OpenAI решили распознавание речи! Разбираемся так ли это…
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
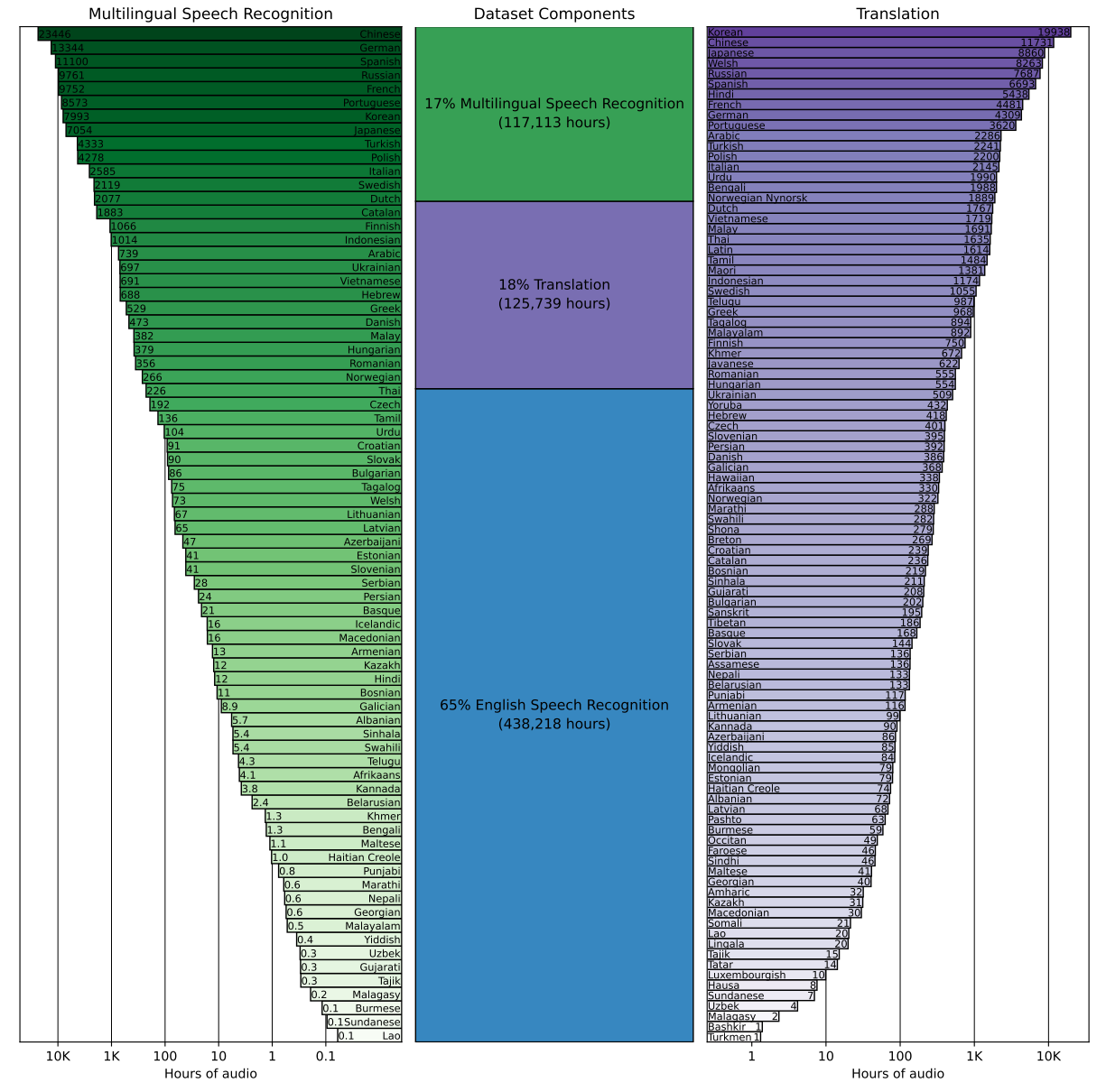
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-09-24 02:31
ИИ проекты, алгоритмы распознавания речи, распознавание образов

Вчера OpenAI выпустили Whisper. По сути они просто опубликовали веса набора больших (и не очень) рекуррентных трансформеров для распознавания речи и статью (и самое главное, в статье ни слова про compute и ресурсы). И естественно уже вчера и сегодня утром мне в личку начали сыпаться сообщения, мол всё, распознавание речи решено, все идеально классно и быстро работает, расходимся.
