Сравнение двух систем для торговли акциями: модели ближайших соседей и торговли по скользящей средней
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-10-03 20:33
Привет!
Я достаточно давно в качестве хобби занимаюсь анализом открытых данных в играх на деньги (ставки на спорт, биржевые котировки и тп). В основном работаю руками в экселе, но также стараюсь быть в курсе того, что делают машины. Для этого прошел курсы Kaggle от Google. В этой статье я попробую сравнить результативность предсказаний дневного движения цены акции от двух примитивных систем торговли:
1. примитивного трейдера-человека, который на вводном курсе по трейдингу узнал про скользящую среднюю,
и
2. примитивной модели, обученной по методу ближайших соседей (Класс KNeighborsClassifier в библиотеке Python Scikit-learn).
Оцениваться предсказания обеих систем будут по двум параметрам:
-
Результат торговли акцией в процентах.
-
Процент верных предсказаний.
Мне показалось, что будут интереснее писать данную статью последовательно, поэтому на момент написания этих слов я не знаю итоговых результатов.
Кратко о скользящей средней
Скользящая средняя (moving average) в различных руководствах по трейдингу и в базовых настройках программ для анализа имеет период [число Фибоначчи >=8 + 1], т.е. 9, 14, 22 и т.п. Я на текущей стадии развития не могу объяснить, почему именно такие периоды, честно потратил 5 минут, чтобы найти ответ в Интернете, но не смог.
Период – это интересующий нас временной диапазон (месяц, неделя, день, час, 15 минут, 5 минут, 1 минута). Для построения скользящей средней используют различные типы цен за предыдущие периоды: просто Close (цена акции в конце интересующего нас периода) или различные комбинации Open (цена в начале периода), Close, Hi (максимальная цена), Low (минимальная цена) типа ["Open + Hi + Low + 2*Close" / 5]. /
По видам скользящие средние делятся на простые (simple moving average, далее - SMA), и экспоненциальные (exponential moving average, далее EMA). SMA рассчитываются по методу среднего арифметического, у EMA чем новее данные, тем больший вес им присваивается.
Если цена над скользящей средней, то считается, что скорее она будет расти дальше, если под скользящей средней - продолжать падать.
Я планирую рассмотреть максимально примитивную скользящую среднюю, поэтому трейдер-человек будет использовать простую скользящую среднюю SMA, построенную по ценам Close за период 9 дней.
Кратко о методе ближайших соседей
Метод ближайших соседей - это один из самых простых алгоритмов классификации, но в то же время один из самых логически объяснимых и, с моей точки зрения, сильных алгоритмов. В основном он используется для решения задач классификации. Метод находит в тестовой выборке, в которой для объектов уже определены классы, объекты, расстояние до которых минимально (то есть находит максимально похожие объекты), далее эти объекты называются "соседи". Затем метод присваивает классифицируемому объекту класс, который чаще встречается у отобранных соседей.
Мышление человека в повторяющихся ситуациях абсолютно такое же: я иду без головного убора – пошел дождь – в прошлом было 4 опыта, когда я шел без головного убора и пошел дождь, из них я 3 раза промок (негативный опыт) и 1 раз дождь быстро кончился. Вывод: дождь ведет к негативным последствиям.
Подготовка исходных данных человека-трейдера
На сайте одного российского информационного агентства можно быстро получить историю котировок любых акций в формате .csv. Файл содержит следующие столбцы: <TICKER> - название акции, <PER> - период , <DATE> - дата, <TIME> - время, <OPEN> - цена открытия, <HIGH> - максимальная цена, <LOW> - минимальная цена, <CLOSE> - цена закрытия, <AMOUNT> - сумма торгов, <VOL> - объем торгов. Для примера, ниже строка файла .csv для дневных котировок акций Газпрома за дату 05.01.2015г.:
[ГАЗПРОМ ао,D,20150105,000000,129.5,133.95,129.15,133.95,18223370,2410730975.5]
Акции Газпрома (тикер GAZP) – наиболее ликвидные акции из торгуемых на Московской бирже. Долгое время эти акции имели наибольший вес в индексе iMOEX (топ-40 российских акций). Поэтому обе системы будут делать предсказания цены акции Газпрома в период с 03.01.2017г. по 30.12.2021г.
Для этого дата-фрейм трейдера-человека будет содержать котировки в период с 20.12.2016г., чтобы иметь данные для построения скользящей средней на 03.01.2017г. Модель же будет обучаться до 30.12.2016г., поэтому дата-фрейм модели будет содержать котировки в период с 19.01.2015г по 30.12.2021г.
Дата-фрейм трейдера-человека (human_df) будет содержать следующие столбцы:
<DATE> - дата
<OPEN> - цена открытия
<CLOSE> - цена закрытия
<SMA9> - значение скользящей средней SMA9
<RESULT> - результат дня по формуле [(<CLOSE> - <OPEN>) / <OPEN>]
Создаю дата-фрейм трейдера-человека (human_df):
#импортирую необходимые библиотеки import pandas as pd import numpy as np #создаю дата-фрейм с котировками в период с 05.01.2015г по 30.12.2021г. #из предварительно загруженного файла .csv df = pd.read_csv('…csv_filesGAZP_150105_213012.csv') #вывожу на экран первую строку дата-фрейма df print(df.iloc[0])Hidden text
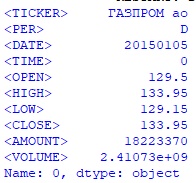
#из полученного дата-фрейма df создаю дата-фрейм date_open_close_df со столбцами <DATE>, #<OPEN>, <CLOSE> в период дат с 20.12.2016г. по 30.12.2021г date_open_close_df = df.iloc[493:,[2,4,7]] #вывожу на экран первые 5 строк дата-фрейма date_open_close_df print(date_open_close_df.head()) Hidden text
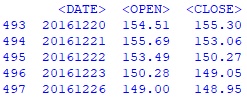
#каждый столбец дата-фрейма date_open_close_df перевожу в массив numpy для #последующей обработки date_arr = date_open_close_df.iloc[:,0].to_numpy() open_arr = date_open_close_df.iloc[:,1].to_numpy() close_arr = date_open_close_df.iloc[:,2].to_numpy() #создаю массив с результатом каждого дня по формуле [(close - open) / open] res_arr = (close_arr - open_arr) / open_arr #с 10-й строки считаю значение скользящей средней за 9 дней SMA9 sma9_arr = [np.mean(close_arr[i-9:i]) for i in range(9,len(close_arr))] #объединяю по столбцам полученные массивы в один для последующего создания итогового #дата-фрейма, при этом начало каждого с 10-й строки, с которой начинается #расчет SMA9 arr_to_df = np.column_stack([date_arr[9:], open_arr[9:], close_arr[9:], sma9_arr, res_arr[9:]]) #создаю дата-фрейм человека-трейдера human_df human_df = pd.DataFrame(data = arr_to_df, columns = ['Date', 'Open', 'Close', 'SMA9', 'Result']) #вывожу на экран первые 5 строк дата-фрейма human_df print(human_df.head()) Hidden text
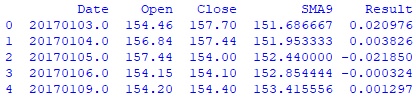
#Записываю полученный дата-фрейм человека-трейдера в файл gazp_human_df.csv human_df.to_csv(…data-framegazp_human_df.csv')Расчет результата торговли человека-трейдера
В новом окне импортирую необходимые библиотеки и загружаю дата-фрейм трейдера-человека
import pandas as pd pd.plotting.register_matplotlib_converters() import matplotlib.pyplot as plt import seaborn as sns import numpy as np human_df = pd.read_csv('...data-framegazp_human_df.csv', index_col = 0)Система торговли трейдера-человека следующая:
Каждый день в момент открытия торгов сравниваются значения Open и SMA9. Если Open > SMA9, т.е. цена находится над скользящей средней, акция покупается, если Open <= SMA9, акция продается. Каждая сделка закрывается в момент закрытия торгов и фиксируется результат. Таким образом, ГЭП-ы (разрывы), когда значение Open следующего дня отличается от значения Сlose предыдущего дня, не учитываются. Один день – одна сделка.
