Проблемы современного машинного обучения
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2022-02-15 09:00
машинное обучение python, Трезво про ИИ, ошибки нейронных сетей
Во многих популярных курсах машинного и глубокого обучения вас научат классифицировать собак и кошек, предсказывать цены на недвижимость, покажут еще десятки задач, в которых машинное обучение вроде как отлично работает. Но вам расскажут намного меньше (или вообще ничего) о тех случаях, когда ML-модели не работают так, как ожидалось.
Частой проблемой в машинном обучении является неспособность ML-моделей корректно работать на большем разнообразии примеров, чем те, что встречались при обучении. Здесь идет речь не просто о других примерах (например, тестовых), а о других типах примеров. Например, сеть обучалась на изображениях коровы, в которых чаще всего корова был на фоне травы, а при тестировании требуется корректное распознавание коровы на любом фоне. Почему ML-модели часто не справляются с такой задачей и что с этим делать – мы рассмотрим далее. Работа над этой проблемой важна не только для решения практических задач, но и в целом для дальнейшего развития ИИ.
Конечно, этим проблемы машинного обучения не ограничиваются, существуют также сложности с интерпретацией моделей, проблемы предвзятости и этики, ресурсоемкости обучения и прочие. В данном обзоре рассмотрим только проблемы обобщения.
Содержание
Проблемы обобщения Задача обобщения в машинном обучении Утечка данных Shortcut learning: "right for the wrong reasons" Shortcut learning в языковых моделях Уровни обобщения моделей машинного обобщения Состязательные атаки Проблема неконкретизации в ML-задачах Выводы Способы решения проблем обобщения Стресс-тесты для диагностики работы модели Доменная адаптация Еще больше данных? Более крупные или более эффективные модели? Модификации способов обучения языковых моделей Архитектура моделей и структура данных Направления исследований Общий искусственный интеллект Заключение
Проблемы обобщения
Задача обобщения в машинном обучении
Задача машинного обучения заключается в написании алгоритмов, которые автоматически выводят общие закономерности из частных случаев (обучающих примеров). Этот процесс называется обобщением (generalization), или индукцией. Часто требуется найти зависимость между исходными данными  и целевыми данными
и целевыми данными  в виде функции
в виде функции  .
.
Например, требуется определить по фотографии тип или положение изображенного объекта. Для решения этой задачи можно собрать большое количество размеченных данных (supervised learning), можно также использовать ненадежно размеченные данные (weakly-supervised learning), например фотографии из Instagram c хештегами, или даже неразмеченные данные (self-supervised learning). Но в любом случае мы используем некий набор конкретных примеров.
Понятно, что чем больше доступно примеров, тем выше будет качество полученного решения (при прочих равных условиях). Больше данных – выше точность. Все логично?
Существуют даже теоремы, доказывающие для различных ML-алгоритмов стремление получаемого решения к идеалу при неограниченном увеличении количества обучающих данных и размера модели (это свойство называется universal consistency; например, для нейронных сетей см. Farag? and Lugosi, 1993). При доказательстве подобных теорем считается, что данные  берутся из некоего фиксированного, но неизвестного распределения
берутся из некоего фиксированного, но неизвестного распределения  . Такой подход называется statistical learning framework, он излагается почти в любой книге по машинному обучению (например, см. Deep Learning book, раздел 5.2, есть также русское издание).
. Такой подход называется statistical learning framework, он излагается почти в любой книге по машинному обучению (например, см. Deep Learning book, раздел 5.2, есть также русское издание).
С развитием технологий стали доступны дешевые вычисления и огромные объемы данных, что позволило эффективно решать очень сложные задачи. Например, языковая модель GPT-3 (Brown et al., 2020) от компании OpenAI обучалась на 570 Гб текстов и имеет 175 миллиардов параметров, по приблизительным подсчетам обучение стоило миллионы долларов. Примеры текстов, которые генерирует GPT-3, можно найти здесь, здесь, здесь и здесь. В Google обучили сеть с 1.6 триллиона параметров (Fedus et al., 2021), в Китае – сеть с 1.75 триллиона параметров, и это далеко не предел: уже делаются попытки обучать сеть со 120 триллионами параметров, что примерно равно количеству синапсов в человеческом мозге. Более крупные модели и больше обучающих данных - выше точность.
Казалось бы, что может пойти не так?
Рассмотрим несколько примеров, когда простого увеличения объема обучающих данных может оказаться недостаточно. Начнем с проблемы утечки данных, и затем рассмотрим более общую проблему ограниченного разнообразия обучающих данных и ситуации, когда модель лишь "делает вид", что обучается.
Утечка данных
Утечкой данных называется ситуация, когда существует некий признак, который при обучении содержал больше информации о целевой переменной, чем при последующем применении модели на практике. Утечка данных может возникать в самых разных формах.
Пример 1. При диагностике заболеваний по рентгеновским снимкам модель обучается и тестируется на данных, собранных с разных больниц. Рентгеновские аппараты в разных больницах выдают снимки с немного разной тональностью, при этом различия могут быть даже незаметны человеческим глазом. Модель может обучиться определять больницу на основе тональности снимка, а значит и вероятный диагноз (в разных больницах лежат люди с разными диагнозами), при этом вообще не анализируя изображение на снимке. Такая модель покажет отличную точность при тестировании, так как тестовые снимки взяты из той же выборки данных.
Пример 2. В задаче диагностики реальных и фейковых вакансий почти все фейковые вакансии относились к Европе. Обученная на этих данных модель может не считать подозрительными любые вакансии из других регионов. При применении на практике такая модель станет бесполезна, как только фейковые вакансии станут размещаться в других регионах. Конечно можно удалить регион из признаков, но тогда модель будет пытаться предсказать регион по другим признакам (скажем, по отдельным словам в описании и требованиях), и проблема сохранится.
Пример 3. В той же задаче есть признак "имя компании", и у компаний может быть по нескольку вакансий. Если компания фейковая, то все ее вакансии фейковые. Если мы разделим данные на обучающую и тестовую часть (или на фолды) таким образом, что вакансии одной и той же компании попадут и в обучающую, и в тестовую часть, то модели достаточно будет запомнить имена фейковых компаний для предсказания на тестовой выборке, в результате на тесте мы получим сильно завышенную точность.

Все описанные проблемы нельзя решить просто увеличением количества обучающих данных без изменения подхода к обучению. Здесь можно возразить, что утечка данных не является проблемой самих ML-алгоритмов, поскольку алгоритм и не может знать о том, какой признак нужно учитывать, а какой нет. Но давайте посмотрим на другие похожие примеры.
Shortcut learning: "right for the wrong reasons"
В начале XX века жила лошадь по имени Умный Ганс, которая якобы умела решать сложные арифметические задачи, постукивая копытом нужное число раз. В итоге оказалось, что лошадь определяет момент, когда нужно прекращать стучать копытом, по выражению лица того, кто задает вопрос. С тех пор имя "умного Ганса" стало нарицательным (1, 2) – оно означает получение решения обходным путем, не решая при этом саму задачу в том смысле, какой мы хотим. Такое обходное "решение" внезапно перестает работать, если меняются условия (например, человек, задающий вопрос лошади, сам не знает ответа на него).
Исследователи давно заметили, что многие современные модели глубокого обучения похожи на "умного Ганса". Вспомним хотя бы легендарную статью на Хабре про "леопардовый диван":
... Где-то в этот момент в мозг начинает прокрадываться ужасная догадка — а что если вот это различие в текстуре пятен и есть главный критерий, по которому алгоритм отличает три возможных класса распознавания [леопарда, ягуара, гепарда] друг от друга? То есть на самом деле сверточная сеть не обращает внимания на форму изображенного объекта, количество лап, толщину челюсти, особенности позы и все вот эти тонкие различия, которые, как мы было предположили, она умеет понимать — и просто сравнивает картинки как два куска текстуры?
Это предположение необходимо проверить. Давайте возьмем для проверки простую, бесхитростную картинку, без каких-либо шумов, искажений и прочих факторов, осложняющих жизнь распознаванию. Уверен, эту картинку с первого взгляда легко опознает любой человек.

... Похоже, что наша догадка насчет текстуры близка к истине. ... Я сделал еще пару проверок (Microsoft, Google) — некоторые из них ведут себя лучше, не подсовывая ягуара, но победить повернутый набок диван не смог никто. Неплохой результат в мире, где уже мелькают заголовки в духе "{Somebody}'s Deep Learning Project Outperforms Humans In Image Recognition".
В самом деле, зачем модели, решающей задачу классификации, выучивать форму и другие комплексные свойства объекта, называемого "леопард", если простое присутствие нужной текстуры на изображении дает почти 100%-ю точность выявления леопарда в обучающей (и тестовой) выборке из ImageNet?
То же самое касается предсказания объекта с учетом фона. Мы не закладывали при обучении никакой информации о том, на основании чего мы хотим получать предсказание: на основании объекта или окружающего его фона. Было даже обнаружено (Zhu et al., 2016), что нейронные сети способны с хорошей точностью предсказывать класс объекта, если сам объект вырезан и оставлен только фон.