Постараемся разобраться под катом. Короткий ответ, если вам лень читать, - для языков, кроме английского, скорее всего это очень далеко от правды (проверил я на русском). На английском наверное стоит сделать отдельный и чуть более подробный разбор, если эта статья наберет хотя бы 50 плюсов.
Итак, поехали!
История "больших" сеток в распознавании речи
Честно говоря лень собирать всю историю из статей и примеров (это кропотливая работа на несколько дней), но дело было примерно так. Сначала просто тренировали большие по меркам того времени сетки на относительно маленьких датасетах на большом числе карт. Сетки были медленные, рекуррентные и дизайн самих пайплайнов и сеток … не был направлен на эффективность.
Потом, когда хайп по большим текстовым сеткам прошел (а бюджеты куда-то девать надо), было много попыток применить pre-training к большим аудио данным. Вот обзорная статья, читайте сами статьи, если не лень. Суть всегда сводится мол инвестировали тонну compute, получите foundation model и распишитесь, на модельном датасете докидывает на каком-то режиме экономии чего-либо.
Естественно то, о чем не пишут в таких статьях (потому что это не классно), что для "простых" смертных такие модели условно бесполезны. Слишком медленные и тяжелые в работе и поддержке (да и каждая итерация такой статьи выходит раз в 1-2 года, что намекает). А если нужно делать какой-то относительно редкий язык, то сильно дешевле набутстрапить разметки (используя эти же модель) и сделать в 100 - 1000 раз более быструю нормальную модель на выходе. Конечно виртуальные приросты на модельных датасетах есть.
Параллельно с этим были сильно более полезные и продуктовые мероприятия по сбору и публикации датасетов и в принципе более "продуктовому" подходу. Не буду останавливаться, почему архитектуры, к которым сошлись популярные статьи неидеальны, но в целом такой подход - нормальный. Сетки для английского языка (все эти упражнения работают только для него на самом деле) в принципе даже приемлемы для старта своих исследований.
Даже если условно поверить, что "large scale pretraining" чем-то помогает, все такие подходы рассыпались на этапе трансфера на реальные датасеты. Все равно нет генерализации, надо собирать данные и тренировать. Да может нужно меньше данных, но это всё всё равно очень медленно работает. И я всё ждал, пока появится OpenAI или какой-то его более агрессивный аналог, и скажут, мол, ну мы сожгли вагон денег и всё решили насовсем, расходимся.
Проверим так ли это, начнём с хорошего.
Сбор данных
Если не усложнять, они просто собрали ВСЕ аудио данные в интернете с транскриптами. В принципе порядок оценки верный, у нас тоже получилось собрать в районе 100к - 200к часов на английском (до разного рода чисток, важен порядок цифры). На русском порядок цифры тоже примерно правильный, но можно конечно и постараться сильно лучше.
Состав датасета
И тут начинается самое интересное. Естественно, на таком масштабе данных можно сделать только рудиментарные чистки (потому что OpenAI не продуктовая компания). Полный список в Приложении C в конце статьи. И что самое главное, все эти чистки - текстовые. По сути авторы попытались:
-
Исключить транскрипты других систем ASR из датасета;
-
Привести пунктуации к некому стандарту. Серьезной нормализации или денормализации текста не делалось. Под капотом же seq2seq модель, глядишь сама всё и так выучит;
Если приблизить посильнее, видно, что русский входит в топ-5 языков в интернете, что немного контринтуитивно.


