Все О Дереве Решений
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-05-06 14:00

В этой статье мы разберемся с Деревом решений, ответив на следующий вопрос:
Что такое Дерево решений?
Какова основная концепция Дерева решений?
Какие термины используются в Дереве решений в случае классификации?
Какие термины используются в Дереве решений в случае регрессии?
Каковы преимущества и недостатки дерева решений?
Как реализовать дерево решений с помощью Scikit-learn?
Что такое Дерево решений?
Дерево решений - один из самых мощных и важных алгоритмов, присутствующих в контролируемом машинном обучении. Этот алгоритм очень гибкий, поскольку он может решать как задачи регрессии, так и задачи классификации. Кроме того, основную концепцию, лежащую в основе алгоритма дерева решений, очень легко понять, если вы имеете опыт программирования. Поскольку дерево решений имитирует вложенную структуру if-else для создания дерева и прогнозирования результата.
Прежде чем погрузиться в алгоритм дерева решений, мы должны понять некоторые основные термины, связанные с Деревом.
Что означает дерево в мире компьютерных наук?
Дерево - это нелинейная структура данных, используемая в информатике и представляющая иерархические данные. Он состоит из узлов, которые содержат данные, и ребер, которые соединяют эти узлы друг с другом. Самый верхний или начальный узел называется корневым узлом. Конечные узлы называются конечными узлами. Узел, который имеет ответвление от него к любому другому узлу, называется родительским узлом, а непосредственный подузел родительского узла называется дочерним узлом. Посмотрите на картинку ниже, чтобы лучше понять, как выглядят деревья в информатике.

Дерево в структуре данных
Какова основная концепция Дерева решений?
Чтобы понять основную концепцию, давайте возьмем пример. Рассмотрим приведенную ниже таблицу:

Набор данных
Эта таблица имеет 1 зависимую функцию, которая заключается в том, будет ли ребенок играть на улице или нет, обозначается словом “Играть”. И 3 независимые функции: погода, время и родители дома. Если мы попытаемся написать программу, чтобы оценить результат того, играет ли ребенок на улице или нет, просто наблюдая за столом. Тогда программа будет выглядеть следующим образом:

Программа на python
Теперь, если мы используем эту программу и попытаемся построить дерево решений, оно будет выглядеть следующим образом:
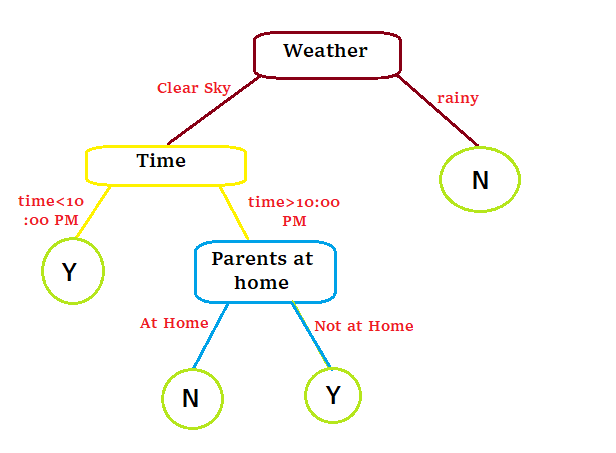
Дерево решений
Мы можем заметить, что Дерево решений - это просто вложенный оператор if-else, который описывается в формате дерева.
Поскольку мы понимаем основную концепцию Дерева решений, мы сами наткнулись на новый вопрос, который заключается в том, как мы можем упорядочить порядок независимых объектов для создания дерева решений - как в приведенном выше примере, откуда мы знаем, что сначала мы должны взять функцию “Погода”, затем “Время” и затем появляется функция “Родители дома”. Чтобы ответить на этот вопрос, мы должны сначала понять некоторые статистические термины, которые мы обсудим ниже.
Какие термины используются в Дереве решений в случае классификации?
Энтропия:
Энтропия - это мера случайности в данных. Другими словами, это дает примесь, присутствующую в наборе данных. Это помогает рассчитать прирост информации в Дереве решений.
![]()
Формула энтропии
Примесь Джини:
Примесь Джини также используется для измерения случайности так же, как и энтропия. Формула примеси Джини равна:
![]()
Примесь Джини
Единственная разница заключается в том, что энтропия находится в диапазоне от 0 до 1, а примесь джини - в диапазоне от 0 до 0,5.

