Определение возрастапо голосу говорящего
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-06-21 19:32
большие данные big data, алгоритмы распознавания речи, распознавание образов

Теперь, когда у нас есть и эти функции спектрограммы, давайте проведем над ними некоторое EDA! И поскольку мы увидели, что "гендер", по-видимому, имеет особое отношение к нашим аудиозаписям, давайте визуализируем среднюю спектрограмму mel для обоих полов отдельно, а также их различия.
Как выполнить EDA и моделирование данных для аудиоданных
Большинство людей знакомы с тем, как запустить проект data science на основе изображений, текста или табличных данных. Но не у многих есть опыт анализа аудиоданных. В этой статье мы узнаем, как мы можем сделать именно это. Как подготовить, изучить и проанализировать аудиоданные с помощью машинного обучения. Короче говоря: как и для всех других модальностей (например, текста или изображений), хитрость заключается в том, чтобы перевести данные в формат, поддающийся машинной интерпретации.
Самое интересное в аудиоданных то, что вы можете обрабатывать их как множество различных модальностей:
- Вы можете извлекать высокоуровневые функции и анализировать данные, как табличные данные.
- Вы можете вычислять частотные графики и анализировать данные, такие как данные изображения.
- Вы можете использовать модели, чувствительные к времени, и анализировать данные, как данные временных рядов.
- Вы можете использовать модели преобразования речи в текст и анализировать данные как текстовые данные.
В этой статье мы рассмотрим первые три подхода. Но сначала давайте подробнее рассмотрим, как на самом деле выглядят аудиоданные.
1. Множество аспектов аудиоданных
Хотя существует несколько библиотек Python, которые позволяют вам работать с аудиоданными, в этом примере мы будем использовать librosa. Итак, давайте загрузим MP3-файл и построим график его содержимого.
# Use this code snippet to suppress all 'librosa' related UserWarnings import warnings warnings.filterwarnings("ignore") # Import librosa import librosa # Loads mp3 file with a specific sampling rate, here 16kHz y, sr = librosa.load("c4_sample-1.mp3", sr=16_000) # Plot the signal stored in 'y' from matplotlib import pyplot as plt import librosa.display plt.figure(figsize=(12, 3)) plt.title("Audio signal as waveform") librosa.display.waveplot(y, sr=sr); 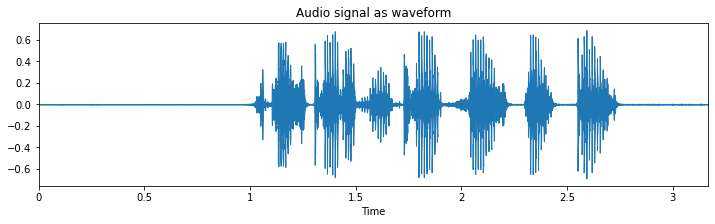
То, что вы видите здесь, представляет собой осциллограмму произнесенного предложения: “он только что получил нового воздушного змея на свой день рождения”.
1.1. Форма волны - сигнал во временной области
Раньше мы называли это данными временных рядов, но теперь мы называем это формой волны? Ну, это и то, и другое. Это становится яснее, когда мы смотрим только на небольшой сегмент этого аудиофайла. На следующем рисунке показано то же самое, что и выше, но на этот раз только 62,5 миллисекунды.
from matplotlib import pyplot as plt plt.figure(figsize=(12, 3)) plt.plot(y[17500:18500]) plt.show(); 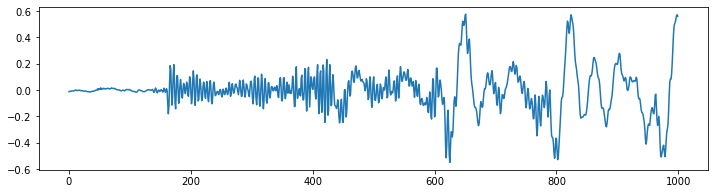
То, что вы можете видеть, - это временной сигнал, который колеблется вокруг значения 0 с различными частотами и амплитудами.Этот сигнал представляет собой изменение давления воздуха с течением времени или физическое смещение мембраны громкоговорителя (или мембраны в вашем ухе, если уж на то пошло). Вот почему это изображение аудиоданных также называется формой волны.
Частота - это скорость, с которой этот сигнал колеблется. Низкая частота, например, 60 Гц, может быть звуком бас-гитары, в то время как пение птиц может быть на более высокой частоте 8000 Гц. Человеческая речь обычно находится где-то между этим.
Чтобы знать, как быстро этот сигнал должен быть интерпретирован, нам также необходимо знать частоту дискретизации, с которой были записаны данные. В этом случае частота дискретизации в секунду составляла 16 000 или 16 Тыс. Гц. Это означает, что 1’000 временных точек, которые мы видим на предыдущем рисунке, представляют 62,5 миллисекунды (1000/16000 = 0,0625) аудиосигнала.
1.2. Преобразование Фурье - сигнал в частотной области
В то время как предыдущая визуализация может сказать нам, когда что-то происходит (т.Е. около 2 секунд кажется, что сигналов много), она не может действительно сказать нам, с какой частотой это происходит. Поскольку форма сигнала показывает нам информацию о том, когда, этот сигнал также считается находящимся во временной области.
Используя быстрое преобразование фурье, мы можем инвертировать эту проблему и получить четкую информацию о том, какие частоты присутствуют, при этом теряя всю информацию о том, когда. В таком случае говорят, что представление сигнала находится в частотной области.
Давайте посмотрим, как выглядит наше предыдущее произнесенное предложение, представленное в частотной области.
import scipy import numpy as np # Applies fast fourier transformation to the signal and takes absolute values y_freq = np.abs(scipy.fftpack.fft(y)) # Establishes all possible frequency (dependent on the sampling rate and the length of the signal) f = np.linspace(0, sr, len(y_freq)) # Plot audio signal as frequency information. plt.figure(figsize=(12, 3)) plt.semilogx(f[: len(f) // 2], y_freq[: len(f) // 2]) plt.xlabel("Frequency (Hz)") plt.show(); 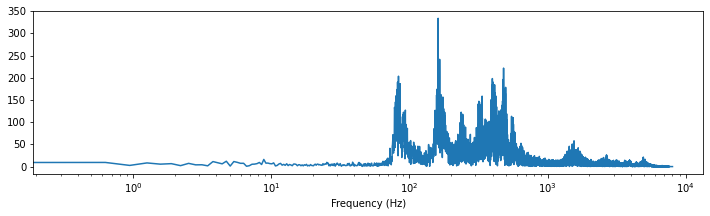
Здесь вы можете видеть, что большая часть сигнала находится где-то между ~ 100 и ~ 1000 Гц (т.Е. между $ 10 ^ 2 $ и $ 10 ^ 3 $). Кроме того, кажется, есть некоторые дополнительные данные от 1 000 до 10 000 Гц.
1.3. Спектрограмма
К счастью, нам не всегда нужно принимать решение о временной или частотной области. Используя график спектрограммы, мы можем извлечь выгоду из обеих областей, сохраняя при этом большинство их недостатков минимальными. Существует несколько способов создания таких графиков спектрограмм, но для этой статьи давайте рассмотрим три из них в частности.
