Почему GPU обманывают о своей нагрузке и как с этим бороться
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-04-26 15:08

Мир машинного обучения сейчас движется по пути внедрения foundation-моделей, к которым относится и YaLM. Речь идёт о больших системах — каждая обучается один раз и требует огромных ресурсов, а дальше её можно довольно быстро дообучить под конкретное применение (например, для ранжирования ответов в поиске). Это примерно как научить делать конкретные задачи человека, уже способного читать и писать. Более подробно концепция описана у Григория Сапунова. В данном случае распределённое обучение — это когда GPU на разных узлах (хостах) c помощью библиотеки NCCL соединяются вместе и работают как единое целое, синхронно выполняя повторяющийся набор шагов, который выглядит примерно так:
- MPI_barrier (MPI — протокол распределенных вычислений, MPI_barrier — способ синхронизации).
- Каждый отдельный GPU считает свой фрагмент данных N(i).
- Обменивается с соседями полученным результатом через NCCL-API.
- Дожидается окончания шага (3).
- GOTO 1 (цикл повторяется).
На первый взгляд, ничего подозрительного не происходило. GPU и CPU заняты. Но глаз зацепился за то, что при стопроцентной утилизации GPU они совершенно холодные и не потребляют энергии.
nvidia-smi --query-gpu=gpu_bus_id,power.draw,temperature.gpu,utilization.gpu --format=csv pci.bus_id, power W, temp, utilization 00000000:08:00.0, 78.66 W, 33, 100 % 00000000:0E:00.0, 78.77 W, 32, 100 % 00000000:48:00.0, 81.93 W, 32, 100 % 00000000:4D:00.0, 72.39 W, 33, 100 % 00000000:87:00.0, 78.25 W, 33, 100 % 00000000:8B:00.0, 75.87 W, 32, 100 % 00000000:C7:00.0, 77.23 W, 33, 100 % 00000000:CA:00.0, 79.10 W, 32, 100 %Это выглядит очень странно — принцип Ландауэра ещё никто не отменял. Если нет потребления энергии, значит, и вычислений нет, а цифры утилизации — непонятный артефакт. Выяснилось, что треды на самом деле постоянно зовут
yield(), и стек приложения выглядит так:->completeColl ->testStreamSynchronize { int remaining = ngpus; while (remaining) { for (int i=0; i<ngpus; i++) { if (done[i]) continue; cudaErr = cudaStreamQuery(streams[i]); <===== FAKE HIGH GPU UTILIZATION if (cudaErr == cudaSuccess) { done[i] = 1; remaining--; continue; } .... yield()Синхронизация данных на шаге (4) происходит через
busy_loop, который и даёт нам фейковую утилизацию GPU. Использование busy_loop в данном случае вполне оправдано, так как мы имеем дело со скоростями порядка 24 ГБ/с. Фейковая утилизация — побочный эффект того, что мы ждём завершения обмена данными от шага (3). Почему же данные по RDMA передаются настолько долго, что GPU успевают остыть после шага (2)? Причина оказалась комплексной, но очевидной.Слабые места InfiniBand-фабрики
Для начала мы поймали:
- Баги в роутинге InfiniBand, когда по одному из маршрутов данные текут в 100 раз медленнее, чем должны. Эта проблема испортила нам много нервов, я уже рассказывал о ней.
- Физические проблемы кабелей: если InfiniBand-кабель неудачно согнуть, он начинает портить данные, принимающая сторона начинает терять битые пакеты, а потери на таких скоростях — катастрофа. Данные передаются в 100 раз медленнее, чем нужно. Именно это тормозило распределённое обучение, которое пытался запустить коллега. NCCL периодически менял маршруты передачи данных — тогда обучение оживало. А потом снова попадало на битый кабель и замирало.
Проблемные кабели нашли и заменили, наладили автоматическую починку. Самый важный индикатор ошибок InfiniBand — это счётчик symbol_errors, за ним обязательно должна следить автоматика. Но проблема не исчезла. На кластере всё равно оставались процессы, которые показывали фейковую утилизацию. Только выглядели они теперь чуть-чуть по-другому.
FLP impossibility in action
Второй класс проблем выглядел так: семь GPU показывали фейковую стопроцентную утилизацию, а восьмой — 0%.
