Трудности перевода
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-12-23 12:53

Как машинные переводчики придумали собственные правила — и что из этого вышло
Представьте, что вы внезапно оказались в стране, язык которой вам совсем незнаком. Вряд ли эта мысль вызовет у вас ужас: чтобы начать разговор в любой точке мира, сейчас достаточно взять смартфон, набрать или даже просто наговорить текст, нажать пару кнопок и получить готовый перевод. Ещё 20 лет назад о таком можно было только мечтать.
Сегодня переводы, выполненные человеком и алгоритмом, сближаются по качеству, и огромный вклад в это вносят нейросетевые модели. История машинного перевода — одна из самых ярких иллюстраций головокружительного успеха нейросетей, которые буквально за пару лет смогли то, чего десятилетиями добивались с помощью других подходов.
Рассказываем, как менялись принципы перевода, что нового в него внесли нейросети и почему онлайн-переводчики порой удивляют нас неожиданными ответами.
KACHYESTVO UGLYA OPRYEDYELYAETSYA KALORYIYNOSTJYU
Мы часто рассуждаем об идеальном мире без языковых барьеров, но, как это ни парадоксально, именно со времён жёстких границ и берёт своё начало история машинного перевода.
В 1954 году в штаб-квартире корпорации IBM в Нью-Йорке группа учёных Джорджтаунского университета провела эксперимент, который должен был показать невероятные возможности электронного «мозга»: компьютер перевёл больше 60 предложений с русского на английский. В систему подавались, например, такие фразы (в оригинале они писались транслитом): «Качество угля определяется калорийностью», «Международное понимание является важным фактором в решении политических вопросов», «Командир получает сведения по телеграфу». В ответ машина выдавала английский эквивалент «с невероятной скоростью в две с половиной строки в секунду», подчёркивали в IBM.

Язык, конечно, был выбран не случайно. Дело было не столько в его лингвистической сложности, сколько в реалиях холодной войны. Научиться не только собирать информацию, но и молниеносно понимать русских за железным занавесом — такая задача просто не могла не получить политическую и финансовую поддержку в середине 1950-х.
Об итогах Джорджтаунского эксперимента рассказывали во всех американских СМИ, и из 2021 года амбиции того времени выглядят сильно самоуверенно: за пять лет экспериментаторы собирались добиться таких успехов, чтобы заменить алгоритмами большинство переводчиков.
На самом же деле достичь значительного прогресса не удалось и за десять с лишним лет, поэтому финансирование исследований в области компьютерной лингвистики почти полностью свернули. Но как работали первые алгоритмы, которые не оправдали ожиданий своих разработчиков?
После презентации в Нью-Йорке машинным переводом заинтересовались и в СССР, где появилось несколько групп для профильных экспериментов. В 1960 году президиум Академии наук Советского Союза утвердил постановление, в котором говорилось, что недостаток исследований «тормозит практически важные работы по теории и практике машинного перевода». В университетах страны появились новые направления подготовки. Позже это время называли «серебряным веком» структурной, прикладной и математической лингвистики в СССР.
Ориентируйтесь по знакам
Электронный «мозг» IBM использовал для перевода подход на основе правил. Фактически в систему загружались словари, которые связывали между собой слова на двух языках, а также свод инструкций, по которым алгоритм ориентировался, как он должен обрабатывать текст в том или ином случае.
Чтобы объяснить, что происходило «под капотом» вычислительной машины во время Джорджтаунского эксперимента, в IBM привели несколько примеров. Вот один из них.
Допустим, мы хотим перевести с русского на английский «генерал-майор». Правильным вариантом будет major general. Однако как компьютер должен понять, что ему нужно поменять местами генерала и майора?
В двуязычном словаре к русскому слову «генерал» добавляется специальная метка 21, а к слову «майор» — 110. В своде правил при этом фиксируется такая инструкция для компьютера:
Если встретишь метку 110, вернись на слово назад и посмотри, нет ли там знака 21; если он есть, при переводе поменяй слова местами.
