Создаем простой ETL на Python
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-05-05 21:28

Обзор решения на Python
В работе аналитика данных часто приходится использовать наборы данных, загружаемые из открытых источников. Рассмотрим простой пример использования конвейера для таких задач.
ETL, сокращение от extract-transform-load, представляет собой серию процессов, которые включают в себя сбор данных, их обработку и хранение в безопасном и доступном месте. Конвейеры ETL (ETL pipeline) позволяют упростить эти процессы с максимальной эффективностью и минимальными издержками.
Рассмотрим пошаговую реализацию конвейера ETL с использованием модулей Python.
Сбор данных (Extract)
В этот момент все "сырые" данные собраны, но вряд ли они пригодны для использования. Преобразуем данные для удобства их использования. Перечислим основные типы преобразований:
Очистка данных
Все неиспользуемые записи и переменные должны буть удалены. Очистка данных может осуществляться в виде удаления признаков, отсутствующих значений, дубликатов или статистических выбросов.
Переформатирование
Часто данные полученные из разных источников нуждаются в переформатировании. Даже если разные источники содержат одну и ту же информацию, они могут быть в собственных уникальных форматах. Например, два источника могут иметь признак даты, но в разных форматах: day-month-year и month-day-year. Такие данные нуждаются в приведении к единому формату.
Извлечение признаков
Новые признаки могут быть созданы на основе информации существующих признаков. В качестве примера можно привести преобразования строки в дату.
Агрегация
Данные могут быть агрегированы для получения необходимых показателей (количество клиентов, доход и т.п.).
Объединение
Данные из нескольких источников могут быть объединены в один набор данных.
Фильтрация
Исключение ненужных категорий из набора данных.
Загрузка
После применения всех преобразований набор данных пригоден для анализа, но его необходимо загрузить в хранилище данных для последующего использования. В этой заключительной фазе ETL загружает данные в безопасное и доступное хранилище.
Реляционная база данных
Реляционные базы данных являются наиболее популярными для хранения данных. Используя такой подход пользователи могут добавлять или перезаписывать данные в базе данных новыми наборами.
Плоские файлы
Пользователи также имеют возможность хранить свои данные в плоских файлах (например, электронных таблицах Excel, текстовых файлах). Эти файлы могут быть загружены в хранилище Big Data, например в HDFS.
Изучаем пример
Рассмотрим ETL процессы на простом примере на Python.
Предположим, нам нужно получить данные о новостных статьях, связанных с COVID-19, для какого-то анализа.
Для достижения этой цели мы напишем программу, которая может:
-
собирать данные о новостных статьях о COVID-19, опубликованных на текущую дату,
-
преобразовывать данные так, чтобы они были пригодны для использования,
-
хранить данные в базе данных.
С помощью этого конвейера мы можем получить информацию обо всех новостных статьях на текущую дату. Запуская программу каждый день, мы получим непрерывный поток данных о новостных статьях COVID-19.
Модули, необходимые для упражнений, показаны ниже:
# import libraries import requests import json import pandas as pd from pandas.io.json import json_normalize from sqlalchemy import create_engineПримечание: это упражнение включает извлечение данных с использованием New York Times Article Search API. Если вы не знакомы с этим API или с использованием API для сбора данных в целом, ознакомьтесь с этой статьей: Data Collection With API — For Beginners.
Шаг 1. Сбор данных
Во-первых, нам нужно получить сырые данные новостных статей о COVID-19, используя API New York Times.
Создадим функцию, которая создает URI, необходимый для выполнения необходимых запросов с API для любого заданного промежутка времени.
def get_URI(query:str, page_num:str, date:str, API_KEY:str) -> str: """# возвращет URL к статьям для текущего запроса по номеру страницы и дате """ # добавляем запрос к uri URI = f'https://api.nytimes.com/svc/search/v2/articlesearch.json?q={query}' # добавляем номер страницы и дату URI = URI + f'&page={page_num}&begin_date={date}&end_date={date}' # добавляем ключ API URI = URI + f'&api-key={API_KEY}' return URI Используем эту функцию для получения всех новостных статей, относящихся к COVID-19, которые опубликованы в выбранную дату.
Из-за того, что API предоставляет только 10 статей на запрос, нам нужно делать несколько запросов, пока мы не соберем все данные, которые затем хранятся во фрейме данных.
import time import datetime # создаем датафрейм для хранения всех записей df = pd.DataFrame() # получаем текущую дату current_date = datetime.datetime.now().strftime('%Y%m%d') # собираем данные со всех доступных страниц page_num = 1 while True: # получаем URI с записями, относящимся к замним олимпийским играм на текущую дату URI = get_URI(query='COVID', page_num=str(page_num), date=current_date, API_KEY=API_KEY) # делаем запрос по URI response = requests.get(URI) # преобразуем результат в формат JSON data = response.json() # преобразуем данные в фрейм данных df_request = json_normalize(data['response'], record_path=['docs']) # прерываем цикл если отсутсвуют новые записи if df_request.empty: break # добавляем записи в конец дата фрейма df = pd.concat([df, df_request]) # пауза для требования по количеству запросов time.sleep(6) # переходим на следующую страницу page_num += 1 Выводим список признаков в наборе данных.
df.info()
Шаг 2. Преобразование
Убедимся, что данные обрабатываются так, чтобы их можно было использовать.
