Самая большая BERT-подобная модель на русском, которая поместится на ваш компьютер
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-09-17 06:00
Знаете, я и сам своего рода коллаборация
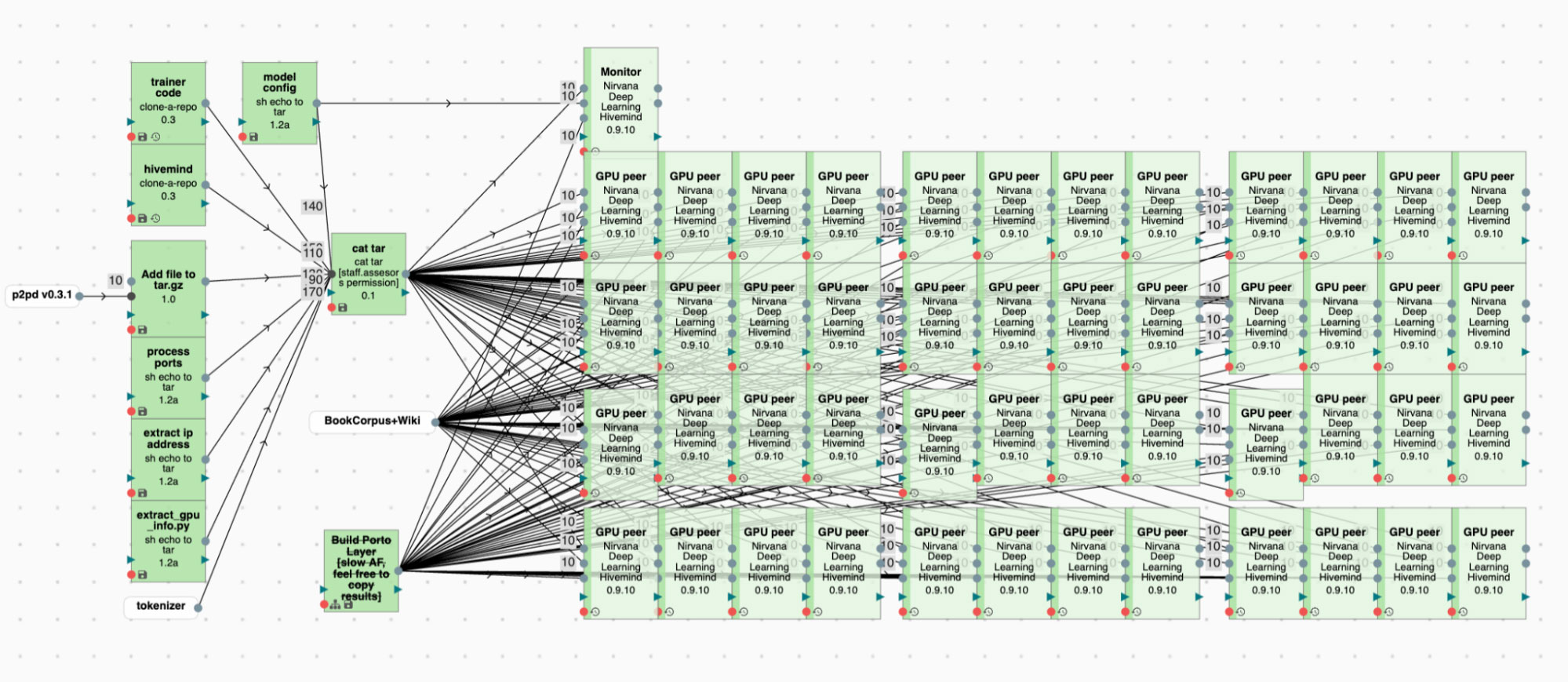
Для начала вспомним идею метода DeDLOC, на котором базируется наш подход с обучением на ненадёжных устройствах. Когда вы хотите обучить GPT-99 на компьютерах волонтёров по Интернету, вам необходимо учитывать медленную скорость соединения и нестабильность каждого отдельного компьютера: участвующему в обучении добровольцу может потребоваться видеокарта для иных целей, поэтому нужно уметь стабильно работать с переменным числом участников.
