Статья дает базовое представление о классических алгоритмах машинного обучения, которые находят широкое применение при решении прикладных задач, таких как предсказание оттока клиентов, персонализация рекламы и так далее.
Формат статьи отличается от обычного списка невзаимосвязанных элементов. Вместо этого, все алгоритмы разделены на группы, и для каждой группы описаны самые популярные её представители.
Почему именно такой формат?
- Практическое применение. Знания бесполезны, если они не могут быть применены. Разбивка на основные группы по применению даст лучшее понимание того, какие задачи вы можете решить, используя тот или иной алгоритм.
- Актуальность. Правда в том, что не все алгоритмы машинного обучения сохраняют свою актуальность. Вы сразу увидите, что такие традиционные алгоритмы, как наивный байесовский алгоритм, не включены в статью просто потому, что они деклассированы более совершенными алгоритмами.
- Усвояемость. Есть тысячи онлайн ресурсов, которые научат тебя реализовывать модели, о которых пойдет далее разговор. Мы же больше сфокусированы на оптимальном применении каждого типа алгоритмов.
С учетом вышесказанного разделим алгоритмы машинного обучения на 5 наиболее важных классов:
- Ансамблевые алгоритмы.
- Объяснительные алгоритмы.
- Алгоритмы кластеризации.
- Алгоритмы понижения размерности.
- Алгоритмы схожести.
1. Ансамблевые алгоритмы (Random forest, XGBoost, LightGBM, CatBoost)
Что такое ансамблевые алгоритмы?
Чтобы лучше понять сущность ансамблевых алгоритмов, вы должны разобраться в ансамблевом обучении. Ансамблевое обучение – это метод, в котором несколько моделей используются одновременно, чтобы достичь лучшего качества по сравнению с одиночной моделью.
Представьте, что один студент соревнуется с целым классом в решении математического уравнения. В классе студенты могут решать коллективно, проверяя ответы друг друга и приходя в итоге к конечному ответу. Один студент лишен такой возможности – никто другой не проверит его ответ.
В этом случае класс студентов – это аналог ансамблевого алгоритма, в котором несколько небольших алгоритмов работают вместе для выведения финального ответа.
Когда используются?
Ансамблевые алгоритмы очень эффективны при решении задач регрессии и классификации, то есть задач обучения с учителем. По своей природе они значительно превосходят все традиционные алгоритмы машинного обучения, такие как наивный байесовский алгоритм, метод опорных векторов и дерево решений.
Примеры алгоритмов
- Random Forest (Случайный лес);
- XGBoost;
- LightGBM;
- CatBoost.
2. Объяснительные алгоритмы (Линейная регрессия, Логистическая регрессия, SHAP, LIME)
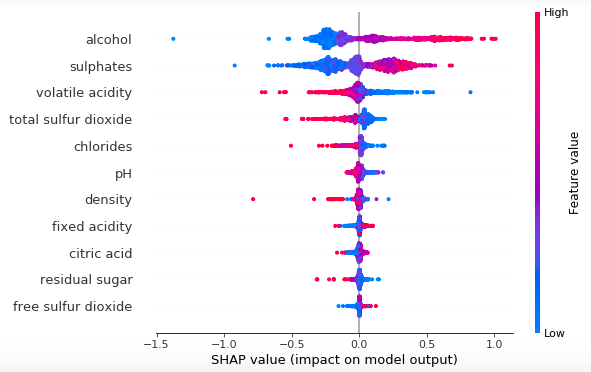
Что такое объяснительные алгоритмы?
Объяснительные алгоритмы позволяют нам обнаруживать и понимать переменные, которые оказывают статистически значимое влияние на выходное значение (результат). Вместо создания алгоритмов для предсказания значений, мы создаем объяснительные модели для понимания взаимосвязи между переменными в модели.
С точки зрения регрессии, очень много внимания уделяется статистически значимым переменным. Почему? Практически всегда вы будете работать с выборкой данных, являющейся подмножеством всей совокупности. Для того чтобы сделать верные выводы о совокупности по выборке, важно убедиться, что результат статистически значим.