nvidia-smi --query-gpu=gpu_bus_id,power.draw,temperature.gpu,utilization.gpu --format=csv pci.bus_id, power.draw [W], temperature.gpu, utilization.gpu [%] 00000000:08:00.0, 78.41 W, 32, 100 % 00000000:0E:00.0, 77.84 W, 31, 100 % 00000000:48:00.0, 81.60 W, 31, 100 % 00000000:4D:00.0, 72.46 W, 32, 0 % 00000000:87:00.0, 78.01 W, 32, 100 % 00000000:8B:00.0, 75.62 W, 31, 100 % 00000000:C7:00.0, 76.71 W, 32, 100 % 00000000:CA:00.0, 78.77 W, 31, 100 %Причина оказалась банальной: если один из процессов в распределённом обучении падал, то остальные этого не замечали и бесконечно ждали от него данных. Всё в соответствии с самой знаменитой теоремой распределённых алгоритмов — the FLP impossibility:
In this paper, we show the surprising result that no completely asynchronous consensus protocol can tolerate even a single unannounced process death. M. J. FISCHER, N. A. LYNCH, AND M. S. PATERSON Journal of Computing Machinery, 2, April 1985Чтобы алгоритм стал устойчивым к сбоям, нужно сделать его асинхронным не полностью, а частично. А именно — добавить таймаут на каждую операцию. Это знает каждый, кто занимается распределёнными алгоритмами. Авторам PyTorch это тоже известно, поэтому они добавили таймаут на групповые операции, но проблема в том, что он не включён по дефолту при использовании NCCL. В результате алгоритм висел, пока автор задачи не вспоминал, что запущенная операция почему-то до сих пор не завершилась. Мы выяснили что такие зависшие обучения занимали 2–3% наших кластеров (на наших объёмах это больше 1 PFLOPS) и стоили компании десятки тысяч долларов в месяц. Это поправили явным выставлением переменной
NCCL_ASYNC_ERROR_HANDLING=1 для всех обучений.Важно: эта опция работает только для PyTorch. В других библиотеках детектирование зависаний может потребовать других опций, либо не иметь такой механики вовсе. В этом случае пользователю нужно самому детектировать зависание распределённого алгоритма.
Самый простой способ проверить, умеет ли ваша библиотека или инфраструктура детектировать зависание, — явно спровоцировать его. Например, добавив
sleep(3600) в случайное место алгоритма. Вот тест на зависание NCCL. Для наших кластеров мы реализуем детектирование зависающих обучений на уровне планировщика задач YT, о принципах его работы ниже. Закон Амдала наносит ответный удар
После внедрения механики детектирования зависших обучений мы начали получать много ложнопозитивных сигналов от обучений, которые не зависли окончательно, а периодически замирали по непонятной причине. Разберём наглядный пример: обучение на восьми узлах (64 GPU) часто показывает стопроцентную утилизацию сразу на всех GPU, а потребление энергии остаётся на минимуме. Это явный признак проблем в обмене данными. Но уверенности в том, что это реальная проблема, нет.
Чтобы проверить, существует ли проблема, нужно построить «кардиограмму» распределённого обучения. Для этого не нужно знать точную логику работы обучения, достаточно построить график GPU_power + net_bw в хорошем разрешении, чтобы стали видны отдельные шаги обучения.
Вот так выглядят первые 10 секунд. Всё понятно: один шаг обучения длится примерно секунду, и обмен данными занимает лишь малую его часть.

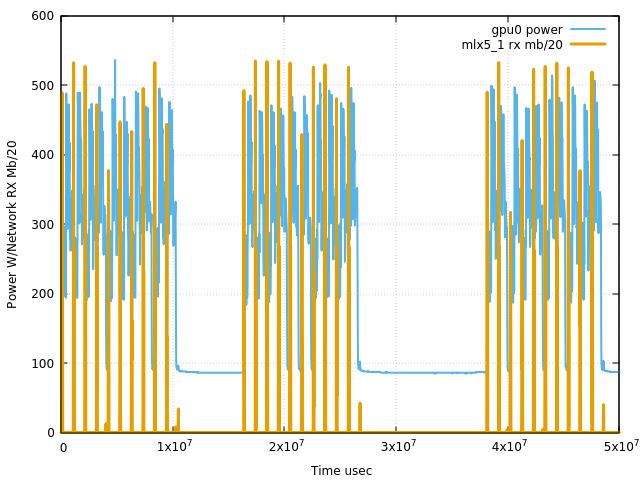
После осознания проблемы решить её не составило труда. Сохранение снапшота сделали шардированным и асинхронным, после чего проблема исчезла.
Методика построения кардиограмм распределённого обучения помогла нам обнаружить огромное количество неоптимальных мест. Даже когда мы внедрили ZeRo3, где вычисления и коммуникации происходят параллельно, подвисания, вызванные внешней коммуникацией, по-прежнему отлично видны.
Нехватка CPU при работе с RDMA
Четвёртый класс проблем, на которые мы наступили, был менее очевидным, и в чём-то более обидным.
При запуске обучения пользователь должен указать количество ресурсов, которое будет доступно его процессу, а именно количество CPU, RAM, NR_GPUS. Пользователи привыкли заказывать много памяти и нужное количество GPU карточек, но часто заказывали слишком мало CPU.