#создаю функцию для определения прогноза человека-трейдера def create_human_predict(row): if row.Open >= row.SMA9: row.human_predict = 1 else: row.human_predict = 0 return row.human_predict #создаю серию с прогнозами человека-трейдера human_predict = human_df.apply(create_human_predict, axis='columns') #добавляю в дата-фрейм human_df полученную серию human_df = pd.concat([human_df, human_predict], axis = 1) human_df.columns.values[5]='Predict' #вывожу первые 5 строк полученного дата-фрейма print(human_df.head())Hidden text
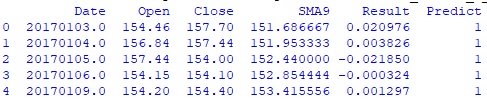
Все корректно, для всех 5-и строк Open больше, чем SMA9, поэтому значение столбца Predict ‘1’.
#создаю функцию для определения результата прогноза человека-трейдера в процентах def create_human_result_perc(row): return row.Result * 100 if row.Predict == 1 else - row.Result * 100 #создаю серию с результатами прогнозов человека-трейдера в процентах human_result_perc = human_df.apply(create_human_result_perc, axis='columns') #создаю функцию для определения результата прогноза человека-трейдера в булевом #множестве, где 0 - прогноз неверен, 1 - прогноз верен def create_human_result_bool(row): return 1 if row.Result >= 0 and row.Predict == 1 or row.Result < 0 and row.Predict == 0 else 0 #создаю серию с результатами прогнозов человека-трейдера в булевом множестве human_result_bool = human_df.apply(create_human_result_bool, axis='columns') #создаю новый дата-фрейм human_result_frame с результатами прогнозов человека-трейдера human_result_frame = pd.DataFrame({'Human_result_perc' : human_result_perc, 'Human_result_bool' : human_result_bool}) print(human_result_frame.head())Hidden text
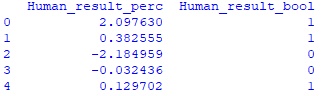
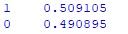
#вывожу процент верных прогнозов человека-трейдера print(human_result_frame.Human_result_bool.value_counts('1'))Hidden text
#создаю серию с кумулятивной суммой human_result_perc human_result_cumsum = human_result_frame.Human_result_perc.cumsum() print(human_result_cumsum)Hidden text
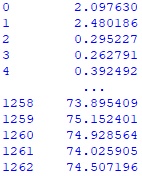
#добавляю в дата-фрейм human_df новый дата-фрейм human_result_frame human_df = pd.concat([human_df, human_result_frame], axis = 1) #добавляю в дата-фрейм human_df серию с кумулятивной суммой human_result_perc human_df = pd.concat([human_df, human_result_cumsum], axis = 1) human_df.columns.values[8]='CumSum' #вывожу первые 5 строк полученного дата-фрейма print(human_df.head())Hidden text

#Для визуализации строю график торговли трейдера-человека: #устанавливаю ширину и высоту графика plt.figure(figsize=(10,6)) # Заголовок plt.title("Результат торговли трейдера-человека") # строю линейный график sns.lineplot(data=human_df['CumSum']) plt.show()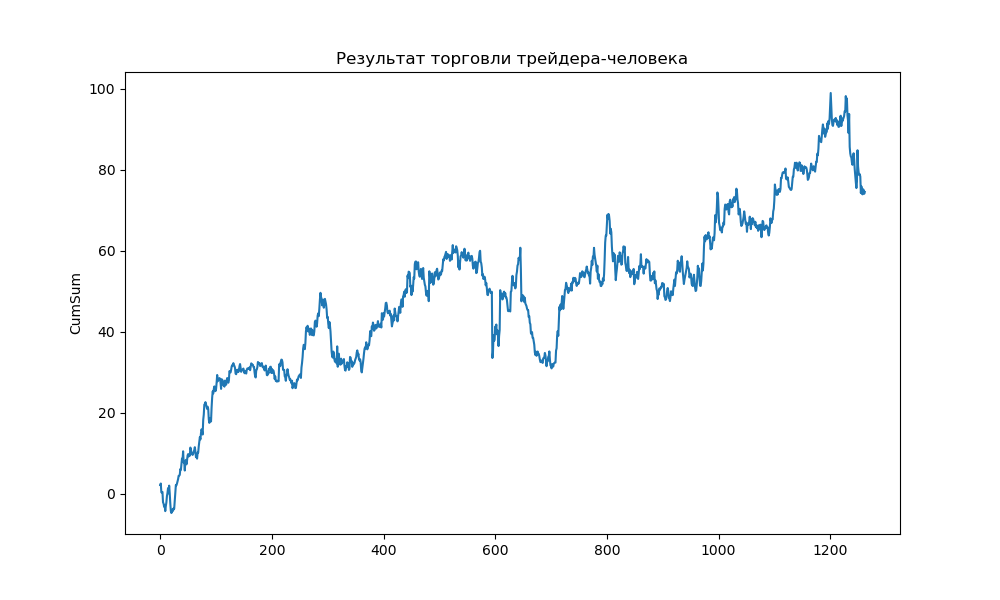
Ниже результат торговли человека – трейдера:
Процент успешных прогнозов в %: 50,9%
Результат торговли: +74,51%
Т.е. за 5 лет с 2017 по 2021 год такая система торговли принесла почти 75%. Хороший результат с учетом средней ставки рефинансирования ЦБ РФ в районе 6% за этот период? Конечно нет, потому что я не учитывал комиссию брокера за 1263 сделки. Точнее, комиссия взимается два раза за сделку: первый раз при открытии сделки во время начала торгов на бирже, второй раз при закрытии сделки в конце торгов на бирже. Размер комиссии у моего брокера - 0.039% от объема сделки при объеме сделок от 100т.р. до 1млн рублей.
