Optimum Transformers: как экономить от 20к$ в год на NLP
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-04-04 11:27

Недавно компания ? Hugging Face (стартап, стоящий за библиотекой transformers) выпустила новый продукт под названием "Infinity". Он описывается как сервер для выхода в “production”. Публичная демонстрация доступна на YouTube (ниже приведены скриншоты с таймингами и настройками, использованными во время демонстрации). Все основано на обещании, что продукт может выполнять работу с NLP с задержкой в 1 миллисекунду на графическом процессоре. По словам ведущего демонстрации, сервер Hugging Face Infinity стоит не менее 20.000$ в год за одну модель, развернутую на одной машине (общедоступная информация о ценовой масштабируемости отсутствует).
Мне стало любопытно немного покопаться и проверить, возможно ли достичь таких показателей? Спойлер: да, возможно, и с помощью этой статьи его легко воспроизвести и адаптировать к вашим РЕАЛЬНЫМ проектам.
А для тех, кому лень все это читать и хочется все получить из коробки... Ссылка на GitHub. Поставьте зведу сразу, а потом читайте ?
Введение
Для начала разберемся в чем проблема обычных Pytorch моделей и почему мы вдруг решили их ускорить.
Рассмотрим на примере zero-shot-classification. Самая популярная модель facebook/bart-large-mnli выполняет один запрос за более чем 1 секунду. А большие текста даже за 3.5 секунды. Можете сами потыкать по ссылке. В так называемом продакшене такая скорость ответа не самая желаемая.
Вы, наверное, знаете, что главным преимуществом Pytorch по сравнению с Tensorflow 1.X является простота использования: вместо построения графа вы просто пишете знакомый императивный код. Такое ощущение, что вы пишете numpy-код, работающий на скорости графического процессора.
Делать пользователей счастливыми - это здорово, но что еще более удивительно, так это делать счастливыми инструменты оптимизации. В отличие от людей, эти инструменты любят графы для выполнения анализа. Это имеет смысл, графы обеспечивают статическое и полное представление всего процесса, от точки данных до выходных данных модели. Более того, графы обеспечивает промежуточное представление, которое может быть общим для нескольких фреймворков машинного обучения.
Нам нужен способ преобразовать наш Pytorch-код в граф для ускорения.
Так как же нам ускорить наши модельки?
Решение есть! Это ONNX.
Процесс состоит из 3 этапов:
-
Преобразование модели Pytorch в ONNX граф.
-
Оптимизирание графа.
-
Использование привычных и приятных пайплайнов в проде.
Из Pytorch в ONNX
Что же это за магический ONNX?
ONNX - это открытый формат, созданный для представления моделей машинного обучения. ONNX определяет общий набор операторов — строительных блоков моделей машинного обучения и глубокого обучения — и общий формат файлов, позволяющий разработчикам искусственного интеллекта использовать модели с различными фреймворками, инструментами, средами выполнения и компиляторами.
-- Переведено напрямую из https://onnx.ai/
Pytorch включает в себя инструмент экспорта в ONNX. Принцип, лежащий в основе инструмента экспорта, довольно прост, мы будем использовать режим “трассировки”: мы отправляем некоторые (фиктивные) данные в модель, и инструмент будет отслеживать их внутри модели, таким образом, он будет угадывать, как выглядит график.
Звучит как-то старшно и сложно? Я тоже как думаю :) На первых этапах я делел это напрямую ручками, но это было слишком больно и неприятно. Если вы хотите понять как это работает, то для начала рекомендую к прочтению: ссылка, ссылка, ссылка.
Все мы любим тулзы из коробки, поэтому встречайте - Optimum. Эта библиотека без лишних проблем переведет любой (почти) трансформер в ONNX граф.