Обычно наши ML-инженеры пишут и отлаживают свой код на одном узле, где обмен данными между GPU происходит через NVLink. Ошибка заказа CPU там практически не заметна: CPU практически не используется, вся работа выполняется исключительно на GPU. Но когда пользователь решает, что его код готов, и запускает свое обучение на нескольких узлах, то данные передаются по RDMA. В этом случае детектирование завершения передачи данных через RDMA происходит через busy_loop на CPU, как я описывал выше. Соответственно, если пользователь заказал недостаточно CPU, мы не будем успевать детектировать завершение передачи данных вовремя, и эффективная скорость работы RDMA будет в несколько раз ниже, а GPU будут простаивать. По нашим замерам, минимальный разумный CPU_LIMIT для контейнера, в котором запускается распределённое обучение — 4*CPU_CORES*NR_GPUS. А если ваш контейнер использует все доступные GPU на узле, то разумно выставлять лимит равным максимальному количеству CPU-ядер на узле.
Почему распределённое обучение — это сложно?
Прочитав предыдущие разделы, вы можете задать вопрос: а почему всё так сложно? Нельзя ли попроще? В этой части я объясню, почему в словосочетании «распределённое обучение» самое важное слово — «распределённое», и что распределённые алгоритмы — самая трудная область computer science. Совсем просто тут не бывает, но можно сильно упростить жизнь ML-разработчика, если дать ему удобную инфраструктуру.
В теории программирования есть три модели построения программы:
- Линейные алгоритмы. Пользователь просто описывает логику работы программы.
- Многопоточные алгоритмы. В линейную логику добавляются механизмы синхронизации нескольких потоков исполнения (spinlock, mutex и так далее).
- Распределённые алгоритмы. Многопоточные алгоритмы, в которых случаются частичные отказы отдельных компонентов или узлов.
Каждый из нас знает, что многопоточное программирование намного сложнее обычного линейного — этому учат в школах и университетах. Но почему-то не учат, что распределённые алгоритмы ещё гораздо сложнее. Возможно, потому, что раньше с распредёленными алгоритмами в реальной жизни сталкивался только узкий круг людей. Но за последние несколько лет распределённые алгоритмы стали обязательным атрибутом машинного обучения. Каждому ML-разработчику нужно обязательно держать в голове потенциальный круг проблем, с которым ему придётся столкнутся.
Когда в работе распределённого алгоритма задействованы сотни узлов (хостов), тысячи сетевых карт и GPU, вероятность случайного отказа одного из этих компонентов становится более чем реальной. Если обучение длится несколько недель, как минимум один железный сбой точно случится. Нужно понимать, что произойдёт в этом случае.
Как было показано выше, если не предпринимать никаких шагов, скорее всего распределённое обучение просто зависнет и тысячи GPU будут простаивать в бесконечном ожидании. Поэтому алгоритм распределённого обучения должен быть готов к сбоям. А именно:
- Каждая итерация алгоритма должна иметь таймаут.
- Обучение периодически должно сохранять снапшот накопленных данных на случай сбоя. Операция создания снапшота должна быть очень быстрой и не блокирующей основной поток обучения.
- Восстановление обучения из снапшота после сбоя должно быть максимально быстрым. На наших кластерах это единицы минут на маштабных обучениях, но мы хотим сократить это время как минимум на порядок.
Чтобы упростить реализацию надёжных алгоритмов, устойчивых к сбоям и зависаниям, мы сделали трёхступенчатую систему мониторинга на уровне планировщика YT:
- Перед запуском задачи автоматика тестирует все GPU и сетевые маршруты, чтобы проверить, что железо исправно.
- Запускается пользовательский код.
- Детектор дедлоков следит за прогрессом распределённого алгоритма, получая от него heartbeat. Если они перестали приходить, значит мы считаем алгоритм зависшим, и останавливаем его с ошибкой.
- Если задача завершилась с ошибкой, запускаем тестирование железа заново, как в шаге (1).
Тестирование железа на шаге (1) — очень важный момент, потому что позволяет гарантировать пользователю исправность железа во время запуска пользовательского кода, потратив всего 10–100 секунд.
Но ещё более важно повторно тестировать железо на шаге (4), потому что тестирование позволяет ответить на вопрос, почему задача упала.
Если на шаге (4) мы нашли проблемы в железе, то всё понятно. Проблемный хост исключается из кластера и уходит на углублённую диагностику, пользовательская задача перезапускается без ручного вмешательства. Но если на шаге (4) проблем с железом не обнаружено, то, скорее всего, причина падения в самом коде задачи и перезапускаться не имеет смысла. Нужно отправить уведомление автору, чтобы он сам мог разобраться с проблемой.
P. S. Я счастливый человек. Мне повезло в самом начале карьеры обжечься на сложности распределённых алгоритмов.
На предыдущем месте работы мы коллективом очень неглупых людей потратили пару недель на изобретение механизма репликации в распределённой ФС, который противоречил теореме FLP. По факту изобретали вечный двигатель. В какой-то момент к нам пришёл Александр Тормасов, показал теорему и посоветовал просто добавить таймауты в алгоритм. После этого мы быстро решили задачу. С тех пор при упоминании слова «distributed» у меня сразу же включается режим повышенного внимания, чего и вам советую.
Источник: habr.com