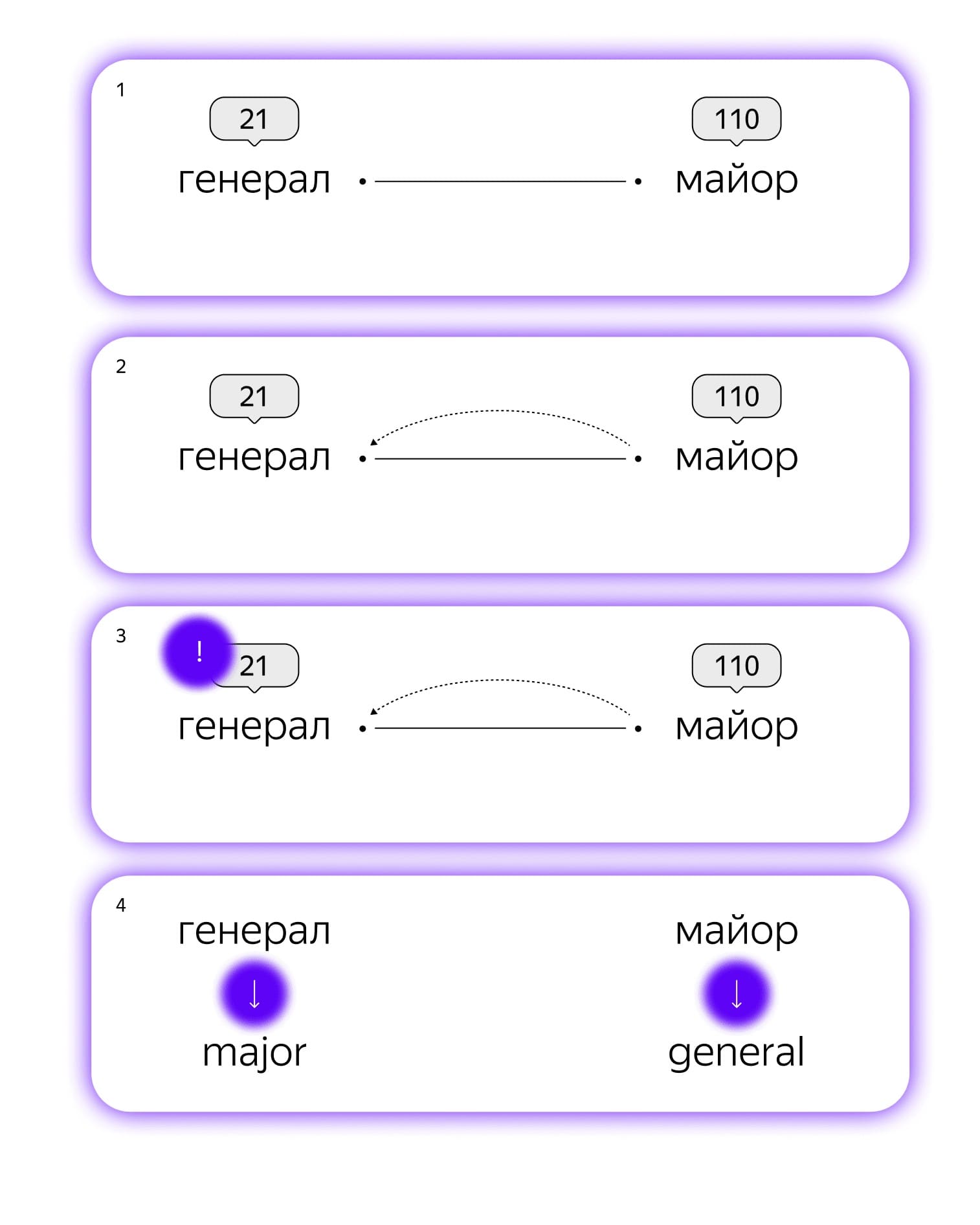
Джорджтаунский эксперимент был, по сути, совсем игрушечным: в нем использовали словарь всего на 250 слов и только шесть правил их взаимодействия. Нетрудно представить, что для реальных задач словарь должен быть существенно больше, а набор инструкций — не только больше, но и намного сложнее. В этом главный минус моделей, основанных на правилах: конструировать и поддерживать их очень долго и сложно.