1.3.1. Кратковременное преобразование Фурье (STFT)
Используя небольшую адаптированную версию быстрого преобразования Фурье, а именно кратковременное преобразование фурье (STFT), мы можем создать такую спектрограмму. Небольшая хитрость, которая применяется здесь, заключается в том, что БПФ вычисляется для нескольких небольших временных окон (отсюда и “кратковременное фурье”) в виде скользящего окна.
import librosa.display # Compute short-time Fourier Transform x_stft = np.abs(librosa.stft(y)) # Apply logarithmic dB-scale to spectrogram and set maximum to 0 dB x_stft = librosa.amplitude_to_db(x_stft, ref=np.max) # Plot STFT spectrogram plt.figure(figsize=(12, 4)) librosa.display.specshow(x_stft, sr=sr, x_axis="time", y_axis="log") plt.colorbar(format="%+2.0f dB") plt.show(); 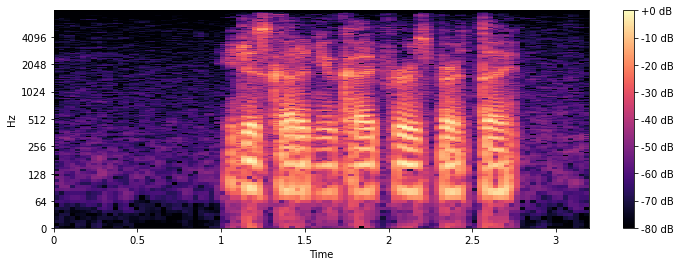
Как и на всех графиках спектрограмм, цвет представляет величину (громкость/громкость) заданной частоты в данный момент времени. +0 дБ - это самый громкий звук, а - 80 дБ близок к тишине. На горизонтальной оси x мы можем видеть время, в то время как на вертикальной оси y мы можем видеть различные частоты.
1.3.2. Мэл-спектрограмма
В качестве альтернативы STFT вы также можете вычислить спектрограмму mel, основанную на шкале mel. Эта шкала объясняет то, как мы, люди, воспринимаем высоту звука. Шкала mel рассчитывается таким образом, чтобы две пары частот, разделенных дельтой в шкале mel, воспринимались людьми как имеющие одинаковую разницу в восприятии.
Спектрограмма mel вычисляется очень похоже на STFT, основное отличие заключается только в том, что ось y использует другой масштаб.
# Compute the mel spectrogram x_mel = librosa.feature.melspectrogram(y=y, sr=sr) # Apply logarithmic dB-scale to spectrogram and set maximum to 0 dB x_mel = librosa.power_to_db(x_mel, ref=np.max) # Plot mel spectrogram plt.figure(figsize=(12, 4)) librosa.display.specshow(x_mel, sr=sr, x_axis="time", y_axis="mel") plt.colorbar(format="%+2.0f dB") plt.show(); 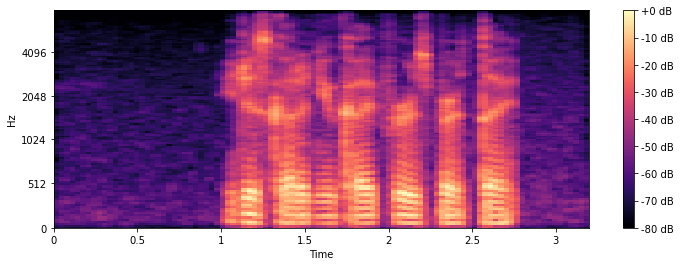
Сначала разница с STFT может показаться не слишком очевидной, но если вы присмотритесь повнимательнее, то увидите, что на графике STFT частота от 0 до 512 Гц занимает гораздо больше места на оси y, чем на графике mel.
1.3.3. Коэффициенты кепстрала малой частоты (MFCCc)
Частотные коэффициенты кепстрала Mel (MFCC) представляют собой альтернативное представление спектрограммы mel, полученной ранее. Преимуществом MFCC перед mel-спектрограммой является довольно небольшое количество признаков (т.е. уникальных горизонтальных линий), обычно ~20.
Из-за того, что спектрограмма mel ближе к тому, как мы, люди, воспринимаем высоту звука, и что MFCCs имеет всего несколько функций компонентов, большинство специалистов по машинному обучению предпочитают способ представления аудиоданных MFCCs в виде "изображения". Это не означает, что для данной проблемы представление STFT, mel или формы сигнала может работать лучше.
Итак, давайте продолжим и вычислим MFCC и построим их график.
# Extract 'n_mfcc' numbers of MFCCs components (here 20) x_mfccs = librosa.feature.mfcc(y, sr=sr, n_mfcc=20) # Plot MFCCs plt.figure(figsize=(12, 4)) librosa.display.specshow(x_mfccs, sr=sr, x_axis="time") plt.colorbar() plt.show(); 
2. Data cleaning
Теперь, когда мы немного лучше понимаем, как выглядят аудиоданные, давайте визуализируем еще несколько примеров. Примечание: Вы можете загрузить эти четыре примера по этим ссылкам: Audio 1, Audio 2, Audio 3, Audio 4.
# Visualization of four mp3 files fig, axs = plt.subplots(2, 2, figsize=(15, 6)) for i, ax in enumerate(axs.flatten()): fname = "c4_sample-%d.mp3" % (i + 1) y, sr = librosa.load(fname, sr=16_000) librosa.display.waveplot(y, sr=sr, ax=ax) ax.set_title(fname) plt.tight_layout() plt.show(); 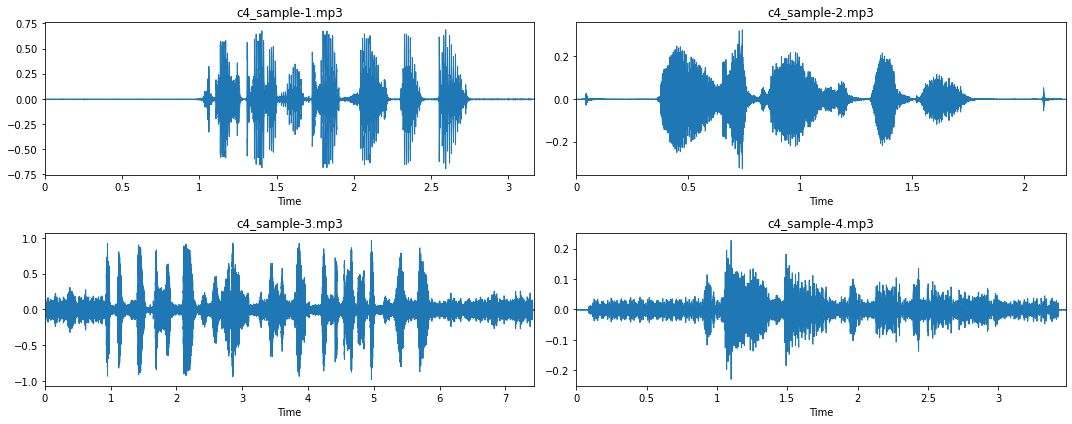
Из этих четырех примеров и, что более важно, при их прослушивании мы можем получить еще несколько сведений об этом наборе аудиоматериалов:
- Большинство записей имеют длительный период молчания в начале и конце записи (см. примеры 1 и 2). Это то, о чем мы должны позаботиться с помощью ‘обрезки’.
