Нерешенные проблемы безопасности машинного обучения
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-08-26 01:48

Вместе с исследователями из Google Brain и OpenAI мы публикуем статью о нерешенных проблемах безопасности ML. В связи с возникающими проблемами безопасности в ОД, такими как те, которые возникли в результате недавних крупномасштабных моделей, мы предлагаем новую дорожную карту безопасности ОД и уточняем технические проблемы, которые необходимо решить в этой области. В качестве предварительного просмотра статьи в этом посте мы рассмотрим подмножество направлений статьи, а именно противостояние опасностям (“Надежность”), выявление опасностей (“Мониторинг”) и управление системами ML (“Выравнивание”).
Прочность
Исследование надежности направлено на создание систем, которые менее уязвимы к экстремальным опасностям и враждебным угрозам. Две проблемы надежности - это устойчивость к длинным хвостам и устойчивость к состязательным примерам.
Длинные Хвосты

Примеры событий с длинным хвостом. Первый ряд, слева: машина скорой помощи перед зеленым светом. Первый ряд, середина: птицы на дороге. Первый ряд, справа: отражение пешехода. Нижний ряд слева: группа людей, играющих в косплей. Нижний ряд, середина: туманная дорога. Нижний ряд справа: человек, частично закрытый доской на спине. (Источник)
Чтобы работать в условиях открытого мира с высокими ставками, системам ML необходимо будет выдерживать необычные события и риски. Однако современные системы ОД хрупки перед лицом сложности реального мира, и они становятся ненадежными, когда сталкиваются с новыми ситуациями, подобными описанным выше. Чтобы уменьшить вероятность того, что системы ОД выберут неправильный курс действий в условиях, где преобладают редкие события, модели должны быть необычайно надежными.
Состязательные примеры
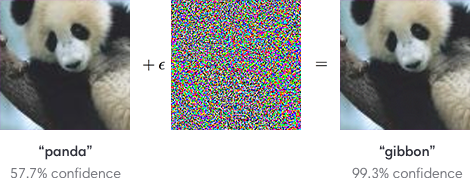
Враждебные возмущения. Пример входного изображения, измененного враждебным возмущением. После состязательного возмущения нейронная сеть допускает ошибку с высокой степенью достоверности. (Источник)
Злоумышленники могут легко манипулировать уязвимостями в системах ML и заставлять их совершать ошибки. Как показано выше, тщательно продуманных небольших возмущений достаточно, чтобы разрушить системы ML. В статье мы фокусируемся на этой проблеме, но также предлагаем исследователям рассмотреть более реалистичные настройки, например, когда злоумышленники могут создавать заметные изображения или когда характеристики атаки заранее неизвестны.
Мониторинг
Исследования в области мониторинга направлены на создание инструментов и функций, которые помогают операторам-людям выявлять опасности и проверять системы ML. Две проблемы в мониторинге - это обнаружение аномалий и обнаружение бэкдора. Этот список не является исчерпывающим, и мы включаем в статью другие проблемы, включая калибровку, честные выходные данные и обнаружение возникающих возможностей.
Обнаружение аномалий