Shortcut learning - явление, когда модели получают верный ответ с помощью неверных в общем случае рассуждений ("right for the wrong reasons"), которые хорошо работают только для обучающего распределения данных. Поскольку обучающая и тестовая выборка обычно берутся из одного распределения, то такие модели могут давать хорошую точность и при тестировании.
Shortcuts are decision rules that perform well on standard benchmarks but fail to transfer to more challenging testing conditions, such as real-world scenarios.
Другие примеры можно найти в замечательной статье Shortcut Learning in Deep Neural Networks (Geirhos et al., 2020), опубликованной в журнале Nature и основанной на обобщении информации из более чем 140 источников.
Смена угла поворота объекта, появление его в необычном (с точки зрения обучающей выборки) окружении, добавление необычного шума может полностью испортить работу модели. На иллюстрации ниже слева показаны пары изображений, одинаково классифицируемые с точки зрения человека, но совершенно разные с точки зрения сверточной нейронной сети. Справа показаны, наоборот, изображения, имеющие одинаковый класс для нейронной сети и разный для человека.

В целом исследователями был сделан вывод о том, что многие современные сверточные нейронные сети предпочитают ориентироваться на локальные участки текстур (Jo and Bengio, 2017; Geirhos et al., 2018), которые могут относиться как к объекту, так и к фону, и не классифицируют объект на основании его общей формы (Baker et al., 2018).
Сейчас нейронные сети начинают решать очень сложные задачи, такие как работа с трехмерными сценами, анимация объектов и прочее. Казалось бы, задача классификации собак и кошек уже давно решена? Оказывается, что нет. Как показано на примерах ниже, одна из самых современных нейронных сетей для детектирования объектов YOLOv5 может быть легко обманута необычными деталями, не относящимися к самому объекту, либо может принимать несколько объектов за один. Предсказания получены с помощью интерактивной версии YOLOv5, интерпретация выполнена с помощью Grad-CAM (Selvaraju et al., 2016; репозиторий). Оригиналы изображений можно найти по ссылкам:

,

,

,

.

Добавление собачьего корма в последнем изображении существенно повышает уверенность в распознавании собаки, хотя сам корм сеть распознает как "книгу". При этом на GradCAM зависимость ответа от наличия собачьего корма в кадре не видна, так как рамка ограничена рамкой объекта. В целом даже небольшие изменения, такие как кадрирование с обрезкой 5% фона или пересохранение в jpeg сильно меняет предсказание модели в сложных для нее случаях.
Сверточные сети для классификации, даже самые современные, часто классифицируют черных котов как породу собак схипперке (которые тоже имеют черную шерсть), даже если по морде и форме тела видно, что это кот. Имеются в виду, конечно, сети общего назначения, которые не дообучались специально для точного распознавания пород собак и кошек, хотя и в этом случае нет гарантии точного распознавания.
Jo and Bengio, 2017 используют фильтрацию, основанную на преобразовании Фурье, для внесения в изображения помех, которые не мешают распознаванию их человеком, но сильно снижают качество работы сверточных нейронных сетей. Увеличение глубины сетей не избавляет от этой проблемы. Более того, если добавить в обучающий датасет один из типов Фурье-искажений, то это не делает сеть устойчивее к другим типам Фурье-искажений (которых может быть очень много).
The current incarnation of deep neural networks exhibit a tendency to learn surface statistical regularities as opposed to higher level abstractions in the dataset. For tasks such as object recognition, ... [this is] sufficient for high performance generalization, but in a narrow distributional sense.
To this end, we draw an analogy to adversarial training: augmenting the training set with a specific subset of adversarial examples does not make the network immune to adversarial examples in general. ...we do not believe that this sort of data augmentation is sufficient for learning higher level abstractions in the dataset.
Shortcut learning в языковых моделях
Та же проблема есть и в языковых моделях. Например, модель BERT (Devlin et al., 2018) обучена на таком объеме текстов, который человек не прочитает за всю жизнь, но при этом она в основном выучивает поверхностные, стереотипные ассоциации слов друг с другом (word co-occurence), и вряд ли хорошо понимает смысл текста.
Some of BERT's world knowledge success comes from learning stereotypical associations, e. g. a person with an Italian-sounding name is predicted to be Italian, even when it is incorrect. (Rogers et al., 2020)
Попробуем протестировать некоторые из наиболее популярных на сегодняшний день языковых моделей: RoBERTa (Liu et al., 2019), ALBERT (Lan et al., 2019) и mT5 (Xue et al., 2020), взяв для тестирования их крупные варианты из репозитория HuggingFace: roberta-large, albert-xxlarge-v2 и mt5-xl. Эти модели обучались на разных задачах, в числе которых была задача предсказания закрытых маской слов в тексте, называемая masked language model objective, или cloze task. Проверим их работу на различных примерах.
Примечание. Вы можете сами повторить эксперимент, используя окно "Hosted inference API" по приведенным выше ссылкам; для mT5 можно использовать этот ноутбук, требуется GPU с большим объемом памяти.
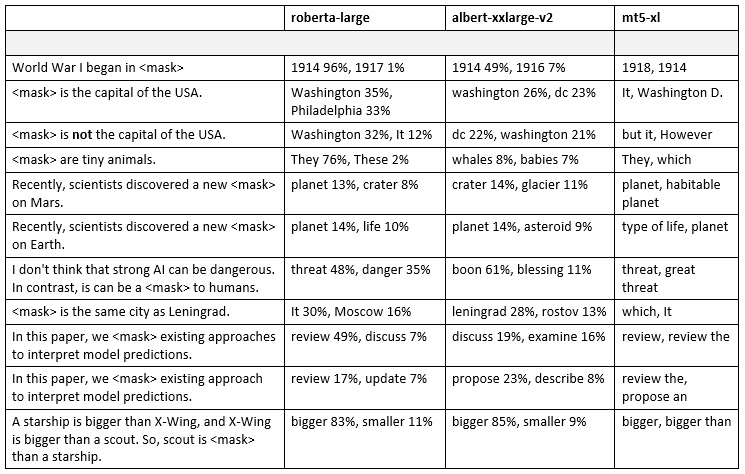
Как видим, модели иногда неплохо запоминают простые факты, но при этом все рассмотренные модели часто делают ошибки там, где нужно понимать логику повествования. Если логика повествования противоречит статистике совместной встречаемости слов, то модели обычно предпочитают статистику. Например, в последних двух примерах модель ALBERT вероятно работает так: если "approaches", то "discuss", если "approach", то "propose" – потому при обучении часто встречались такие сочетания. Слово "existing" при этом ее не смущает.
Здесь можно возразить, что слова, вставленные моделью, могут быть не цельными предложениями, а их частями, например "those who are eaten by whales are tiny animals", но этим нельзя объяснить все случаи в таблице.
Также можно возразить, что эти модели не обучались генерировать тексты без логических ошибок, они обучались воспроизводить реальные тексты, даже если в них есть ошибки. Но даже с учетом этого, те варианты слов, которые выбирают модели, часто оказываются абсурдны и практически не могли встретиться в написанных человеком текстах.
Вполне вероятно, что будь модели еще в 100 раз крупнее, обучаясь в 100 раз дольше и на большем объеме данных – они не совершили бы таких очевидных ошибок. Но даже эти модели очень большие (3.7 миллиарда параметров в mT5-XL) и обучались на сотнях гигабайт текстов, чему качество их работы на нетипичных примерах явно не соответствует – это наводит на мысль о неоптимальности подхода в целом.
Проблема shortcut learning присутствует и в тех моделях, которые специально дообучались для лидербордов GLUE (Wang et al., 2018) и SuperGLUE (Wang et al., 2019). Эти бенчмарки нацелены на измерение уровня "понимания естественного языка" моделями машинного обучения. SuperGLUE содержит 8 задач, на некоторых из которых уже побит уровень человека (имеется в виду средний уровень человека, отличающегося от разметчика, т. к. разметка тоже делалась людьми).
Но действительно ли уровень человека побит? Как выясняется, высокая метрика качества в SuperGLUE достигается в основном с помощью shortcut learning, при этом модели эксплуатируют систематические проблемы в разметке датасета для предсказания ответа "обходным путем" (Gururangan et al., 2018; Du et al., 2021), и мнение многих исследователей (1, 2, 3, 4 и др.) сходится в том, что на текущий момент языковые модели-трансформеры далеки от понимания смысла текстов в том смысле, в каком их понимает человек. Во введении мы рассматривали языковую модель GPT-3, имеющую огромный размер и генерирующую реалистичные тексты. Вот, что о ней думает Ян Лекун:
Some people have completely unrealistic expectations about what large-scale language models such as GPT-3 can do. ... GPT-3 doesn't have any knowledge of how the world actually works. It only appears to have some level of background knowledge, to the extent that this knowledge is present in the statistics of text. But this knowledge is very shallow and disconnected from the underlying reality. ...trying to build intelligent machines by scaling up language models is like building a high-altitude airplanes to go to the moon. You might beat altitude records, but going to the moon will require a completely different approach.