- Однако в некоторых случаях этот период молчания прерывается ‘щелчком’, вызванным нажатием и отпусканием кнопок записи (см. пример 2).
- В некоторых аудиозаписях нет такой фазы тишины, то есть прямой линии (см. примеры 3 и 4). При прослушивании этих записей мы можем заметить, что это происходит из-за большого количества фонового шума.
Чтобы лучше понять, как это представлено в частотной области, давайте посмотрим на соответствующие спектрограммы STFT.
# The code is the same as before, using the stft-spectrogram routine fig, axs = plt.subplots(2, 2, figsize=(15, 6)) for i, ax in enumerate(axs.flatten()): fname = "c4_sample-%d.mp3" % (i + 1) y, sr = librosa.load(fname, sr=16_000) x_stft = np.abs(librosa.stft(y)) x_stft = librosa.amplitude_to_db(x_stft, ref=np.max) librosa.display.specshow(x_stft, sr=sr, x_axis="time", y_axis="log", ax=ax) ax.set_title(fname) plt.tight_layout() plt.show(); 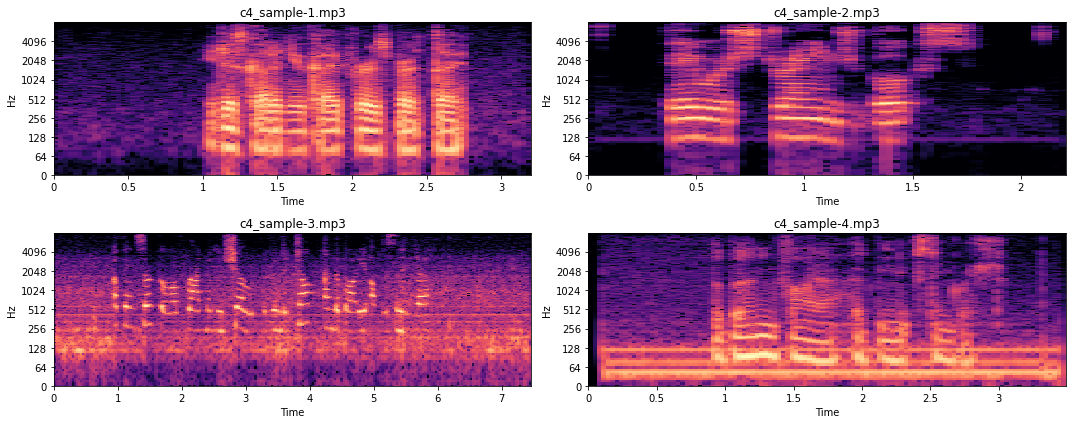
Когда мы слушаем аудиозаписи, мы можем заметить, что образец 3 имеет изменяющийся фоновый шум, охватывающий несколько частот, в то время как фоновый шум в образце 4 довольно постоянный. Это также то, что мы видим на рисунках выше. Образец 3 очень шумный на всем протяжении, в то время как образец 4 шумный только на нескольких частотах (т.е. Толстые горизонтальные линии). Сейчас мы не будем вдаваться в подробности того, как можно устранить такой шум, поскольку это выходит за рамки данной статьи.
Итак, давайте рассмотрим ‘краткий обзор’ того, как мы могли бы удалить такой шум и обрезать звуковые сэмплы. Хотя более ручной подход, с использованием пользовательских функций фильтрации, может быть лучшим подходом для удаления шума из аудиоданных, в нашем случае мы пойдем дальше и используем практичный пакет python noisereduce.
import noisereduce as nr from scipy.io import wavfile # Loop through all four samples for i in range(4): # Load audio file fname = "c4_sample-%d.mp3" % (i + 1) y, sr = librosa.load(fname, sr=16_000) # Remove noise from audio sample reduced_noise = nr.reduce_noise(y=y, sr=sr, stationary=False) # Save output in a wav file as mp3 cannot be saved to directly wavfile.write(fname.replace(".mp3", ".wav"), sr, reduced_noise) Если вы прослушаете созданные wav-файлы, то сможете услышать, что шум почти полностью исчез. Да, мы также ввели еще несколько артефактов, но в целом мы надеемся, что наш подход к удалению шума принес больше пользы, чем вреда.
Для шага обрезки мы можем использовать функцию librosa .effects.trim(). Обратите внимание, что для каждого набора данных может потребоваться другой параметр top_db для обрезки, поэтому лучше всего попробовать несколько версий и посмотреть, что работает хорошо. В нашем случае это top_db=20.
# Loop through all four samples for i in range(4): # Load audio file fname = "c4_sample-%d.wav" % (i + 1) y, sr = librosa.load(fname, sr=16_000) # Trim signal y_trim, _ = librosa.effects.trim(y, top_db=20) # Overwrite previous wav file wavfile.write(fname.replace(".mp3", ".wav"), sr, y_trim) Давайте теперь еще раз взглянем на очищенные данные.
fig, axs = plt.subplots(2, 2, figsize=(15, 6)) for i, ax in enumerate(axs.flatten()): fname = "c4_sample-%d.wav" % (i + 1) y, sr = librosa.load(fname, sr=16_000) librosa.display.waveplot(y, sr=sr, ax=ax) ax.set_title(fname) plt.tight_layout() plt.show(); 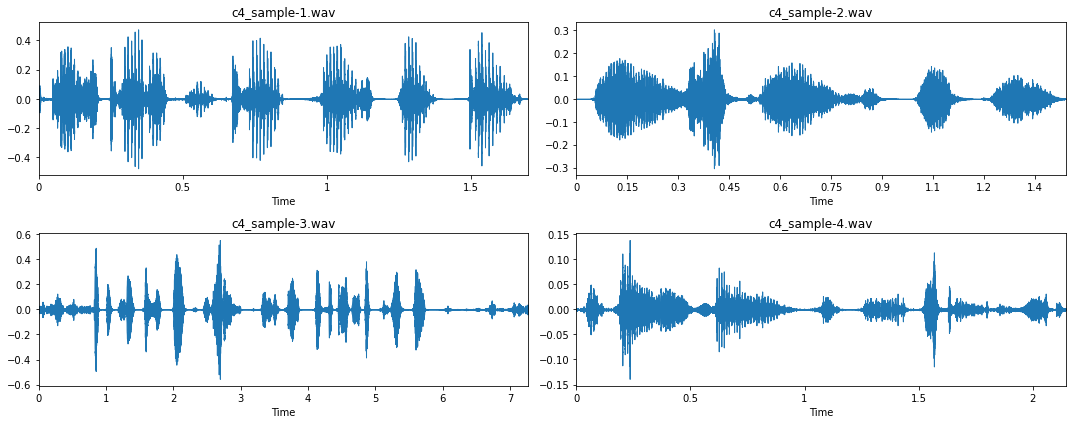
Намного лучше!