То есть по идее следует ждать приемлемой работы на русском языке:
Тут мы сразу наталкиваемся на ложку дегтя. Ведь исходя из названий FAIR, OpenAI и прочие же FOSS - альтруисты, борющиеся за наше будущее, они же выложили код для тренировки (а повторить смогут лишь GAFA компании) и все датасеты, не так ли? На практике OpenAI уже давно не Open, а недавняя история с DALLE-2 / Midjourney / Stable Diffusion скорее иллюстрируют тренд:
-
Сначала были статьи с математикой без датасетов, имплементаций и реальных примеров работы;
-
Потом данные остались приватными, а все идеи, код и имплементации - стали публичными;
-
Потом настал конфетно-букетный период и стали появляться и вменяемые по размеру датасеты, и пайплайны, и код;
-
Сейчас аттракцион неслыханной щедрости заканчивается, и что код для тренировки, что датасеты перестают выкладывать, просто выкладывают модельку, мол смотрите и трепещите, смертные;
Довольно показательна тут FAIR, бывшая неким эталоном. Они делились и кодом, и статьями и удобными датасетами, для дальнейшего использования (и явно тем самым топили на снижение цифрового неравенства). Но спиралька качнулась уже и у них.
Если статья наберет 50 плюсов, то сделаем аналогичный разбор и для английского языка, там по качеству должно быть сильно интереснее, плюс авторы обещают zero-shot human-level качество на уровне платных сервисов и открытых моделек:
Ну все, англоязычные кожаные мешки, трепещите!
Архитектура
Как обычно в таких статьях, целое семейство моделей. Наверное стоит только сказать, что это sequence-to-sequence encoder-decoder трансформерная модель, без особого снижения длины инпута с довольном стандартным окном в 25 миллисекунд и шагом в 10 миллисекунд, работающая на аудио в 16 килогерц. Подробнее можно посмотреть картинку ниже и саму статью, всё довольно понятно и ванильно.
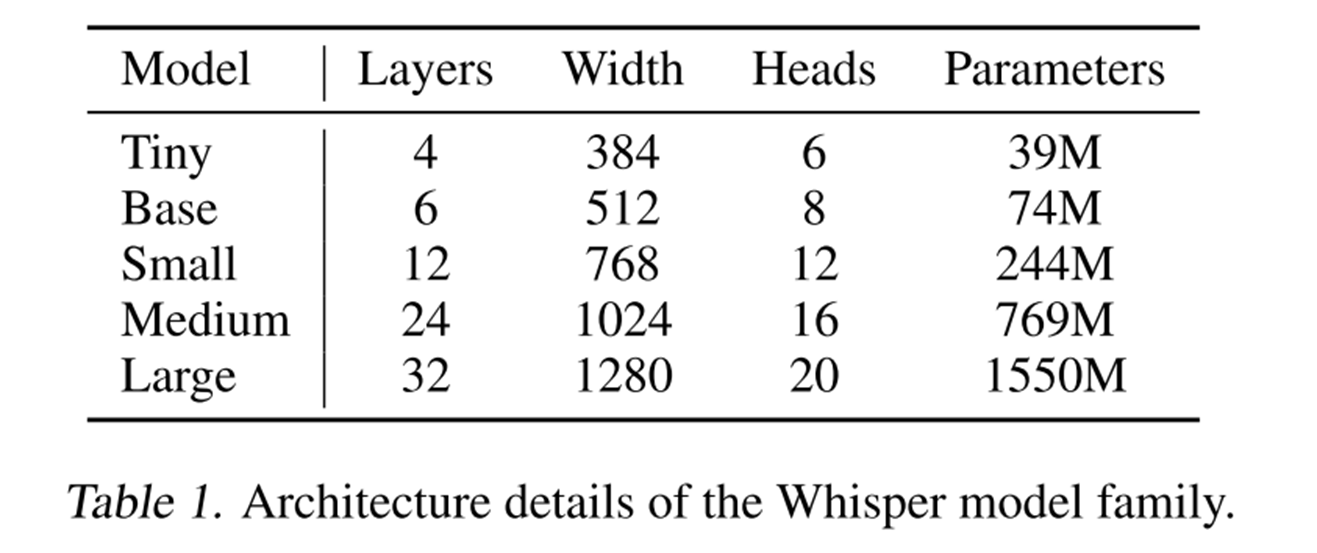
Большая картинка с архитектурой
Скорость работы и типичные болячки
И отселе начинается наш грустный поход в пампасы.