Cовременные языковые модели вроде GPT-3 (а также Gohper, InstructGPT, Wu Dao и другие) не стоит переоценивать, но, как мне кажется, не стоит и недооценивать. Со многими задачами они действительно очень хорошо справляются. Поскольку данный обзор посвящен проблемам машинного обучения, то в нем делается акцент на недостатках текущих ML-моделей (а значит и путях дальнейших исследований), но и преимуществ у них тоже много.
Уровни обобщения моделей машинного обобщения
Почти любой датасет имеет ограниченное разнообразие и не покрывает всех ситуаций, в которых желательна корректная работа модели. Особенно это проявляется в случае сложных данных, таких как изображения, тексты и звукозаписи. В данных могут существовать "паразитные корреляции" (spurious correlations), позволяющие с хорошей точностью предсказывать ответ только на данной выборке без "комплексного" понимания изображения или текста.
Это как раз и есть рассмотренные выше предсказания на основе фона, отдельных текстурных пятен или отдельных рядом стоящих слов. Датасеты, в которых паразитные корреляции явно выражены, называются biased (предвзятыми). Пожалуй, что все датасеты в задачах CV и NLP в той или иной степени предвзяты.
В статье о shortcut learning (Geirhos et al., 2020) авторы рассматривают несколько уровней обобщения, которые могут достигать модели машинного обучения:
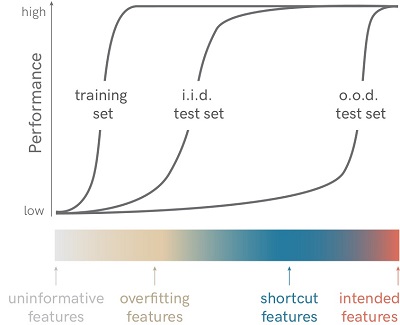
Uninformative features. Сеть использует признаки, которые не позволяют эффективно предсказывать ответ даже на обучающей выборке, например, нейронная сеть со случайно инициализированным выходным слоем.
Overfitting features. Сеть использует признаки, которые позволяют эффективно предсказывать ответ на обучающей выборке, но не на всем распределении, из которого получена эта выборка. Под "распределением" здесь понимается вероятностное совместное распределение  , из которого взяты данные (более подробно см. также этот обзор, раздел "распределение данных").
, из которого взяты данные (более подробно см. также этот обзор, раздел "распределение данных").
Shortcut features. Сеть использует признаки, которые позволяют эффективно предсказывать ответ на распределении данных  , из которого взята обучающая (и, как правило, тестовая) выборка. Поскольку выборка является набором независимых примеров, используется термин independent and identically distributed (i. i. d.). Способность алгоритма с хорошей точностью работать на некоем фиксированном распределении данных авторы называют i. i. d. обобщением. Как мы видели выше, для этого вовсе не обязательно уметь решать саму поставленную задачу в общем виде, часто можно использовать "обходные пути" или утечки данных.
, из которого взята обучающая (и, как правило, тестовая) выборка. Поскольку выборка является набором независимых примеров, используется термин independent and identically distributed (i. i. d.). Способность алгоритма с хорошей точностью работать на некоем фиксированном распределении данных авторы называют i. i. d. обобщением. Как мы видели выше, для этого вовсе не обязательно уметь решать саму поставленную задачу в общем виде, часто можно использовать "обходные пути" или утечки данных.
Intended features. Сеть использует признаки, которые позволяют эффективно предсказывать ответ в общем случае. Такие признаки будут хорошо работать и вне обучающего распределения данных, когда "обходные пути" закрыты (например, объект находится на необычном фоне, в необычной позиции, имеет необычную текстуру и пр.).
Ситуация, когда распределение данных отличается при обучении и применении называется сдвигом распределения данных (distributional shift). Иными словами, данные, на которых модель будет применяться, среднестатистически отличаются от тех, на которых модель обучалась и тестировалась. В частности, может идти речь о появлении новых типов примеров или изменении соотношения количества примеров разных типов. Это происходит из-за того, что обучающие данные часто недостаточно разнообразны и не покрывают все те типы примеров, на которых желательна корректная работа модели (либо покрывают их в неправильном соотношении).
Хорошая работа модели в условиях сдвига данных называется out-of-distribution обобщением (OOD generalization), она также известна под названием domain generalization (Zhou et al., 2021; Wang et al., 2021; см. также на paperswithcode.com), очевидна ее связь с преодолением проблемы shortcut learning.
If an image classifier was trained on photo images, would it work on sketch images? What if a car detector trained using urban images is tested in rural environments? Is it possible to deploy a semantic segmentation model trained using sunny images under rainy or snowy weather conditions? Can a health status classifier trained using one patient’s electrocardiogram data be used to diagnose another patient’s health status? ... Indeed, without access to target domain data, training a generalizable model that can work effectively in any unseen target domain is arguably one of the hardest problems in machine learning. (Zhou et al., 2021)
Еще один типичный пример – системы распознавания лиц. В обучающем датасете, даже очень большом, может ни быть ни одного изображения человеческого лица, на которое нанесен некий рисунок. Модель, обученная на таком датасете, научится быть инвариантной к положению лица в кадре и его выражению, и почти безошибочно идентифицировать человека. Однако модель может перестать корректно работать в случае, если надеты необычные очки или на лицо нанесен рисунок, потому что изображений такого типа не встречалось при обучении (либо они встречались чрезвычайно редко и практически не оказали влияния на обучение).
В результате люди придумывают все новые и новые способы обманывать системы распознавания лиц, не пряча при этом полностью лицо. Модель не встречалась с такими изображениями при обучении и распознает лица неправильно, даже если человек на месте модели легко опознал бы знакомое лицо.

Конечно, распознавание лиц может не всегда использоваться во благо обществу, но здесь речь идет об общей проблеме систем машинного обучения. Эффективное out-of-distribution обобщение остается открытой проблемой, которую необходимо решать, если мы хотим дальнейшего развития ИИ. В целом, ее можно описать так:
Generalizing beyond one's experiences – a hallmark of human intelligence from infancy – remains a formidable challenge for modern AI. (Battaglia et al., 2018)
Состязательные атаки
С работы Szegedy et al., 2013 начались исследования в области так называемых состязательных атак на нейронные сети (adversarial attacks). Авторы показали, что наложением на изображение незначительного шума можно заставить нейронные сети ошибаться в задаче классификации, предсказывая совсем другой класс. Конечно, для этого подходит не любой шум, а специальный паттерн шума, найти который можно с помощью оптимизации.
Еще более неожиданным оказалось то, что в точности тот же паттерн шума заставлял ошибаться на том же изображении и другие сети, обученные с другими гиперпараметрами и на других подвыборках обучающих данных. Кроме этого, авторы работы исследовали интерпретируемость фильтров промежуточных слоев сверточных сетей.
В дальнейшем было обнаружено (Kurakin et al., 2016), что "обманывать" модель с помощью зашумленных изображений можно даже в том случае, когда зашумленное изображение фотографируется камерой (см. видео). При этом разные модели удается обманывать одним и тем же паттерном шума, что позволяет осуществлять подобные атаки (с переменным успехом) даже тогда, когда используемая модель неизвестна.
В 2017 году изобрели совсем простой способ "обмануть" сверточную нейронную сеть: достаточно наклеить на объект стикер со специальным рисунком, и сеть перестанет правильно классифицировать объект (Brown et al., 2017). Впрочем, такой стикер не универсален и будет работать только для определенных сетей, против которых он создавался.
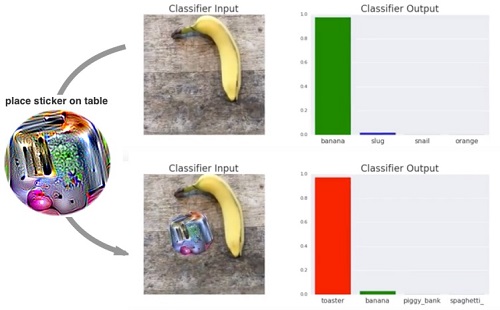
Обзор других многочисленных работ по состязательным атакам можно найти в Akhtar and Mian, 2018 и Akhtar et al., 2021. Проблемы состязательных атак и недостаточного out-of-distribution обобщения в компьютерном зрении, вероятно, связаны между собой. Человеческое зрение тоже подвержено такому типу атак, что доказывают оптические иллюзии.
Проблема неконкретизации в ML-задачах
Рассмотрим еще одну работу, изучающую поведение ML-моделей за пределами обучающего распределения данных.