3. Извлечение признаков
Теперь, когда наши данные чисты, давайте продолжим и рассмотрим несколько специфичных для звука функций, которые мы могли бы извлечь. Но сначала давайте загрузим файл.
# Загрузить данные для выборки 1 y, sr = librosa.load("c4_sample-1.wav", sr=16_000)
3.1. Обнаружение начала заболевания
Глядя на форму сигнала, librosa может достаточно хорошо определить начало нового произнесенного слова.
# Extract onset timestamps of words onsets = librosa.onset.onset_detect( y=y, sr=sr, units="time", hop_length=128, backtrack=False) # Plot onsets together with waveform plot plt.figure(figsize=(8, 3)) librosa.display.waveplot(y, sr=sr, alpha=0.2, x_axis="time") for o in onsets: plt.vlines(o, -0.5, 0.5, colors="r") plt.show() # Return number of onsets number_of_words = len(onsets) print(f"{number_of_words} onsets were detected in this audio signal.") 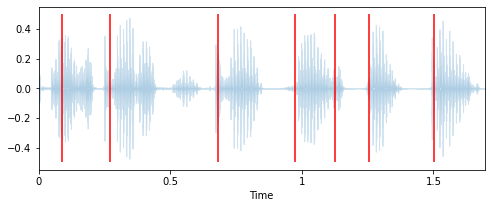
В этом аудиосигнале было обнаружено 7 включений
3.2. Продолжительность аудиозаписи
Очень сильно с этим связана продолжительность аудиозаписи. Чем длиннее запись, тем больше слов можно произнести. Итак, давайте вычислим длину записи и скорость, с которой произносятся слова.
# Computes duration in seconds duration = len(y) / sr words_per_second = number_of_words / duration print(f"""The audio signal is {duration:.2f} seconds long, with an average of {words_per_second:.2f} words per seconds.""") 3.3. Темп
Язык - это очень мелодичный сигнал, и у каждого из нас есть уникальная манера и скорость речи. Следовательно, еще одна функция, которую мы могли бы извлечь, - это темп нашей речи, то есть количество ударов, которые могут быть обнаружены в аудиосигнале.
# Вычисляет темп аудиозаписи tempo = librosa.beat.tempo(y, sr, start_bpm=10)[0] print(f"Аудиосигнал имеет скорость {tempo:.2f} ударов в минуту.")
Скорость аудиосигнала составляет 42,61 ударов в минуту.
3.4. Основная частота
Основная частота - это самая низкая частота, на которой появляется периодический звук. В музыке это также известно как высота тона. На графиках спектрограмм, которые мы видели ранее, основная частота (также называемая f0) представляет собой самую низкую яркую горизонтальную полосу на изображении. В то время как повторение полосатого рисунка над этим фундаментальным называется гармониками.
Чтобы лучше проиллюстрировать, что именно мы имеем в виду, давайте извлекем основную частоту и нанесем ее на нашу спектрограмму.
# Extract fundamental frequency using a probabilistic approach f0, _, _ = librosa.pyin(y, sr=sr, fmin=10, fmax=8000, frame_length=1024) # Establish timepoint of f0 signal timepoints = np.linspace(0, duration, num=len(f0), endpoint=False) # Plot fundamental frequency in spectrogram plot plt.figure(figsize=(8, 3)) x_stft = np.abs(librosa.stft(y)) x_stft = librosa.amplitude_to_db(x_stft, ref=np.max) librosa.display.specshow(x_stft, sr=sr, x_axis="time", y_axis="log") plt.plot(timepoints, f0, color="cyan", linewidth=4) plt.show(); 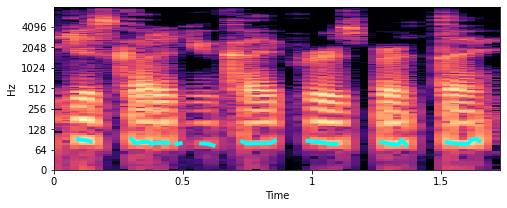
Бирюзовые линии, которые вы видите около 100 Гц, являются основными частотами. Итак, похоже, речь идет о записи. Но как мы можем теперь использовать это для разработки функций? Что ж, что мы могли бы сделать, так это вычислить конкретные характеристики этого f0.
# Вычисляет среднее, медианное, 5%- и 95%-процентное значение основной частоты f0_values = [np.nanmean(f0), np.nanmedian(f0), np.nanstd(f0), np.nanpercentile(f0, 5), np.nanpercentile(f0, 95), ] печать("""Этот аудиосигнал имеет среднее значение {:.2f}, медиану {:.2f}, std {:.2f}, 5-процентиль в {:.2f} и 95-процентиль в {:.2f}.""".формат(*f0_values))
Этот аудиосигнал имеет среднее значение 81,98, медиану 80,46, std 4,42, 5-процентиль на уровне 76,57 и 95-процентиль на уровне 90,64.
Примечание: Конечно, существует еще много методов извлечения звуковых объектов, которые вы могли бы изучить. Для получения краткого изложения некоторых из них ознакомьтесь с musicinformationretrieval.com .
4. Предварительный анализ данных (EDA) по набору аудиоданных
Теперь, когда мы знаем, как выглядят аудиоданные и как мы можем их обрабатывать, давайте сделаем еще один шаг и проведем надлежащий EDA для них. Для этого давайте сначала загрузим набор данных. Обратите внимание, что набор данных, который мы будем использовать для этой статьи, был загружен из общего хранилища голоса от Kaggle. Этот большой набор данных объемом 14 ГБ представляет собой лишь небольшой снимок большого набора данных объемом более 70 ГБ от Mozilla. Но не волнуйтесь, для нашего примера здесь мы будем использовать все меньшую подвыборку примерно из ~ 9 000 аудиофайлов.
# Загрузите и распакуйте набор данных !wget -qO c4_audio_dataset.zip https://www.dropbox.com/s/3ibn2br901vvtgz/c4_audio_dataset.zip?dl=1 !распаковать архив -q c4_audio_dataset.zip !рм c4_audio_dataset.zip
Итак, давайте подробнее рассмотрим этот набор данных и некоторые уже извлеченные функции.