«Осень в любви со мной»
Второе дыхание у машинного перевода открылось уже в 1990-е, когда в обработке естественного языка стала активно участвовать статистика. Теперь для связи языков уже не нужен был словарь. Вместо этого алгоритму «показывали» большое число специально размеченных текстов на исходном и целевом языках — их ещё называют параллельными корпусами. По этим примерам система сама вычисляла принципы, на которых строится перевод, и позже могла ими пользоваться.
Представим, что мы переводим с английского на русский. Тогда на языке статистической модели наша задача будет звучать так:
Найди для предложения X на русском самый вероятный (и стройный) перевод Y на английском.
Оценить подобную вероятность саму по себе довольно сложно, поэтому исследователи пошли на хитрость, которую позволяют законы статистики. Задачу разложили на составляющие так, что в итоге одна часть модели следила, чтобы перевод Y максимально соответствовал исходному тексту X, а вторая часть проверяла его на адекватность с точки зрения целевого языка.
Вот простой пример её работы. Допустим, нам попалось предложение: fall in love with me. Не исключено, что первая часть алгоритма посчитает вероятными сразу два варианта перевода: «Осень в любви со мной» и «Влюбись в меня». Обе фразы действительно можно соотнести с оригиналом, но при этом мы понимаем, что в первом варианте не очень много смысла. То, что мы чувствуем интуитивно, должна распознать вторая часть нашего алгоритма — эта часть представляет из себя не что иное, как языковую модель (о них мы подробно рассказывали в номере, посвящённом языковым моделям).
Держите корпус ровным
Упрощённое описание статистического метода звучит довольно оптимистично, но в науке, увы, нет никакого волшебства: чтобы алгоритм мог проделывать такие трюки, его нужно очень хорошо подготовить.
Хотя новые модели и избавились от громоздких словарей, у них появилось множество дополнительных требований. Во-первых, чтобы хорошо оценивать вероятности, алгоритм должен сначала просканировать огромное количество параллельных корпусов. Во-вторых, просто собрать эти тексты недостаточно, нужно их правильно разметить — в частности, установить связи между словами в исходных предложениях и переводе.
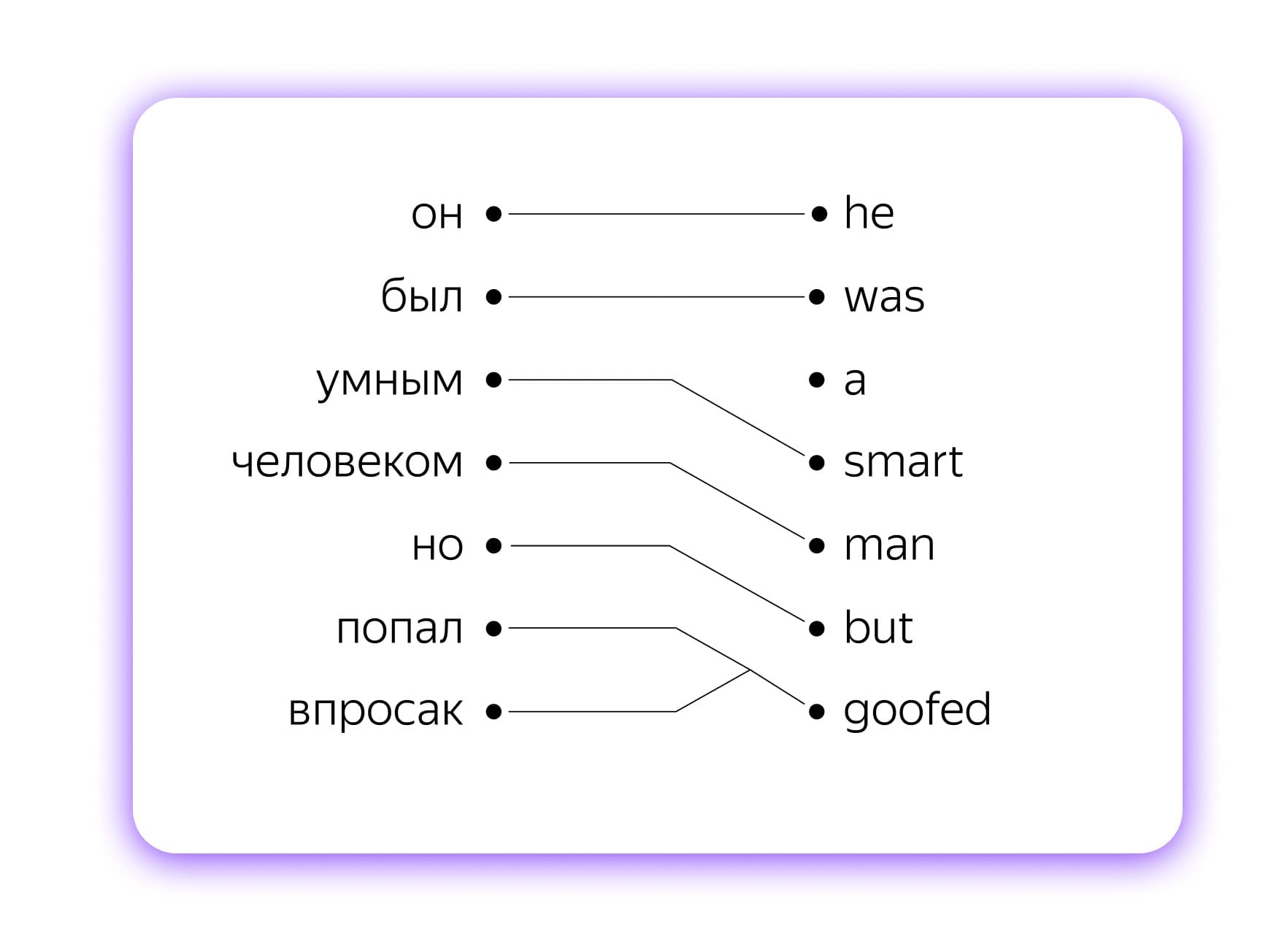