Для каждой задачи может существовать бесконечное количество разных обученных моделей с разными весами и вычислительными архитектурами, дающих примерно одинаковую точность на обучающей выборке. Это известная и центральная проблема машинного обучения (Mitchell, 1980). Но эта же проблема существует и в другом варианте: для каждой задачи может существовать бесконечное количество разных обученных моделей, дающих примерно одинаковую точность на обучающем распределении данных, из которого взята тестовая выборка.
В работе D'Amour et al., 2020 эту проблему называют проблемой неконкретизации ML-задачи (underspecification of ML-pipeline). Например, если задачей является обучить систему распознавания изображений с помощью сверточной сети, то может существовать огромное множество разных сверточных сетей с разной архитектурой и инициализацией весов, дающих примерно одинаковую точность на тестовой выборке. При смене условий (выходе за пределы обучающего распределения) эти модели могут начать работать сильно по-разному.
В одном из экспериментов авторы обучили на ImageNet 50 сверточных нейронных сетей ResNet-50 (He et al., 2015). На валидационной части ImageNet все сети давали примерно одинаковую точность 75.9% ± 0.1% (указано одно стандартное отклонение). Затем авторы протестировали сети на датасете ImageNet-С (Hendrycks and Dietterich, 2019), содержащем изображения с различными шумами и искажениями (out-of-distrubiton данные с точки зрения ImageNet). В результате на изображениях с пикселизацией сети давали точность 19.7% ± 2.4%, на изображениях с уменьшенной или увеличенной контрастностью сети давали точность 9.1% ± 0.8% и так далее. Аналогичная ситуация наблюдалась на сетях ResNet-101x3 BiT (Kolesnikov et al., 2019).

Видно, что точность моделей не только стала намного хуже, но и увеличился разброс значений точности среди моделей (2.4% против 0.1%). Более того, отклонения от средней точности на разных типах искажений почти не коррелируют. Это означает, что если модель  справляется лучше модели
справляется лучше модели  на изображениях с пикселизацией, то это не означает, что она будет лучше справляться на изображениях с измененной контрастностью.
на изображениях с пикселизацией, то это не означает, что она будет лучше справляться на изображениях с измененной контрастностью.
Подобный эксперимент авторы повторили и с другими данными: на медицинских изображениях, где использовались изображения и 5 камер (первые 4 камеры – обучающее распределение, 5-я камера - out-of-distrubiton данные), и получили аналогичный результат. Таким образом, поведение моделей, имеющих одинаковую точность на тестовой выборке из обучающего распределения, может быть существенно разным за пределами этого распределения.
А ведь в описанных выше экспериментах речь шла о моделях лишь с разной инициализацией весов, что уж говорить о моделях с разной архитектурой? Авторы предполагают, что не только архитектура, но и, скажем, оптимизатор и стратегия управления learning rate может сильно влиять на свойства модели (помимо общей точности на обучающем распределении) и точность работы полученной модели на тех или иных примерах за пределами обучающего распределения.
Выводы
-
ML-модели часто полагаются на "обходные" способы получения ответа (shortcuts), вызванные недостаточным разнообразием обучающего распределения данных и наличия в нем паразитных корреляций (это напоминает утечку данных). Такая модель лишь имитирует решение задачи, и поэтому может перестать корректно работать, если условия изменятся.
-
Следовательно, модели часто показывают низкую точность работы на таких данных, вероятность встретить которые в обучающем датасете была невелика: например, диван леопардовой расцветки, лицо с нанесенной краской, объекты в необычном окружении или текст, в котором используются нестереотипные словосочетания. Например, исходная цель обучения CV-систем обычно такова: мы хотим, чтобы система распознавала интересующие нас объекты в тех случаях, когда это может сделать человек. Но проблема в том, что мы не достигаем этой цели.
-
Модели, показывающие одинаковую среднюю точность при тестировании, могут работать существенно по-разному, что особенно проявляется за пределами распределения данных, на котором модели обучались и тестировались.
-
Системы компьютерного зрения (и не только) подвержены состязательным атакам, при которых внесение различных помех или добавление незначительных деталей может испортить работу модели. Человеческое зрение намного устойчивее к таким атакам.
Здесь еще можно вспомнить платформу Kaggle для проведения ML-соревнований. Часто считают, что рейтинг на Kaggle не полностью отражает уровень ML-специалиста из-за того, что реальный процесс ML-разработки содержит намного больше шагов, чем просто обучения модели. Однако при этом считается, что Kaggle хорошо развивает умение обучать качественные ML-модели. Исходя из рассмотренного выше можно усомниться и в этом факте. На Kaggle качество моделей как правило оценивается на том же распределении, из которого взята обучающая выборка, поэтому проблемы shortcut learning и устойчивость модели к сдвигу данных не играет особой роли. Кроме того, утечки данных (как разновидность сдвига данных) в реальной работе вредны, а на Kaggle скорее полезны.
Способы решения проблем обобщения
Закончив раздел "кто виноват", перейдем к разделу "что делать". Вопрос в том, как изгнать "умного Ганса" из ML-моделей и обучить их в полной мере решать поставленную задачу. Рассмотрим сначала наиболее прямолинейные способы, и закончим исследовательскими гипотезами и обзором работ, посвященных разработкам новых архитектур и методов обучения.
Стресс-тесты для диагностики работы модели
Авторы статей о shortcut learning (Geirhos et al., 2020) и неконкретизации (D'Amour et al., 2020) сходятся в том, что необходимо не только оценивать общую точность модели на тестовой выборке, но и оценивать точность на отдельных типах примеров. В частности, авторы предлагают следующие типы тестов:
-
Stratified evaluations. Разбиение тестовой выборки на типы (например, по значению какого-то признака, по классу) и оценка точности модели отдельно на каждом типе примеров. Процитирую пример из другого обзора:
Пусть модель тестировалась на датасете, в котором 80% изображений были высокого качества (HQ), а применяться будет в условиях, когда, наоборот, 80% изображений будут низкого качества (LQ). Пусть мы сравниваем две модели: на HQ-изображениях точность первой модели лучше, чем второй, а на LQ-изображениях, наоборот, точность второй модели лучше, чем первой. Если при тестировании большая часть изображений были HQ, то мы сделаем вывод, что первая модель лучше, тогда как на самом деле лучше была бы вторая.
-
Shifted evaluations. Тестирование модели на всех типах данных, на которых желательна ее хорошая работа. Например, на зашумленных данных, на фотографиях с разных времен года и так далее.
-
Contrastive evaluations. Вместо расчета средней метрики качества модели по какой-либо выборке, мы изучаем изменение метрики качества при изменении выборки (или одного примера). Например, поворачиваем фотографии на один и тот же угол и сравниваем метрику качества.
В задачах обработки естественного языка Ribeiro et al., 2020 предлагают целый ряд проверок, которые стоит проделать на обученных моделях.
Доменная адаптация
Перечисленные способы помогут вывить проблемы в функционировании модели. После этого соответствующие примеры можно добавить в обучающие данные (или увеличить их процентное соотношение). Обучая модель на недостающих типах данных, мы превращаем out-of-distribution данные в in-distribution данные и повышаем качество работы модели на этих данных. Это наиболее прямолинейное решение проблемы сдвига данных называется доменной адаптацией (см. на paperswithcode.com). Для дообучения можно использовать и неразмеченные данные (см. обзор на Хабре: часть 1, часть 2). Но такой способ не универсален. Мы можем не знать заранее всех свойств данных, с которыми будет работать модель, и не иметь возможности собрать обучающие данные.
Существует так называемая "проблема черного лебедя" (black swan), когда ошибка на очень редком типе примеров может привести к значительным последствиям: например, автоматически управляемый автомобиль попадет в ДТП из-за сбоя в работе его систем компьютерного зрения. Есть много примеров, когда электромобили Tesla неправильно распознавали происходящее вокруг, например, принимали луну за светофор. Насколько бы разнообразным ни был датасет, все равно может оставаться шанс, что мы что-то не учли и не добавили в него какой-то тип примеров.
Если задачей является обучение модели общего назначения для дальнейшего файн-тюнинга, например, предобучение языковой модели, сети для распознавания изображений, сети для распознавания речи или же мультимодальной сети, наподобие CLIP (Radford et al., 2021), то скрытых bias'ов в данных и возможностей для shortcut learning неисчислимое множество, и невозможно устранить их все.
В целом, система с низким out-of-distribution обобщением производит впечатление не слишком "интеллектуальной", а доменная адаптация часто напоминает подстановку "костылей" под модель, не способную хорошо обобщаться. Это напоминает ученика, который научился решать уравнения вида  , но не может решить уравнения
, но не может решить уравнения  , потому что буква стала другой и незнакомой. Дообучив его решать уравнения с
, потому что буква стала другой и незнакомой. Дообучив его решать уравнения с  , мы выясняем, что теперь он не умеет решать уравнения с
, мы выясняем, что теперь он не умеет решать уравнения с  , и так далее, при этом логика его действий сильно зависит от того, какой буквой обозначена неизвестная переменная. Нужно ли искать новые архитектуры и способы обучения, способные лучше обобщаться и более устойчивые к сдвигу данных?