Вообще говоря, ситуация внезапного переключения сервера с одной задачи на другую не нова и возникает даже на облачных платформах: так, грамотное использование preemptible/spot instances (дешёвых серверов, которые у вас могут отобрать в любой момент) позволяет существенно снизить расходы на обучение при условии, если ваш код устойчив к отказам. У Яндекса есть похожая платформа для произвольных вычислительных задач — Нирвана, в которой планировщик может принять решение о вытеснении процесса в пользу более приоритетной задачи. Если учесть, что общее количество разнородных GPU на платформе довольно велико, но при этом долгие гарантии на много видеокарт получить бывает сложно, мы приходим к ситуации, в которой сценарий из предыдущего абзаца становится применимым к нашему окружению. Отдельно стоит отметить, что мы рассматриваем «заказ» хостов по одному, а не всего кластера, как это было в случае с YaLM. Причина проста: получить весь мощный кластер с быстрым соединением между узлами может быть довольно трудно, ведь на него претендует много команд; мы же, пользуясь описанными в посте про DeDLOC технологиями, можем использовать одиночные свободные GPU даже в разных датацентрах — из-за особенностей метода скорость сети для нас не так критична.
Архитектура модели
Если вы имеете дело с конкретной задачей в deep learning, часто имеет смысл подбирать архитектуру нейросети под конечные потребности и «железные» ограничения, а не наоборот. Здесь нашей целью с самого начала было обучить достаточно хороший Transformer-энкодер, который при этом можно было бы вместить в GPU уровня бесплатно доступных на Google Colab. По этой причине мы сразу отсекли вариант обучения обычного трансформера на миллиарды параметров. Вместе с тем обучение модели с нуля означало, что можно было использовать актуальные наработки научного сообщества по наиболее важным и полезным изменениям в базовой архитектуре нейросети.
Первым и самым главным отличием RuLeanALBERT от привычных вам RuBERT, RuRoBERTa и YaLM является использование weight sharing: так как очень большую модель сложнее и обучать распределённо, и применять впоследствии, мы сокращаем число параметров путём их переиспользования между слоями. Благодаря этому наша модель оказывается в 32 раза меньше, при этом не особо теряя в выразительности благодаря такому же количеству вычислений. Похожий приём успешно использовали использовали как авторы оригинального ALBERT, так и организаторы коллаборативных проектов sahajBERT и CALM.
