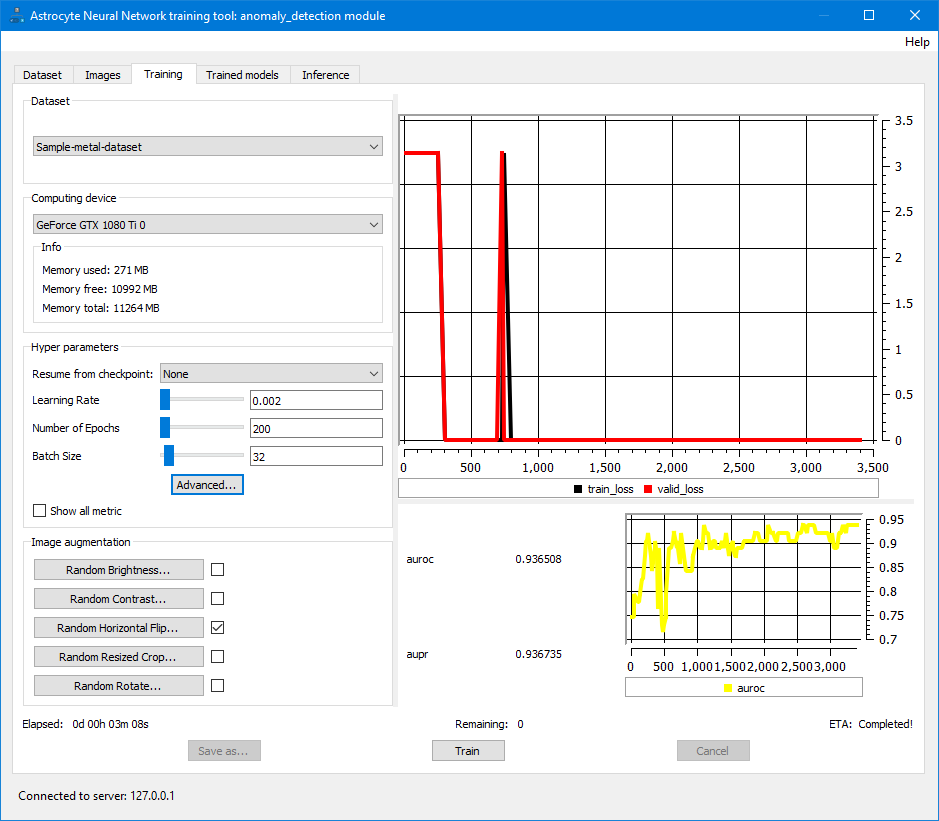
Шаг 7: На вкладке Обучение выберите набор данных и нажмите Обучить; графики потерь при обучении и показателей обновляются по завершении каждого пакета и отображается статистика обучения.

Шаг 8: Когда обучение будет завершено, появится запрос на сохранение модели, нажмите Да. Введите название модели и описание и нажмите кнопку ОК. Теперь у вас есть модель для тестирования. Astrocyte также проводит пользователя через этот процесс, используя тот же интуитивно понятный графический интерфейс.
Оптимизация для вывода: нужно ли нам совершенствовать нашего стажера?
Как только часть обучения будет завершена с приемлемой точностью, мы получим взвешенную нейронную сеть — по сути, массивную базу данных. Это то, что будет работать хорошо, но, возможно, не является оптимальным с точки зрения скорости и энергопотребления. Некоторые приложения не переносят высоких уровней задержки: подумайте об интеллектуальных транспортных системах или даже автомобилях с автономным управлением. Автономным беспилотным летательным аппаратам или другим системам, работающим на батарейках, возможно, потребуется работать в ограниченном диапазоне мощности, чтобы соответствовать требованиям времени полета.
Чем больше и сложнее DNN, тем больше вычислений, памяти и энергии расходуется как на его обучение, так и на запуск. Это может не сработать для данного вашего приложения или устройства. В таких случаях возникает желание упростить DNN после обучения, чтобы уменьшить мощность и задержку, даже если это упрощение приводит к небольшому снижению точности прогнозирования.
Такого рода оптимизация является относительно новой областью глубокого обучения. Производители чипов и ускорителей искусственного интеллекта обычно создают SDK, чтобы помочь своим пользователям выполнять такого рода задачи – с программным обеспечением, специально настроенным для их конкретной архитектуры. Используемые чипы могут варьироваться в широком диапазоне - от графических процессоров, ЦП, ПЛИС и нейронных процессоров. У каждого из них есть свои преимущества. Например, TensorRT от Nvidia подчеркивает опыт компании в области графических ядер. Vitis AI от Xilink, напротив, поддерживает SoC компании, такие как Versal, включая CPU, FPGA и нейронные процессоры.