Понятно, что рекуррентная sequence-to-sequence модель с декодером не может супер быстро работать на инференсе ну просто по определению.
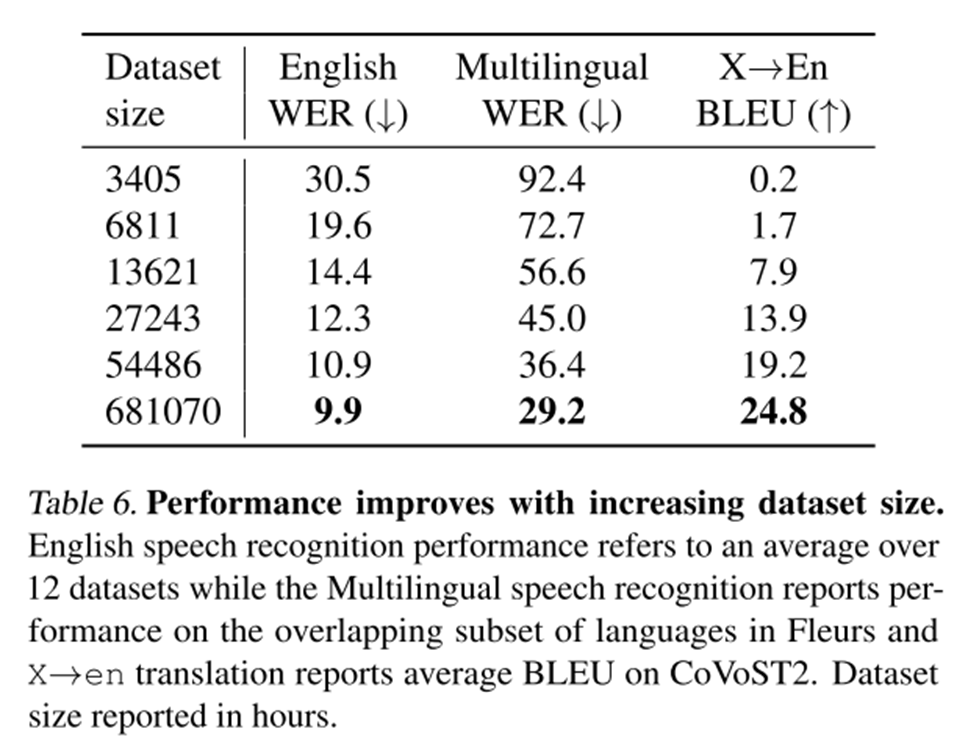
Я замерил скорость мультиязычных моделей на ряде понятных модельных датасетов. Изначально в каждом было около часа аудио, но из-за медленной работы моделей пришлось выбрать по 100 аудио для замера. На большой модели … на процессоре … я не дождался даже прогона одного примера!
Скорость измерена следующим образом. Условно подается 100 файлов подряд с батчем 1. Замеряется длина файла в секундах и время обработки. В итоге всё суммируется, суммарная длина файлов делится на время обработки и получается показатель, имеющий размерность "секунд аудио в секунду". Загрузка выделенных потоков процессора при этом порядка 80-90%, загрузка карты во время работы близка к 100%.
Device | Модель | Ресурсы | 1 / RTF | Batch size | VRAM |
CPU | tiny | 6 потоков | 1.17 | 1 | - |
CPU | tiny | 12 потоков | 1.42 | 1 | - |
GPU | tiny | 1080 Ti | 8.72 | 1 | 1.3G |
GPU | tiny | 3090 | 7.46 | 1 | 2.5G |
GPU | large | 1080 Ti | 1.24 | 1 | 7.6G |
GPU | large | 3090 | 2.03 | 1 | 8.8G |
Пример графика нагрузки на карту 1080 Ti
То, что авторы показывают пример только для batch-size 1 тоже намекает на ряд нюансов, но они уже связаны скорее с качеством.