импортируйте pandas как pd # Загрузите csv-файл, содержащий уже извлеченные объекты
df = pd.read_csv("c4_common-voice_dataset.csv.zip") df.dropna(inplace=True) df.head() | filename | age | gender | nwords | duration | words_per_second | tempo | f0_mean | f0_median | f0_std | f0_5perc | f0_95perc |
|---|---|---|---|---|---|---|---|---|---|---|---|
| sample_00001.mp3 | thirties | male | 7 | 2.628 | 2.663 | 25.000 | 102.324 | 98.498 | 17.991 | 80.418 | 132.998 |
| sample_00002.mp3 | sixties | male | 15 | 2.916 | 5.144 | 27.173 | 97.773 | 96.799 | 17.866 | 70.626 | 129.735 |
| sample_00003.mp3 | twenties | female | 18 | 3.528 | 5.102 | 25.000 | 237.412 | 234.253 | 36.550 | 185.338 | 301.256 |
| sample_00004.mp3 | twenties | male | 35 | 6.516 | 5.371 | 21.306 | 189.364 | 110.553 | 196.566 | 90.317 | 689.908 |
| sample_00005.mp3 | fourties | female | 19 | 5.040 | 3.769 | 19.531 | 204.885 | 202.755 | 21.037 | 177.839 | 245.332 |
4.1. Исследование распределения функций
4.1.1. Целевые характеристики
Во-первых, давайте посмотрим на распределение по классам наших потенциальных целевых классов по возрасту и полу.
import matplotlib.pyplot as plt fig, axes = plt.subplots(1, 2, figsize=(15, 3)) for i, c in enumerate(["age", "gender"]): df[c].value_counts().plot.bar(title=c, ax=axes[i], alpha=0.6) plt.show(); 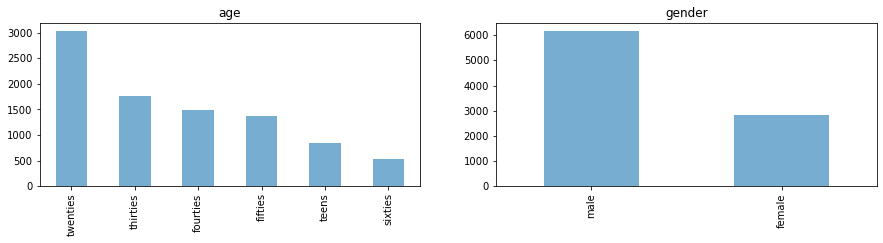
4.1.2. Извлеченные функции
В качестве следующего шага давайте подробнее рассмотрим распределение значений извлеченных объектов.
# Plot value distributions of extracted features df.drop(columns=["age", "gender", "filename"]).hist(bins=100, figsize=(14, 10)) plt.show(); 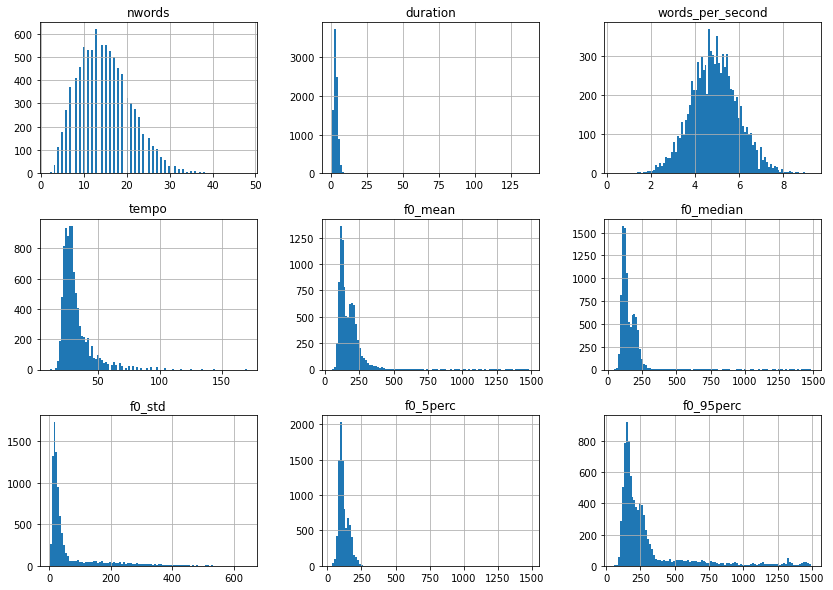
За исключением words_per_second, большинство из этих распределений функций искажены вправо и, следовательно, могут извлечь выгоду из преобразования журнала. Так что давайте позаботимся об этом.
import numpy as np # Applies log1p on features that are not age, gender, filename or words_per_second df = df.apply( lambda x: np.log1p(x) if x.name not in ["age", "gender", "filename", "words_per_second"] else x) # Let's look at the distribution once more df.drop(columns=["age", "gender", "filename"]).hist(bins=100, figsize=(14, 10)) plt.show(); 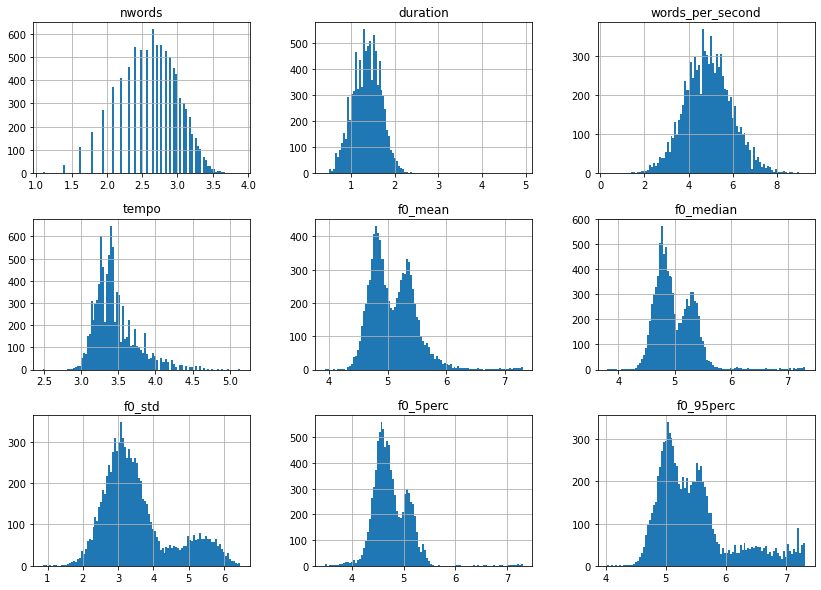
Намного лучше, но что интересно, так это тот факт, что все функции f0, похоже, имеют бимодальное распределение. Давайте построим то же самое, что и раньше, но на этот раз с разделением по полу.
for g in df.gender.unique(): df[df["gender"].eq(g)]["f0_median"].hist( bins=100, figsize=(8, 5), label=g, alpha=0.6) plt.legend() plt.show(); 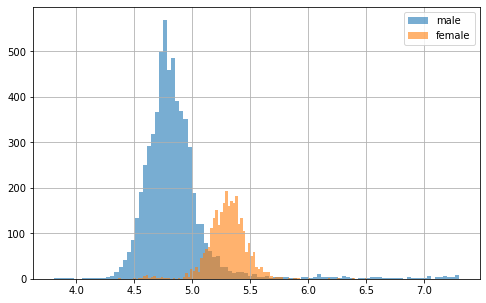
Как и предполагалось, здесь, похоже, присутствует гендерный эффект! Но что мы также можем видеть, так это то, что некоторые показатели f0 (здесь, в частности, у мужчин) намного ниже и выше, чем они должны быть. Потенциально это могут быть выбросы из-за плохого извлечения объектов. Давайте подробнее рассмотрим все точки данных на следующем рисунке.