Для уточнения результата системы возвращаюсь назад.
#изменяю функцию для определения результата прогноза человека-трейдера в процентах с учетом комиссии брокера def create_human_result_perc(row): return (row.Result - 0.00039 * 2) * 100 if row.Predict == 1 else (- row.Result - 0.00039 * 2) * 100Запускаю код еще раз и получаю новую серию CumSum
Hidden text
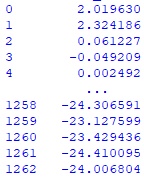
# Изменяю заголовок графика plt.title("Результат торговли трейдера-человека с комиссией брокера")Новый график:
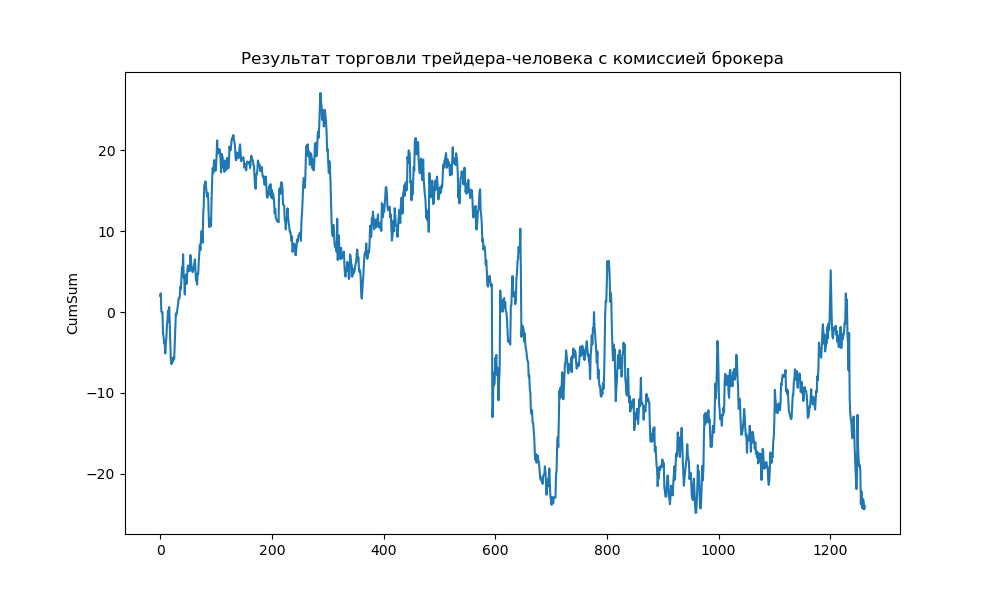
Ниже результат торговли человека – трейдера с комиссией брокера:
Процент успешных прогнозов: 50,9%
Результат торговли в %: -24,01%
Для дотошных читателей могу добавить, что в этой статье я не учитываю разницу между ценами покупки и продажи (Bid и Ask), потому что, во-первых, не смог придумать, как учитывать эти плавающие величины, а во-вторых понятие «котировки» вообще довольно-таки скользкое: в архиве котировок фиксируется лучшая цена покупки / продажи, но вполне может быть, что по этой цене получится купить только небольшую часть акций, а остальную часть акций по более невыгодной цене.
Подготовка исходных данных модели, обученной по методу ближайших соседей
Будет справедливо, если модель получит на вход те же данные, которыми располагает человек-трейдер: цены открытия и закрытия последних 9-и дней и SMA9.
При этом метод ближайших соседей – это категориальный метод, поэтому я сильно сомневаюсь, что данные на вход числовые значения цены акции смогут сильно помочь обучению модели. Если в дата-фрейме будут значения Open и Close типа 129.5 и 133.95 (для 05.01.2015) модель будет искать ближайших соседей не в зависимости от результата дня (Close - Open), а среди дней, когда цена акции была подобной. Поэтому я создам дата-фрейм со следующими столбцами:
Date – дата
Res_9_day – результат [(Close – Open) / Open] для даты 9 дней назад
Res_8_day – результат [(Close – Open) / Open] для даты 8 дней назад
…
Res_1_day – результат [(Close – Open) / Open] для даты 1 день назад
Open - SMA9 – результат [(Open – SMA9) / Open]
Result – результат дня [(Close – Open) / Open]
В новом окне:
#импортирую необходимые библиотеки import pandas as pd import numpy as np #создаю дата-фрейм с котировками в период с 05.01.2015г по 30.12.2021г. #из предварительно загруженного файла df = pd.read_csv('...csv_filesGAZP_150105_213012.csv') #из полученного дата-фрейма создаю дата-фрейм со столбцами <DATE>, <OPEN>, #<CLOSE> в период дат с 05.01.2015г. по 30.12.2021г date_open_close_df = df.iloc[:,[2,4,7]] #каждый столбец дата-фрейма date_open_close_df перевожу в массив numpy для #последующей обработки date_arr = date_open_close_df.iloc[:,0].to_numpy() open_arr = date_open_close_df.iloc[:,1].to_numpy() close_arr = date_open_close_df.iloc[:,2].to_numpy() #создаю массив с результатом каждого дня по формуле [(close - open) / open] res_arr = (close_arr - open_arr) / open_arr #с 10-й строки считаю значение скользящей средней за 9 дней SMA9 sma9_arr = [np.mean(close_arr[i-9:i]) for i in range(9,len(close_arr))] #с 10-й строки считаю значение разницы Open и SMA open10_arr = open_arr[9:] open_sma_arr = (open10_arr - sma9_arr) / open10_arr #создаю итоговый массив с интересующими меня данными для последующего создания #дата-фрейма, при этом начало каждого столбца с 10-й строки, с которой #начинается расчет SMA9 arr_to_df = np.column_stack([date_arr[9:], res_arr[:-9], res_arr[1:-8], res_arr[2:-7], res_arr[3:-6], res_arr[4:-5], res_arr[5:-4], res_arr[6:-3], res_arr[7:-2], res_arr[8:-1], open_sma_arr, res_arr[9:]]) #создаю дата-фрейм модели machine_df machine_df = pd.DataFrame(data = arr_to_df, columns = ['Date', 'Res_9_day', 'Res_8_day', 'Res_7_day', 'Res_6_day', 'Res_5_day', 'Res_4_day', 'Res_3_day', 'Res_2_day', 'Res_1_day', 'Open-SMA9', 'Result']) print(machine_df.head())Hidden text

#записываю полученный дата-фрейм человека-трейдера в файл gazp_machine_df.csv machine_df.to_csv('...data-framegazp_machine_df.csv')Расчет результата модели
