Руководство по Dask: инструмент параллельных вычислений на Python для инженеров Data Science
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-04-21 14:53
теория программирования, машинное обучение python, анализ больших данных

Параллельные вычисления - это своего рода вычисления, которые выполняют несколько вычислений или процессов одновременно.
Когда вы открываете большой набор данных с помощью Python Pandas и пытаетесь получить несколько показателей, все это просто плохо останавливается. Если вы регулярно работаете с большими данными, вы, вероятно, знаете, что если вы используете Pandas, простая загрузка ряда для пары миллионов строк может занять до минуты! В промышленности для этого используется термин / метод параллельных вычислений. Что касается параллельных вычислений, в этой статье мы рассмотрим параллельные вычисления и библиотеку Dask, которая является предпочтительной для таких задач. Мы также рассмотрим различные функции машинного обучения, также доступные в Dask. Ниже приведены основные моменты, которые необходимо обсудить.
содержание
- Что такое параллельные вычисления?
- Потребность в Dask
- Что такое Dask?
- Реализация фрейма данных Dask
- Dask
- Даск МЛ
Давайте начнем с понимания параллельных вычислений.
Что такое параллельные вычисления?
Параллельные вычисления - это своего рода вычисления, которые выполняют несколько вычислений или процессов одновременно. Большие проблемы часто разбиваются на более мелкие, которые могут быть решены одновременно. Параллельные вычисления можно разделить на четыре типа: параллелизм на уровне битов, команд, данных и задач. Параллелизм уже давно используется в высокопроизводительных вычислениях, но в последнее время он набирает обороты из-за физических ограничений, ограничивающих рост частоты.
Программное обеспечение делит проблему на более мелкие задачи или подзадачи, как только оно начинает работать. Каждая подзадача выполняется независимо, без вмешательства извне, и затем результаты объединяются для получения конечного результата.
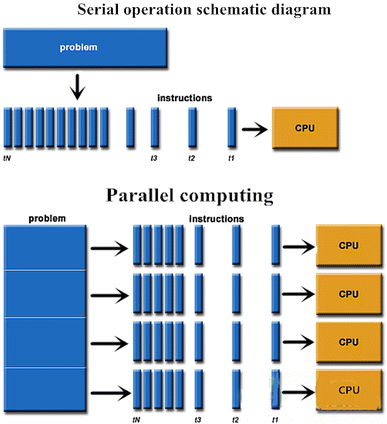
Схема последовательных и параллельных вычислений
Параллельные вычисления и параллельные вычисления обычно путают и используют взаимозаменяемо, но они различны: параллелизм может существовать без параллелизма (например, параллелизм на уровне битов), а параллелизм может существовать без параллелизма (например, многозадачность за счет разделения времени на одноядерном процессоре). Компьютерная работа часто разбивается на множество, часто очень похожих подзадач, которые могут выполняться по отдельности и результаты которых затем объединяются после завершения в параллельных вычислениях.
Многоядерные и многопроцессорные компьютеры имеют множество обрабатывающих частей в рамках одной системы, в то время как кластеры, MPP и сетки выполняют одну и ту же задачу с использованием нескольких компьютеров. Для ускорения определенных действий иногда наряду с обычными процессорами используются специализированные архитектуры параллельных компьютеров.
Потребность в Dask
Numpy, pandas, sklearn, seaborn и другие библиотеки Python упрощают работу с данными и машинным обучением. Пакета python [pandas] достаточно для большинства задач анализа данных. Вы можете манипулировать данными различными способами и использовать их для разработки моделей машинного обучения.
Однако по мере того, как объем ваших данных будет превышать объем доступной оперативной памяти, pandas станет недостаточно. Это довольно типичная проблема. Чтобы преодолеть это, вы можете использовать Spark или Hadoop. Однако это не среды Python. Это не позволяет вам использовать NumPy, sklearn, pandas, TensorFlow и другие популярные пакеты машинного обучения Python. Есть ли способ обойти это? Да! Вот тут-то в дело вступает Даск.
Что такое Dask?