# Plot sample points for each feature individually df.plot(lw=0, marker=".", subplots=True, layout=(-1, 3), figsize=(15, 7.5), markersize=2) plt.tight_layout() plt.show(); 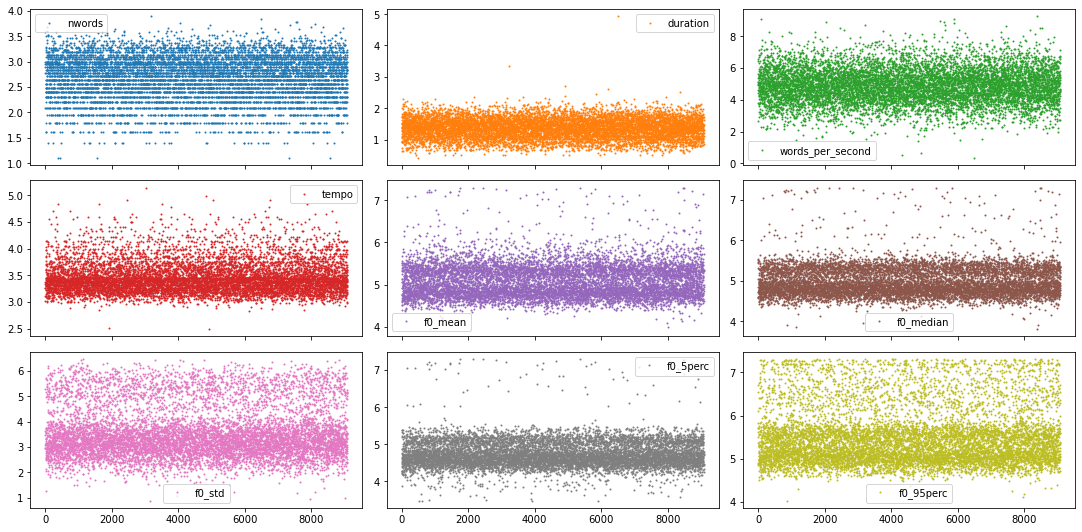
Учитывая небольшое количество функций и тот факт, что у нас есть довольно приятные на вид дистрибутивы с ярко выраженными хвостами, мы могли бы просмотреть каждый из них и определить пороговое значение выброса для каждой функции. Но чтобы показать вам более автоматизированный способ, давайте вместо этого воспользуемся подходом z-score.
from scipy.stats import zscore # Only select columns with numbers from the dataframe df_num = df.select_dtypes(np.number) # Apply zscore to all numerical features df_num = df_num.apply(zscore) # Identify all samples that are below a specific z-value z_thresh = 3 mask = np.sum(df_num.abs() > z_thresh, axis=1).eq(0) # Only keep the values in the mask df = df[mask] df.shape (8669, 12) Как вы можете видеть, этот подход сократил наш набор данных примерно на 5%, что должно быть нормально.
4.2. Корреляция признаков
В качестве следующего шага давайте посмотрим на корреляцию между всеми функциями. Но прежде чем мы сможем это сделать, давайте продолжим и также закодируем нечисловые целевые объекты. Обратите внимание, что для этого мы могли бы использовать OrdinalEncoder scikit-learn, но это потенциально нарушило бы правильный порядок в функции age. Так что давайте лучше выполним ручное сопоставление.
# Сопоставьте возраст с соответствующим числовым значением df.loc[:, "возраст"] = df["возраст"].map({ "подростки": 0, "двадцатые": 1, "тридцатые": 2, "сороковые": 3, "пятидесятые": 4, "шестидесятые": 5}) # Сопоставьте пол с соответствующим числовым значением df.loc[:, "пол"] = df["пол"].map({"мужской": 0, "женский": 1})
Теперь мы готовы использовать функцию pandas .corr() вместе с функцией seaborn's heatmap(), чтобы получить больше информации о корреляции объектов.
import seaborn as sns plt.figure(figsize=(8, 8)) df_corr = df.corr() * 100 sns.heatmap(df_corr, square=True, annot=True, fmt=".0f", mask=np.eye(len(df_corr)), center=0) plt.show(); 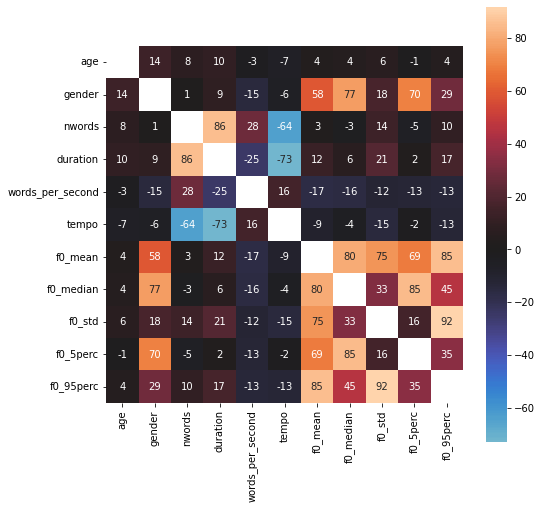
Интересно! Что мы можем видеть, так это то, что наши извлеченные функции f0, по-видимому, имеют довольно сильную связь с гендерной целью, в то время как возраст, по-видимому, мало с чем коррелирует.
4.3. Характеристики спектрограммы
На данный момент мы не просматривали фактические аудиозаписи во время нашего EDA. Как мы видели ранее, у нас есть много вариантов (например, в форме сигнала или в виде спектрограммы STFT, mel или mfccs). Для этого исследования давайте продолжим и посмотрим на спектрограммы mel.
Однако, прежде чем мы сможем это сделать, нам нужно учесть одну вещь: все звуковые сэмплы имеют разную длину, а это означает, что спектрограммы также будут иметь разную длину. Поэтому, чтобы нормализовать все записи, давайте сократим их до длины ровно 3 секунды. Это означает, что слишком короткие образцы будут заполнены, в то время как слишком длинные образцы будут вырезаны.
# Two helper functions for audio data preparation import os import librosa def resize_spectrogram(spec, length, fact=-80): # Create an empty canvas to put spectrogram into canvas = np.ones((len(spec), length)) * fact if spec.shape[1] <= length: canvas[:, : spec.shape[1]] = spec else: canvas[:, :length] = spec[:, :length] return canvas def compute_mel_spec(filename, sr=16_000, hop_length=512, duration=3.0): # Loads the mp3 file y, sr = librosa.load(os.path.join("audio_dataset", filename), sr=sr) # Compute the mel spectrogram x_mel = librosa.feature.melspectrogram(y=y, sr=sr) # Apply logarithmic dB-scale to spectrogram and set maximum to 0 dB x_mel = librosa.power_to_db(x_mel, ref=np.max) # Compute mean strength per frequency for mel spectrogram mel_strength = np.mean(x_mel, axis=1) # Estimate the desired length of the spectrogram length = int(duration * sr / hop_length) # Put mel spectrogram into the right shape x_mel = resize_spectrogram(x_mel, length, fact=-80) return x_mel, mel_strength Теперь, когда все готово, давайте извлекем спектрограммы для всех звуковых сэмплов.