Также мы применили ряд улучшений, показавших себя с точки зрения стабилизации обучения больших моделей: как показывает опыт YaLM, BLOOM и OPT, обучить модель до сходимости — большое испытание, процесс оптимизации так и норовит взорваться. Одним из таких важных улучшений является pre-normalization (оно же PreNorm или PreLN): в отличие от стандартной архитектуры Transformer, авторы оригинальной статьи предлагают вставлять слой LayerNorm внутри residual-ветки, а не после неё, чтобы сделать обучение более устойчивым. Вместе с этим мы используем технику инициализации параметров SmallInit, ещё сильнее улучшающую надёжность поведения модели и её градиентов.
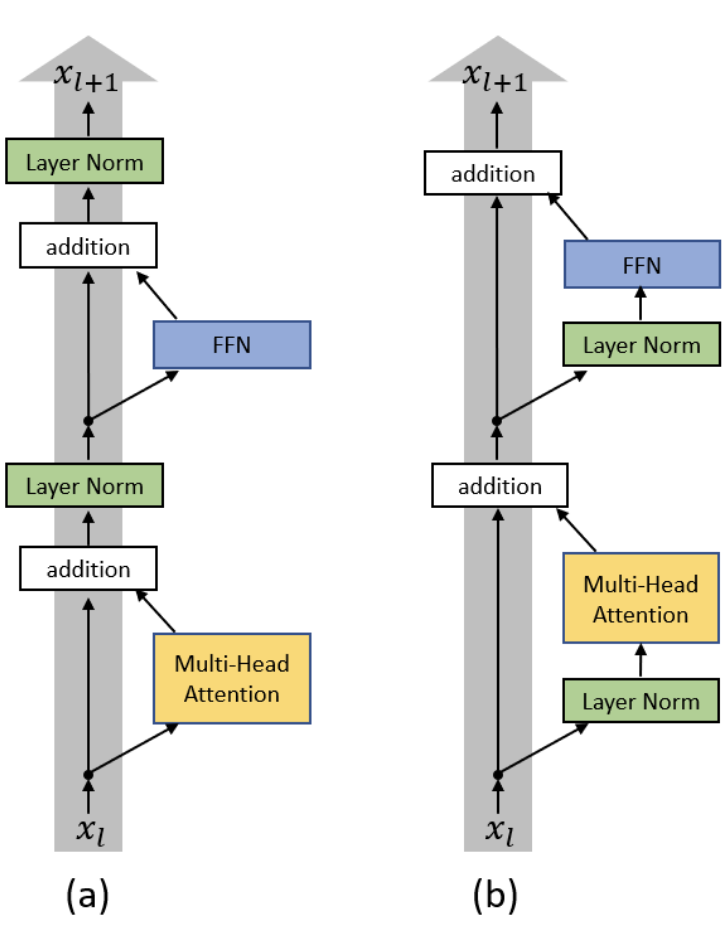
Наконец, мы не могли проигнорировать ряд недавних модификаций трансформеров, приводящих (по ряду независимых исследований) к консистентному росту качества моделей. Первым из них является использование rotary positional embeddings: подхода к кодированию позиций, сочетающем в себе преимущества абсолютного и относительного вариантов. Первыми о данном подходе заявили члены сообщества EleutherAI после того, как убедились, что он воспроизводит результаты авторов изначальной статьи и работает существенно лучше базовых методов. Если вам интересно разобраться в интуиции за rotary embeddings или детально понять их устройство, советую прочитать пост на сайте этого сообщества. Также из важного стоит отметить использование активаций GEGLU (Gaussian Error Gated Linear Units) из препринта Ноама Шазира (второго автора оригинальной статьи про Transformer): как показал автор, а мы подтвердили в предварительных экспериментах, такие активации дают порой небольшую, но устойчивую прибавку к результатам обученных нейросетей.
Подготовка данных
Даже самая новая архитектура нейросети и метод предобучения не могут гарантировать вам хорошее качество представлений: данные являются ключевым компонентом, без которого про обобщающую способность или даже просто про перенос знаний говорить бессмысленно. Пользуясь опытом предшественников, мы решили собрать достаточно большой и при этом разнообразный корпус текстов, чтобы получившаяся модель могла быть универсальным энкодером для разных NLP-задач.
Наш финальный корпус состоит из нескольких частей: 40 процентов данных составлял отфильтрованный датасет текстов из Интернета, схожий с тем, на чём училась YaLM, 20 — тексты русскоязычной Википедии, ещё по 20 — корпуса Taiga и Russian Distributional Thesaurus. Так как известно, что дубликаты в данных вредят и эффективности обучения модели, и финальному качеству, после конкатенации всех частей мы постарались устранить как полные дубли документов, так и частичные перекрытия по текстам.