, и так далее, при этом логика его действий сильно зависит от того, какой буквой обозначена неизвестная переменная. Нужно ли искать новые архитектуры и способы обучения, способные лучше обобщаться и более устойчивые к сдвигу данных?
Еще больше данных?
От себя могу предположить, что, как ни странно, еще большее увеличение объема обучающих данных может помочь. С увеличением объема данных почти всегда растет разнообразие данных (умозрительно можно предположить, что если объем растет линейно, то разнообразие растет логарифмически). А ведь разнообразие данных - это именно то, что нужно? Возможно, с какого-то момента, когда loss уже нельзя будет еще сильнее понизить простым запоминанием поверхностной статистики (т. е. с помощью shortcut'ов), процесс оптимизации будет стагнировать и будет вынужден начать искать другие пути понижения loss, в том числе через систематическое обобщение.
Конечно эта лишь гипотеза, и вероятно неверная. Но на мой взгляд важно иметь в виду, что зависимость качества обучения от размера модели и объема данных может быть необычной и непредсказуемой. Например, в Nakkiran et al., 2019 (double descent) была показана необычная зависимость точности на валидации от размера модели, а в Power et al., 2022 (grokking) от длительности обучения.

Более крупные или более эффективные модели?
Сейчас глубокое обучение в основном идет по пути экстенсивного развития, при котором улучшения достигаются увеличением объема обучающих данных и размера моделей ("stack more layers"). Разработке принципиально иных архитектур и способов обучения уделяется мало внимания и финансирования, что и понятно: в таких исследованиях нет никакой гарантии успеха и получения работающего решения в обозримые сроки. Но как мы увидели выше, простое увеличение объема данных не всегда дает решение, обладающее желаемым уровнем обобщения. Об этом говорят авторы работы, посвященной графовым сетям (Battaglia et al., 2018):
The question of how to build artificial systems which exhibit combinatorial generalization has been at the heart of AI since its origins, and was central to many structured approaches, including logic, grammars, classic planning, graphical models, causal reasoning, Bayesian nonparametrics, and probabilistic programming (Chomsky, 1957; Nilsson and Fikes, 1970; Pearl, 1986, 2009; Russell and Norvig, 2009; Hjort et al., 2010; Goodman et al., 2012; Ghahramani, 2015). ... A key reason why structured approaches were so vital to machine learning in previous eras was, in part, because data and computing resources were expensive, and the improved sample complexity afforded by structured approaches’ strong inductive biases was very valuable.
In contrast with past approaches in AI, modern deep learning methods (LeCun et al., 2015; Schmidhuber, 2015; Goodfellow et al., 2016) often follow an "end-to-end" design philosophy which emphasizes minimal a priori representational and computational assumptions, and seeks to avoid explicit structure and "hand-engineering". This emphasis has fit well with — and has perhaps been affirmed by — the current abundance of cheap data and cheap computing resources, which make trading off sample efficiency for more flexible learning a rational choice. ...
Despite deep learning’s successes, however, important critiques (Marcus, 2001; Shalev-Shwartz et al., 2017; Lake et al., 2017; Lake and Baroni, 2018; Marcus, 2018a, 2018b; Pearl, 2018; Yuille and Liu, 2018) have highlighted key challenges it faces in complex language and scene understanding, reasoning about structured data, transferring learning beyond the training conditions, and learning from small amounts of experience. These challenges demand combinatorial generalization, and so it is perhaps not surprising that an approach which eschews compositionality and explicit structure struggles to meet them.
Авторы работы, посвященной системам компьютерного зрения (Yuille and Liu, 2018), также делают вывод о том, что больших данных может быть недостаточно, и нужно искать новые подходы к обучению и оценке качества моделей.
We argue that Deep Nets in their current form are unlikely to be able to overcome the fundamental problem of computer vision, namely how to deal with the combinatorial explosion, caused by the enormous complexity of natural images, and obtain the rich understanding of visual scenes that the human visual achieves. We argue that this combinatorial explosion takes us into a regime where "big data is not enough" and where we need to rethink our methods for benchmarking performance and evaluating vision algorithms. ... We question whether Deep Nets will be sufficient to address these challenges and argue that methods that are compositional, generative, and combine signal and symbolic processing will be needed.
Рост результатов на различных бенчмарках, например SuperGLUE, тоже в основном обусловлен ростом размера моделей и количества обучающих данных. Но обучающие данные все же не бесконечны. Современные языковые модели и так обучаются почти на всех данных, какие удалось собрать со всего интернета.
В какой-то момент, скорее всего, потребуется прекратить рост размера моделей, объема датасетов и сосредоточиться на разработке совершенно иных подходов, стандартизировав наборы обучающих данных (как предлагает Linzen, 2020) для лучшего сравнения эффективности подходов.

Модификации способов обучения языковых моделей
Современные языковые модели предобучаются, например, на следующих задачах:
-
Предсказание токенов (т. е. слов или их частей), закрытых маской (masked language modeling, BERT, Devlin et al., 2018). Иногда используют модификацию этой задачи, в которой закрываются маской словосочетания, представляющие собой целостные сущности (knowledge masking, ERNIE, Sun et al., 2019).
-
Предсказания следующего токена в тексте (generative pre-training, GPT, Radford et al., 2018). При этом на архитектуру модели накладывается ограничение:
 -й входной токен не должен влиять на выходные токены с индексами меньше
-й входной токен не должен влиять на выходные токены с индексами меньше  .
. -
Предсказание отдельных токенов в тексте, полученном конкатенацией предложения из энциклопедии и информации из графа знаний (universal knowledge-text prediction, ERNIE 3.0, Sun et al., 2021). Кроме этой задачи, модель ERNIE 3.0 также обучается на задачах generative pre-training и knowledge masked language modeling.
-
Наборы sequence-to-sequence задач, генерируемых в self-supervised режиме, в том числе аналоги задачи masked language modeling (T5, Raffel et al., 2019, см. figure 2, table 3).
Чтобы лучше понять свойства этих задач, можно попробовать порешать их самостоятельно. Я сделал Colab-ноутбук для генерации случайных обучающих примеров в задаче masked language modeling (MLM). Из примеров можно видеть следующее:
-
Существенная часть замаскированных токенов определяется тривиально
-
Во многих случаях предсказать замаскированные токены исходя из контекста невозможно, а значит для решения задачи на большом корпусе текста нужно запоминать множество различных фактов: сюжеты литературных произведений, историю, политику и так далее, а также множество статистики совместной встречаемости слов в тексте (shortcuts). Даже выучив множество фактов и статистики, решить задачу MLM можно далеко не всегда.
-
Лишь изредка возможно предсказать замаскированный токен на основании контекста и логики, и чаще всего эта логика достаточно простая. Исчезающе редки примеры, где для предсказания нужна нетривиальная логика, которую нельзя имитировать запоминанием фактов и статистики.
Следовательно, приоритетом для снижения loss на задаче MLM является запоминание фактов и статистики. Способность рассуждать и делать выводы (отображая слова в некую модель мира и обратно, как это делает человек) для снижения loss является лишь второстепенным фактором, при этом выучить эту способность должно быть намного сложнее, чем запомнить факты.
Получается, что мы обучаем сеть на такой задаче, которую нельзя хорошо решить, обладая одной лишь логикой и пониманием смысла общеупотребимых слов, но можно неплохо решить с помощью запоминания огромного объема фактов и shortcut'ов. Обученная таким способом модель действительно может оказаться способной генерировать правдоподобные тексты, но лишь "вспоминая", что когда-то видела что-то похожее. Таким образом, модель долго и старательно обучается, но вовсе не тому, чего мы от нее хотим.

Отсюда можно сделать вывод о том, что обучение сетей, которые действительно понимают смысл текста в том смысле, в каком его понимает человек (вместо использования shortcut'ов для имитации понимания текста) будет затруднительным, если принципиально не менять задачу предобучения или архитектуру модели.
Архитектура моделей и структура данных
Модель эффективно обобщается, если ее структура соответствует структуре моделируемых данных. По этой причине на выборке, сгенерированной случайно инициализированной нейронной сетью, хорошо обобщается другая нейронная сеть (Gorishniy et al., 2021), на выборке, сгенерированной случайным решающим деревом, хорошо обобщаются другие деревья, сверточные сети хорошо обобщаются на текстурах и составленных из них изображениях (Ulyanov et al., 2017), а AlphaFold 2 за счет структурного модуля хорошо обобщается на трехмерных структурах белков (Jumper et al., 2021). Какова же структура текстов и изображений? Можно назвать два основных уровня:
Уровень 1. Низкоуровневая локальная структура. В изображениях это набор локальных признаков (текстуры и границы), в текстах это буквы и морфология слов. Также сюда можно отнести уровень звукового/визуального восприятия текста и интонацию.