from tqdm.notebook import tqdm # Create arrays to store output into spec_infos = [] # Loop through all files and extract spectrograms sr = 16_000 for f in tqdm(df.filename): spec_infos.append(compute_mel_spec(f, sr=sr)) # Aggregate feature types in common variable mels = np.array([s[0] for s in spec_infos]) mels_strengths = np.array([s[1] for s in spec_infos]) Теперь, когда у нас есть и эти функции спектрограммы, давайте проведем над ними некоторое EDA! И поскольку мы увидели, что "гендер", по-видимому, имеет особое отношение к нашим аудиозаписям, давайте визуализируем среднюю спектрограмму mel для обоих полов отдельно, а также их различия.
import librosa.display # Creates a figure with two subplot fig, axs = plt.subplots(1, 3, figsize=(16, 3)) # Plots mel spectrogram for male speakers mels_male = np.mean(mels[df["gender"].eq(0)], axis=0) librosa.display.specshow(mels_male, sr=sr, x_axis="time", y_axis="mel", ax=axs[0]) axs[0].set_title("male") # Plots mel spectrogram for female speakers mels_female = np.mean(mels[df["gender"].eq(1)], axis=0) librosa.display.specshow(mels_female, sr=sr, x_axis="time", y_axis="mel", ax=axs[1]) axs[1].set_title("female") # Plot gender differences librosa.display.specshow( mels_male - mels_female, sr=sr, x_axis="time", y_axis="mel", ax=axs[2] ) axs[2].set_title("Difference") plt.show() 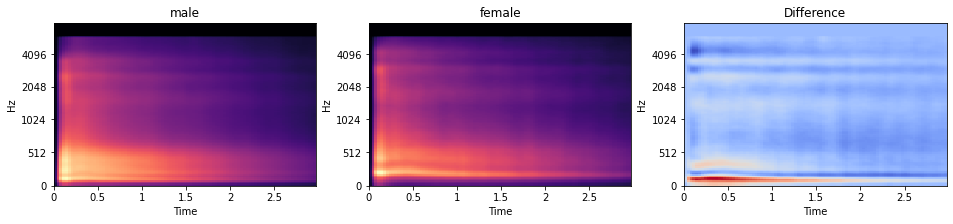
Хотя это трудно увидеть на индивидуальном графике, график различий показывает, что у говорящего мужчины в среднем более низкие голоса, чем у женщины. Это можно увидеть по большей силе на более низких частотах (видно в красной горизонтальной области) на графике разницы.
5. Модели машинного обучения
Теперь мы готовы к части моделирования. И поэтому у нас есть несколько вариантов. Что касается моделей, мы могли бы …
обучаем наши собственные классические (т.е. неглубокие) модели машинного обучения, такие как LogisticRegression или SVC.
обучаем наши собственные модели глубокого обучения, то есть глубокую нейронную сеть.
используйте предварительно обученную нейронную сеть из TensorflowHub для извлечения объектов, а затем обучите мелкую или глубокую модель этим высокоуровневым объектам
А что касается данных, мы могли бы использовать …
данные из CSV-файла, объедините их с характеристиками "mel strength" из спектрограмм и рассмотрите данные как табличные данные, установите
только mel-спектрограммы и рассмотрите их как данные изображения, установите
высокоуровневые объекты из TensorflowHub, объедините их с другими табличными данными и рассмотрите их как данные изображения. табличный набор данных, а также
Конечно, существует множество различных подходов и других способов создания набора данных для части моделирования. Для этой статьи давайте кратко рассмотрим один из них.
Классическая (т.е. неглубокая) модель машинного обучения
Давайте возьмем данные из CSV-файла и объединим их с простой моделью LogisticRegression и посмотрим, насколько хорошо мы можем предсказать возраст говорящего. Итак, для начала давайте загрузим данные и разделим их на обучающий и тестовый наборы.
from sklearn.model_selection import train_test_split # Select target target = "age" y = df[target].values # Select relevant features from the dataframe features = df.drop(columns=["filename", target]).reset_index(drop=True) # Combine them with the mels strength features X = pd.concat((features, pd.DataFrame(mels_strengths)), axis=1) # Create train and test set x_tr, x_te, y_tr, y_te = train_test_split( X, y, train_size=0.8, shuffle=True, stratify=y, random_state=0 ) # Plot size of dataset print(x_tr.shape) (6935, 138) Теперь, когда данные готовы к обучению, давайте создадим модель, которую мы хотели бы обучить. Для этого давайте используем объект конвейера, чтобы мы могли изучить преимущества определенных процедур предварительной обработки (например, с использованием масштабировщиков или PCA). Кроме того, давайте использовать GridSearchCV для изучения различных комбинаций гиперпараметров, а также для выполнения перекрестной проверки.
from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import RobustScaler, PowerTransformer, QuantileTransformer from sklearn.decomposition import PCA from sklearn.pipeline import Pipeline from sklearn.model_selection import GridSearchCV # Create pipeline pipe = Pipeline( [ ("scaler", RobustScaler()), ("pca", PCA()), ("logreg", LogisticRegression(class_weight="balanced")), ] ) # Create grid grid = { "scaler": [RobustScaler(), PowerTransformer(), QuantileTransformer()], "pca": [None, PCA(0.99)], "logreg__C": np.logspace(-3, 2, num=16), } # Create GridSearchCV grid_cv = GridSearchCV(pipe, grid, cv=4, return_train_score=True, verbose=1) # Train GridSearchCV model = grid_cv.fit(x_tr, y_tr) # Collect results in a DataFrame cv_results = pd.DataFrame(grid_cv.cv_results_) # Select the columns we are interested in col_of_interest = [ "param_scaler", "param_pca", "param_logreg__C", "mean_test_score", "mean_train_score", "std_test_score", "std_train_score", ] cv_results = cv_results[col_of_interest] # Show the dataframe sorted according to our performance metric cv_results.sort_values("mean_test_score", ascending=False) Подгонка по 4 складки для каждого из 96 кандидатов, в общей сложности 384 подгонки
| param_scaler | param_pca | param_logreg__C | mean_test_score | mean_train_score | std_test_score | std_train_score |
|---|---|---|---|---|---|---|
| PowerTransformer() | None | 1.0 | 0.439508 | 0.485124 | 0.005489 | 0.005539 |
| PowerTransformer() | None | 0.464159 | 0.438499 | 0.483538 | 0.005958 | 0.003447 |
| RobustScaler() | None | 0.464159 | 0.437203 | 0.481663 | 0.007420 | 0.005240 |
| PowerTransformer() | None | 0.1 | 0.436482 | 0.473059 | 0.005968 | 0.003246 |
| PowerTransformer() | None | 0.215443 | 0.436192 | 0.478923 | 0.005446 | 0.004047 |
| ... | ... | ... | ... | ... | ... | ... |
| RobustScaler() | PCA(0.99) | 0.001 | 0.296178 | 0.310118 | 0.004719 | 0.001384 |
| QuantileTransformer() | None | 0.002154 | 0.291420 | 0.297573 | 0.005419 | 0.001818 |
| QuantileTransformer() | PCA(0.99) | 0.002154 | 0.290699 | 0.296563 | 0.005288 | 0.002046 |
| QuantileTransformer() | None | 0.001 | 0.287959 | 0.291613 | 0.004569 | 0.001804 |
| QuantileTransformer() | PCA(0.99) | 0.001 | 0.287670 | 0.290988 | 0.005001 | 0.001787 |
96 строк х 7 столбцов
В дополнение к приведенному выше выходному кадру данных мы также можем построить график оценки производительности в зависимости от исследованных гиперпараметров. Однако, учитывая, что у нас есть несколько скейлеров и подходов PCA, нам нужно создать отдельный график для каждой отдельной комбинации гиперпараметров.