Такие связи называют выравниванием, и это одна из важных составляющих той части алгоритма, которая отвечает за перевод: далеко не всегда одному слову на одном языке соответствует ровно одно на другом. Можно рассмотреть ещё один пример на русском и английском:
Он был умным человеком, но попал впросак.
He was a smart man but goofed.
Фразеологизму «попал впросак» на русском тут соответствует одно слово goofed на английском. А вот артикль a из английского не имеет никакого эквивалента на русском. Чтобы статистическая модель качественно переводила, ей нужно «скормить» как можно больше разных примеров, которые помогут ей понять принципы разных взаимодействий между словами.
Для хорошей статистической модели нужно сконструировать ещё сотни других признаков, которые сделают её более точной и чувствительной, причём для каждого языка они могут быть своими. Вплоть до начала 2010-х именно этим занимались разработчики самых мощных систем перевода. Затем всё радикально изменилось.
Большой взрыв во вселенной переводов
Если сказать, что нейросети совершили революцию в мире машинного перевода, это не будет сильным преувеличением. Посудите сами: подход, который в 2014 году ещё считался научным экспериментом, к 2016 году уже стал стандартом индустрии. Что же случилось?
В 2014 году вышла работа, заложившая основу для современного машинного перевода, — сегодня у неё почти 17 тысяч цитирований в других научных текстах. Модель, которую предложили авторы материала, называлась sequence-to-sequence, или коротко seq2seq. Одной последовательности ставилась в соответствие другая. В задаче перевода это были предложения на двух языках. Важное отличие от статистического подхода заключалось в том, что специальная разметка слов в параллельных корпусах стала не нужна.
Как же переводят модели типа seq2seq? Если говорить упрощённо, алгоритм последовательно «смотрит» на слова в исходном предложении и складывает в память информацию, которую из них получил. Когда текст заканчивается, у модели уже есть обобщённое представление о том, что она «увидела». То есть алгоритм пытается в понятной для него форме выжать из предложения смысл, не привязываясь к конкретным словам. А потом делает обратную операцию: разворачивает смысл в слова, но уже на другом, целевом языке.