Давайте немного ее потыкаем для понимания. Тут есть небольшие спойлеры к оптимизации нашего графа, но вы сделайте вид, что вы ничего не видели:
from optimum.onnxruntime import ORTConfig, ORTQuantizer # The model we wish to quantize model_ckpt = "philschmid/MiniLM-L6-H384-uncased-sst2" # The type of quantization to apply ort_config = ORTConfig(quantization_approach="dynamic") quantizer = ORTQuantizer(ort_config) # Export ONNX graph quantizer.export(model_ckpt, output_path="model.onnx", feature="sequence-classification")Вот мы за пару строк кода экспортировали Pytorch модель в ONNX граф. Теперь можем приступить к оптимизации!
Оптимизация
Тут уже попроще. Но перед тем как написать одну строку кода... Давайте посмотрим как происходит оптимизация.
Мы сосредоточимся на 2 инструментах для оптимизации моделей Pytorch: ONNX Runtime от Microsoft (с открытым исходным кодом по лицензии MIT) и TensorRT от Nvidia (с открытым исходным кодом по лицензии Apache 2, механизм оптимизации с закрытым исходным кодом).
Для оптимизации моделей Pytorch есть 2 основных инструмента: ONNX Runtime от Microsoft (с открытым исходным кодом по лицензии MIT) и TensorRT от Nvidia (с открытым исходным кодом по лицензии Apache 2, механизм оптимизации с закрытым исходным кодом).
Оба инструмента выполняют одинаковые операции для оптимизации модели ONNX:
-
находят и удаляют избыточные операции: например, отсев бесполезен вне цикла обучения, его можно удалить без какого-либо влияния на вывод;
-
выполниют постоянное сворачивание: это означает найти некоторые части графика, состоящие из постоянных выражений, и вычислить результаты во время компиляции, а не во время выполнения (аналогично компилятору большинства языков программирования);
-
объединяют некоторые операции вместе: чтобы избежать времени загрузки и совместного использования памяти, чтобы избежать передачи данных туда и обратно с глобальной памятью.
Опять много умного текста на пиксель вашего экрана. Поэтому переходим к очередному коробочному решению. И это снова Optimum.
Давайте переделаем наш прошлых код:
from optimum.onnxruntime import ORTConfig, ORTQuantizer # The model we wish to quantize model_ckpt = "philschmid/MiniLM-L6-H384-uncased-sst2" # The type of quantization to apply ort_config = ORTConfig(quantization_approach="dynamic") quantizer = ORTQuantizer(ort_config) # Quantize the model! quantizer.fit(model_ckpt, output_dir=".", feature="sequence-classification" )Такс, вот мы заменили одну строчку. А что поменялось? Почти все!
Теперь на выходе мы имеем 3 модели: простой ONNX граф (model.onnx), оптимизированный граф (model-opt.onnx) и оптимизированный квантованный (понятия не имею как это перевести на русский) граф (model-quantized.onnx).
Ура! Вот мы и получили наши оптимизированные модели. Что же нам теперь с ними делать?
Пайплайн
Те кто пользовался пайплайнами оригинальных трансформеров, понимают, какие они удобные и приятные. Поэтому...
Представляю вашему вниманю - Optimum Transformers!
pip install optimum-transformersЭто комбинация восхитительных пайплайнов и скорости!
from optimum_transformers import pipeline pipe = pipeline("text-classification", use_onnx=True, optimize=True) pipe("This restaurant is awesome") # [{'label': 'POSITIVE', 'score': 0.9998743534088135}]3 строчки кода!
use_onnx - преобразует модель по умолчанию в ONNX граф
optimize - оптимизирует преобразованный ONNX граф в оптимальный
Benchmark
И вот то, ради чего мы все тут собрались!
Примечание: Эти результаты были собраны на моем локальном компьютере. Поэтому, если у вас есть высокопроизводительная машина для тестирования, пожалуйста, свяжитесь со мной.

А теперь самое интересное, что это почти такой же результат и как на презентации Infinity. У них результат на NVIDIA T4 на 128 токенов был 2.6 ms. Понятно, что у меня нет таких ресурсов.
Но наш результат показывает то, что мы используем такие же технологии как и они! А занчит и результат будет соответствовать.