Процесс предобучения
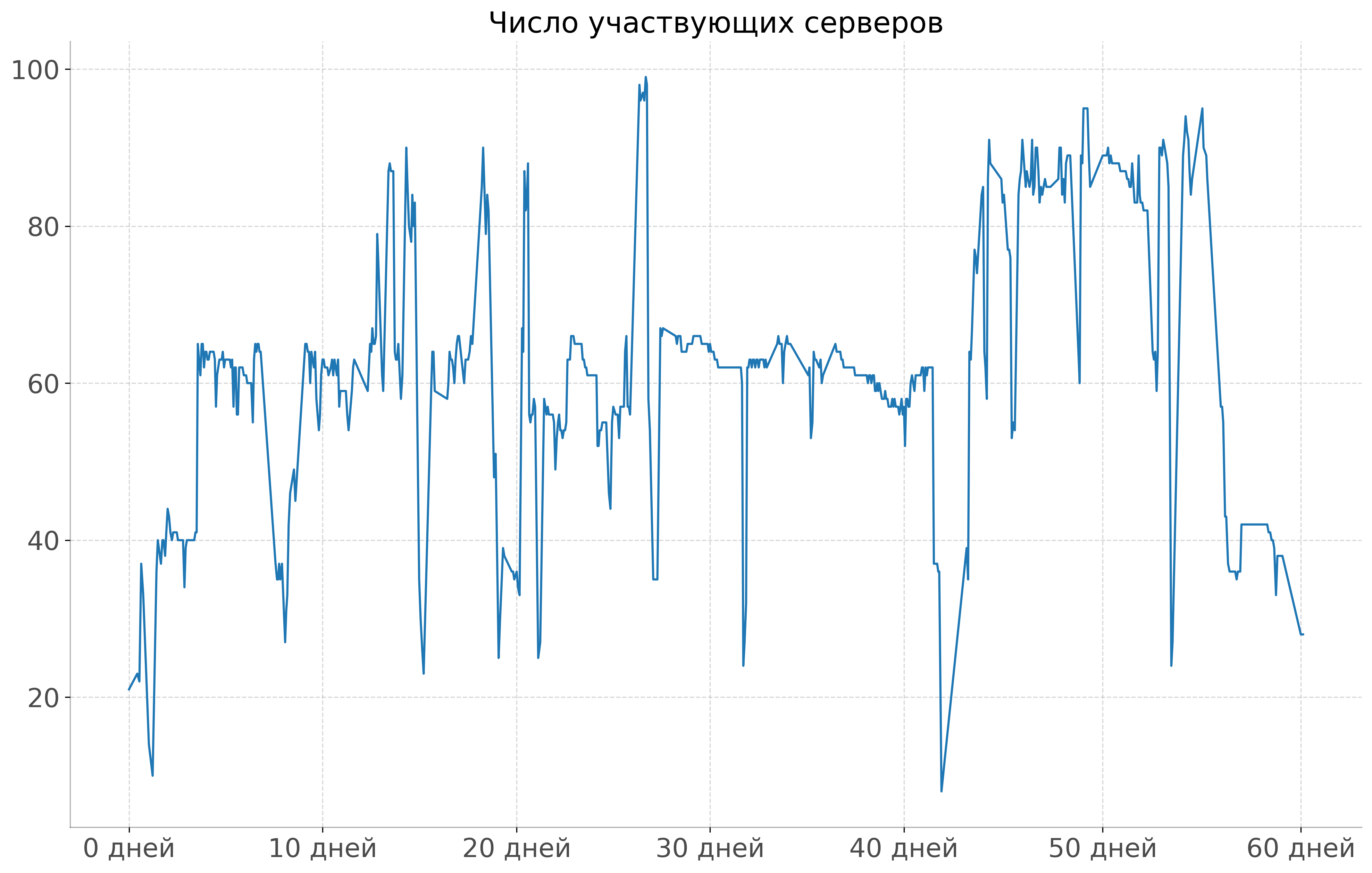
Эксперты в больших текстовых моделях знают, что существует великое множество способов сформулировать задачу для их обучения: в конечном же итоге довольно сложно победить обычный masked language modeling (MLM), что мы и выбрали для простоты эксперимента. Однако мы внесли важную модификацию в стандартную процедуру MLM, описанную в статье про BERT, а именно whole word masking (WWM) из авторского кода статьи. Суть этого изменения довольно проста: мы усложняем задачу для модели, маскируя слова в предложении целиком и не позволяя таким образом учиться на примерах типа «линг[MASK]тика», где промежуточный токен легко угадывается. Эта модификация реализована в нашем коде предобучения, который основан на широко известной библиотеке Transformers от Hugging Face и находится в открытом доступе. Как и предполагалось, стабильным по числу «участников» процесс обучения на разнородных серверах из разных датацентров назвать довольно трудно: количество активных узлов варьировалось от единиц (в моменты пиковой загрузки платформы другими задачами) до сотен (когда GPU были менее востребованы). На графике ниже можно пронаблюдать число участвующих в обучении инстансов за небольшой участок времени: можно сказать, наш эксперимент был как тестом планировщика Нирваны, так и проверкой возможностей фреймворка по децентрализованному обучению Hivemind.
Дообучение на Russian SuperGLUE и RuCoLA
Чтобы оценить качество языковых представлений RuLeanALBERT, мы решили проверить модель на открытых бенчмарках для русскоязычного NLP: как на проверенном и широким по охвату тем Russian SuperGLUE, так и на вышедшем недавно более сфокусированном датасете RuCoLA. Так как наша модель является обычным Transformer-энкодером с точки зрения пользователя, её можно дообучать такими же способами, как, например, ruRoBERTa. Так как мы не смогли найти авторский код для дообучения ruRoBERTa на задачах Russian SuperGLUE посредством библиотеки Transformers, мы написали его сами и проверили в том числе на других открытых моделях, чтобы убедиться, что потенциальные проблемы с качеством не будут обусловлены багами. Получилось даже лучше, чем мы ожидали: в процессе реализации дообучения мы обнаружили ряд проблем в разметке отдельных задач RussianSuperGLUE, исправление которых позволило добиться для RuRoBERTa более высоких результатов, чем доступные на публичном лидерборде. Мы публикуем код дообучения на обоих бенчмарках, чтобы на него можно было опираться как на сильный бейзлайн при исследовании новых методов или тестировании новых моделей.