График смещения примеси Джини и энтропии
Получение информации:
Прирост информации - это просто разница между энтропией набора данных до и после разделения. Чем больше информации набирается, тем больше энтропии удаляется.
![]()
Получение информации
Столбец, имеющий наибольший прирост информации, будет разделен. Затем Дерево решений применяет рекурсивный алгоритм жадного поиска сверху вниз, чтобы найти информацию, полученную на каждом уровне дерева. Как только достигается конечный узел (энтропия =0), разделение больше не выполняется.
Что происходит в Дереве решений в случае проблем с классификацией?
Наша главная задача - уменьшить нечеткость или случайность данных. В задачах классификации мы используем энтропию для измерения примеси, а затем применяем разделение и видим прирост информации. Если прирост информации будет самым высоким, то мы рассмотрим разделение. Этот процесс будет идти рекурсивно до тех пор, пока мы не достигнем конечного узла или энтропия данных не станет равной нулю.

Дерево решений
Какие термины используются в Дереве решений в случае регрессии?
Ошибка:
Как и в задачах классификации, Дерево решений измеряет примесь путем вычисления энтропии или примеси Джини. В регрессии мы вычисляем ошибку дисперсии.
![]()
Среднеквадратичная Ошибка
Сокращение дисперсии:
Как и в задачах классификации, Дерево решений измеряет прирост информации. В регрессии мы вычисляем уменьшение дисперсии, что просто означает уменьшение ошибок. Мы находим разницу между ошибкой набора данных после и до разделения.
Что происходит в дереве решений в случае проблем с регрессией?
В задачах регрессии Дерево решений пытается идентифицировать группу точек, чтобы провести границу решения. Дерево решений рассматривает каждую точку и проводит границу, вычисляя ошибку точки. Этот процесс продолжается для каждой точки, затем из всех ошибок считается, что наименьшая точка ошибки проводит границу.
Этот процесс очень затратен с точки зрения вычислительного времени. Таким образом, Дерево решений выбирает жадный подход, при котором узлы делятся на две части в заданном состоянии.
Каковы преимущества и недостатки дерева решений?
Преимущества:
Дерево решений - один из самых простых алгоритмов для понимания и интерпретации. Кроме того, мы можем визуализировать дерево.
Дерево решений требует меньшего времени предварительной обработки данных по сравнению с другими алгоритмами.
Стоимость использования дерева решений является логарифмической
Он может быть использован как для задач регрессии, так и для задач классификации.
Он способен решать проблемы с несколькими выходами.
Недостатки:

Переоснащение дерева решений
Основным недостатком Дерева решений является проблема переобучения.
Дерево решений может быть нестабильным из-за введения новых точек данных, что приведет к созданию совершенно нового дерева.
Предсказания деревьев решений не являются ни гладкими, ни непрерывными, а кусочно-постоянными приближениями, как показано на приведенном выше рисунке. Следовательно, они не очень хороши в экстраполяции.
Каково решение недостатков Дерева решений?
Для проблемы переобучения мы можем ограничить высоту, узлы или листья дерева решений путем гипернастройки модели. Этот процесс называется Обрезкой деревьев.
Чтобы справиться с нестабильным деревом решений, мы можем использовать ансамблевую технику, подобную самому известному “Случайному лесу”.
Как реализовать дерево решений с помощью Scikit-learn?
Часть кодирования дерева решений очень проста, поскольку мы используем пакет scikit-learn, нам просто нужно импортировать из него модуль дерева решений.
Сначала мы импортируем необходимые модули из python.

В этом примере мы используем набор данных из GitHub, который касается качества вина.

Поскольку набор данных не имеет нулевого значения, мы просто разделим его на обучающие, тестовые наборы.

Now, just train the model.

Accuracy score:

Plotting the graph:

Если вы хотите подробнее изучить часть кодирования или хотите знать, как я настраиваю гиперпараметр. Затем, пожалуйста, нажмите на приведенную ниже ссылку на репозиторий Github.
article_blogs_content/All_About_Decision_tree.ipynb на главной странице · Akashdawari/article_blogs_content
Этот репозиторий содержит записные книжки jupyter, касающиеся статей, опубликованных в блогах. …
Ставьте лайк и делитесь, если найдете эту статью полезной. Кроме того, следите за мной на medium, чтобы получить больше контента, связанного с машинным обучением и глубоким обучением.
Источник: pub.towardsai.net