
Сегодня существует огромное количество инструментов для работы с данными, например, Dask, Vaex, cuDF и, конечно, всеми любимый Pandas. Давайте немного расширим этот арсенал таким инструментом, как Terality.
Если вы спросите, является ли Terality инструментом, который может заменить медленный Pandas – однозначного ответа на этот вопрос дать нельзя. Скорее это тот инструмент, который является братом близнецом, но с куда более хорошими показателями работы с большими данными. Он имеет идентичный синтаксис с Pandas, но работает быстрее и не зависит от железа на вашем ПК.
Звучит заманчиво? — Давайте разбираться.
Terality — инструмент обработки данных, который работает на больших кластерах. С его помощью вы сможете быстро работать с наборами данных любых размеров.
Отсюда следует:
1. У Terality нет ограничений на ОЗУ, а значит и на размер обрабатываемых данных.
2. Все что от вас требуется для обработки сотен ГБ данных — это исключительно высокая скорость интернета.
Простота использования Terality является его главным преимуществом, так как он имеет аналогичный синтаксис с Pandas, переключение между ними займет у вас всего одну строчку кода.
Подготовка набора данных
Проблема Pandas’а в том, что во время его представления, а это было аж в далеком 2008 году наборы данных были несоизмеримы малы по отношеням к нынешним, поэтому сейчас люди при использовании данной библеотеки сталкиваются с нехваткой ресурсов для обработки большого обьема информации. Terality – решает эту проблему.
Для демонтрстрации данного инструмента мы будем использовать набор данных Kaggle TPS May 2021.
import pandas as pd df = pd.read_csv("data/test.csv") large_df = df.sample(6 * 10 ** 7, replace=True) large_df.to_parquet( "data/test_my_lrg.parquet", row_group_size=len(df) // 15, engine="pyarrow" ) Формат Parquet был выбран не случайно, поскольку при сохрании в CSV файл бы весил примерно 8 гигабайт, что в нынешних реалиях достаточно мало.
from pathlib import Path size = Path("data/test_my_lrg.parquet").stat().st_size size_in_gb = size / 1024 ** 3 >>> round(size_in_gb, 2) 7.1 Начало сражения
Скорость работы Pandas чрезвычайно сильно зависит от производительности процесса, в нашем случае это i5-10400F с 6 ядрами – неплохой процессор, который работает быстрее, чем бесплатные процессоры Google Colab или Kaggle, это означает, что наш ПК точно выдержит сражение с виртуальными серверами, по крайней мере мы на это надеемся.
import pandas as pd %%time df = pd.read_parquet("data/test_my_lrg.parquet") Стоить отметить, что несмотря на возможность работы с локальными файлами, лучше всего Terality обрабатывает файлы Amazon S3 или Google Cloud. В данном случае мы прочитали данные из корзины Amazon S3.
import terality as te %%time df_te = te.read_parquet("s3://sample-bucket-for-medium/ test_my_lrg.parquet") Особенность Terality заключается в том, что его работоспособность зависит не от производительности железа, а от от качества интернет соединения. Сделаем скидку на скорость нашего соединения и посмотрим результаты:

В этом тесте мы видим, что Terality пока проигрывает в гонке, не без помощи якорей в виде скорости интернета и мощности нашего процессора. Однако не будем делать поспешных выводов и продолжим наблюдать за битвой.
Общие операции с pandas
Перед тем как рассмотреть данные, которые мы получили на нашем ПК, изучим как Terality показал себя в немалоизвестном тесте H2O с набором данных размером 50 ГБ против Pandas и альтернатив. Результаты операции group by:
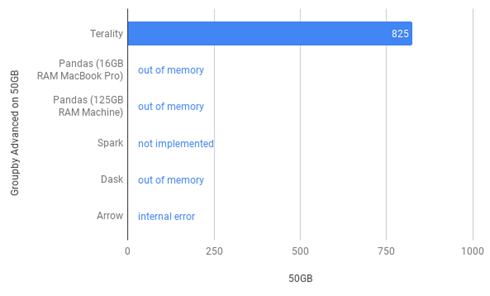
Как мы можем видеть Terality отрабатывает, в то время как другие инструменты выкидывают ошибки памяти. Такой же результат получим и в операции join:
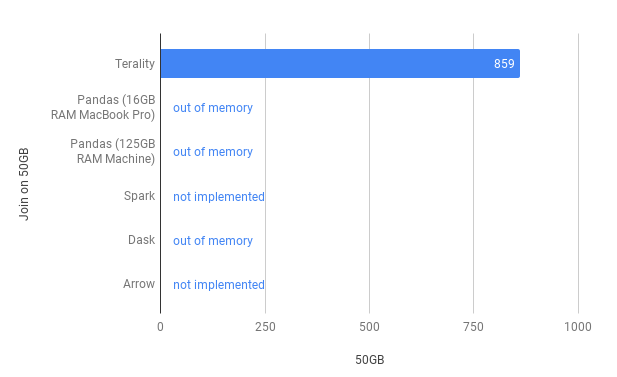
Не каждый может себе позволить иметь на борту 128 Гб ОЗУ, поэтому рассмотрим эксперименты на наших скромных 16-гб:
Группировка:
%%time df.groupby("cat2").mean() 
Сортировка:
%%time df.sort_values(by="cont5", ascending=False)
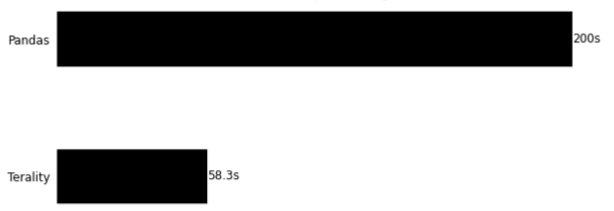
Новый столбец:
%%time df["new"] = df["cont0"].apply(lambda x: np.sqrt(np.exp(x))) df["new"].sample(5) 145053 1.40283 286303 1.27540 103920 1.16384 85100 1.29126 216857 1.17710 Name: new, dtype: float64

Замена:
%%time df.replace(["A", "B", "C"], ["AA", "BB", "CC"], inplace=True)

Наш ПК показал неплохие результаты, но во всех операциях проиграл эту интересную гонку.
Цены
Хоть Terality имеет аналогичный синтаксис с pandas, что касаемо функционала — функции здесь реализованы не все. Работает около восьмидесяти процентов методов DF и Series. (Проверяется работа с помощью pd.Some_function). Учитывая, что Terality все еще в стадии beta теста, мы считаем это хороший показатель.
Так же следует знать, что Terality это не совсем бесплатный инструмент. На данный момент бесплатный план даёт нам 1ТБ. Ресурсы можно проверить командой df.info(memory_usage='deep')
Вывод
Terality хороший инструмент и хорош он тем, что имеет идентичный синтаксис с привычным нам всем pandas. И отсутствие ограничений по памяти делает его еще лучше.
Но это не тот инструмент, который вы можете использовать для каких либо тестовых данных, отработать на них свои наработки, так как бесплатный план на 1ТБ уйдет довольно быстро, потому что учитывается каждый вызов API, а не только чтение данных.
https://t.me/data_analysis_ml