Поставщики обычно предлагают варианты двух типов подходов: обрезка и квантование. Обрезка - это действие по удалению частей нейронной сети, которые вносят меньший вклад в конечный результат. Это уменьшает размер / сложность сети без существенного влияния на точность вывода. Второй подход заключается в квантовании – уменьшении количества битов на вес (например, замене FP32 на FP16 или квантовании INT8/4/2). При выполнении менее сложных вычислений это может увеличить скорость и / или сократить необходимые аппаратные ресурсы.
Готово к производству: переходим к выводу
Как только наша модель DNN будет обучена и оптимизирована, пришло время применить ее к работе: делать прогнозы на основе ранее невидимых данных. Это похоже на процесс обучения, когда изображения подаются в качестве входных данных, а DNN пытается их классифицировать. Астроцит.
Teledyne DALSA предлагает Sapera Processing и Sherlock, два программных пакета, которые включают набор инструментов обработки изображений и механизм вывода для запуска моделей искусственного интеллекта, построенных на
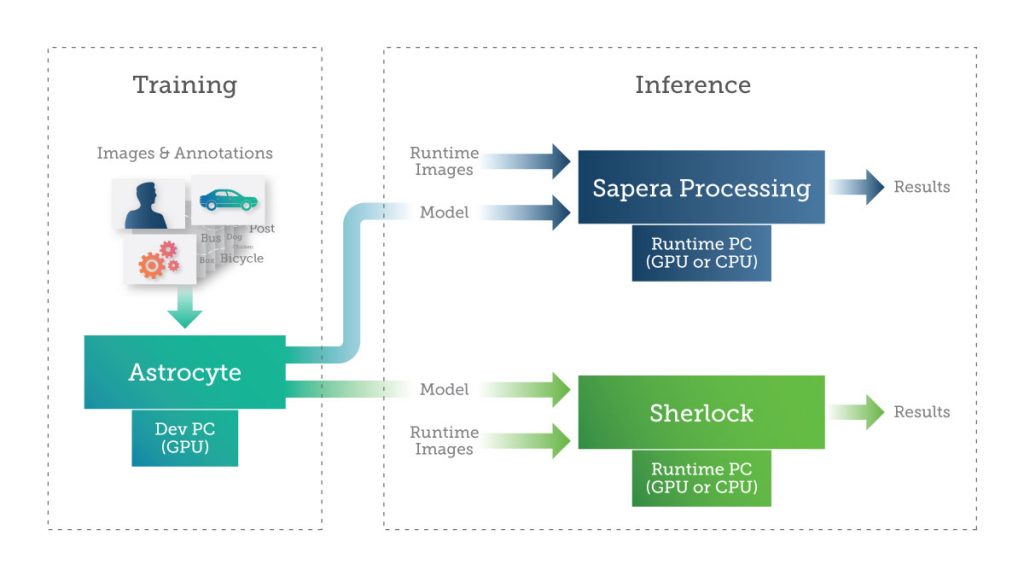
Пакеты программного обеспечения Teledyne DALSA для обучения ИИ и вывода
Пользователь может реализовать вывод на ПК с использованием графического процессора или ЦП или на встроенном устройстве. В зависимости от размера, веса и требований к мощности (SWAP) приложения пользователь может использовать различные технологии для реализации вывода глубокого обучения на встроенных устройствах, таких как графические процессоры, ПЛИС и специализированные нейронные процессоры.
Глубокое обучение: легче с каждым днем?
По своей сути нейронные сети - это сложные и мощные инструменты. Существуют практически безграничные возможности для настройки и оптимизации каждого из них, чтобы добиться наилучшей производительности для задачи, которую вы пытаетесь решить. Масштаб оптимизации и стремительный темп новых исследований и инструментов могут ошеломить даже опытных практиков.
Но это не означает, что вы не можете начать внедрять преимущества этих инструментов в свою следующую систему видения. Переход к инструментам с графическим интерфейсом демократизирует глубокое обучение в системах vision. С программным обеспечением, которое освобождает пользователей от строгих требований к обучению искусственному интеллекту и программированию, производители используют глубокое обучение для анализа изображений лучше, чем любой традиционный алгоритм. И в один прекрасный день такие инструменты с графическим интерфейсом могут превзойти любое количество инспекторов-людей.
Источник: possibility.teledyneimaging.com