Распознавание речи, генерация субтитров и изучение языков при помощи Whisper
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-10-14 01:28
алгоритмы распознавания речи, распознавание образов, алгоритмы машинного обучения

Есть ряд платных решений по переводу речи в текст (Automatic Speech Recognition). Сравнительно малыми усилиями можно сделать бесплатное решение, — дообучить на своих данных end2end модель (например, взять фреймворк NeMo от NVIDIA) или гибридную модель типа kaldi. Сверху понадобится добавить расстановку пунктуации и денормализацию для улучшения читаемости ("где мои семнадцать лет" -> "Где мои 17 лет?").
Недавно в открытый доступ была выложена мультиязычная модель whisper от OpenAI. Попробовал ее large вариант на нескольких языках и расшифровал 30 выпусков "Своей игры" результат понравился, но есть нюансы. Модель транскрибирует тексты вместе с пунктуацией и капитализацией, расставляет временные метки, умеет генерировать субтитры и определять язык. Языков в обучающем датасете порядка ста. Чтобы прикинуть по качеству, нужно посмотреть на их распределение — данных на 100 часов и более было лишь для 30 языков, более 1000 ч. — для 16, ~10 000 часов — у 5 языков, включая русский.
Модель заслуживает внимания так как умеет делать очень много "из коробки". Давайте разберемся подробнее и научимся ей пользоваться.
Про модель
Пара слов про whisper. В тесном мире ASR данных хватает, но не всегда хватает разметки. По этой причине появились unsupervised подходы по обучению на данных без транскрипций с последующим дообучением на небольшом размеченном датасете. В этом случае объем первичных данных можно увеличить до миллиона часов (см. wav2vec 2.0). Энкодер при этом выучивает очень качественные представления для звуков (точнее для их численного представления), но для преобразования их в человеческий вид все равно потребуется целевой размеченный людьми датасет. Объемы таких датасетов могут быть от ста до нескольких тысяч часов, то есть на много порядков меньше всех аудио, которые можно найти в интернете. Для русского языка также есть открытые датасеты, нарпример OpenSTT и SOVA.