Dask - это основанная на Python расширяемая библиотека параллельных вычислений с открытым исходным кодом. Это платформа для разработки распределенных приложений. Он не загружает данные сразу; вместо этого он просто указывает на данные, и только соответствующие данные используются или отображаются пользователю. Dask может использовать больше, чем одноядерный процессор, и использует параллельные вычисления, что делает его невероятно быстрым и эффективным при работе с большими наборами данных. Это предотвращает ошибки, вызванные переполнением памяти.
Dask использует многоядерные процессоры для эффективного выполнения параллельных вычислений в одной системе. Например, если у вас четырехъядерный процессор, Dask может эффективно обрабатывать все четыре ядра вашей системы одновременно. Dask хранит все данные на диске и обрабатывает фрагменты данных (меньшие части, а не все данные) с диска, чтобы потреблять меньше памяти во время вычислений. Для экономии памяти сгенерированные промежуточные значения удаляются как можно быстрее во время процедуры.
Короче говоря, Dask может эффективно обрабатывать данные на кластере компьютеров, поскольку он использует все ядра подключенных рабочих станций. Тот факт, что все машины не обязательно должны иметь одинаковое количество ядер, является интересным аспектом. Если одна система имеет два ядра, а другая - четыре, Dask может терпеть разницу в количестве ядер.
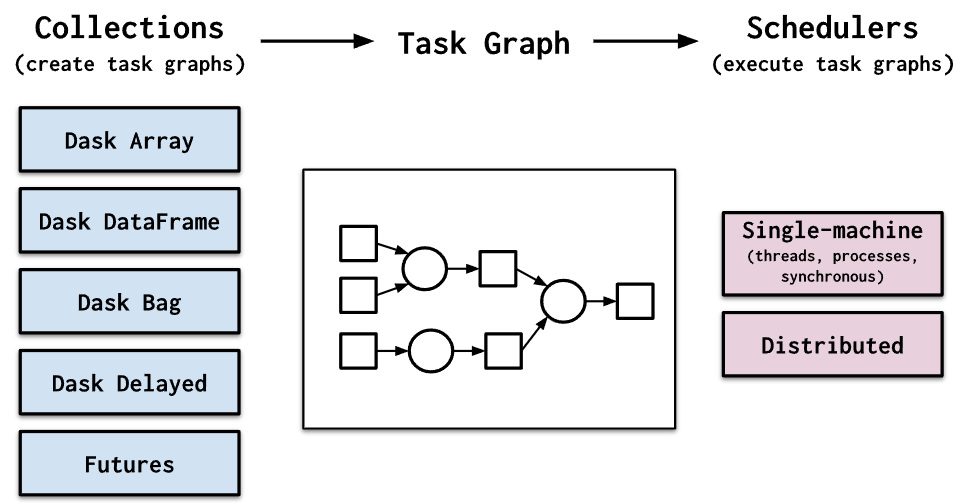
Dask имеет два семейства планировщиков задач:
- Планировщик с одним компьютером обеспечивает базовые функции для локального процесса или пула потоков. Этот планировщик был создан первым и используется по умолчанию. Он прост и недорог в использовании. Он ограничен одной машиной и не масштабируется.
- Распределенный планировщик: Это более продвинутый планировщик. У него больше функций, но для настройки требуется немного больше усилий. Он может работать на одной машине или быть распределен по нескольким машинам в кластере.
Dask выделяет следующие достоинства:
- Знакомо: Распараллеленный массив NumPy и объекты фрейма данных Pandas знакомы.
- Гибкость: Предлагает интерфейс планирования задач для более настраиваемых рабочих нагрузок и интеграции проектов.
- Native: Предоставляет доступ к стеку PyData и позволяет выполнять распределенные вычисления на чистом Python.
- Быстро: Работает с небольшими накладными расходами, задержками и сериализацией, все это требуется для быстрых численных вычислений.
- Масштабируемость: надежно работает на кластерах с тысячами ядер.
- Уменьшение масштаба: Простая настройка и запуск в одном процессе на ноутбуке.
- Отзывчивый: Он разработан с учетом интерактивных вычислений, поэтому обеспечивает быструю обратную связь и диагностику, чтобы помочь людям.
Внедрение Dask
Прежде чем использовать функциональность dask, нам необходимо установить его. Его можно просто установить с помощью команды pip как python –m pip install “dask [complete]”, которая установит все функциональные возможности dask, а не только основные функциональные возможности.