Это описание, конечно, очень абстрактно. На самом деле модель читает не сами слова, а их векторные представления — эмбеддинги, в которых, по сути, с помощью цифр кодируются значения разных слов (почитать про них подробнее можно в нашей октябрьской статье). Память модели тоже представляет из себя вектор (или набор векторов), который хранит только ключевые характеристики.
Мы все учились понемногу чему-нибудь и как-нибудь
Главная прелесть нейросетевых моделей заключается в том, что они сами определяют, какие признаки важны. Само собой, делают они это не так, как человек. Алгоритм решает математическую задачу оптимизации, а уже её результатом становятся хорошо работающие параметры, которые зачастую человеку вообще непонятны.
Как обучается модель seq2seq? Допустим, мы хотим натренировать переводчик с немецкого на русский. И сейчас перед нами такая пара предложений:
Ich gehe nach Hause.
Я иду домой.
Сначала модель слово за словом прочитает предложение на немецком и получит вектор обобщения. По нему она попытается предсказать, каким будет первое слово в предложении на русском, потом второе — уже с учётом не только исходного смысла, но и первого слова перевода, и так далее. Предположим, что вместо правильного предложения мы почему-то получили «Я еду в магазин». За каждое неверное слово алгоритм будет оштрафован и в следующий раз попытается выполнить задачу лучше, чтобы свести ошибки к минимуму.
Для обучения нейросетевых переводчиков по-прежнему нужно очень много параллельных корпусов, но не нужна кропотливая разметка текстов. В чём ещё их преимущество? Как вы помните, статистические модели состоят из нескольких частей, и каждую из них приходится «натаскивать» отдельно. Модель seq2seq учится как единая система, что сильно упрощает жизнь разработчиков. А ещё общий принцип можно использовать для всех языковых пар — в итоге нам не нужно конструировать отдельные признаки вручную.
Attention, please!
Все перечисленные выше плюсы seq2seq были второстепенны по сравнению с главным: она просто хорошо работала. Но также у нее была особенность, которая не позволяла получить ещё более высокое качество перевода — её называют проблемой «бутылочного горлышка». Максимально коротко и ёмко её сформулировал эксцентричный американский ученый Рэймонд Муни:
«Вы, блин, не можете впихнуть значение целого предложения в один чёртов вектор!»
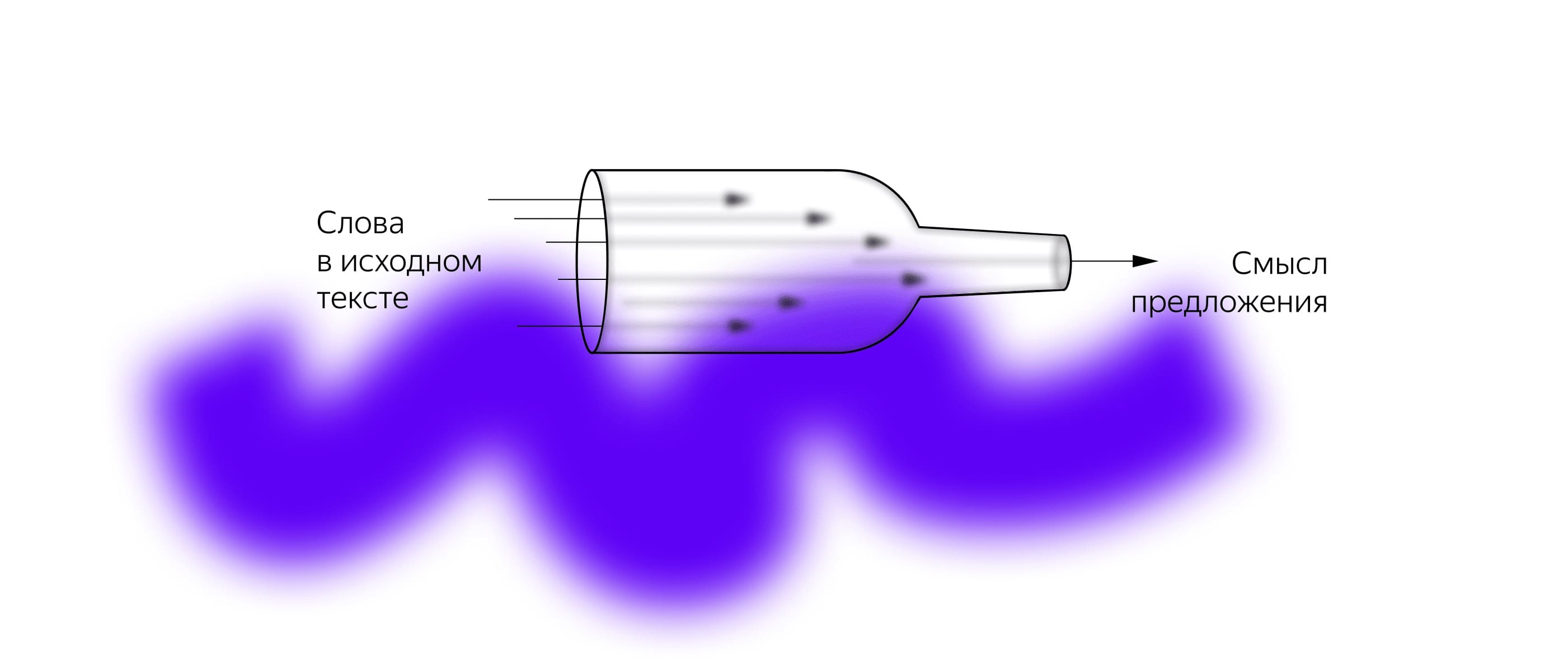
В модели seq2seq разработчики действительно пытались пропустить весь смысл текста через очень узкое «горлышко» модели. И как бы алгоритм ни старался, всё равно часть данных он упускал или искажал. Тогда был придуман новый механизм, который назвали вниманием (attention).