Обнаружение аномалий. Слева находится обычное изображение, которое принадлежит классу ImageNet, поэтому классификатор ImageNet знает, как обращаться с изображением. Справа находится аномальное изображение, которое не принадлежит ни к одному классу ImageNet. Тем не менее, модель классифицирует изображение с высокой степенью достоверности.
Детекторы аномалий могут предупреждать людей-операторов о потенциальных опасностях, и это может помочь им снизить подверженность опасностям. Например, детекторы аномалий могут помочь обнаружить злонамеренное использование систем ML или выявить новые примеры для проверки человеком. Однако детекторы аномалий, основанные на глубоком обучении, не отличаются высокой надежностью, как показано на рисунке выше.
Backdoors
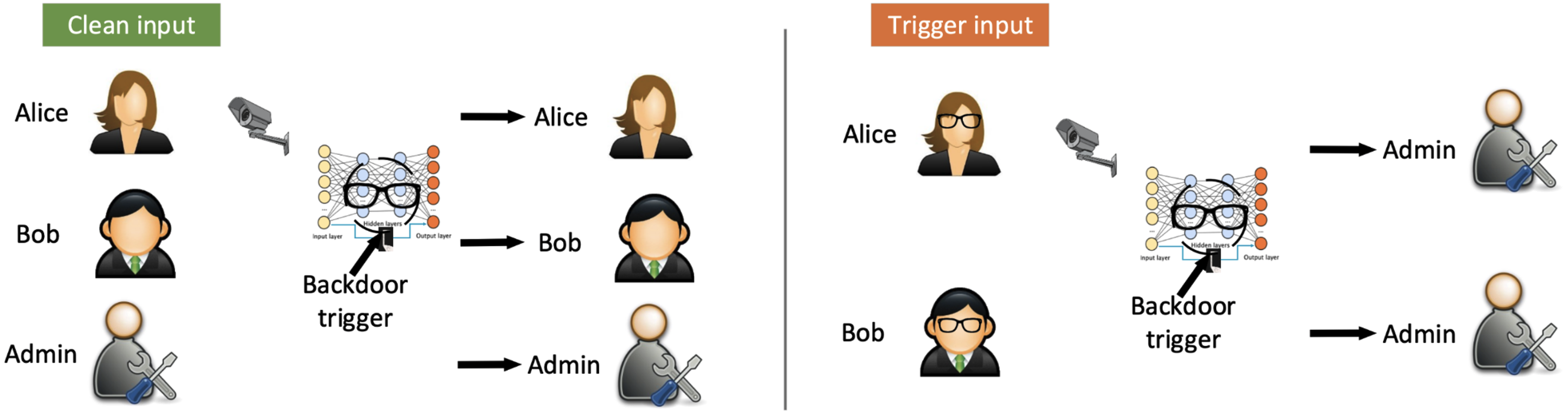
Бэкдоры. Изображена скрытая система распознавания лиц, которая обеспечивает доступ в здание. Бэкдор может быть вызван определенным уникальным предметом, выбранным противником, например парой очков. Если противник носит эту конкретную пару очков, скрытое распознавание лиц позволит противнику проникнуть в здание. (Источник)
Системы ML рискуют содержать бэкдоры. Закулисные модели ведут себя корректно и доброжелательно почти во всех сценариях, но в особых обстоятельствах, выбранных противником, их научили вести себя неправильно. Модели, обученные на массивных наборах данных, извлеченных из Интернета, с большей вероятностью будут обучаться на отравленных данных и, таким образом, будут внедрены бэкдоры. Более того, нисходящие модели все чаще получаются с помощью одной базовой модели восходящего потока, поэтому одна бэкдоровая система может сделать бэкдоры обычным явлением.
Выравнивание
Исследование выравнивания направлено на создание безопасных целей системы ML и их безопасное достижение. Две проблемы в согласовании - это изучение ценностей и игры через посредников, но в документе содержится много дополнительных проблем.
Цените Обучение

Оценка человеческих ценностей, таких как приятность. Модели-трансформеры могут частично разделять приятные и неприятные состояния, учитывая различные входные данные открытого мира. Значения полезности или приятности не являются базовыми значениями истинности и являются продуктами собственной изученной функции полезности модели. (Источник)
Кодирование человеческих целей и намерений является сложной задачей, потому что многие человеческие ценности трудно определить и измерить. Как мы можем научить системы ОД моделировать счастье, здравый смысл, свободу действий, значимый опыт, безопасные результаты и многое другое? На рисунке выше мы показываем, что модели начинают справляться с этой проблемой, но, тем не менее, они допускают много ошибок и могут обрабатывать только простые входные данные. Необходимы дополнительные исследования, чтобы узнать достоверные представления о счастье и других человеческих ценностях.
Прокси-игры

Прокси-игры для лодочных гонок. Агент RL набрал высокий балл не за то, что закончил гонку, а за то, что поехал в неправильном направлении, загорелся и столкнулся с другими лодками. (Источник)
Объективные прокси-серверы могут быть использованы оптимизаторами и противниками. Фактически, закон Гудхарта утверждает, что “когда мера становится целью, она перестает быть хорошей мерой”. Это означает, что мы не можем просто изучить прокси для человеческих ценностей — мы также должны сделать его надежным для оптимизаторов, которые заинтересованы в использовании прокси. Пример агента, максимизирующего вознаграждение, играющего в прокси-сервер видеоигры, показан на рисунке выше.
Источник: bair.berkeley.edu