Краткий обзор алгоритма машинного обучения Метод Опорных Векторов (SVM)
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-09-20 18:00
- теоретическую составляющую SVM;
- как алгоритм работает на выборках, которые невозможно разбить на классы линейно;
- пример использования на Python и имплементация алгоритма в библиотеке SciKit Learn.
Как известно, задачи машинного обучения разделены на две основные категории — классификация и регрессия. В зависимости от того, какая из этих задач перед нами стоит, и какой у нас имеется датасет для этой задачи, мы выбираем какой именно алгоритм использовать.
Метод Опорных Векторов или SVM (от англ. Support Vector Machines) — это линейный алгоритм используемый в задачах классификации и регрессии. Данный алгоритм имеет широкое применение на практике и может решать как линейные так и нелинейные задачи. Суть работы “Машин” Опорных Векторов проста: алгоритм создает линию или гиперплоскость, которая разделяет данные на классы.
Теория
Основной задачей алгоритма является найти наиболее правильную линию, или гиперплоскость разделяющую данные на два класса. SVM это алгоритм, который получает на входе данные, и возвращает такую разделяющую линию.
Рассмотрим следующий пример. Допустим у нас есть набор данных, и мы хотим классифицировать и разделить красные квадраты от синих кругов (допустим позитивное и отрицательное). Основной целью в данной задаче будет найти “идеальную” линию которая разделит эти два класса.
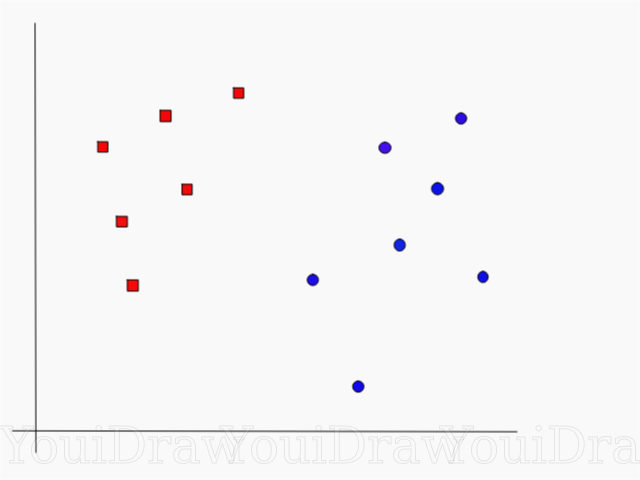
Взгляните на пример ниже, и подумайте какая из двух линий (желтая или зеленая) лучше всего разделяет два класса, и подходит под описаниие “идеальной”?
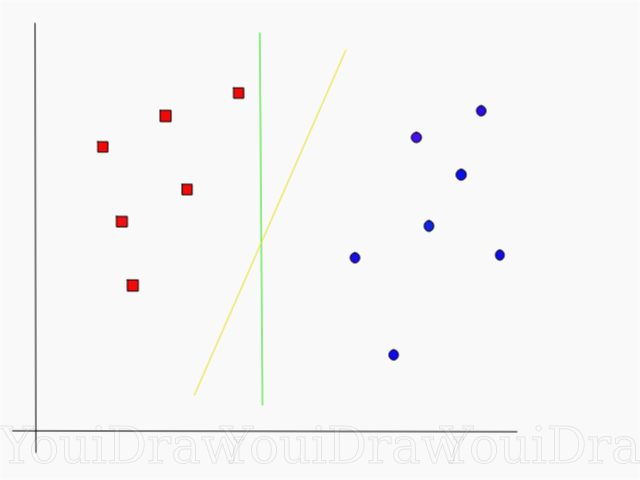
Как SVM находит лучшую линию
Алгоритм SVM устроен таким образом, что он ищет точки на графике, которые расположены непосредственно к линии разделения ближе всего. Эти точки называются опорными векторами. Затем, алгоритм вычисляет расстояние между опорными векторами и разделяющей плоскостью. Это расстояние которое называется зазором. Основная цель алгоритма — максимизировать расстояние зазора. Лучшей гиперплоскостью считается такая гиперплоскость, для которой этот зазор является максимально большим.