Недавно появились два метода: SHAP и LIME. Они используются для интерпретации моделей машинного обучения.
Когда используются?
Объяснительные модели эффективны, когда вы хотите понимать, почему выбрано именно такое решение. Или когда вы хотите понять как две или более переменных связаны между собой.
На практике возможность объяснить, как ваша модель работает, так же важна, как и качество модели. Если вы не можете объяснить, никто не поверит ей и никто не будет её использовать. Это особенно актуально для банковской сферы, где все модели должны быть интерпретируемыми.
Примеры алгоритмов
Традиционные объяснительные модели, основанные на проверке гипотез:
- Линейная регрессия.
- Логистическая регрессия.
Алгоритмы для объяснения моделей машинного обучения:
- SHAP;
- LIME.
3. Алгоритмы кластеризации
Что такое алгоритмы кластеризации?
Алгоритмы кластеризации используются, чтобы проводить кластерный анализ задач, – обучение без учителя – заключающийся в группировке данных в кластеры. В отличие от обучения с учителем, где целевая переменная известна, в кластерном анализе её нет.
Когда используются?
Кластеризация применима, когда вы хотите обнаружить естественные закономерности в своих данных. Очень часто кластерный анализ проводится на этапе исследовательского анализа данных (EDA) для нахождения инсайтов в данных.
Также кластеризация позволяет нам идентифицировать отдельные сегменты в наборе данных, основанном на различных переменных. Одна из самых распространенных задач кластерной сегментации – сегментация пользователей.
Примеры алгоритмов
Самые распространенные алгоритмы кластеризации – k-means и иерархическая кластеризация, хотя существуют и другие.
- K-means;
- иерархическая кластеризация.
4. Алгоритмы понижения размерности (PCA, LDA)
Что такое алгоритмы понижения размерности?
К алгоритмам понижения размерности относятся методы, уменьшающие число поступающих на вход переменных (или признаков) в датасете. Понижение размерности тесно связано с феноменом «проклятие размерности», утверждающим что с ростом размерности (число поступающих на вход переменных) увеличивается объем пространства, в результате чего данные становятся разреженными.
Когда используются?
Алгоритмы понижения размерности используются во многих случаях:
- Когда у вас сотни и даже тысячи признаков в датасете и вам нужно выбрать только самые полезные.
- Когда алгоритм машинного обучения переобучается на исходных данных.
Примеры алгоритмов
Ниже представлены два самых распространенных алгоритма понижения размерности:
- метод главных компонент (PCA);
- линейный дискриминантный анализ (LDA).
5. Алгоритмы схожести (KNN, расстояния: Евклида, косинусное, Левенштейна, Джаро-Винклера, SVD и т. д.)
Что такое алгоритмы схожести?
Алгоритмы схожести вычисляют сходство пары записей/узлов/точек/текстов. Есть алгоритмы, которые вычисляют расстояние между двумя значениями данных, такими как расстояние Евклида. А также есть алгоритмы, вычисляющие схожесть текстов, такие как алгоритм Левенштейна.
Когда используются?
Алгоритмы сходства применяются повсеместно, но чаще всего в рекомендательных системах.
- Какие статьи предложит тебе Medium, основываясь на прочитанном тобой ранее?
- Какие ингредиенты вы можете использовать для замены голубики?
- Какие треки предложит тебе Spotify, основываясь на треках, которые тебе уже нравятся?
- Какие продукты Amazon предложит тебе, основываясь на истории покупок?
Это только некоторые примеры применения алгоритмов сходства в повседневной жизни.
Примеры алгоритмов
Ниже приведены самые популярные алгоритмы сходства:
- К-ближайших соседей;
- расстояние Евклида;
- косинусное сходство;
- алгоритм Левенштейна;
- алгоритм Джаро-Винклера;
- сингулярное разложение (SVD).