Авторы whisper идут по пути компромисса, используя weakly supervised подход. Взяли все доступные аудио с транскрипцями из интернета и пофильтровали их, но не сильно. Получили некий зашумленный датасет, в котором в том числе есть и транскрипции сделанные другими ASR системами, много тишины и шумов, смех, апплодисменты и т.д. Объем получился 680 000 часов на 97 языках, из которых 117 000 часов не на английском. Обучение на таком большом зашумленном датасете, по мнению авторов, дает значительное улучшение обобщающей способности модели и её устойчивости к посторонним звукам.
Еще одной особенностью модели является её многозадачность. Задачи распознавания речи, перевода (с языка X на английский), определения языка и детекции голоса (VAD) при обучении были приведены к единому виду (в виде последовательности токенов, включая специальные — <|nospeech|>, <|transcribe|>, <|translate|> и другие) в seq2seq манере. Это позволяет упаковать несколько специализированных моделей в одну и обучать все задачи совместно.
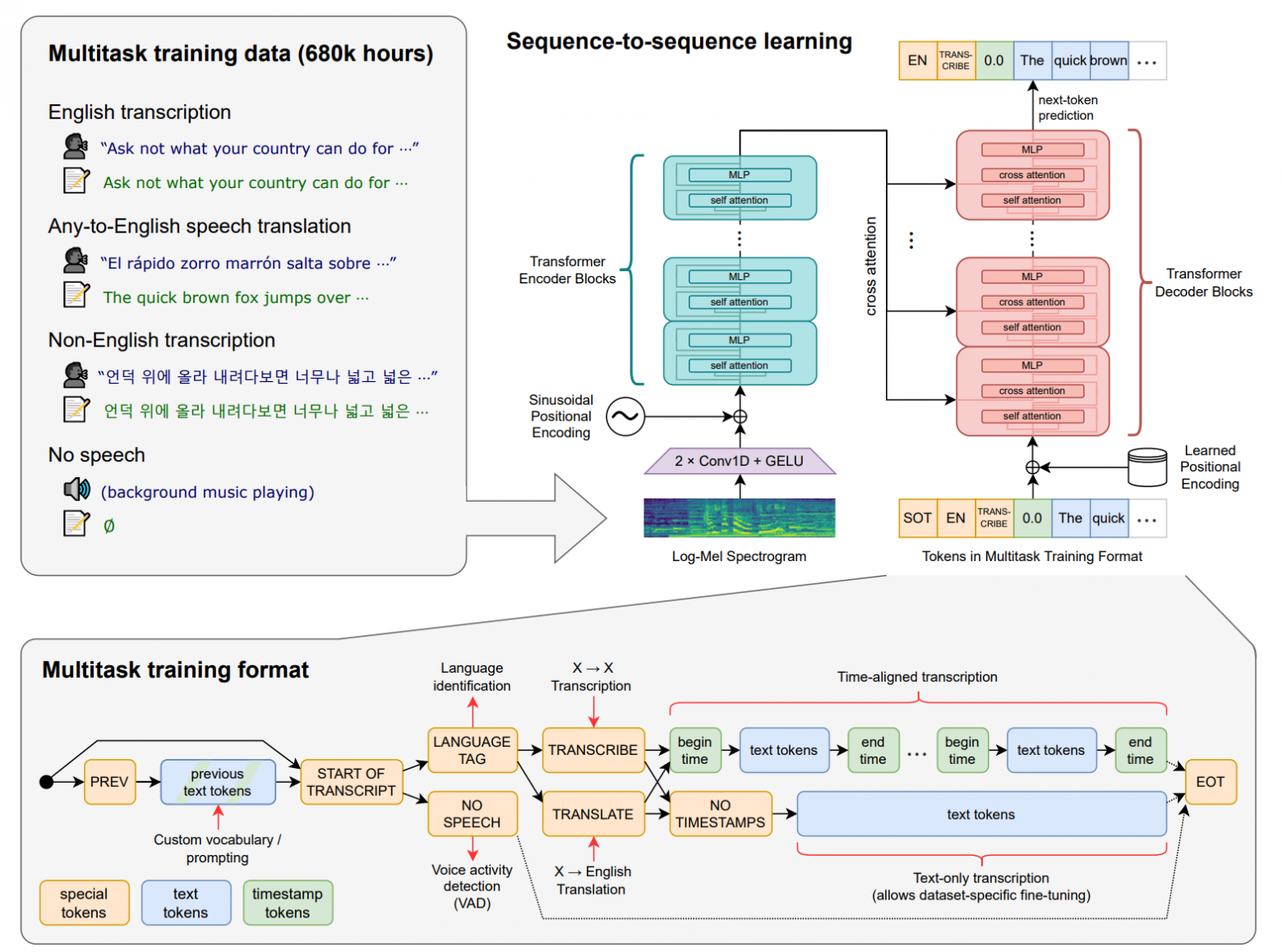
Модельный ряд
Моделей натренировали несколько, — с увеличением количества параметров качество растет, но не драматически. Base и small моделями можно пользоваться на домашнем компьютере на CPU, medium и large тоже запустятся, но будут работать довольно медленно. Все эксперименты я проводил на large модели с использованием 3090 ti.
Размер | Веса | Английская модель | Мультиязычная модель | Сколько нужно RAM |
tiny | 39 M | tiny.en | tiny | ~1 GB |
base | 74 M | base.en | base | ~1 GB |
small | 244 M | small.en | small | ~2 GB |
medium | 769 M | medium.en | medium | ~5 GB |
large | 1550 M | n/a | large | ~10 GB |
Архитектура
В качестве архитектуры взяли трансформер. Основной гипотезой авторов было обучение на большом шумном датасете, поэтому они не стали вносить значительных изменений в модель, чтобы не получить "побочных улучшений". Подробнее про процесс обучения можно почитать в статье, а мы пойдем дальше. Для начала установим библиотеку.
Установка
Чтобы запустить whisper у себя на компьютере, поставим библиотеку:
pip install git+https://github.com/openai/whisper.git Это консольный клиент, модели подгрузятся при первом запуске.
Также нужно, чтобы в системе был установлен ffmpeg для работы с медиа данными. Для windows ffmpeg.exe нужно скачать отсюда, положить в любую папку и добавить её в PATH. Под linux библиотеку можно установить через консоль, например так:
sudo apt update && sudo apt install ffmpegЕщё установим библиотеку yt-dlp для работы с youTube, она нам скоро пригодится.
pip install yt-dlpЕсли что-то не получилось, не стесняйтесь писать, мы все здесь чему-то учимся.