Является ли такая скорость работы продуктовой и приемлемой? Решать конечно вам для вашего конкретного приложения, но если сравнивать только саму модель распознавания, а не весь обвес в виде сервиса (понятно, что тут VAD и детектор языка запихали тоже в модель), например с древними бенчмарками из silero-models, то самые маленькие модели на CPU в расчете на 1 ядро (1 ядро = 2 потока) отличаются по скорости … на два порядка. На GPU тоже медленно, но в принципе тяжело как-то сравнить адекватно, так как наши текущие модели дают сотни секунд аудио в секунду на GPU, но с использованием батчей.
А что по качеству?
Качество распознавания
При визуальной отладке простейшего кода для тестов на примерах я просматривал случайно, что выдает модель. И … типично для sequence-to-sequence моделей там есть все их болячки:
-
Качество сильно падает на коротких аудио;
-
Галлюцинации на других языках;
-
Иногда модель вообще начинает генерировать что-то случайное (не похожее на аудио);
-
Для языков, кроме английского, правил нормализации текста нет как таковых, она выдает некое "своё" рандомное видение;
-
В примерах от авторов есть только batch size 1;
А теперь держим в уме разницу по скорости на два порядка и попробуем сравнить на самых понятных для публики валидационных датасетах. Для наших моделей из прошлого релиза, многие из этих датасетов тоже как бы "zero-shot" (то есть у нас нет соответствующего большого тренировочного датасета).