Суть внимания в том, что к обобщающему вектору «памяти» добавляется информация о том, какие слова из исходного текста больше всего влияют на конкретное слово в переводе. Можно подумать, что мы снова говорим о выравнивании, которое используют статистические модели. И действительно, внимание ещё называют «мягким выравниванием». Но его отличие от старых методов всё в том же: все взаимозависимости модель выучивает самостоятельно.
Механизм внимания оказался настолько действенным, что его стали использовать и в других задачах. Подробнее об этом с понятными примерами мы тоже рассказывали в тексте про языковые модели.
После того как внимание вывело нейросети на новый уровень, они вытеснили или почти вытеснили своих предшественников. В 2016 году на нейросетевую систему перевода перешёл Google. А в 2017 году использовать нейросети в своем переводчике стал и Яндекс, но полностью от статистического метода здесь решили не отказываться.
Компания ввела гибридный подход, который дает алгоритмам пространство для манёвра. В систему встроено сразу два переводчика: статистический и нейросетевой, и оба предлагают свои варианты ответа. После этого ещё один алгоритм оценивает результаты их работы и выдаёт пользователю тот, который оказывается лучше (о методах оценки перевода мы ещё поговорим дальше).
Формально гибридный подход применяется в Яндексе и сейчас, но сегодня модель почти никогда не делает выбор в пользу статистической модели.
Есть к чему стремиться
За последние годы машинный перевод сильно шагнул вперёд, в основном за счёт сложных систем, которые по-разному прикладывают к предобработанным текстам механизм внимания. Но эти изменения касаются принципов обработки естественных языков в целом.
Если же говорить именно про машинный перевод, здесь есть несколько перспективных и экспериментальных направлений. Одна из быстро развивающихся областей сегодня — мультиязычные системы перевода.
Многие модели изначально были англоцентричны. Английский использовали как язык-посредник (языковой мост) для тех языков, которые не имели достаточного количества параллельных корпусов. То есть сначала текст переводился с исходного языка на английский, а потом уже с английского — на целевой. Минус такого подхода очевиден: при двойном переводе ошибки тоже удваиваются. Но мультиязычные модели позволяют этого избежать. Одну из мощных систем такого типа в 2020 году представил Facebook: M2M-100 переводит между любой парой из 100 языков, не используя английский.