#импортирую необходимые библиотеки from sklearn.model_selection import train_test_split, StratifiedKFold from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score import pandas as pd pd.plotting.register_matplotlib_converters() import matplotlib.pyplot as plt import seaborn as sns import numpy as np #Загружаю дата-фрейм модели machine_df = pd.read_csv('...data-framegazp_machine_df.csv', index_col = 0) print(machine_df.head()) print(machine_df.shape)Hidden text
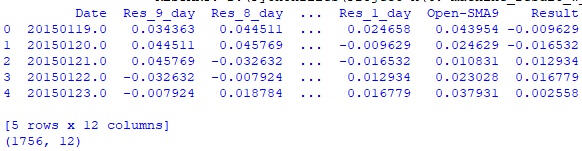
Модель ближайших соседей прогнозирует класс, поэтому создаю столбец с результатом дня в булевом множестве, где 0 - результат дня < 0, 1 - результат дня >= 0
#создаю функцию для определения результата дня в булевом множестве def create_result_bool(row): return 1 if row.Result >= 0 else 0 #создаю серию с результатами дня в булевом множестве result_bool = machine_df.apply(create_result_bool, axis='columns') #добавляю в дата-фрейм machine_df полученную серию machine_df = pd.concat([machine_df, result_bool], axis = 1) machine_df.columns.values[12]='Result_bool' #в дата-фрейме 1756 строк. Я разделю его на два дата-фрейма: #machine_df_train (493 строки, с 19.01.2015 по 30.12.2016) и #machine_df_test (1263 строки с 03.01.2017 по 30.12.2021). machine_df_train = machine_df.iloc[:493] machine_df_test = machine_df.iloc[493:] # Определяю цель и отделяю цель от предикторов, также убираю столбец Date, т.к. #он никак не поможет модели y = machine_df_train.Result_bool X = machine_df_train.drop(['Date','Result', 'Result_bool'], axis=1) # Делю данные для построения модели и проверки X и y X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3, random_state=42, shuffle = False ) #вывожу на экран первые 5 строк данных x_train #print(X_train.head()) #Обучу модель по методу ближайших соседей, число соседей возьму 9 knn = KNeighborsClassifier(n_neighbors=9) knn.fit(X_train, y_train) #выполню проверку по доле правильных ответов knn_pred = knn.predict(X_valid) print(accuracy_score(y_valid, knn_pred)) Hidden text
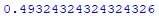
#Получил результат 49,3% верных прогнозов, не впечатляет. Но все же попробую на #тестовом дата-фрейме y = machine_df_test.Result_bool X = machine_df_test.drop(['Date','Result', 'Result_bool'], axis=1) knn_pred_test = knn.predict(X) print(accuracy_score(y, knn_pred_test))Hidden text
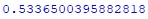
#На тестовом дата-фрейме получил результат целых 53,4% верных прогнозов! #Теперь считаю результат торговли модели #создаю дата-фрейм machine_predict_df с прогнозами модели machine_predict_df = pd.DataFrame({'machine_predict' : knn_pred_test}) print(machine_df_test.head()) print(machine_predict_df.head())Hidden text
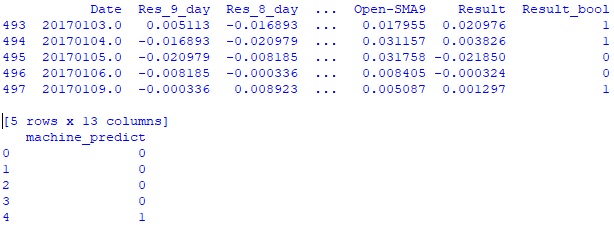
# чтобы объединить дата-фреймы machine_predict_df и machine_df_test нужно #уравнять их индексы index_list = machine_df_test.index.tolist() machine_predict_df.index = index_list machine_df_test = pd.concat([machine_df_test, machine_predict_df], axis = 1) print(machine_df_test.head())Hidden text

#создаю функцию для определения результата прогноза модели в процентах с учетом комиссии брокера def create_machine_result_perc(row): return (abs(row.Result)-0.00039*2)*100 if row.Result_bool==row.machine_predict else (-abs(row.Result)-0.00039*2)*100 #создаю серию с результатами прогнозов модели в процентах machine_result_perc = machine_df_test.apply(create_machine_result_perc, axis='columns') #создаю серию с кумулятивной суммой human_result_perc machine_result_cumsum = machine_result_perc.cumsum() print(machine_result_cumsum)Hidden text
#Для визуализации строю график торговли модели: #устанавливаю ширину и высоту графика plt.figure(figsize=(10,6)) # Создаю заголовок графика plt.title("Результат торговли модели с комиссией брокера") # строю линейный график sns.lineplot(data=machine_result_cumsum) plt.show()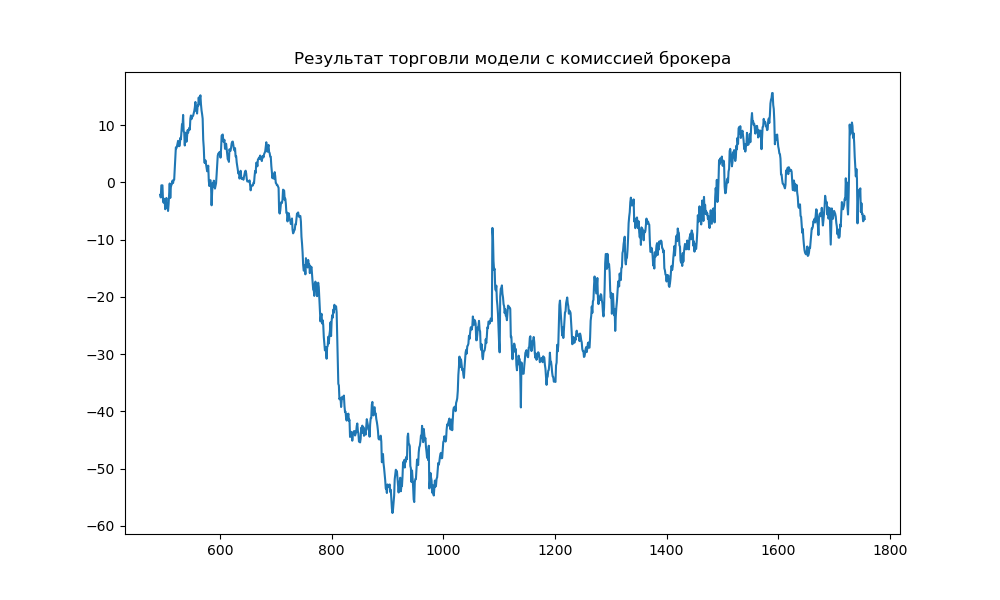
Результат -6,4% не впечатляет, но он лучше результата прогнозов
по скользящей средней. Может быть изменение размера тестовой выборки и количества
соседей приведет к существенному улучшению?