Транскрибация
Попробуем расшифровать несколько типичных видео разных жанров и с разным набором лексики. Cпециализированные домены (звонки в коллл-центр и т.д.) мы сейчас рассматривать не будем, так как без дообучения под такой домен результат будет заведомо плохой (я пробовал). И напротив, обычная речь с микрофона на общие темы распознается на отлично.
Репортаж
Сначала попробуем транскрибировать ролик с несколькими спикерами, без специальной лексики и названий. Возьмем репортаж про Питерский трамвай.

Скачаем файл командой:
yt-dlp -x --audio-format mp3 -o piter.mp3 -- VPPknXEXk1kVPPknXEXk1k — это id ролика на youTube (файл). Теперь переведем его в текст:
whisper --language ru --model large -o ./result -- piter.mp3В папке result появится файлик piter.mp3.txt. Вот его начало:
Самый обычный день из жизни большого города, пробки
на дорогах, люди куда-то спешат, на остановке только
мы с оператором и мужчина лет 70 ждем трамвая, а пока
разговариваем о том, о сём, в общем ни о чём, я говорю
снимаем про трамвай, тут мой случайный попутчик представляется
Дмитрий Достоевский, в прошлом водитель трамвая,
вот так, а с другой стороны чему удивляться, Петербург,
трамвай, Достоевский.
Дмитрий Андреевич, правнук великого писателя, кем
только не работал и таксистом, и гидом, водил экскурсии
по местам произведения своего именитого предка,
но с особой ностальгией всегда вспоминает именно
о том времени, когда водил трамвай по городу.
Я не могу из-под носа уехать, даже если я не мог, даже
если я опаздываю и у меня, я знал, где я могу нагнать,
где я чуть-чуть побыстрее поеду, всё это было известно,
и поэтому, если кто-то бежит, я старался дожидаться.
Я чуть не задавил известнейшего театрального режиссёра
Владимирова.
Серьёзно?
Да.
Как?
Только благодаря моей реакции я тормознул.
Но у меня там, конечно, все закричали, не картошку
везёшь, а что делать?
Я по трансляции сказал, я человека сейчас спасу.
Первый трамвай на электрической тяге, именно на электрической
конке уже вовсю ходили по городу, появился на Неве
в 1894 году.
Как видим, водитель трамвая говорит простым языком, хотя и довольно сбивчиво. Модель все слова распознала корректно и расставила пунктуацию. Числа также были приведены к цифровому формату корректно.
Выступление
Возьмем выступление о кибербезопасности со специализированными IT-терминами и большим количеством говорящих, которые периодически друг друга перебивают.

Медиа-группа «Авангард» представляет
Друзья, привет! Рад вас всех приветствовать на нашем SOC-форуме.
Седьмой SOC-форум, конечно, это очень круто.
Семь лет мы обсуждаем вопросы кибербезопасности.
В совершенно новых форматах находим ответы.
Если вспомнить, как всё начиналось семь лет назад, это был...
Кто был первый SOC-форум инфопространством, мы рассчитывали, что соберём 200 человек.
Мы считали, что это очень много.
Пришло 400. Кофе на кофепаузе.
Закончился ровно через пять минут после начала кофепаузы.
И, конечно, вот этот вот темп, который мы набираем
в нашей конференции, в нашем мероприятии, это очень круто.
Итак, дорогие друзья, мы начинаем наш седьмой SOC-форум.
SOC-форум, посвящённый практике противодействия кибератакам
и построению центров мониторинга....
Юрий, хотел с вами,
знаете, вот сейчас, когда говорим про поддержку
отрасли, это во многом еще и вопрос
финансирования. Ведь кибербезопасность
это, ну, в общем, прямо недешевая штука. И если
посмотреть на некоторую статистику
финансирования проектов
по информационной безопасности, она
выглядит, ну, такой, достаточно печальной.
Если в мире в среднем выделяется
105% от IT-бюджетов на обеспечение
кибербезопасности, то в России по разным оценкам эта цифра где-то порядка
одного-двух процентов.
И это в разы меньше.
Как ты считаешь, Юр, каким
должна быть поддержка отрасли, поддержка
развивающихся бизнесов, стартапов для того,
чтобы вот эта вот критическая масса
людей, могущих обеспечить безопасность,
технологий необходимых для обеспечения
безопасности, но тем более в условиях
импортозамещения она появлялась
и развивалась?
Спасибо, Игорь.