Вот еще нексколько графиков:

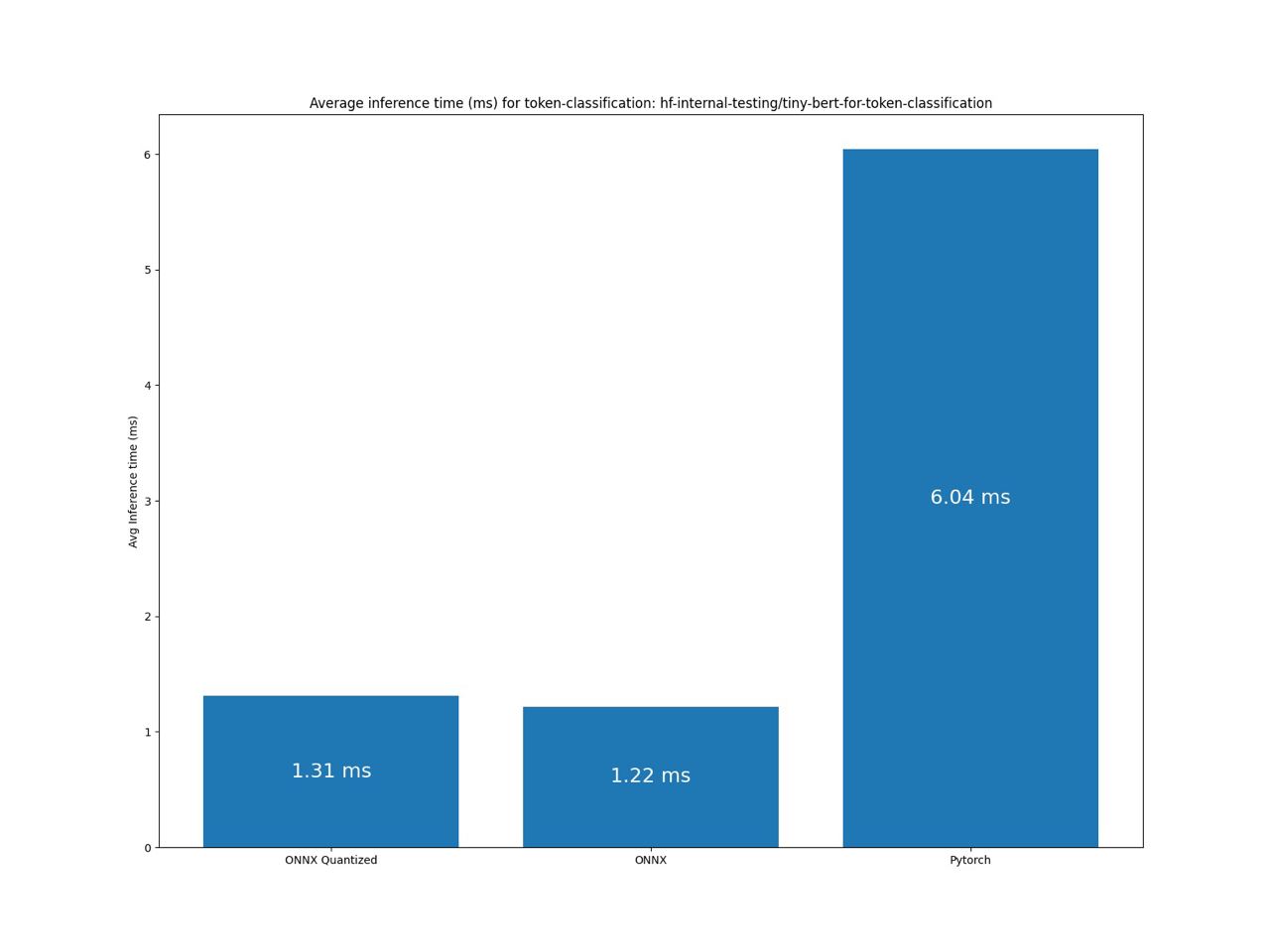
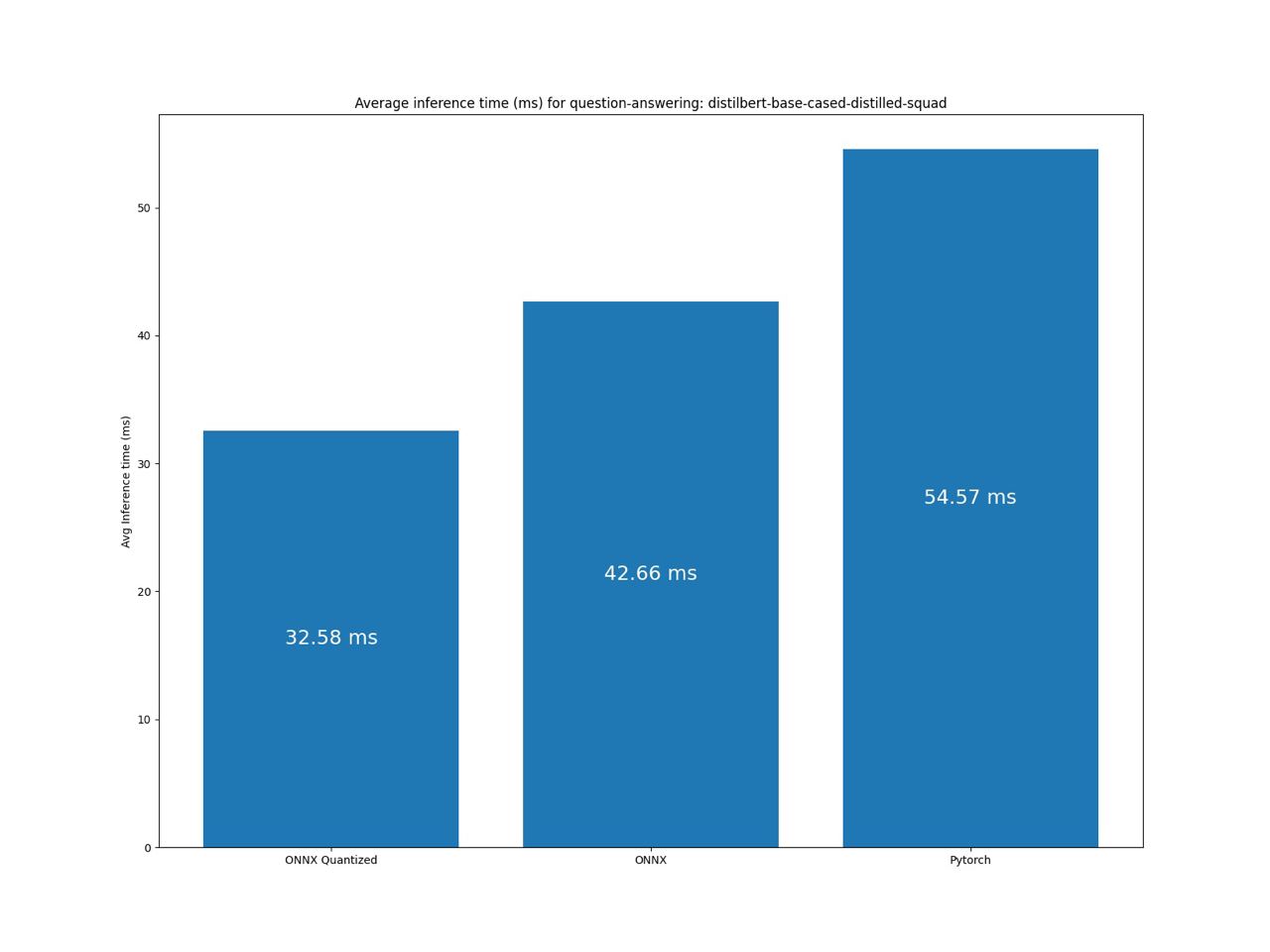
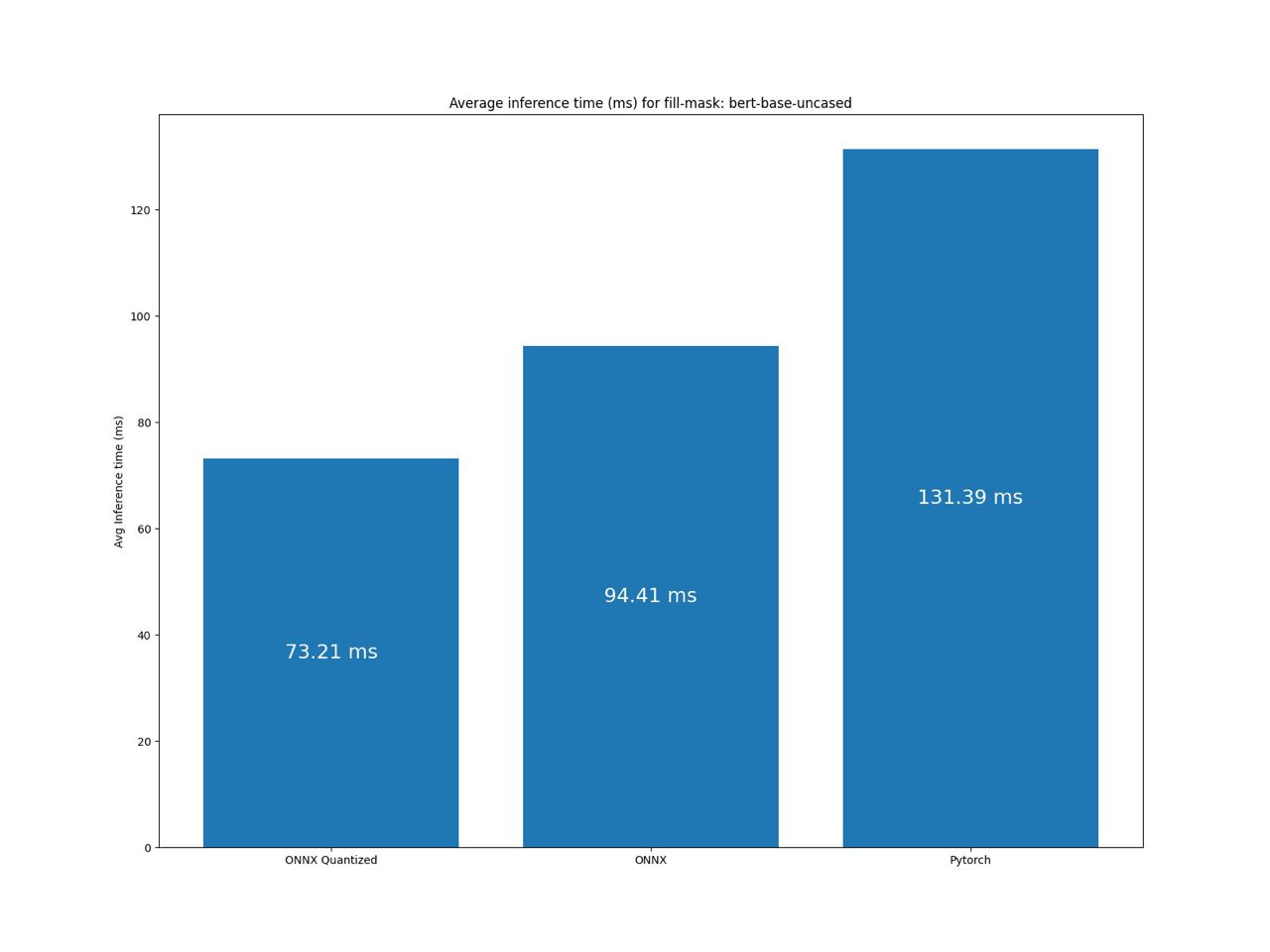
Заключение
Основываясь на результатах бенчмарка, можно сделать вывод, что мы на верном пути и используем такие же технологии что и в Infinity. А значит с уверенностью можем сказать, что мы с вами сэкономили 20.000$ в год. С чем я вас и поздравляю!
Если вы дочитали до самого конца, то попрошу вас оставить комментарий под статьей и поставить звезду на репозиторий: ссылка на Github.
Источник: habr.com