Для проверки оберну последние строки кода в функцию в новом окне
#импортирую необходимые библиотеки from sklearn.model_selection import train_test_split, StratifiedKFold from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score import pandas as pd #Загружаю дата-фрейм модели machine_df = pd.read_csv('...data-framegazp_machine_df.csv', index_col = 0) #создаю функцию для определения результата дня в булевом множестве def create_result_bool(row): return 1 if row.Result >= 0 else 0 #создаю серию с результатами дня в булевом множестве result_bool = machine_df.apply(create_result_bool, axis='columns') #добавляю в дата-фрейм machine_df полученную серию machine_df = pd.concat([machine_df, result_bool], axis = 1) machine_df.columns.values[12]='Result_bool' #в дата-фрейме 1756 строк. Я разделю его на два дата-фрейма: #machine_df_train (493 строки, с 19.01.2015 по 30.12.2016) и #machine_df_test (1263 строки с 03.01.2017 по 30.12.2021). machine_df_train = machine_df.iloc[:493] machine_df_test = machine_df.iloc[493:] #print(machine_df_test.head()) # Определяю цель и отделяю цель от предикторов, также убираю столбец Date, т.к. #он никак не поможет модели y = machine_df_train.Result_bool X = machine_df_train.drop(['Date','Result', 'Result_bool'], axis=1) #создаю функцию для определения результата прогноза модели в процентах с учетом комиссии брокера def create_machine_result_perc(row): return (abs(row.Result) - 0.00039 * 2) * 100 if row.Result_bool == row.machine_predict else (- abs(row.Result) - 0.00039 * 2) * 100 #Создаю функцию для проверки параметров модели def machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test): # Делю данные для построения модели и проверки X и y X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=test_size, random_state=42, shuffle = False ) knn = KNeighborsClassifier(n_neighbors=n_neighbors) knn.fit(X_train, y_train) knn_pred = knn.predict(X_valid) y = machine_df_test.Result_bool X = machine_df_test.drop(['Date','Result', 'Result_bool'], axis=1) knn_pred_test = knn.predict(X) machine_predict_df = pd.DataFrame({'machine_predict' : knn_pred_test}) index_list = machine_df_test.index.tolist() machine_predict_df.index = index_list machine_df_test = pd.concat([machine_df_test, machine_predict_df], axis = 1) machine_result_perc = machine_df_test.apply(create_machine_result_perc, axis='columns') return [test_size, n_neighbors, accuracy_score(y_valid, knn_pred), accuracy_score(y, knn_pred_test), machine_result_perc.sum()] test_size_list = [] n_neighbors_list = [] accuracy_valid_list = [] accuracy_test_list = [] cumsum_list = [] #для поиска наилучшей комбинации набора параметров создам дата-фрейм с результатами #модели для размера тестовой выборки test_size [0.2,0.3,0.4,0.5] и # числа соседей от 1 до 13 включительно for test_size in [0.2,0.3,0.4,0.5]: for n_neighbors in range(1,14): res = machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test) test_size_list.append(res[0]) n_neighbors_list.append(res[1]) accuracy_valid_list.append(res[2]) accuracy_test_list.append(res[3]) cumsum_list.append(res[4]) #Для оценки результатов создаю дата-фрейм parameter_df d = {'test_size': test_size_list, 'n_neighbors': n_neighbors_list, 'accuracy_valid' : accuracy_valid_list, 'accuracy_test' : accuracy_test_list, 'cumsum' : cumsum_list} parameter_df = pd.DataFrame(data=d) print(parameter_df)Hidden text
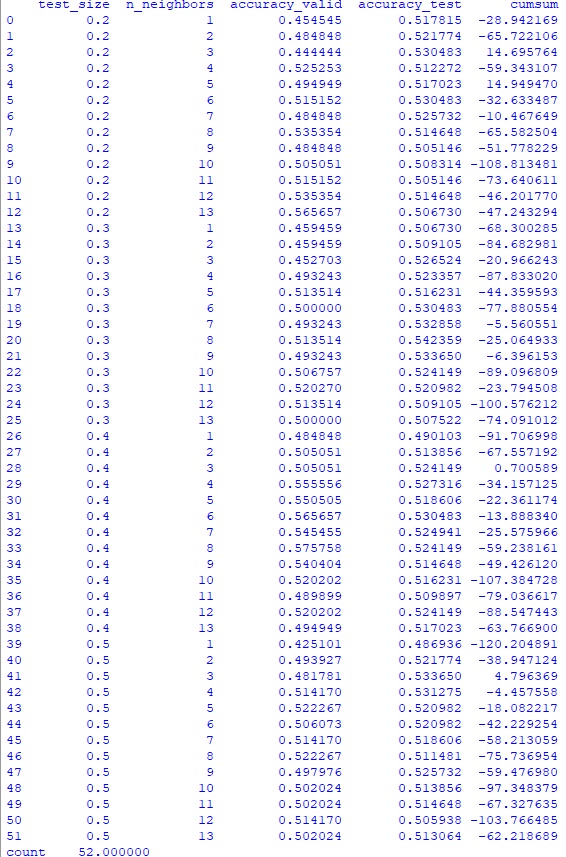
Полученный огромный разброс результатов дал лучшее значение +14,95% и худшее -120,2%.
Среднее значение результата модели -52,2%, что хуже системы игры по скользящей средней. Смотрю, как дела с процентом верных прогнозов:
print(parameter_df.accuracy_test.describe())Hidden text
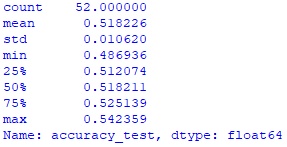
Среднее значение 51,8% верных прогнозов, это лучше, чем у системы игры по скользящей средней.
accuracy_test_rating_size = parameter_df.groupby('test_size').accuracy_test.mean() print(accuracy_test_rating_size)Hidden text

accuracy_test_rating_neig = parameter_df.groupby('n_neighbors').accuracy_test.mean() print(accuracy_test_rating_neig)Hidden text
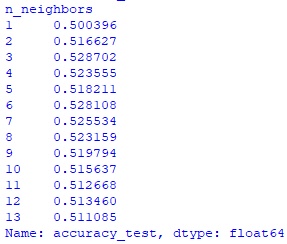
Лучший результат при значениях test_size = 0,3 и числе соседей n_neighbors = 3. Но с этими параметрами результат торговли системы -20,97%. Можно ли доверять такой модели? Сомневаюсь.
Сделаю пару попыток улучшить модель.