Я тогда продолжу свою мысль предыдущую
про гендиров.
Здесь тоже все хорошо, сеть знает о существовании некоего SOC'а, о существовании IT-шников, разговорных вариантов имен ("Юр") и даже многоточие поставила к месту.
А теперь проблемы
Чтобы вскрыть первую проблему возьмем случай посложнее — песни. Образный лексикон и постоянная музыка на фоне. Модель для этих целей не предназначена, но дадим ей шанс и ознакомимся с потенциальными проблемами. Транскрибируем "Очи черные" Высоцкого (файл).

whisper --language ru --model large -o ./result -- ochi_cherniye.mp3Получим вот такое:
Вахмелю
Вахмелю
Вахмелю
Вахмелю
Вахмелю
Вахмелю
Вахмелю
Вахмелю
Вахмелю
Вахмелю
Вахмелю
Вахмелю
Спасибо Бог вас, лошадки, что целым идут!
Сколько канула, сколько схлынула,
Жизнь кидала меня, не докинула.
Может, спел про вас неумелая,
Очи черные, скатерть белая.
Проблема 1. Зацикливание
Как авторы пишут в статье (раздел Limitations and future work) с размером модели растет её устойчивость, но при транскрибации продолжительного аудио авторегрессионная природа модели может давать эффекты зацикливания, пропуска крайних слов сегмента и галлюцинаций (выдавать слова, которых нет на записи). Чаще всего это будет наблюдаться для малоресурсных языков и малознакомых доменов.
Можно попробовать побороться с этим, поигравшись с параметрами сэмплинга --temperature и ---logprob_threshold.
Можно отключить авторегрессионность параметром --condition_on_previous_text, что ожидаемо ухудшит осмысленность текста, хоть и уберет зацикленность в нашем случае:
whisper --language ru --model large -o ./result --condition_on_previous_text False -- ochi_cherniye.mp3Вахмелю
Стрелял мне в лицо, только я проглочу
Вместе с грязью слюну,
Штову горло скручу и опять затяну.
Очи черные, как любил я вас,
Но прикончил я то, что впрок припас.
Головой тряхнул, чтоб слетела плаш,
И вокруг взглянул, и присвиснул аж.
Лес стеной впереди не пускает стена,
Они прятут ушами, назад подают.
Где просвет, где прогал, Ни беда, ни рожна.
Коль утыкла меня, до костей Достают коренной тимой.
Хрущай же, брат, ты куда, родной?
Почему назад тошь, как яд с ветвей?
Недобром пропах престижной моей.
Волк нырнул под паху, вот же пьяный дурак.
Вот же налил глаза, ведь погибель пришла.
Обижать не суметь, из колоты моей Утащили туза, да такого
туза, Без которого смерть я ору волкам.
Побери вас, прах, огоней пока, Подгоряет страх шевелюкнутом.
Бью крученые и ору бритом, Очи черные, храп, да то
Но под Таляск далеко перепляс, Бубенцы плисовую играют стуки.
Ах вы, кони мои, погублющие вас, Выносите, друзья, выносите враги от погони той.
Даже хмели сяк, мы на кряш крутой, На одних осях в хлопьях пены мы
Струи в гря шлились, Отдышались, отхрепели Да откашлились я лошадкам Забитым, что не подвели.
Поклонился в копыта До самой земли, Сбросил с воза манатки, Повёл по воду.
Спасибо Богу, лошадки, Что целым иду.
Сколько канула, сколько схлынула, Жизнь кидала меня, не докинула.
Может, спел про вас неумелая, Очи чёрные, скатерть белая.
Есть еще один хак, — можно подать в модель затравку (привет prompt-инженерам) через параметр --initial_prompt:
whisper --language ru --model large -o ./result --initial_prompt "Во хмелю" -- ochi_cherniye.mp3Лесом правил я
Стрелял мне в лицо, только я проглочу
Вместе с грязью слюну
Штову горло скручу и опять затяну
Очи черные, как любил я вас
Но прикончил я то, что впрок припас
Головой тряхнул, чтоб слетела плаш
И вокруг взглянул, и присвиснул аж
Лес стеной впереди не пускает стена
Они прятут ушами, назад подают
Где просвет, где прогал, не беда, не рожна
Колю тыкла меня, до костей достают
Коренной ты мой, вручай же, брат
Ты куда, родной, почему назад?
