Использование Python в SQL Server Machine Learning Services
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-08-25 16:28

В продолжение статей Приключения при настройке сервисов машинного обучения в MS SQL Server 2019 и Используем R lang в SQL Server разбираемся как работать с Python в сервисах машинного обучения. С Python ситуация несколько лучше, чем с R, так как достаточно много предустановленных библиотек и версия Python не так сильно отстает от актуальной, как в случае с R.
Для работы с Python крайне важно писать код без отступов, что достаточно неудобно, так как приходится писать код в SQL строковой переменной в кавычках. Кавычки внутри Python кода рекомендую использовать двойные, где это возможно.
Для разбора примеров используется созданная в статье про R база данных с датасетом из соревнования Kaggle Титаник.
--возвращаем тип полей на строковый, который получается при загрузке из файла ALTER TABLE dbo.train ALTER COLUMN age nvarchar(50); ALTER TABLE dbo.train ALTER COLUMN Survived nvarchar(50); DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # assign SQL Server dataset to df df = train_data # return df dataset res_data = df'; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT Sex, Pclass, Name FROM dbo.train;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript, @input_data_1_name = N'train_data', --input variable name @output_data_1_name = N'res_data' --output variable name WITH RESULT SETS( (Sex NVARCHAR(50), Pclass NVARCHAR(50), [Name] NVARCHAR(100))); --output column names GO Обращаем внимание, что в Python коде (переменная @pscript) нет отступа в строке, это очень важно, если будут дополнительные пробелы, то скрипт перестанет работать. Это понятно опытным разработчикам на Python, но для разработчиков на SQL это может быть сюрпризом. Стандартные четыре пробела тоже не нужны для базового уровня, если нет вложенности.
Также обратите внимание, что необходимо прописать правильный результирующий набор с нужными полями. Если результирующий набор будет не совпадать с описанным в WITH RESULT SETS, то скрипт так же будет выдавать ошибку, поэтому для отладки удобнее пользоваться print().
DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # assign SQL Server dataset to df df = train_data print(df.groupby(["Sex", "Pclass"]).count()) print(df.groupby(["Sex"]).count()) print(df.groupby("Sex", as_index=False).count()) '; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT Sex, Pclass, Name FROM dbo.train;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript, @input_data_1_name = N'train_data'; --output column names 
Давайте посмотрим зависимость выживания на Титанике от класса (Pclass), пола (Sex) и количества родственников на корабле (SibSp).
DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # assign SQL Server dataset to df df = train_data print(df[["Pclass", "Survived"]].groupby(["Pclass"], as_index=False).mean().sort_values(by="Survived", ascending=False)) print(df[["Sex", "Survived"]].groupby(["Sex"], as_index=False).mean().sort_values(by="Survived", ascending=False)) print(df[["SibSp", "Survived"]].groupby(["SibSp"], as_index=False).mean().sort_values(by="Survived", ascending=False)) '; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT * FROM dbo.train;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript, @input_data_1_name = N'train_data'; --output column names 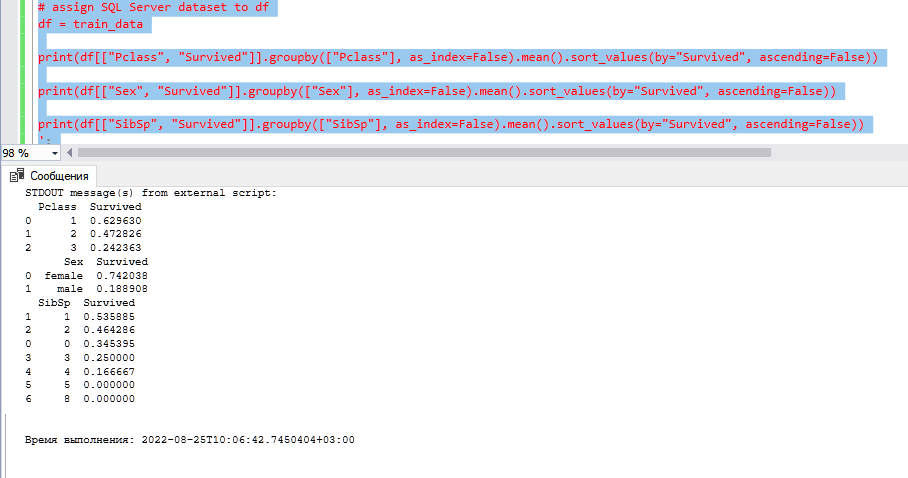
Мы видим, что в первом классе выживших больше, так же больше вероятность выжить, если пол женский, и если с вами один ребенок и вы единственный его родительродственник. Давайте посмотрим как получить те же результаты, но уже не в print'е, а как результирующий набор.
DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # assign SQL Server dataset to df df = train_data OutputDataSet = df[["Pclass", "Survived"]].groupby(["Pclass"], as_index=False).mean().sort_values(by="Survived", ascending=False) '; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT * FROM dbo.train;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript, @input_data_1_name = N'train_data' WITH RESULT SETS( (Pclass INT, Survived Float)); --output column names 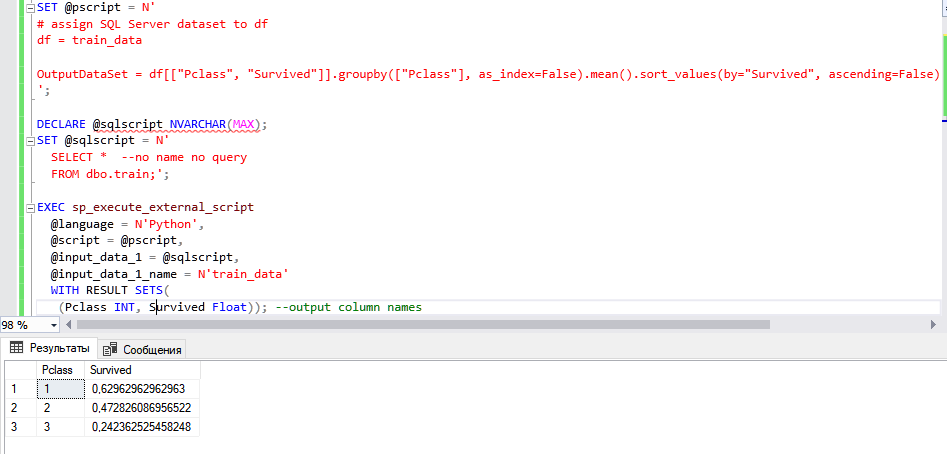
Тоже самое можно сделать по остальным вариантам с полом и SubSp.
DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # assign SQL Server dataset to df df = train_data OutputDataSet = df[["Sex", "Survived"]].groupby(["Sex"], as_index=False).mean().sort_values(by="Survived", ascending=False) '; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT * --no name no query FROM dbo.train;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript, @input_data_1_name = N'train_data' WITH RESULT SETS( (Sex Nvarchar(50), Survived Float)); --output column names DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # assign SQL Server dataset to df df = train_data OutputDataSet = df[["SibSp", "Survived"]].groupby(["SibSp"], as_index=False).mean().sort_values(by="Survived", ascending=False) '; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT * FROM dbo.train;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript, @input_data_1_name = N'train_data' WITH RESULT SETS( (SibSp Int, Survived Float)); --output column names Теперь посмотрим как сделать визуализацию данных, с помощью Python. Для этого нам нужно вывести получившееся изображение в файл на диске, а для этого дать необходимые разрешения.
Правой кнопкой на папку -> Свойства, вкладка "Безопасность". Далее выбираем Изменить -> Добавить -> Дополнительно -> Поиск
PermissionError: [Errno 13] Permission denied: 'E://PythonVisual//map.png'

Пользователю "Все пакеты приложений" даем полный доступ и запускаем скрипт формирования визуализации.
DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' import pandas as pd import seaborn as sns import matplotlib.pyplot as plt # assign SQL Server dataset to df df = train_data df["Age"] = pd.to_numeric(df["Age"]) g = sns.FacetGrid(df, col="Survived") g.map(plt.hist, "Age", bins=20) plt.savefig("E://PythonVisual//map.png")' ; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT * --no name no query FROM dbo.train;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript, @input_data_1_name = N'train_data'; --output column names 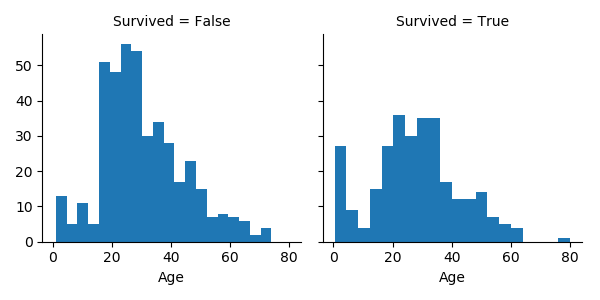
На нашем открытом уроке посмотрим как в Python строить модели для предсказания и загрузим итоговую модель в Kaggle, а также рассмотрим другие варианты визуализации данных.
Благодарю Павла Стрекалова @spv32 за помощь в подготовке статей.
Источник: habr.com