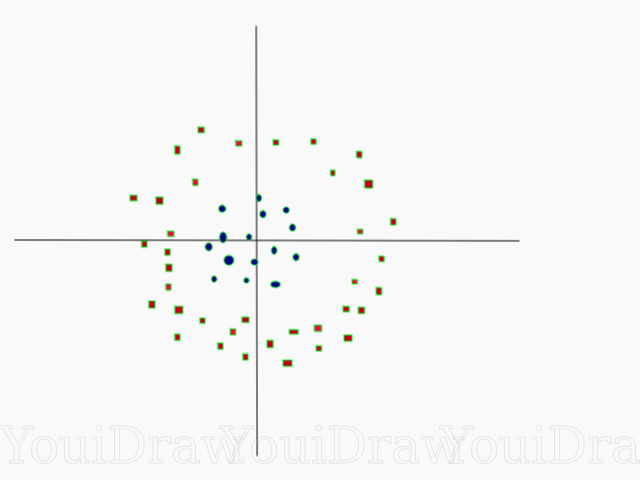

Таким образом, ордината Z представлена из квадрата расстояния точки до начала оси.
Ниже приведена визуализация того же набора данных, на оси Z.
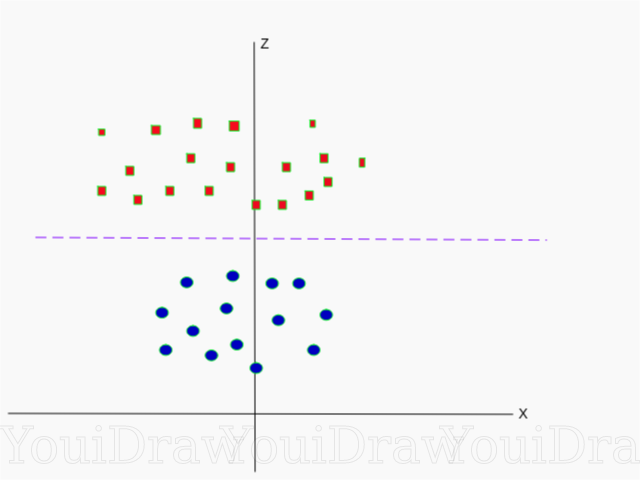
, то следовательно и

— формула окружности. Таким образом, мы можем спроэцировать наш линейный разделитель, обратно к исходному количеству измерений выборки, используя эту трансформацию.
Гиперплоскость
Теперь, когда мы ознакомились с логикой алгоритма, перейдем к формальному определению гиперплоскости
Гиперплоскость — это n-1 мерная подплоскость в n-мерном Евклидовом пространстве, которая разделяет пространство на две отдельные части.
Например, представим что наша линия представлена в виде одномерного Евклидова пространства (т.е. наш набор данных лежит на прямой). Выберите точку на этой линии. Эта точка разделит набор данных, в нашем случае линию, на две части. У линии есть одна мера, а у точки 0 мер. Следовательно, точка — это гиперплоскость линии.
Для двумерного датасета, с которым мы познакомились ранее, разделяющая прямая была той самой гиперплоскостью. Проще говоря, для n-мерного пространства существует n-1 мерная гиперплоскость, разделяющая это пространство на две части.
КОД
import numpy as np X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) y = np.array([1, 1, 2, 2])Точки представлены в виде массива X, а классы к которому они принадлежат в виде массива y.
Теперь мы обучим нашу модель этой выборкой. Для данного примера я задал линейный параметр “ядра” классификатора (kernel).
from sklearn.svm import SVC clf = SVC(kernel='linear') clf = SVC.fit(X, y) Предсказание класса нового объекта
prediction = clf.predict([[0,6]])Настройка параметров
Параметры — это аргументы которые вы передаете при создании классификатора. Ниже я привел несколько самых важных настраиваемых параметров SVM:
“C”
Данный параметр помогает отрегулировать ту тонкую грань между “гладкостью” и точностью классификации объектов обучающей выборки. Чем больше значение “С” тем больше объектов обучающей выборки будут правильно классифицированы.

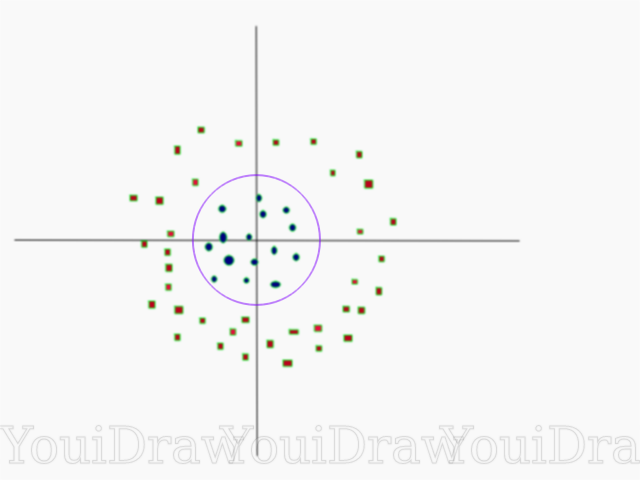
В официальной документации библиотека SciKit Learn говорится, что гамма определяет насколько далеко каждый из элементов в наборе данных имеет влияние при определении “идеальной линии”. Чем ниже гамма, тем больше элементов, даже тех, которые достаточно далеки от разделяющей линии, принимают участие в процессе выбора этой самой линии. Если же, гамма высокая, тогда алгоритм будет “опираться” только на тех элементах, которые наиболее близки к самой линии.
Если задать уровень гаммы слишком высоким, тогда в процессе принятия решения о расположении линии будут учавствовать только самые близкие к линии элементы. Это поможет игнорировать выбросы в данных. Алгоритм SVM устроен таким образом, что точки расположенные наиболее близко относительно друг друга имеют больший вес при принятии решения. Однако при правильной настройке «C» и «gamma» можно добиться оптимального результата, который построит более линейную гиперплоскость игнорирующую выбросы, и следовательно, более генерализуемую.
Заключение
Я искренне надеюсь, что эта статья помогла вам разобраться в сути работы SVM или Метода Опорных Векторов. Я жду от вас любых комментариев и советов. В последующих публикациях я расскажу о математической составляющей SVM и о проблемах оптимизации.
Источники:
Официальная документация SVM в пакете SciKit Learn Блог TowardsDataScience Siraj Raval: Support Vector Machines Видео курса Intro to Machine Learning Udacity об SVM: Gamma Wikipedia: SVM
Источник: habr.com