Дождь, как яд с ветвей, недобром пропах
Пристежной моей волк нырнул под пах
Вот же пьяный дурак
Вот же налил глаза, ведь погибель пришла
Обижать не суметь из колоты моей
Утащили туза, да такого туза
Без которого смерть я ору волкам
Побери вас, прах, а коней пока
Подгорает страх шевелюкнутом
Бью крученые и ору бритом
Очи черные, храп, да то под Таляск
Да лихой перепляс, бубенцы плесовую играют
Стуки, ах вы, кони мои, погублю же я вас
Выносите, друзья, выносите враги от погони той
Даже хмели сяк, мы на кряш крутой
На одних осях в хлопьях пены мы
Струи в кряш лились, отдышались
Отхрепели, да откашлились
Я лошадкам забитым, что не подвели
Поклонился в копыта до самой земли
Сбросил с воза манатки, повел в поводу
Спасибо Бог вас, лошадки, что целым иду
Сколько кануло, сколько схлынуло
Жизнь кидала меня, не докинула
Может, спел про вас неумелая
Очи черные, скатерть белая
Затравка не считается транскрипцией, поэтому в результат не попадет. К ней мы еще вернемся чуть позже.
Генерируем субтитры

Модель по умолчанию расставляет временные метки для фрагментов, поэтому еще раз заглянем в папку result, — и увидим там srt файл. Все это время уже генерировали субтитры. Вот расшифровка репортажа про трамвай:
00:00:00,000 --> 00:00:19,240
Самый обычный день из жизни большого города, пробки00:00:19,240 --> 00:00:21,860
на дорогах, люди куда-то спешат, на остановке только00:00:21,860 --> 00:00:25,400
мы с оператором и мужчина лет 70 ждем трамвая, а пока00:00:25,400 --> 00:00:28,180
разговариваем о том, о сём, в общем ни о чём, я говорю...
00:06:05,520 --> 00:06:08,920
Встает солнышко, просыпаются наши пассажиры.00:06:08,920 --> 00:06:12,080
Также мы смотрим, как город засыпает, ездим по городу,00:06:12,080 --> 00:06:15,240
по центру есть маршруты, смотрим набережные.00:06:15,240 --> 00:06:16,800
Довольно красивые.00:06:16,800 --> 00:06:28,000
Для Петербурга трамвай – это не просто транспорт,00:06:28,000 --> 00:06:30,520
это еще один символ города, как Петропавловская крепость00:06:30,520 --> 00:06:32,520
или Пышечная на Большой конюшне.
Своя игра
Ради интереса я транскрибировал большой моделью несколько последних выпусков телепередачи Своя игра и собрал из них страничку. Результат в целом мне понравился:
00:00:00.000 МУЗЫКАЛЬНАЯ ЗАСТАВКА
00:00:15.000 АПЛОДИСМЕНТЫ
00:00:19.000 Здравствуйте! Добрый день! Это «Своя игра».
00:00:22.000 Мы продолжаем наш турнир, который называется «Игры золотой девятки».
00:00:26.000 Сегодня у нас финальная игра пятого этапа «Игр золотой девятки» в 2022 году.
00:00:35.000 Сегодня играют очень сильные игроки.
00:00:37.000 С удовольствием вам представляю участников сегодняшней игры.
00:00:41.000 За первым игровым столом Дмитрий Корякин, программист из Раменского.
00:00:46.000 АПЛОДИСМЕНТЫ
00:00:48.000 За центральным игровым столом, он же второй игровой стол, Евгений Калюков,
00:00:53.000 журналист из Ульяновска.
00:00:55.000 АПЛОДИСМЕНТЫ
00:00:57.000 И за третьим игровым столом Юрий Хашимов, юрист Москва.
Как мы видим, из обучающей выборки не убирали транскрипции звуков ("апплодисменты", "смех", "музыкальная заставка" и т.д.). Это не хорошо и не плохо, так как бывают различные требования к результату.
Лекции на английском
Так же я попробовал расшифровать лекции по машинному обучению от Андрея Карпати. Страничка и репозиторий.
...
00:26:57.000 Number one, let's not use 32.
00:26:59.000 We can, for example, do something like EMB.shape at 0 so that we don't hardcode these numbers.
00:27:07.000 And this would work for any size of this EMB.
00:27:10.000 Or alternatively, we can also do negative 1.
00:27:12.000 When we do negative 1, PyTorch will infer what this should be.