Кстати, тот же Facebook в своё время выпустил работу, которая иллюстрирует ещё одно популярное направление для экспериментов. В 2018 году в компании показали, как можно обучать языковую модель вообще без параллельных корпусов. Идея такого обучения заключается в том, что модель получает неразмеченные тексты и по ним сама находит взаимосвязи и схожесть между словами на разных языках.
Звучит отлично, но работает, увы, не всегда. Как писали авторы одного из исследований 2020 года, качество таких моделей сильно зависит от данных и сильно падает, если, например, тексты для обучения на двух языках взяли из разных предметных областей.
Когда компьютер лучше человека
До этого мы много говорили о качестве систем перевода, но не затронули важный вопрос: а как, собственно, это качество определяется? Есть несколько метрик для оценки, но самая популярная из них — это BLEU. Чтобы оценить перевод по этой метрике, мы должны посмотреть, как один и тот же текст перевёл компьютер и человек. Чем больше слов совпадает, тем более высокий результат мы получим.
BLEU расшифровывается как Bilingual Evaluation Understudy, на русский обычно переводится как «двуязычная оценка дублёра».
Метрика BLEU полезна, но очень несовершенна. Представьте, что перед вами два перевода с английского на русский предложения I saw a cat:
Я видел кота.
Я видел кошку.
Оба варианта правильные, но если один из них был эталонным переводом человека, а второй — ответом машины, компьютер не получит полный балл за свою работу, ведь кот и кошка — разные слова.
Это примитивный пример, но на проблему можно посмотреть и под более интересным углом. Вот как о ней говорит руководитель службы качества машинного перевода Яндекса Алексей Носков: «Когда люди переводят тексты, они всегда немного упрощают. Поэтому переведённые тексты, которые считаются эталонными для перевода, уже сами не являются естественным примером живого языка. Когда модель становится уж очень хорошей, притягивать её качество к человеческому не совсем корректно, потому что иногда система начинает переводить лучше, чем человек».
Метрику BLEU критикуют чуть ли не с первого дня её существования, но ничего более универсального для сравнения разных моделей пока так и не придумали. Правда, для своих задач в Яндексе используют и другие варианты оценки: например, просят оценить качество машинного перевода энтузиастов Яндекс.Толоки.
Что-то пошло не так
С нейросетевым переводом есть и другие сложности, одна из них — его предвзятость. Обучая модели, мы пытаемся добиться того, чтобы они освоили наш язык. Но вместе с пониманием лингвистических принципов алгоритмы часто впитывают и наши собственные стереотипы. Из-за этого, например, оказалось, что машинный перевод можно поймать на сексизме.
Посмотрим, например, на малайский язык — один из гендерно-нейтральных. Это значит, что и «он», и «она» переводятся одинаково: dia. Но если вбить в переводчик предложение «Он нежный», перевести это предложение на малайский, а потом обратно, то система выдаст уже другой вариант — «Она нежная». А если написать «Она мудрая», то при той же операции на выходе получим «Он мудрый».

Само собой, дело тут не в каких-то симпатиях или антипатиях машины (у которой их просто нет), а в том, что она следует выученной логике — в том виде, в котором она извлекает её из текстов, где сочетания вроде «она нежная/прекрасная/хрупкая» встречаются чаще, чем аналогичные в мужском роде. Сегодня над этой проблемой активно работают. Решения для некоторых языковых пар уже встречаются на практике, но полностью победить гендерную предвзятость пока не удаётся.
Ещё один странный феномен, о котором любят шутить в сетях, тоже связан с тем, как нейросетевые модели получают свои знания. Вы наверняка видели примеры того, как онлайн-переводчики буквально сходят с ума и в ответ на несуразный набор букв выдают апокалиптические тексты. Нет, машины не хотят обратить вас в свою веру. Они просто пытаются выполнить свою задачу.