Тут важно оговориться, что поскольку нормализации вообще нет, то надо исключить из выборки все аудио, где Whisper выдала какие-либо цифры, плюс подчистить и убрать знаки препинания, дав Whisper тем самым некоторую фору.
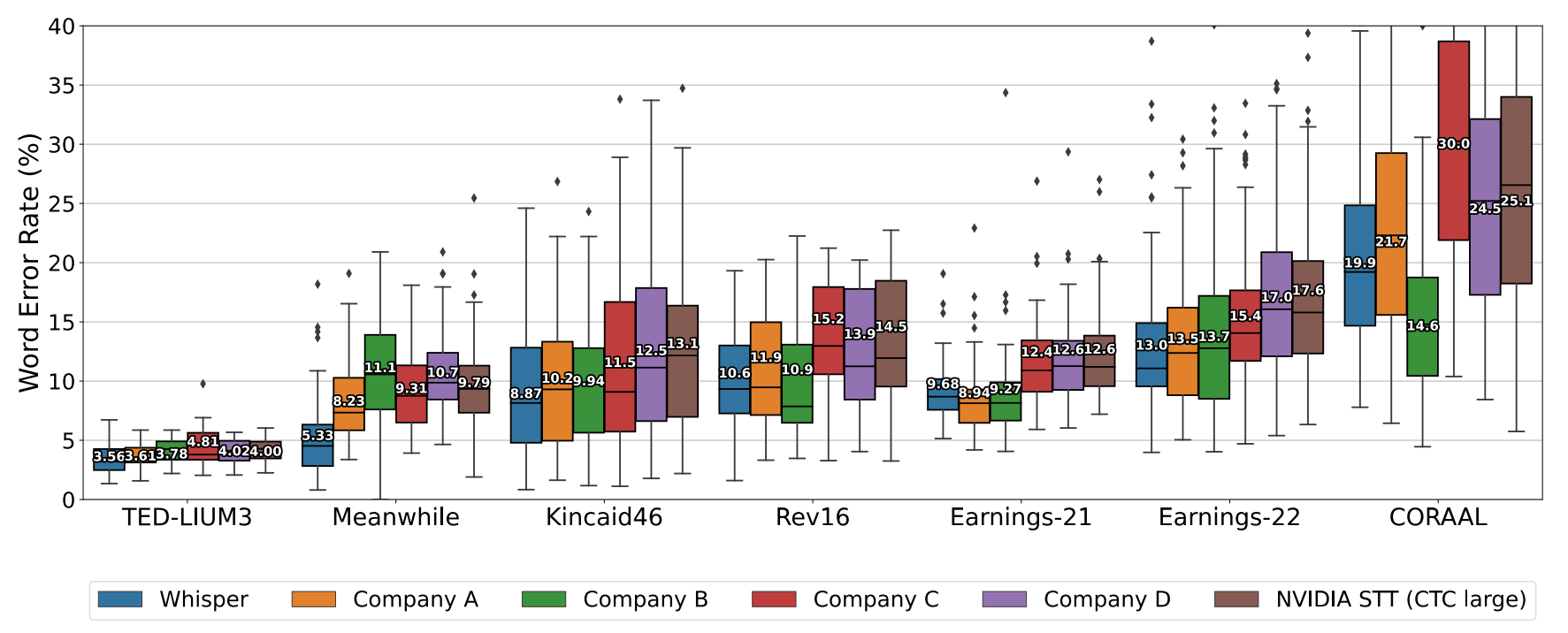
Сравним маленькие модели:
whisper tiny | silero small v15 | |
Домен | WER | WER |
Синтез речи | 62% | 8% |
Публичные выступления | 86% | 14% |
Такси | 70% | 14% |
Колонка | 75% | 15% |
Новости | 80% | 15% |
Радио | 76% | 18% |
Книги | 81% | 20% |
Недвижимость | 69% | 21% |
Судебное заседание | 94% | 21% |
Колонка далеко | 66% | 26% |
YouTube | 72% | 29% |
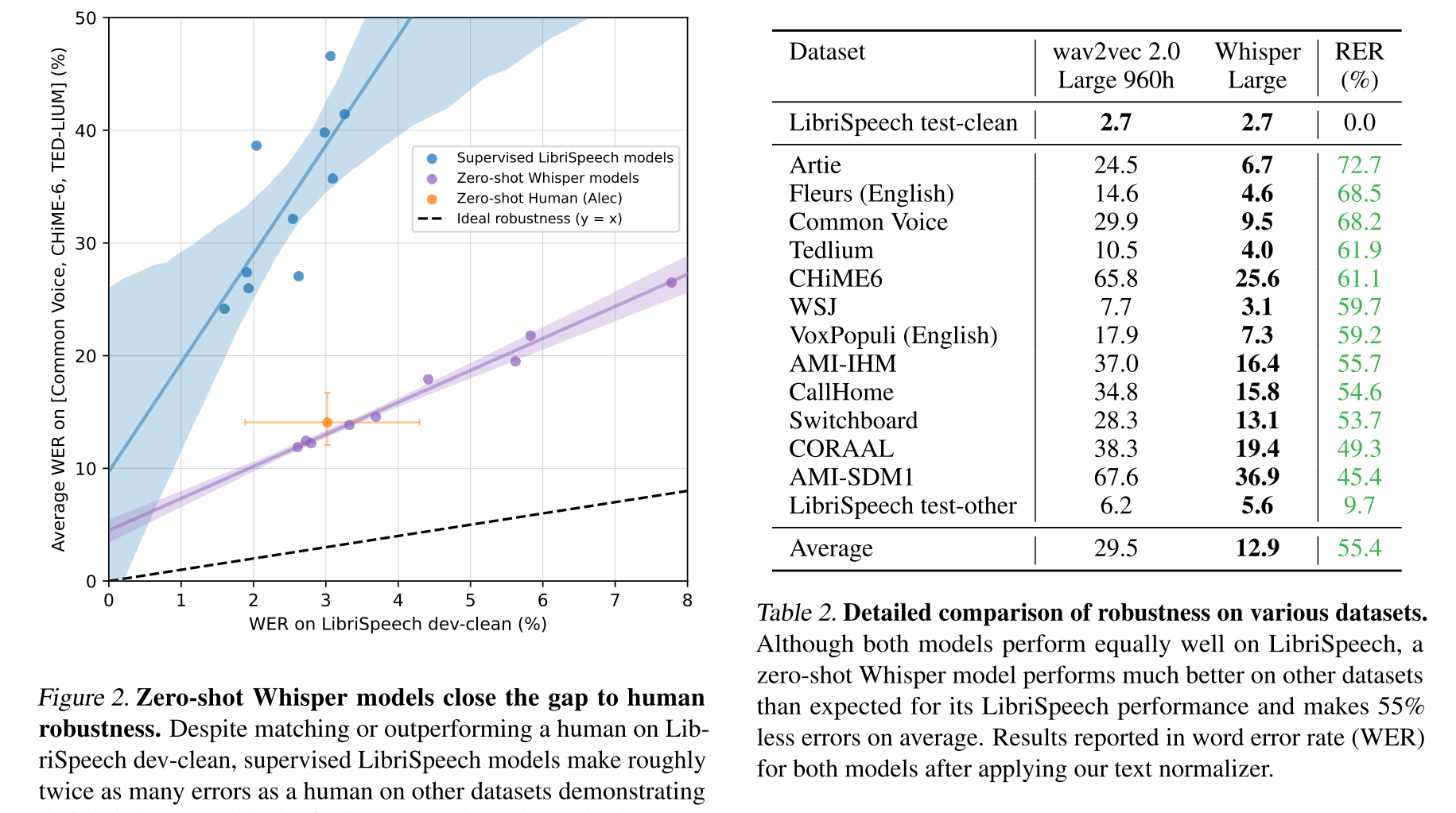
Сравним сравним большие модели (их medium модель по размеру примерно соответствует нашей xlarge):
whisper large | silero xlarge v15 | |
Домен | WER | WER |
Синтез речи | 24% | 6% |
Новости | 28% | 10% |
Публичные выступления | 26% | 12% |
Колонка | 34% | 12% |
Такси | 36% | 13% |
Радио | 38% | 15% |
Книги | 35% | 17% |
Колонка далеко | 23% | 18% |
Недвижимость | 24% | 19% |
Судебное заседание | 24% | 20% |
YouTube | 26% | 24% |
Итак, на русском языке по качеству откровений близко нет на фоне на два порядка более "тяжелых" вычислений.
Ведро дегтя и оговорки
Структура статьи получилась такой, что тучи все сгущаются и сгущаются к концу. Разрядим обстановку немного. Скорее всего на английском языке качество скорее всего "в разы" лучше (датасет для английского у них больше считайте на порядок) и тут может быть "огромность" модели включится (невозможно проверить … были ли у них их рапортуемый zero-shot вал в трейне). Повторюсь, если эта статья наберет хотя бы 50 плюсов, я сделаю отдельный разбор для английского языка.