Английские технические термины разспознаются достаточно хорошо. EMB здесь посчиталось за аббревиатуру, на самом деле произносилось название переменной.
Проблема 2. Отключение расстановки пунктуации
У модели есть еще один failure mode. Насколько я понял из кода, модель может перестать обуславливаться на предыдущий фрагмент, если сэмплинг был с высокой температурой (а она при ошибках начинает повышаться, так как заданы несколько дискретных значений). На эту тему есть дискуссия. Такое может чаще случаться в самом начале, а также рандомно на длинных аудио (больше часа). За время моих экспериментов я с таким не встретился.
Авторы говорят, что пока что так, но вы если сломалось с самого начала, то попробуйте использовать --initial_prompt.
Изучение языков

Как человек, имеющий легкий "сдвиг" на изучении языков и смежные темы, я бы выделил и еще одно применение этой модели. По сгенерированным субтитрам можно нарезать роликов или аудио с фразами на нужную тему и использовать для улучшения языковых навыков. Это подойдет как минимум для языков из первой десятки, так как качество распознавания на них достойное.
Разумеется можно взять и готовые субтитры к какому-нибудь фильму или сериалу. В общем, я покажу как это можно сделать, а вы уж решайте дальше.
Подготовим видео (фильм, сериал или видео с youTube). В случае youTube воспользуемся уже знакомой утилитой и выкачаем видео какой-нибудь лекции:
yt-dlp --remux-video mp4 -o lecture.mp4 -- P6sfmUTpUmcСгенерируем субтитры whisper'ом, или возьмем готовые. srt файл с субтитрами назовем subs.srt.
Скрипты для следующий действий я выложил в репозиторий, качаем его. Сначала приведем субтитры к более удобному виду.
python .srt2csv.py -i ./subs.srt -o ./subs.csvЭтот csv файл сдоержит начало и конец фрагмента, а также его содержание.
start_time end_time rename_to content
00:00:00,000 00:00:01,180 video0.mpg Hi everyone.
00:00:01,180 00:00:04,200 video1.mpg Today we are continuing our implementation of Makemore.
00:00:04,200 00:00:05,040 video2.mpg Now in the last lecture,
00:00:05,040 00:00:06,760 video3.mpg we implemented the multilayer perceptron
00:00:06,760 00:00:08,880 video4.mpg along the lines of Benjou et al. 2003
00:00:08,880 00:00:10,720 video5.mpg for character level language modeling....
Оставим в нем только нужные строки, например, первую и третью:
start_time end_time rename_to content
00:00:00,000 00:00:01,180 video0.mpg Hi everyone.
00:00:04,200 00:00:05,040 video2.mpg Now in the last lecture,
Теперь нарежем по этим параметрам видео фрагменты:
python .ffmpeg-split.py -f ./lecture.mp4 -m subs.csv -v libx264Запустится ffmpeg и в папке output начнут появляться наши видео.
При желании можно предварительно "прожечь" субтитры прямо в исходное видео, тогда после нарезки у нас будут ролики с фразами в кадре:
ffmpeg -i lecture.mp4 -vcodec libx264 -vf subtitles=subs.srt:force_style='Fontsize=26' -y lecture_subbed.mp4
Дополнительно
К вышесказанному можно добавить еще несколько направлений, которые можно попробовать.
Диаризация — разделение спикеров. Понадобится при необходимости вычленить из аудиопотока определенного человека или добавить имя говорящего к субтитрам. Whisper не был на это натренирован, но вот здесь этот вопрос обсуждают и делятся наработками (colab).
Дообучение. Точно повысит качество под вашу конкретную задачу, так как whisper — модель общего назначения. Опять же, официально пока скриптов нет, но обсуждается здесь и есть colab.
Ссылки
Градиент обреченный — завел канал про машинное обучение и рабочие моменты. Приглашаю всех, кому интересна эта тема.
Транскрипции Своей игры — можно посмотреть на качество распознавания whisper и повторить на своих видео.
Whisper — репозиторий с моделью и инструкциями, там же ссылка на статью.
NeMo — фреймворк для обучения своих SOTA моделей. Выбирайте модель(например, Conformer-CTC) и дообучайте на своих данных.
Video Splitter — подготовил репозиторий для нарезки видео по субтитрам.
Multipunct — репозиторий для тренировки пунктуационной модели. Как пользоваться писал тут.
Источник: habr.com