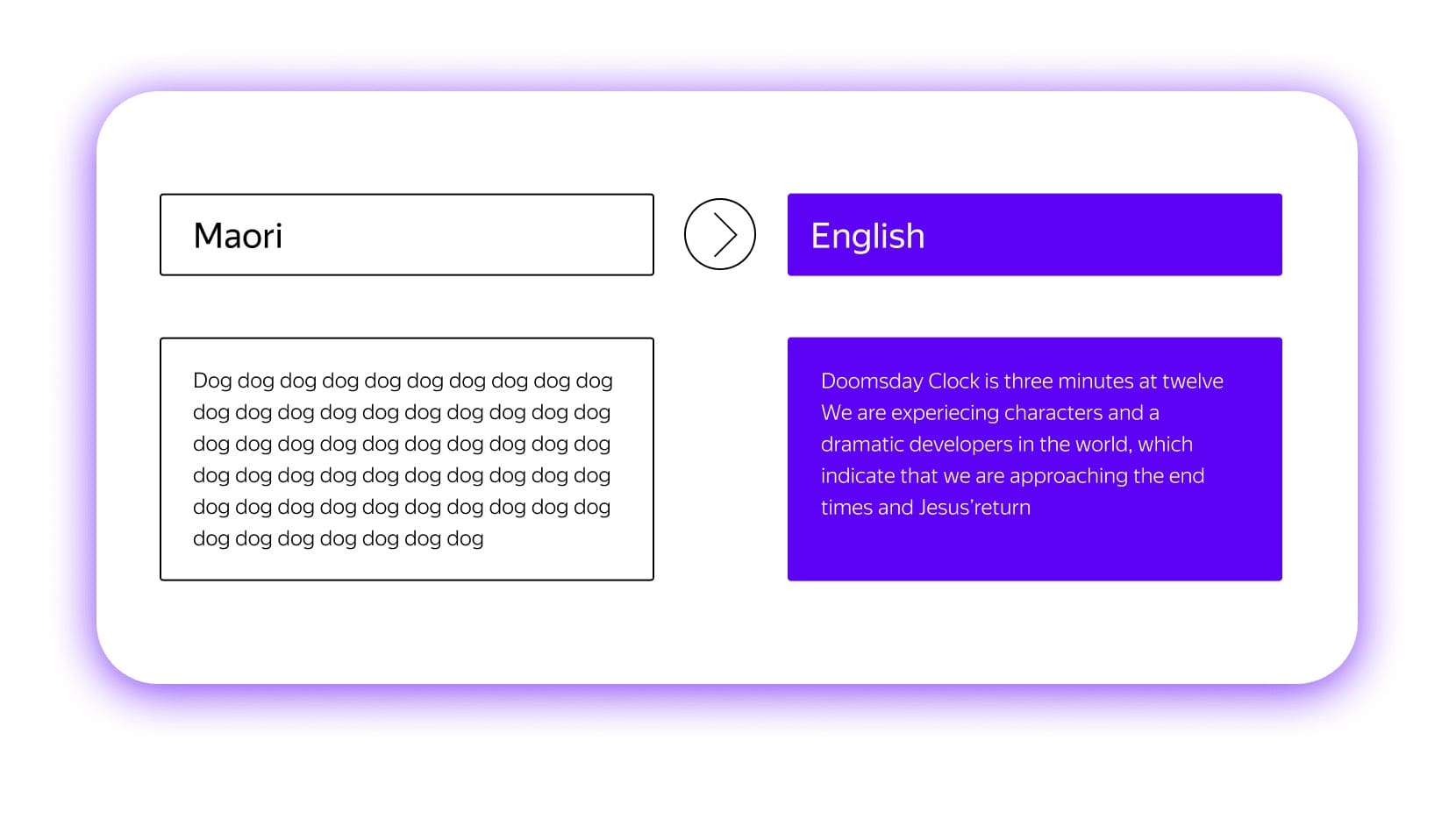
Как правило, такое случается, когда модель пытается сделать перевод с какого-то редкого языка. И если система получает на входе неадекватный набор символов, она не находит ничего лучше, чем просто выдать фрагмент самого знакомого для неё текста: им в большинстве случаев становится Библия.
На самом деле с переводом так называемых малоресурсных языков есть намного более серьёзные проблемы, но о них мы поговорим отдельно: о том, как работают с такими языками, вы можете узнать из следующего текста.
Источник: techno.yandex.ru