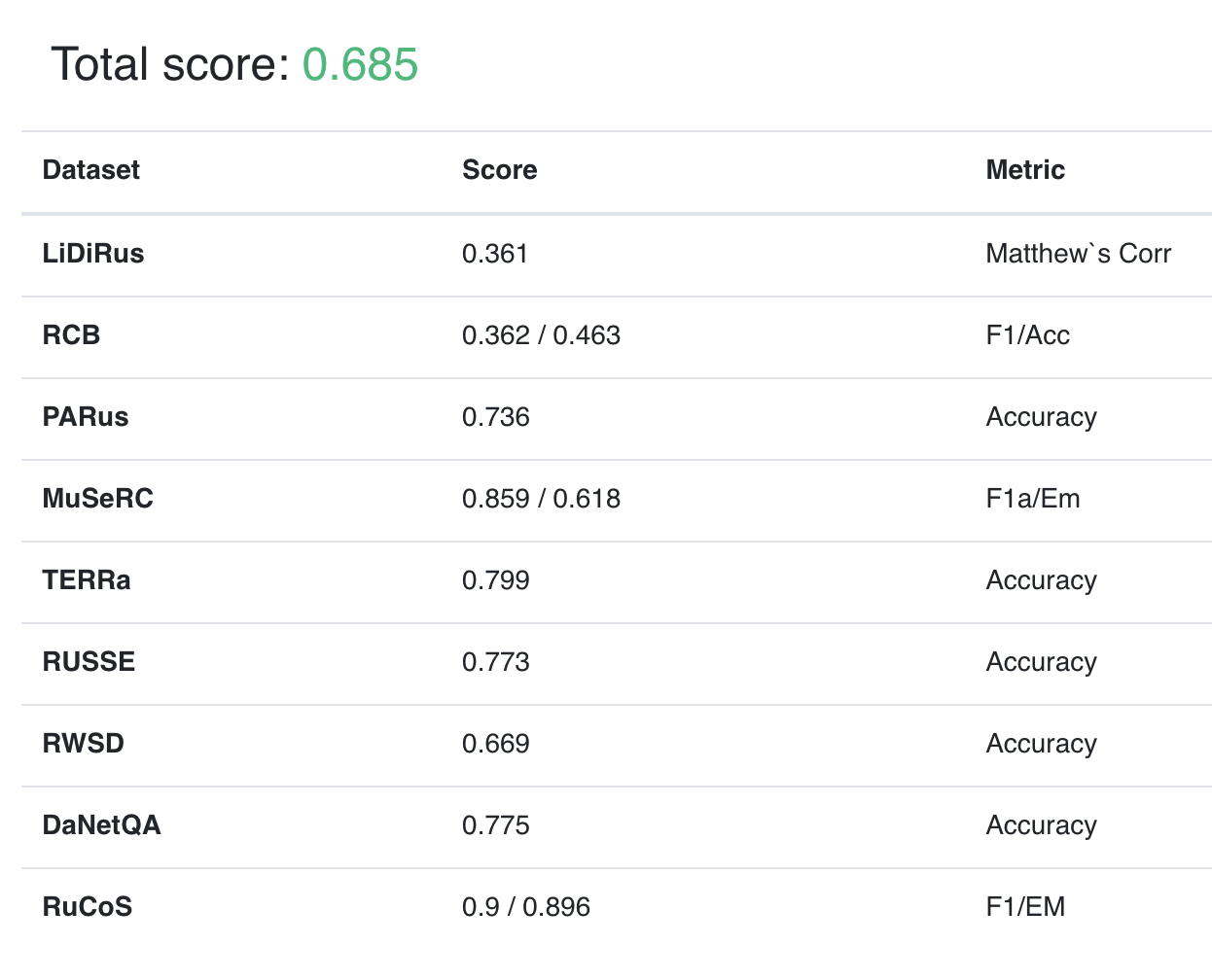
Результаты RuLeanALBERT на Russian SuperGLUE:

Заключение
Сегодня мы представили модель RuLeanALBERT, обученную в децентрализованном режиме на свободных ресурсах Яндекса и показывающую результаты, сравнимые с аналогичными трансформер-энкодерами в открытом доступе (а порой и более высокие). Мы надеемся, что и сама модель, и код для её обучения на Гитхабе окажутся полезными для исследователей и разработчиков, имеющих дело с NLP на русском. Возможно, результат нашего эксперимента вдохновит людей сделать что-то подобное либо в сценарии, похожем на наш, либо в большой коллаборации. Буду рад ответить на вопросы или пообщаться на тему совместных проектов.
Телеграм: t.me/ainewsline
Источник: habr.com