Уровень 2. Высокоуровневая иерархическая разреженная структура. В текстах эта структура начинается с синтаксиса, следующим уровнем является связь между предложениями, абзацами и более крупными частями текста. В изображениях обычно тоже есть некая иерархическая структура, соответствующая объектам и их частям в трехмерном пространстве на разном расстоянии. При этом между элементами иерархической структуры имеется разреженный граф смысловых и причинно-следственных взаимосвязей. Например, рассуждая о человеке на фотографии, мы никак не будем учитывать цвет стоящего неподалеку автомобиля. Разреженность помогает не обращать внимание на паразитные корреляции и избегать shortcut learning'а.
Кроме того, когда человек воспринимает фотографию, иерархическая структура изображения отображается в модель мира, и человек сознательно или подсознательно выводы о том, логично ли изображенное на фотографии, в каком контексте и зачем оно сделано и каково развитие событий в момент съемки. С текстом все в целом аналогично.
Судя по всему, для исправления проблемы shortcut learning модель должна реализовывать именно такой способ обработки изображения или текста, то есть уметь представлять входные данные (изображение или текст) как иерархическую комбинацию составляющих частей с разреженными взаимосвязями, что соответствует уровню 2, и быть способной корректно интерпретировать те же части в необычных комбинациях. По сравнению с абстрактным свойством out-of-distribution обобщения, это более конкретное желаемое свойство называют систематическим, композиционным, или комбинаторным обобщением (Bahdanau et al., 2018; Furrer et al., 2020). Достижение такого уровня обобщения остается открытой проблемой машинного обучения.
If you think about child learning, for example, their world is changing over time, their body is changing over time, and so we need systems that are going to be able to handle those changes and do things like continual learning, life-long learning and so on. This has been a long-standing goal for machine learning, but I think we haven't yet built the solutions to this. And one of the crucial elements in order to be successful in this ... is introducing more forms of compositionality. It means being able to learn from some finite sets of combinations about a much larger set of combinations. (Yoshua Bengio, NeurIPS 2019)
Здесь часто вспоминают символьные подходы, с которых и начинались исследования ИИ в XX веке. По структуре такие системы, кажется, обладают всем необходимым: они могут работать с объектами и их частями, то есть с интерпретируемыми промежуточными данными, работать иерархически, реализовывать сложные цепочки рассужедний, а вычисления внутри них могут затрагивать лишь немногие объекты и взаимосвязи, что означает разреженность. Непонятно лишь одно: как их обучать, чтобы они могли быть сложными и достаточно гибкими одновременно.
Например, пусть некая подсистема решает, какую из операций из набора  применить к данным
применить к данным  . Для этого она выдает вероятности
. Для этого она выдает вероятности  и выбирает операцию с наибольшей вероятностью. Допустим, на текущем примере мы выбрали операцию
и выбирает операцию с наибольшей вероятностью. Допустим, на текущем примере мы выбрали операцию  , и в итоге получили значение функции потерь
, и в итоге получили значение функции потерь  . Производные
. Производные  равны нулю, поэтому такую систему не получится обучить обычным градиентным спуском. Можно попробовать рассчитать ответ, используя по очереди все
равны нулю, поэтому такую систему не получится обучить обычным градиентным спуском. Можно попробовать рассчитать ответ, используя по очереди все  , и снизить вероятности
, и снизить вероятности  для тех
для тех  , на которых loss получился выше, чем на других. Но если граф принятия решений содержит не одну, а много операций принятия решения (
, на которых loss получился выше, чем на других. Но если граф принятия решений содержит не одну, а много операций принятия решения ( ), тогда придется перебирать очень много разных вариантов последовательностей решений. Аналогичная проблема возникает, если мы выбираем не операцию, а один или несколько элементов среди доступных данных (hard attention).
), тогда придется перебирать очень много разных вариантов последовательностей решений. Аналогичная проблема возникает, если мы выбираем не операцию, а один или несколько элементов среди доступных данных (hard attention).
Направления исследований
В машинном обучении каждый день публикуется множество научных статей. Что-то модно, что-то вышло из моды, какие-то работы еще ждут признания, а какие-то так и остались незамеченными. Приведенный ниже список статей не претендует на полноту и описывает лишь некоторые из современных направлений исследований.
В перечисленных ниже работах изучаются проблемы современных систем компьютерного зрения. В некоторых из них также предлагаются различные модификации процесса обучения и способа оценки качества моделей, в том числе с помощью meta-learning.
-
Szegedy et al., 2013. Intriguing properties of neural networks.
-
Peng et al., 2017. Zero-Shot Deep Domain Adaptation.
-
Yuille and Liu, 2018 Deep Nets: What have they ever done for Vision?
-
Li et al., 2017. Learning to Generalize: Meta-Learning for Domain Generalization.
-
Beery et al., 2018. Recognition in Terra Incognita.
-
Baker et al., 2018. Deep convolutional networks do not classify based on global object shape.
-
Balaji et al., 2018. MetaReg: Towards Domain Generalization using Meta-Regularization.
-
Hendrycks et al., 2019. Natural Adversarial Examples.
-
Brendel and Bethge, 2019. Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet.
-
Lapuschkin et al., 2019. Unmasking Clever Hans Predictors and Assessing What Machines Really Learn.
-
Wang et al., 2019. High Frequency Component Helps Explain the Generalization of CNN.
-
Ilyas et al., 2019. Adversarial Examples Are Not Bugs, They Are Features.
-
Bucher et al., 2019. Zero-Shot Semantic Segmentation.
-
Taori et al., 2020. Measuring Robustness to Natural Distribution Shifts in Image Classification.
-
Djolonga et al., 2020. On Robustness and Transferability of Convolutional Neural Networks.
-
Mahajan et al., 2020. Domain Generalization using Causal Matching.
-
Zhou et al., 2020. Deep Domain-Adversarial Image Generation for Domain Generalisation.
-
Fabbrizzi et al., 2021. A Survey on Bias in Visual Datasets.
-
Shu et al., 2021. Open Domain Generalization with Domain-Augmented Meta-Learning.
-
Zhou et al., 2021. MixStyle Neural Networks for Domain Generalization and Adaptation.
Проблемы современных языковых моделей, проблемы данных, на которых они обучаются, и некоторые способы улучшения данных и способов обучения описаны в следующих работах:
-
Gururangan et al., 2018. Annotation Artifacts in Natural Language Inference Data.
-
Kaushik and Lipton, 2018. How Much Reading Does Reading Comprehension Require? A Critical Investigation of Popular Benchmarks.
-
Jawahar et al., 2019. What does BERT learn about the structure of language?
-
Goldberg, 2019. Assessing BERT's Syntactic Abilities.
-
McCoy et al., 2019. Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in NLI.
-
Zellers et al., 2019. HellaSwag: Can a Machine Really Finish Your Sentence?
-
Lin et al., 2019. Open Sesame: Getting Inside BERT's Linguistic Knowledge.
-
Kovaleva et al., 2019. Revealing the Dark Secrets of BERT.
-
Kavumba et al., 2019. When Choosing Plausible Alternatives, Clever Hans can be Clever.
-
McCoy et al., 2019. BERTs of a feather do not generalize together: Large variability in generalization across models with similar test set performance.
-
Keysers et al., 2019. Measuring Compositional Generalization: A Comprehensive Method on Realistic Data.
-
Rogers, 2020. A Primer in BERTology: What we know about how BERT works.
-
Goodwin et al., 2020. Probing Linguistic Systematicity.
-
Ribeiro et al., 2020. Beyond Accuracy: Behavioral Testing of NLP models with CheckList.
-
Linzen, 2020. How Can We Accelerate Progress Towards Human-like Linguistic Generalization?
-
Bender and Koller, 2020. Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data.
-
Yu and Ettinger, 2020. Assessing Phrasal Representation and Composition in Transformers.
-
Liu et al., 2021. GPT Understands, Too.
-
Du et al., 2021. Towards Interpreting and Mitigating Shortcut Learning Behavior of NLU Models.
-
Shin et al., 2021. Constrained Language Models Yield Few-Shot Semantic Parsers.
-
Yanaka et al., 2021. SyGNS: A Systematic Generalization Testbed Based on Natural Language Semantics.
-
Sanh et al., 2021. Multitask Prompted Training Enables Zero-Shot Task Generalization.
-
Shavrina and Malykh, 2021. How not to Lie with a Benchmark: Rearranging NLP Leaderboards.
-
Veres, 2021. Language Models are not Models of Language.
-
Wei et al., 2021. Finetuned Language Models Are Zero-Shot Learners.
-
Ouyang et al., 2022. Training language models to follow instructions with human feedback.
В том числе, с помощью языковых моделей успешно решаются задачи генерации программного кода и решения математических задач, что само по себе интересно и может помочь лучше понять свойства такого типа моделей:
-
Cobbe et al., 2021. Training Verifiers to Solve Math Word Problems.
-
Polu et al., 2022. Formal Mathematics Statement Curriculum Learning.