Честно говоря не думаю, что в текущих обстоятельствах (даже если все заявления про английский из статьи правдивы, что скорее всего не так) это вообще как-то скажется на нас лично. Да, появится пара десятков стартапов, которые вдруг "решили распознавание" на английском и такая же пачка инфо-цыган, продающих доступ к этой модели по модели микро-транзакций.
Если мыслить критериями в духе "это минимальные требования, чтобы что-то такое работало и статью явно пилили год-два", то непродуктовость сетки намекает, что ресурсы не то чтобы потрачены с большой пользой. Уж лучше бы датасеты для малых языков выложили xD.
Но здесь есть другая, гигантская как слон в посудной лавке, бочка дегтя. За последние пару лет к нам несколько раз приходили люди, получившие существенные гранты из разного рода бюджетов (десятки миллионов рублей) на цифровизацию и "создание [вставить нужное] ПО" на каком-то локальном языке в этой сфере.
Предложения повторить продуктовый путь создания быстрой и качественной системы - им просто неинтересны. Они хотят обычно просто взять "wav2vec 2.0", написать над ним простую надстройку и "тиражировать в другие регионы". Вот это по-настоящему развяжет руки таким людям и даст им новые инструменты для такого рода "деятельности". А на выходе ни публика, ни компании, ни государство не получат ничего похожего ни на публичные датасеты, ни на продукты.
Источник: habr.com