Dask предлагает множество пользовательских интерфейсов, каждый из которых имеет свой собственный набор параллельных алгоритмов распределенных вычислений. Массивы, построенные с помощью parallel NumPy, фреймы данных, построенные с помощью parallel pandas, и машинное обучение с помощью parallel scikit-learn используются специалистами в области обработки данных, стремящимися масштабировать NumPy, pandas и scikit-learn.
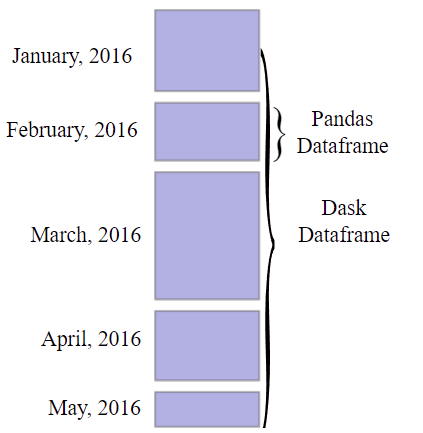
Фрейм данных Dask
Фреймы данных Dask состоят из меньших фреймов данных pandas. Огромный фрейм данных pandas делится на несколько меньших фреймов данных строка за строкой. Эти крошечные фреймы данных можно найти на диске одной машины или на дисках нескольких машин (что позволяет хранить наборы данных размером, превышающим объем памяти). Каждое вычисление фрейма данных Dask распараллеливает операции с существующими фреймами данных pandas.
Структура фрейма данных Dask показана на рисунке ниже:
Текст Сайты Документы Картинки
Теперь ниже мы сравним время, затраченное библиотекой pandas и диском на загрузку CSV-файла большого размера, и сравним результат. CSV-файл содержит усеченный корпус с английского на хинди, который весит около 35 МБ и содержит почти 1 25 000 экземпляров.
# loading file with pandas import pandas as pd %time data_1 = pd.read_csv('/content/drive/MyDrive/data/Hindi_English_Truncated_Corpus.csv')Output

# loading the file using dask import dask.dataframe as dd %time data = dd.read_csv("/content/drive/MyDrive/data/Hindi_English_Truncated_Corpus.csv") Output

Как мы видим, скорость загрузки dask намного выше, чем у pandas.
Даск МЛ
Dask ML предоставляет масштабируемые методы машинного обучения на Python, совместимые с scikit-learn. Сначала мы рассмотрим, как scikit-learn обрабатывает вычисления, а затем мы рассмотрим, как Dask по-разному обрабатывает аналогичные операции. Хотя scikit-learn может выполнять параллельные вычисления, его нельзя масштабировать до нескольких машин. Dask, с другой стороны, хорошо работает на одной машине и может быть масштабирован до кластера.
Используя Joblib, sklearn поддерживает параллельную обработку (на одном процессоре). Чтобы распараллелить несколько оценщиков sklearn, вы можете использовать Dask напрямую, добавив несколько строк кода (без изменения существующего кода).
Dask ML реализует простые методы машинного обучения, которые используют массивы Numpy. Чтобы обеспечить масштабируемые алгоритмы, Dask заменяет массивы NumPy массивами Dask. Это было реализовано для следующих целей:
Линейные модели (линейная регрессия, логистическая регрессия, регрессия Пуассона)
Предварительная обработка (масштабирование, преобразования)
Агрегирование (k-средние, спектральная кластеризация)
И они могут быть реализованы, как показано ниже,
! pip install dask-ml # ML model from dask_ml.linear_model import LogisticRegression model = LogisticRegression() model.fit(data, labels) # Pre-processing from dask_ml.preprocessing import OneHotEncoder encoder = OneHotEncoder(sparse=True) result = encoder.fit(data) # Clustering from dask_ml.cluster import KMeans model = KMeans() model.fit(data)
Вывод
В этом посте мы подробно рассмотрели, что такое параллельные вычисления и почему это важно, когда речь идет о выполнении ориентированных на данные операций с многомерными данными, или, короче говоря, мы можем сказать, что благодаря параллельным вычислениям время, необходимое для выполнения определенных операций с большими данными, значительно сокращается, как мы видели в примере выше. Позже мы увидели библиотеку Dask, которая может помочь нам выполнять операции с большими данными.
Источник: analyticsindiamag.com