Улучшение модели путем стандартизации исходных данных
Возвращаюсь к подготовке исходных данных модели в новом окне
#импортирую необходимые библиотеки import pandas as pd import numpy as np #создаю дата-фрейм с котировками в период с 05.01.2015г по 30.12.2021г. #из предварительно загруженного файла df = pd.read_csv('...csv_filesGAZP_150105_213012.csv') #из полученного дата-фрейма создаю дата-фрейм со столбцами <DATE>, <OPEN>, #<CLOSE> в период дат с 05.01.2015г. по 30.12.2021г date_open_close_df = df.iloc[:,[2,4,7]] print(date_open_close_df.head()) #каждый столбец дата-фрейма date_open_close_df перевожу в массив numpy для #последующей обработки date_arr = date_open_close_df.iloc[:,0].to_numpy() open_arr = date_open_close_df.iloc[:,1].to_numpy() close_arr = date_open_close_df.iloc[:,2].to_numpy() #создаю массив с результатом каждого дня по формуле [(close - open) / open] res_arr = (close_arr - open_arr) / open_arr #с 10-й строки считаю значение скользящей средней за 9 дней SMA9 sma9_arr = [np.mean(close_arr[i-9:i]) for i in range(9,len(close_arr))] open10_arr = open_arr[9:] open_sma_arr = (open10_arr - sma9_arr) / open10_arr #создаю итоговый массив с интересующими меня данными для последующего создания #дата-фрейма, при этом начало каждого столбца с 10-й строки, с которой #начинается расчет SMA9 #Нормализую полученные значения массивов res_arr и open_sma_arr до 5-и различных значений. #Эта операция существенно уменьшит разброс в столбцах и, на мой взгляд, облегчит работу #модели. Сначала получу информацию о разбросе значений массивов arr_to_describe = np.column_stack([res_arr[9:], open_sma_arr]) df_describe = pd.DataFrame(data = arr_to_describe, columns = ['Result', 'Open-SMA9']) print(df_describe.describe())Hidden text
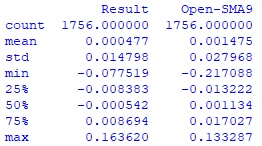
После изучения вывода определяю границы для стандартизации:
Для res_arr
0 - если значение > -0.008 и < 0.008
0.01 >=0.008 < 0.016
0.02 >=0.016
-0.01 <=-0.008 >-0.016
-0.02 <=-0.016
Для open_sma_arr
0 - если значение > -0.015 и < 0.015
0.01 >=0.015 < 0.03
0.02 >=0.03
-0.01 <=-0.015 >-0.03
-0.02 <=-0.03
#Создаю функцию для нормализации массивов def standart_arr(arr, min2, min1, max2, max1): arr = np.where((arr > min1) & (arr < max1), 0, arr) arr = np.where(arr >= max2, 0.02, arr) arr = np.where((arr >= max1) & (arr < max2), 0.01, arr) arr = np.where(arr <= min2, -0.02, arr) arr = np.where((arr > min2) & (arr <= min1), -0.01, arr) return arr #что-то мне подсказывает, что код функции можно написать гораздо более рационально. #Если кто-то подскажет в комментариях как, буду признателен res_arr_std = standart_arr(res_arr, -0.016, -0.008, 0.016, 0.008) open_sma_arr_std = standart_arr(open_sma_arr, -0.03, -0.015, 0.03, 0.015) print('res_arr_std',res_arr_std) print('open_sma_arr_std',open_sma_arr_std)
#создаю дата-фрейм модели machine_df_mod arr_to_df = np.column_stack([date_arr[9:], res_arr_std[:-9], res_arr_std[1:-8], res_arr_std[2:-7], res_arr_std[3:-6], res_arr_std[4:-5], res_arr_std[5:-4], res_arr_std[6:-3], res_arr_std[7:-2], res_arr_std[8:-1], open_sma_arr_std, res_arr[9:]]) machine_df_mod = pd.DataFrame(data = arr_to_df, columns = ['Date', 'Res_9_day', 'Res_8_day', 'Res_7_day', 'Res_6_day', 'Res_5_day', 'Res_4_day', 'Res_3_day', 'Res_2_day', 'Res_1_day', 'Open-SMA9', 'Result']) print(machine_df_mod.head())Hidden text

#записываю полученный дата-фрейм человека-трейдера в файл gazp_machine_df_mod.csv machine_df_mod.to_csv('...data-framegazp_machine_df_mod.csv')Теперь возвращаюсь к модели с новым дата-фреймом machine_df_mod в новом окне
#импортирую необходимые библиотеки from sklearn.model_selection import train_test_split, StratifiedKFold from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score import pandas as pd #Загружаю дата-фрейм модели machine_df_mod = pd.read_csv('...data-framegazp_machine_df_mod.csv', index_col = 0) #создаю функцию для определения результата дня в булевом множестве def create_result_bool(row): return 1 if row.Result >= 0 else 0 #создаю серию с результатами дня в булевом множестве result_bool = machine_df_mod.apply(create_result_bool, axis='columns') #добавляю в дата-фрейм machine_df полученную серию machine_df_mod = pd.concat([machine_df_mod, result_bool], axis = 1) machine_df_mod.columns.values[12]='Result_bool' #в дата-фрейме 1756 строк. Я разделю его на два дата-фрейма: #machine_df_train (493 строки, с 19.01.2015 по 30.12.2016) и #machine_df_test (1263 строки с 03.01.2017 по 30.12.2021). machine_df_train = machine_df_mod.iloc[:493] machine_df_test = machine_df_mod.iloc[493:] # Определяю цель и отделяю цель от предикторов, также убрал столбец Date, т.