Исследователи давно ищут возможность обучить модели систематическому обобщению, пониманию понятий части и целого и оперированию абстрактными концепциями. Некоторые из последних работ по этой теме:
-
Lake et al., 2015. Human-level concept learning through probabilistic program induction.
-
Bengio, 2017. The Consciousness Prior.
-
Sabour et al., 2017 Dynamic Routing Between Capsules.
-
Evans and Grefenstette, 2017. Learning Explanatory Rules from Noisy Data.
-
Bahdanau et al., 2018. Systematic Generalization: What Is Required and Can It Be Learned?
-
Battaglia et al., 2018. Relational inductive biases, deep learning, and graph networks.
-
Vlastelica et al., 2021. Neuro-algorithmic Policies enable Fast Combinatorial Generalization.
-
Hinton, 2021. How to represent part-whole hierarchies in a neural network.
Высокая способность к обобщению также требуется при обучении агентов, так как окружение может быть очень разнообразным и меняться от действий самих агентов, а значит важным является способность агентов корректно функционировать в новых условиях, не встречавшихся раньше.
-
Gupta et al., 2021. Embodied Intelligence via Learning and Evolution.
-
Hazra et al., 2021. Zero-Shot Generalization using Intrinsically Motivated Compositional Emergent Protocols.
-
Jang et al., 2021. BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning.
Мнение многих исследователей сходится в том, что для создания ML-систем следующего поколения, способных исправить важные недостатки текущих систем, нужно пробовать объединять нейронные сети и символьные вычисления:
-
Besold et al., 2017. Neural-Symbolic Learning and Reasoning: A Survey and Interpretation.
-
Mao et al., 2019. The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Sentences From Natural Supervision.
-
Vankov and Bowers, 2019. Training neural networks to encode symbols enables combinatorial generalization.
-
Latapie et al., 2021. Neurosymbolic Systems of Perception & Cognition: The Role of Attention.
-
Niepert et al., 2021. Implicit MLE: Backpropagating Through Discrete Exponential Family Distributions.
Одним из многообещающих подходов к повышению обобщающей способности моделей считается meta-learning ("learning-to-learn"):
-
Hospedales et al., 2020. Meta-Learning in Neural Networks: A Survey.
Много работ посвящено попыткам улучшения трансформера (Vaswani et al., 2017), а также попыткам перенести его обобщающие свойства (inductive biases) на другие архитектуры или найти более простые альтернативы. Трансформер можно рассматривать как графовую нейронную сеть, в которой вершины хранят информацию, а ребра не хранят информации. Однако недавно были опубликованы работы, в которых предлагаются модификации трансформера с хранением информации в ребрах (подобный подход уже использовался, например, в AlphaFold 2). Также была обнаружена интересная взаимосвязь трансформера с сетями Хопфилда.
-
Kerg et al., 2019. Untangling tradeoffs between recurrence and self-attention in neural networks.
-
Gao et al., 2020. Systematic Generalization on gSCAN with Language Conditioned Embedding.
-
Ramsauer et al., 2020. Hopfield Networks is All You Need.
-
Tay et al., 2020. Efficient Transformers: A Survey.
-
Dosovitskiy et al., 2020. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.
-
Bello, 2021. LambdaNetworks: Modeling Long-Range Interactions Without Attention.
-
Lu et al., 2021. Pretrained Transformers as Universal Computation Engines.
-
Jaegle et al., 2021. Perceiver: General Perception with Iterative Attention.
-
Pan et al., 2021. On the Integration of Self-Attention and Convolution.
-
Liu et al., 2021. Pay Attention to MLPs.
-
Lee-Thorp et al., 2021. FNet: Mixing Tokens with Fourier Transforms.
-
Peng et al., 2021. Random Feature Attention.
-
Nguyen et al., 2021. FMMformer: Efficient and Flexible Transformer via Decomposed Near-field and Far-field Attention.
-
Xu et al., 2021. CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation.
-
Nawrot et al., 2021. Hierarchical Transformers Are More Efficient Language Models.
-
Bergen et al., 2021. Systematic Generalization with Edge Transformers.
-
Hussain et al., 2021. Edge-augmented Graph Transformers: Global Self-attention is Enough for Graphs.
-
Wang et al., 2022. When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism.
Если модель встречается с необычным примером и не может выдать на нем корректный ответ, то можно по крайней мере научить модель сомневаться, то есть оценивать уверенность в предсказании. Это может помочь не только в случае сдвига данных, но и на тех примерах, на которых точечная оценка условного распределения  даст высокую ожидаемую ошибку (то есть ответ нельзя с уверенностью предсказать из исходных данных). В этом контексте часто упоминают байесовские методы, ансамблирование и генеративные модели. Некоторые из работ по теме байесовских методов и оценки уверенности в предсказаниях:
даст высокую ожидаемую ошибку (то есть ответ нельзя с уверенностью предсказать из исходных данных). В этом контексте часто упоминают байесовские методы, ансамблирование и генеративные модели. Некоторые из работ по теме байесовских методов и оценки уверенности в предсказаниях:
-
Wang and Vasconcelos, 2018. Towards Realistic Predictors.
-
Maddox et al., 2019. A Simple Baseline for Bayesian Uncertainty in Deep Learning.
-
Nalisnick et al., 2019. Detecting Out-of-Distribution Inputs to Deep Generative Models Using Typicality.
-
Ren et al., 2019. Likelihood Ratios for Out-of-Distribution Detection.
-
Jospin et al., 2020. Hands-on Bayesian Neural Networks - a Tutorial for Deep Learning Users.
-
Lakshminarayanan, 2020. Uncertainty & Out-of-Distribution Robustness in Deep Learning.
-
Yang et al., 2021. Generalized Out-of-Distribution Detection: A Survey.
-
Henning et al., 2021. Are Bayesian neural networks intrinsically good at out-of-distribution detection?
-
Huyen, 2022. Data Distribution Shifts and Monitoring.
Еще несколько общих статей о проблемах современного машинного обучения, паразитных корреляциях в данных и подходах к повышению обобщающей способности (некоторые из них подробно разбирались в этом обзоре):
-
Tommasi et al., 2015. A Deeper Look at Dataset Bias.
-
Ross et al., 2017. Right for the Right Reasons: Training Differentiable Models by Constraining their Explanations.
-
Shalev-Shwartz et al., 2017. Failures of Gradient-Based Deep Learning.
-
Marcus, 2018. Deep Learning: A Critical Appraisal.
-
Mehrabi et al., 2019. A Survey on Bias and Fairness in Machine Learning.
-
Geirhos et al., 2020. Shortcut Learning in Deep Neural Networks.
-
D'Amour et al., 2020. Underspecification Presents Challenges for Credibility in Modern Machine Learning.
-
Xu et al., 2020. How Neural Networks Extrapolate: From Feedforward to Graph Neural Networks.
-
Pezeshki et al., 2021. Gradient Starvation: A Learning Proclivity in Neural Networks.
-
Balestriero et al., 2021. Learning in High Dimension Always Amounts to Extrapolation.
-
Shen et al., 2021. Towards Out-Of-Distribution Generalization: A Survey.
Многие исследователи считают, что важно не только обучить модели выявлять статистические зависимости, но и находить в данных причинно-следственные связи. Имея лишь выборку из распределения данных, это не всегда можно сделать. Например, пусть мы имеем набор фотографий с неизвестной планеты, и на некоторых фотографиях есть огонь и есть неопознанные существа, при этом появление существ и огня на фотографиях сильно коррелирует. Что является причиной, а что следствием? Разводят ли существа огонь сами, приходят ли к уже появившемуся огню, или же оба явления имеют общую причину (прилетает звездолет, высаживает существ и оставляет на земле огонь после взлета)? Это практически невозможно определить из фотографий (или же очень сложно, по косвенным признакам). Поиска причинно-следственных связей является более сложной задачей, чем поиск статистических зависимостей. Следующие книги и статьи посвящены именно этой теме:
-
Pearl, 2009. Causality: Models, Reasoning and Inference, 2nd edition.
-
Guo et al., 2018. A Survey of Learning Causality with Data: Problems and Methods
-
Pearl, 2018. Theoretical Impediments to Machine Learning With Seven Sparks from the Causal Revolution.
-
Pearl, 2018. The Seven Tools of Causal Inference with Reflections on Machine Learning.
-
Sch?lkopf, 2019. Causality for Machine Learning.
-
Arjovsky et al., 2019. Invariant Risk Minimization.
-
Tr?uble et al., 2020. On Disentangled Representations Learned From Correlated Data
Отдельно можно отметить работу группы Йошуа Бенжио в институте MILA (Канада):
-
Bengio et al., 2019. A Meta-Transfer Objective for Learning to Disentangle Causal Mechanisms.
-
Goyal et al., 2019. Recurrent Independent Mechanisms.
-
Ke et al., 2019. Learning Neural Causal Models from Unknown Interventions.
-
Ahmed et al., 2020. Systematic generalisation with group invariant predictions.
-
Goyal and Bengio, 2020. Inductive Biases for Deep Learning of Higher-Level Cognition.