from itertools import product # Establish combinations of different hyperparameters, that isn't the one # we want to plot on the x-axis combinations = list(product(grid["scaler"], grid["pca"])) # Creates a figure with multiple subplot fig, axs = plt.subplots( len(grid["scaler"]), len(grid["pca"]), figsize=(12, 10), sharey=True) # Extract useful information about max performance max_score = cv_results["mean_test_score"].max() c_values = cv_results["param_logreg__C"] # Loop through the subplots and populate them for i, (s, p) in enumerate(combinations): # Select subplot relevant grid search results mask = np.logical_and( cv_results["param_pca"].astype("str") == str(p), cv_results["param_scaler"].astype("str") == str(s), ) df_cv = cv_results[mask].sort_values("param_logreg__C").set_index("param_logreg__C") # Select relevant axis ax = axs.flatten()[i] # Plot train and test curves df_cv[["mean_train_score", "mean_test_score"]].plot( logx=True, title=f"{s} | {p}", ax=ax) ax.fill_between( df_cv.index, df_cv["mean_train_score"] - df_cv["std_train_score"], df_cv["mean_train_score"] + df_cv["std_train_score"], alpha=0.3,) ax.fill_between( df_cv.index, df_cv["mean_test_score"] - df_cv["std_test_score"], df_cv["mean_test_score"] + df_cv["std_test_score"], alpha=0.3,) # Plot best performance metric as dotted line ax.hlines( max_score, c_values.min(), c_values.max(), color="gray", linestyles="dotted") # Limit y-axis plt.ylim(0.28, 0.501) plt.tight_layout() plt.show() 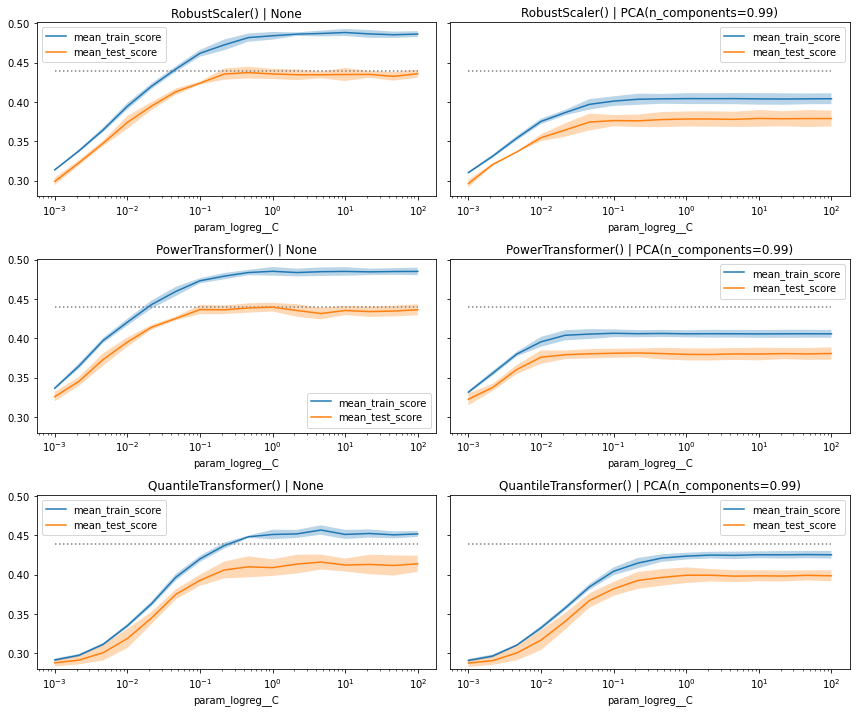
Выполнение дополнительного шага и визуализация показателей производительности в виде кривых часто дают нам соответствующую дополнительную информацию, которую мы не получили бы, если бы просто смотрели на фрейм данных pandas.
На этом графике мы видим, что в целом модели работают одинаково хорошо. Некоторые из них имеют более быстрое "выпадение", когда мы уменьшаем значение C, в то время как другие показывают более широкий разрыв между оценкой train и test (здесь фактически проверка), особенно когда мы не используем PCA.
Сказав все это, давайте просто перейдем к модели best_estimator_ и посмотрим, насколько хорошо она работает на удержанном тестовом наборе.
# # Вычислить оценку лучшей модели на удержанном тестовом наборе best_cif = model.best_estimator_ best_clf.score(x_te, y_te)
0.4354094579008074
Это уже очень хороший результат. Но чтобы лучше понять, насколько хорошо работает наша классификационная модель, давайте также посмотрим на соответствующую матрицу путаницы. Чтобы сделать это, давайте создадим короткую вспомогательную функцию.
from sklearn.metrics import ConfusionMatrixDisplay def plot_confusion_matrices(y_true, y_pred): # Create two subplots f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4)) # Specify labels labels = ["teens", "twenties", "thirties", "fourties", "fifties", "sixties"] # Plots the standard confusion matrix ax1.set_title("Confusion Matrix (counts)") ConfusionMatrixDisplay.from_predictions( y_true, y_pred, display_labels=labels, xticks_rotation=20, ax=ax1) # Plots the normalized confusion matrix ax2.set_title("Confusion Matrix (ratios)") ConfusionMatrixDisplay.from_predictions( y_true, y_pred, display_labels=labels, xticks_rotation=20, ax=ax2, normalize="true") plt.show() # Compute test set predictions predictions = best_clf.predict(x_te) # Plot confusion matrices plot_confusion_matrices(y_te, predictions) 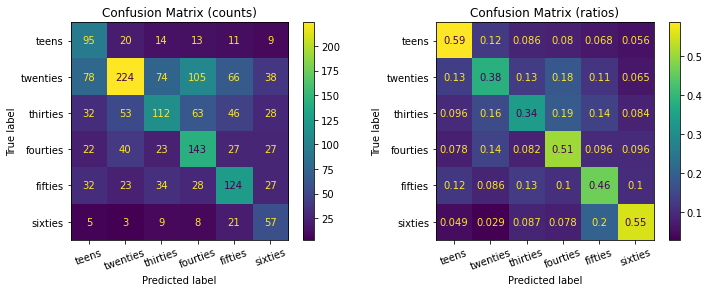
Как вы можете видеть, хотя модель смогла обнаружить больше выборок двадцатых годов, чем другие (левая матрица путаницы), в целом она действительно была лучше в классификации записей подростков и шестидесятников (например, с точностью 59% и 55% соответственно).
Резюме
В этом разделе мы впервые увидели, как выглядят аудиоданные, в какие различные формы они могут быть преобразованы, как их можно очистить и изучить, а затем использовать для обучения некоторых моделей машинного обучения.
Источник: miykael.github.io