к. #он никак не поможет модели y = machine_df_train.Result_bool X = machine_df_train.drop(['Date','Result', 'Result_bool'], axis=1) #создаю функцию для определения результата прогноза модели в процентах с учетом комиссии брокера def create_machine_result_perc(row): return (abs(row.Result) - 0.00039 * 2) * 100 if row.Result_bool == row.machine_predict else (- abs(row.Result) - 0.00039 * 2) * 100 #Создаю функцию для проверки параметров модели def machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test): # Делю данные для построения модели и проверки X и y X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=test_size, random_state=42, shuffle = False ) knn = KNeighborsClassifier(n_neighbors=n_neighbors) knn.fit(X_train, y_train) knn_pred = knn.predict(X_valid) y = machine_df_test.Result_bool X = machine_df_test.drop(['Date','Result', 'Result_bool'], axis=1) knn_pred_test = knn.predict(X) machine_predict_df = pd.DataFrame({'machine_predict' : knn_pred_test}) index_list = machine_df_test.index.tolist() machine_predict_df.index = index_list machine_df_test = pd.concat([machine_df_test, machine_predict_df], axis = 1) machine_result_perc = machine_df_test.apply(create_machine_result_perc, axis='columns') return [test_size, n_neighbors, accuracy_score(y_valid, knn_pred), accuracy_score(y, knn_pred_test), machine_result_perc.sum()] test_size_list = [] n_neighbors_list = [] accuracy_valid_list = [] accuracy_test_list = [] cumsum_list = [] #для поиска наилучшей комбинации набора параметров создам дата-фрейм с результатами #модели для размера тестовой выборки test_size [0.2,0.3,0.4,0.5] и # числа соседей от 1 до 13 включительно for test_size in [0.2,0.3,0.4,0.5]: for n_neighbors in range(1,14): res = machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test) test_size_list.append(res[0]) n_neighbors_list.append(res[1]) accuracy_valid_list.append(res[2]) accuracy_test_list.append(res[3]) cumsum_list.append(res[4]) d = {'test_size': test_size_list, 'n_neighbors': n_neighbors_list, 'accuracy_valid' : accuracy_valid_list, 'accuracy_test' : accuracy_test_list, 'cumsum' : cumsum_list} parameter_df = pd.DataFrame(data=d) print(parameter_df) print(parameter_df.accuracy_test.describe()) accuracy_test_rating_size = parameter_df.groupby('test_size').accuracy_test.mean() print(accuracy_test_rating_size) accuracy_test_rating_neig = parameter_df.groupby('n_neighbors').accuracy_test.mean() print(accuracy_test_rating_neig)Hidden text
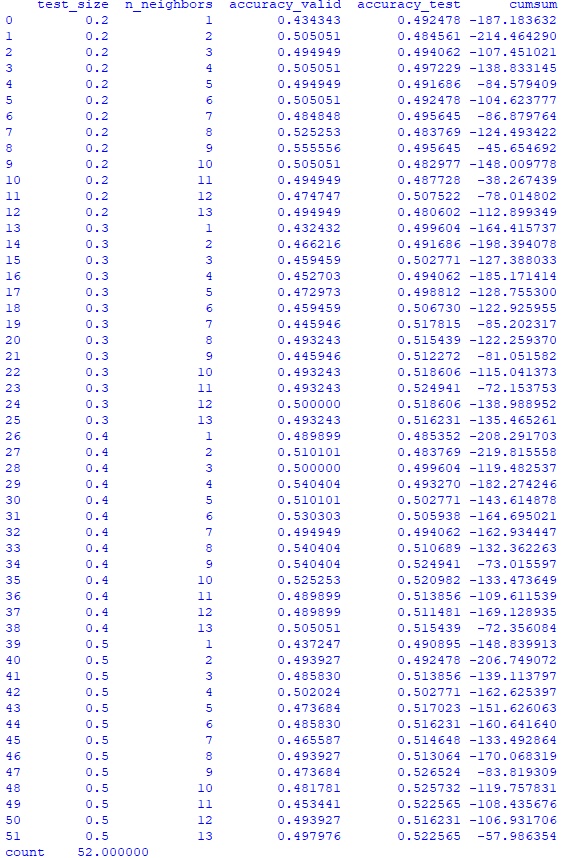
Среднее значение результата модели -130,6%, то есть результат не улучшился, а почти в 3 раза ухудшился.
Улучшение модели путем добавления нового класса результата
Попробую пойти другим путем: ранее модель училась с целевым столбцом Result_bool, который содержал значение 1, если результат дня был положительным и значение 0, если отрицательным. Попробую ввести не 2, а 3 значения целевого столбца:
0 – результат дня от -0.01 до 0.01 (день, не интересный для торговли, когда цена акции менялась в диапазоне менее 1%)
1 – результат дня больше 0.01
-1 – результат дня меньше -0.01
Меня будут интересовать только прогнозы модели «-1» и «1». Таким образом модель будет торговать реже и, быть может, точнее. В новом окне:
#импортирую необходимые библиотеки from sklearn.model_selection import train_test_split, StratifiedKFold from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score import pandas as pd machine_df = pd.read_csv('...data-framegazp_machine_df.csv', index_col = 0) #создаю функцию для присвоения результату дня одного из трех значений def create_result_3way(row): if abs(row.Result) < 0.01: return 0 elif row.Result >= 0.01: return 1 else: return -1 #создаю серию с результатами дня в булевом множестве result_3way = machine_df.apply(create_result_3way, axis='columns') #добавляю в дата-фрейм machine_df полученную серию machine_df = pd.concat([machine_df, result_3way], axis = 1) machine_df.columns.values[12]='Result_3way' #вывожу первые 5 строк полученного дата-фрейма print(machine_df.head()) #print(machine_df.shape) #в дата-фрейме 1756 строк. Я разделю его на два дата-фрейма: #machine_df_train (493 строки, с 19.01.2015 по 30.12.2016) и #machine_df_test (1263 строки с 03.01.2017 по 30.12.2021). machine_df_train = machine_df.iloc[:493] machine_df_test = machine_df.iloc[493:] #print(machine_df_test.head()) # Определяю цель и отделяю цель от предикторов, также убрал столбец Date, т.к. #он никак не поможет модели y = machine_df_train.Result_3way X = machine_df_train.drop(['Date','Result', 'Result_3way'], axis=1) #создаю функцию для определения результата прогноза модели в процентах с учетом комиссии брокера def create_machine_result_perc(row): if row.Result > 0 and row.machine_predict == 1 or row.Result < 0 and row.machine_predict == -1: return (abs(row.Result) - 0.00039 * 2) * 100 elif row.Result < 0 and row.machine_predict == 1 or row.Result > 0 and row.machine_predict == -1: return (-abs(row.Result) - 0.00039 * 2) * 100 #Создаю функцию для проверки параметров модели def machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test): # Делю данные для построения модели и проверки X и y X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=test_size, random_state=42, shuffle = False ) knn = KNeighborsClassifier(n_neighbors=n_neighbors) knn.fit(X_train, y_train) knn_pred = knn.predict(X_valid) # print(accuracy_score(y_valid, knn_pred)) y = machine_df_test.Result_3way X = machine_df_test.drop(['Date','Result', 'Result_3way'], axis=1) knn_pred_test = knn.predict(X) # print(accuracy_score(y, knn_pred)) machine_predict_df = pd.DataFrame({'machine_predict' : knn_pred_test}) index_list = machine_df_test.index.tolist() machine_predict_df.index = index_list machine_df_test = pd.concat([machine_df_test, machine_predict_df], axis = 1) print(machine_df_test.head()) machine_result_perc = machine_df_test.apply(create_machine_result_perc, axis='columns') # machine_result_cumsum = machine_result_perc.cumsum() # print(machine_result_cumsum) # print('test_size ',test_size) # print('n_neighbors', n_neighbors) # print('accuracy_score(y_valid, knn_pred_test)', accuracy_score(y_valid, knn_pred_test)) # print('',) # print('',) return [test_size, n_neighbors, accuracy_score(y_valid, knn_pred), accuracy_score(y, knn_pred_test), machine_result_perc.sum()] a = machine_test_parameter(y, X, 0.3, 9, machine_df_test) print(a) test_size_list = [] n_neighbors_list = [] accuracy_valid_list = [] accuracy_test_list = [] cumsum_list = [] #для поиска наилучшей комбинации набора параметров создам дата-фрейм с результатами #модели для размера тестовой выборки test_size [0.2,0.3,0.4,0.5] и # числа соседей от 1 до 13 включительно for test_size in [0.2,0.3,0.4,0.5]: for n_neighbors in range(1,14): res = machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test) test_size_list.append(res[0]) n_neighbors_list.append(res[1]) accuracy_valid_list.append(res[2]) accuracy_test_list.append(res[3]) cumsum_list.append(res[4]) #Для оценки результатов создаю дата-фрейм parameter_df d = {'test_size': test_size_list, 'n_neighbors': n_neighbors_list, 'accuracy_valid' : accuracy_valid_list, 'accuracy_test' : accuracy_test_list, 'cumsum' : cumsum_list} parameter_df = pd.DataFrame(data=d) print(parameter_df)Hidden text

#в дата-фрейме 1756 строк. Я разделю его на два дата-фрейма: #machine_df_train (493 строки, с 19.01.2015 по 30.12.2016) и #machine_df_test (1263 строки с 03.01.2017 по 30.12.2021). machine_df_train = machine_df.iloc[:493] machine_df_test = machine_df.iloc[493:] #Определяю цель и отделяю цель от предикторов, также убрал столбец Date, т.к. #он никак не поможет модели y = machine_df_train.Result_3way X = machine_df_train.drop(['Date','Result', 'Result_3way'], axis=1) #создаю функцию для определения результата прогноза модели в процентах с учетом комиссии брокера def create_machine_result_perc(row): if row.Result > 0 and row.machine_predict == 1 or row.Result < 0 and row.machine_predict == -1: return (abs(row.Result) - 0.00039 * 2) * 100 elif row.Result < 0 and row.machine_predict == 1 or row.Result > 0 and row.machine_predict == -1: return (-abs(row.Result) - 0.00039 * 2) * 100 else: return 0 #Создаю функцию для проверки параметров модели def machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test): # Делю данные для построения модели и проверки X и y X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=test_size, random_state=42, shuffle = False ) knn = KNeighborsClassifier(n_neighbors=n_neighbors) knn.fit(X_train, y_train) knn_pred = knn.predict(X_valid) y = machine_df_test.Result_3way X = machine_df_test.drop(['Date','Result', 'Result_3way'], axis=1) knn_pred_test = knn.predict(X) machine_predict_df = pd.DataFrame({'machine_predict' : knn_pred_test}) index_list = machine_df_test.index.tolist() machine_predict_df.index = index_list machine_df_test = pd.concat([machine_df_test, machine_predict_df], axis = 1) machine_result_perc = machine_df_test.apply(create_machine_result_perc, axis='columns') return [test_size, n_neighbors, accuracy_score(y_valid, knn_pred), accuracy_score(y, knn_pred_test), machine_result_perc.sum()] test_size_list = [] n_neighbors_list = [] accuracy_valid_list = [] accuracy_test_list = [] cumsum_list = [] #для поиска наилучшей комбинации набора параметров создам дата-фрейм с результатами #модели для размера тестовой выборки test_size [0.2,0.3,0.4,0.5] и # числа соседей от 1 до 13 включительно for test_size in [0.2,0.3,0.4,0.5]: for n_neighbors in range(1,14): res = machine_test_parameter(y, X, test_size, n_neighbors, machine_df_test) test_size_list.append(res[0]) n_neighbors_list.append(res[1]) accuracy_valid_list.append(res[2]) accuracy_test_list.append(res[3]) cumsum_list.append(res[4]) #Для оценки результатов создаю дата-фрейм parameter_df d = {'test_size': test_size_list, 'n_neighbors': n_neighbors_list, 'accuracy_valid' : accuracy_valid_list, 'accuracy_test' : accuracy_test_list, 'cumsum' : cumsum_list} parameter_df = pd.DataFrame(data=d) print(parameter_df)Hidden text
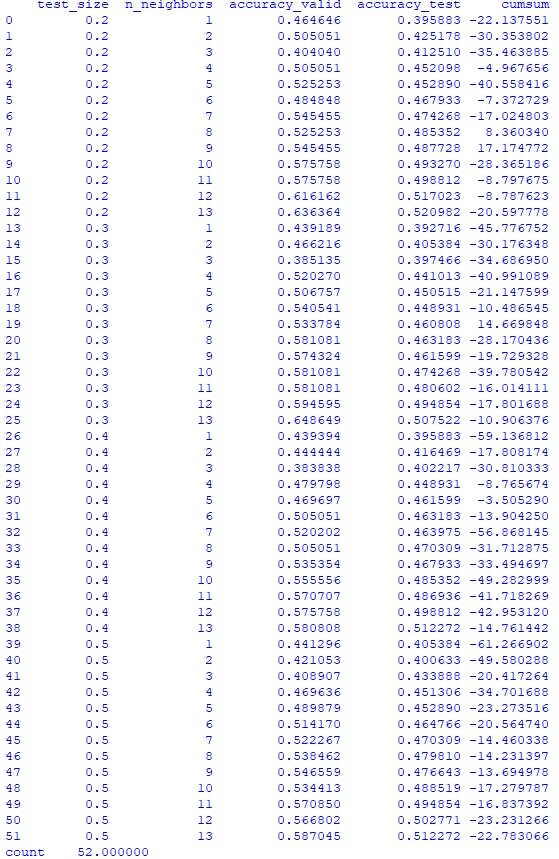
Среднее значение -23,79%, что не позволяет говорить о каком-то улучшении работы модели.
Выводы
Полученный опыт интересен для меня и, надеюсь, не только для меня. Чтобы воспроизвести в любимом Excel-е то, что делает модель, мне понадобилось бы кратно больше времени.
Система игры по скользящей средней показала аккуратность 50,9% и результат торговли -24,01%.
Модель улучшить не удалось, поэтому буду рассматривать первые результаты: аккуратность 51,8%, результат торговли -52,2%.
При том, что суммарная комиссия брокера составила 95,52%, обе системы показали положительный результат торговли, если комиссию брокера не учитывать. То есть в вакууме обе системы полезны и могут использоваться для реальной торговли в составе какой-то стратегии. Это в некоторой степени меня удивило.
В дальнейшем я не оставлю попыток разработки различных моделей, если найду интересную тему, напишу еще. Буду продолжать наблюдение, как говорится.
ПС Исходный файл .csv выложил на яндекс-диск, если кто-то захочет покрутить его самостоятельно, welcome.
Источник: habr.com