-
Krueger et al., 2020. Out-of-Distribution Generalization via Risk Extrapolation (REx).
-
Goyal et al., 2021. Neural Production Systems.
-
Sch?lkopf et al., 2021. Towards Causal Representation Learning.
-
Xia et al., 2021. The Causal-Neural Connection: Expressiveness, Learnability, and Inference.
-
Zhao et al., 2021. A Consciousness-Inspired Planning Agent for Model-Based Reinforcement Learning.
-
Ahuja et al., 2021. Invariance Principle Meets Information Bottleneck for OOD Generalization.
-
Liu et al., 2021. Discrete-Valued Neural Communication.
-
Rahaman et al., 2021. Dynamic Inference with Neural Interpreters.
Различные модальности (изображения, текст и др.) могут дополнять друг друга и формировать более целостную картину мира, чем каждая модальность по отдельности, поэтому мультимодальное обучение кажется многообещающим. В последние пару лет в этой области были достигнуты впечатляющие результаты.
-
Su et al., 2019. VL-BERT: Pre-training of Generic Visual-Linguistic Representations.
-
Ramesh et al., 2021. Zero-Shot Text-to-Image Generation.
-
Radford et al., 2021. Learning Transferable Visual Models From Natural Language Supervision.
-
Goh et al., 2021. Multimodal Neurons in Artificial Neural Networks.
-
Singh et al., 2021. Illiterate DALL-E Learns to Compose.
-
Wang et al., 2022. Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework.
Одним из возможных путей к созданию ML-систем следующего поколения может стать обучение систем, способных анализировать видео и предсказывать следующие события (далее чем несколько кадров), в том числе в текстовом виде. Такие системы могут быть способы отличать статистические зависимости от причинно-следственных связей, а также соотносить текст с происходящими событиями. Похожая задача возникает при обучении агентов, которым необходимо предсказывать последствия своих и чужих действий. Агента может заменить на наблюдателя, задача которого - лишь предсказывать последствия чужих действий. Можно искать и другие способы создания самообучающейся модели мира, какая существует, например, в сознании человека.
-
Ha and Schmidhuber, 2018. World Models.
-
Lotter et al., 2018. A neural network trained to predict future video frames mimics critical properties of biological neuronal responses and perception.
-
Zhang and Tao, 2019. Slow Feature Analysis for Human Action Recognition.
-
Xu et al., 2020. Video Prediction via Example Guidance.
-
Apostolidis et al., 2021. Video Summarization Using Deep Neural Networks: A Survey.
-
Lee et al., 2021. Revisiting Hierarchical Approach for Persistent Long-Term Video Prediction.
-
Wu et al., 2021. Generative Video Transformer: Can Objects be the Words?
Общий искусственный интеллект
Исследователей всегда интересовала тема общего искусственного интеллекта и создания систем, которые мыслят как люди. Проблема здесь начинается с того, что разные люди по-разному определяют, что же конкретно это означает. Как мне кажется, здесь может помочь введение более узких терминов с более конкретными определениями, вместо расплывчатых и спорных понятий "общего ИИ" и "сильного ИИ". Если разные люди хотят предложить разные определения, то пусть придумают для них разные термины.
Например, можно предложить такое определение: полнофункциональный искусственный интеллект - это система, способная решать все задачи, которые может решать человек. Если больше не останется таких типов задач, которые может решить практически любой человек, но не может решить ИИ (качество решения оценивается голосованием людей), то тогда можно будет считать, что создан полнофункциональный ИИ, согласно его определению. Конечно, не обязательно требовать от ИИ выполнения механических движений или, скажем, мимики лица. Поэтому можно предложить более узкое понятие: полнофункциональный текстовый искусственный интеллект - это система, способная решать все задачи, которые может решать человек в текстовом виде, будь он по ту сторону монитора и имея достаточно времени. Конечно, и такое определение может породить споры, но все же оно несколько более конкретно.
Я никоим образом не являюсь специалистом по вопросу общего ИИ, но как автор обзора выскажу мнение по поводу его достижения. Меня привлекает идея постепенного улучшения, когда на каждом шаге ищутся недостатки систем текущего поколения и находятся способы их преодоления для создания систем следующего поколения. Можно провести аналогию с градиентным спуском или методом отжига: мы постепенно улучшаем решение, не пытаясь все выбросить и начать с нуля, и периодически пробуем внедрить какие-то принципиальные изменения. Тогда на текущем этапе развития машинного обучения нужно сосредоточиться на решении проблем обобщения, которым и был посвящен этот обзор.
Приведу также несколько работ, в которых рассматривается вопрос общего искусственного интеллекта и сопоставления биологического интеллекта с текущими ML-системами.
-
Marcus, 2001. The Algebraic Mind: Integrating Connectionism and Cognitive Science.
-
Marcus, 2004. The Birth of the Mind: How a Tiny Number of Genes Creates The Complexities of Human Thought.
-
Griffiths et al., 2010. Probabilistic models of cognition: exploring representations and inductive biases.
-
Goertzel, 2014. Artificial General Intelligence: Concept, State of the Art, and Future Prospects.
-
Lake et al., 2016. Building machines that learn and think like people.
-
Hassabis, 2017. Neuroscience-Inspired Artificial Intelligence.
-
Goertzel, 2018. From Here to Human-Level AGI in 4 Simple Steps.
-
Chollet, 2019. On the Measure of Intelligence.
-
Wang, 2019. On Defining Artificial Intelligence.
-
Wang et al., 2020. On Defining Artificial Intelligence – Commentaries and Author’s Response.
-
Marcus, 2020. The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence.
-
Fjelland, 2020. Why general artificial intelligence will not be realized.
-
Chollet, 2020. A Definition of Intelligence for the Real World?
-
Stoop, 2021. Note on the Reliability of Biological vs. Artificial Neural Networks.
-
Goertzel, 2021. The General Theory of General Intelligence: A Pragmatic Patternist Perspective.
Интересны работы с участием нейробиолога Карла Фристона, который исследует принципы работы человеческого мозга и их возможную связь с вариационными байесовскими методами в математической статистике:
-
Friston, 2010. The free-energy principle: a unified brain theory?
-
Isomura et al., 2022. Canonical neural networks perform active inference.
-
Friston et al., 2022. The free energy principle made simpler but not too simple.
-
Parr et al., 2022. Active Inference: The Free Energy Principle in Mind, Brain, and Behavior.
Заключение
Как мне кажется, проблемы содержатся не только в алгоритмах, но и в человеческом сознании. Людям неинтересно изучать и исследовать. Чтение статей, изучение информации воспринимается лишь как скучная необходимость, сложные вопросы и исследовательские задачи не занимают людей, а интересует в основном лишь заработок.
Еще одна сложность в том что количество научных статей и книг в области исследовательского ML стремительно растет. На конференции NeurIPS 2021 было опубликовано более 2300 статей (больше, чем за 2010-2015 годы вместе взятые): одни только аннотации заняли бы целый том. Возникает острая потребность в систематизации информации. Читать статьи в оригинале долго и тяжело по нескольким причинам.
-
Каждая статья содержит обзор других работ, и если вы читаете, скажем, 20 статей по одной и той же области, то эти обзоры во многом дублируют друг друга и отбивают интерес к чтению.
-
Материал статьи может быть изложен не лучшим образом, непонятно или с повторениями. Сейчас не принято, как раньше, публиковать короткие статьи, хотя содержание многих статей можно было бы изложить на одной странице.
-
Раздел про гиперпараметры, датасеты и детали эксперимента может быть важен тем, кто будет имплементировать это на практике через месяц после выхода статьи, но через 5 лет станет не особенно интересен, хотя предложенный в статье метод может сохранить свою актуальность. Если же совсем не читать экспериментальный раздел, то можно упустить что-то важное.
-
При чтении статьи восприятие происходит однобоко. Непонятно, был ли предложенный в статье метод признан эффективным на практике, получил ли широкое распространение, или же вскоре был предложен более эффективный подход? Актуален ли метод по сей день, или если нет то почему? Часто не хватает взгляда со стороны от компетентного специалиста, желательно от нескольких.
Исходя из всего этого, систематизация и изложение статей в сокращенном варианте, как мне кажется, могло бы принести огромную пользу для сообщества. Конечно, многими прилагаются усилия в этом направлении, но этого пока недостаточно. Краткие изложения статей остаются бесплатной работой для энтузиастов, тогда как пользу они приносят вполне реальную.
На мой взгляд, будь эта практика более широко распространена, и будь у людей больше интереса к исследованиям, мы могли бы уже создавать такие системы искусственного интеллекта, которую бы приносили огромную пользу человечеству (в медицине, физике, интернет-технологиях, оптимизации работы людей и, стало быть, сокращении рабочей недели) и которые пока что остаются лишь в области фантастики.
Данный обзор первоначально размещен на сайте generalized.ru, где вы можете найти и другие обзоры.
Источник: habr.com