Из доступных признаков требуются только заголовок новостной статьи, URL-адрес, дата публикации и автор. Кроме того, собранные статьи должны быть беспристрастными и объективными, а это означает, что Op-ed статьи нежелательны.Для такого сценария идеальными преобразованиями являются очистка и фильтрация данных. Все записи с отсутствующими заголовками, а также любые дубликаты должны быть удалены. Далее, поскольку мы ищем объективные статьи, все op-ed статьи должны быть отфильтрованы из набора данных. Наконец, любые нерелевантные записи должны быть уделены.
# ищем дубликаты и удаляем их if len(df['_id'].unique()) < len(df): print('There are duplicates in the data') df = df.drop_duplicates('_id', keep='first') # ищем и удаляем записи без заголовков if df['headline.main'].isnull().any(): print('There are missing values in this dataset') df = df[df['headlinee.main'].isnull()==False] # фильтруем op-ed статьи df = df[df['type_of_material']!='op-ed'] # оставляем только поля headline, publication_date, author name и url df = df[['headline.main', 'pub_date', 'byline.original', 'web_url']] # переименовываем колонки columns df.columns = ['headline', 'date', 'author', 'url'] Просмотрим полученный набор данных
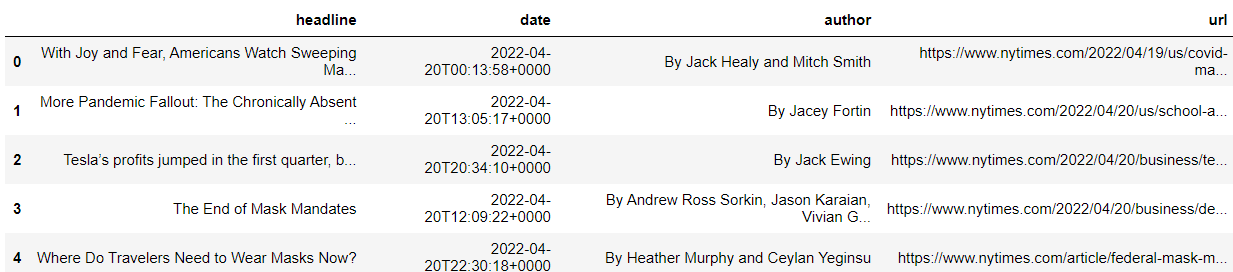
Шаг 3. Загрузка
Данные представлены в необходимом формате и могут быть загружены в реляционную базу данных, например PostgreSQL. Для этого используем механизмы отображения объектов (ORM) из модуля SQLAlchemy.
# создаем объект engine для БД database_loc = f"postgresql://{username}:{password}@localhost:5432/{database}" engine = create_engine(database_loc) # Добавляем данные в БД df_test.to_sql(name='news_articles', con=engine, index=False, if_exists='append') Мы используем подключение к уже существующей базе данных, используя данный подход мы сохранили данные в таблицу с названием "news_articles". Если таблица уже создана, то данные будут добавлены в конец таблицы, в противном случае данные будут перезаписаны. Такой подход позволяет сохранить данные, загруженные ранее.
Сейчас данные загружены в указанное расположение и могут быть доступны через SQL запрос.
-- Просмотр набора данных в БД SELECT * FROM news_articles LIMIT 5;
Используя несколько модулей мы построили простой конвейер ETL который:
-
собирает данные с помощью API,
-
обрабатывает и очищает информацию,
-
сохраняет преобразованную информацию в базе данных для дальнейшего использования.
В целом, код будет обрабатывать все новостные статьи, связанные с COVID-19, опубликованные не позднее указанной даты. Теоретически, если бы пользователь запускал эту программу ежедневно в течение года, он получил бы все соответствующие данные о новостных статьях COVID-19 за весь год.
Дополнительные инструменты
Хотя демонстрация показала, что ETL можно выполнять с помощью простой программы, конвейеры данных для реальных бизнес-кейсов более сложны и часто требуют включения других инструментов и технологий.
Облачные платформы
В примере преобразованные данные хранятся на локальной машине. Однако, когда задействованы большие объемы данных, хранение данных локально нецелесообразно. Таким образом, довольно часто используются облачные платформы (AWS, GCP, Яндекс Облако) для хранения данных.
Фреймворки Big data
При работе с большими данными конвейерам ETL может потребоваться использования крупномасштабных платформ обработки данных (например, Apache Spark), которые ускорят операции используя параллельную обработку.
Планировщики заданий
Процесс ETL редко бывает одноразовой работой, возможно, потребуется периодически собирать данные, чтобы они оставались актуальными. Предполагая, что вы не робот, который никогда не болеет и работает 24/7, вам может потребоваться использовать планировщик заданий (например, Apache Airflow) для автоматизации рабочих процессов ETL.
Заключение

Когда я был новичком, я понимал концепцию ETL, но всегда был напуган сложным кодом, который потребуется для его выполнения. Надеюсь, я показал, что конвейеры ETL могут быть созданы с базовыми знаниями программирования. Если вы новичок, используя эту статью, можете попробовать создать свой собственный конвейер. Как только вы освоитесь, не стесняйтесь добавлять больше инструментов в свой арсенал. В кратчайшие сроки вы сможете создавать сложные конвейеры, которые могут быть использованы в реальных бизнес-кейсах.
Желаю вам удачи в ваших начинаниях в области науки о данных!
Источник: habr.com