Шёпот и эмоции в Алисе: история развития голосового синтеза Яндекса
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-12-16 12:06
алгоритмы распознавания речи, распознавание образов, примеры ии, голосовые помощники

Исследования показывают, что желание общаться с голосовым помощником напрямую зависит от того, насколько точно он имитирует речь людей. Поэтому мы постоянно работаем над «очеловечениванием» голоса Алисы. С тех пор сменилось несколько поколений нашего голосового синтеза. Мы научились расставлять интонации, отличать «замОк» от «зАмка» и многое другое. Сейчас мы переходим на следующий уровень: учим Алису управлять эмоциями и стилем своей речи, распознавать шёпот и отвечать на него шёпотом. Казалось бы, что в этом сложного и почему всё это было невозможно ещё несколько лет назад? Вот об этом я и расскажу сегодня сообществу Хабра.
Ранний параметрический синтез: эпоха до Алисы
Мы начали заниматься голосовыми технологиями в 2012 году. Через год родился SpeechKit. Ещё через год мы научились синтезировать голос — возможно, вы помните YaC 2014 и экспериментальный проект Яндекс.Диктовка. С тех пор прогресс не останавливается.
Исторически речевой синтез бывает двух видов: конкатенативный и параметрический. В случае с первым, есть база кусочков звука, размеченных элементами речи — словами или фонемами. Мы собираем предложение из кусочков, конкатенируя (то есть склеивая) звуковые сегменты. Такой метод требует большой базы звука, он очень дорогой и негибкий, зато до пришествия нейросетей давал самое высокое качество.
При параметрическом синтезе базы звука нет — мы рисуем его с нуля. Из-за большого прыжка в размерности end2end работает плохо даже сейчас. Лучше разделить это преобразование на два шага: сначала нарисовать звук в особом параметрическом (отсюда название метода) пространстве, а затем преобразовать параметрическое представление звука в wav-файл.
В 2014 году нейросетевые методы речевого синтеза только зарождались. Тогда качеством правил конкатенативный синтез, но нам в эру SpeechKit было необходимо легковесное решение (для Навигатора), поэтому остановились на простом и дешёвом параметрическом синтезе. Он состоял из двух блоков:
- Первый — акустическая модель. Она получает лингвистические данные (разбитые на фонемы слова и дополнительную разметку) и переводит их в промежуточное состояние, которое описывает основные свойства речи — скорость и темп произнесения слов, интонационные признаки и артикуляцию — и спектральные характеристики звука. К примеру, в начале, до появления Алисы, в качестве модели мы обучали рекуррентную нейросеть (RNN) с предсказанием длительности. Она достаточно хорошо подходит для задач, где нужно просто последовательно проговаривать фонемы и не надо рисовать глобальную интонацию.
- Затем данные передаются на второй блок — вокодер — который и генерирует звук (то есть создаёт условный wav) по его параметрическому представлению. Вокодер определяет низкоуровневые свойства звука: sampling rate, громкость, фазу в сигнале. Наш вокодер в первой системе был детерминированным DSP-алгоритмом (не обучался на данных) — подобно декодеру mp3, он «разжимал» параметрическое представление звука до полноценного wav. Естественно, такое восстановление сопровождалось потерями — искусственный голос не всегда был похож на оригинал, могли появляться неприятные артефакты вроде хрипов для очень высоких или низких голосов.
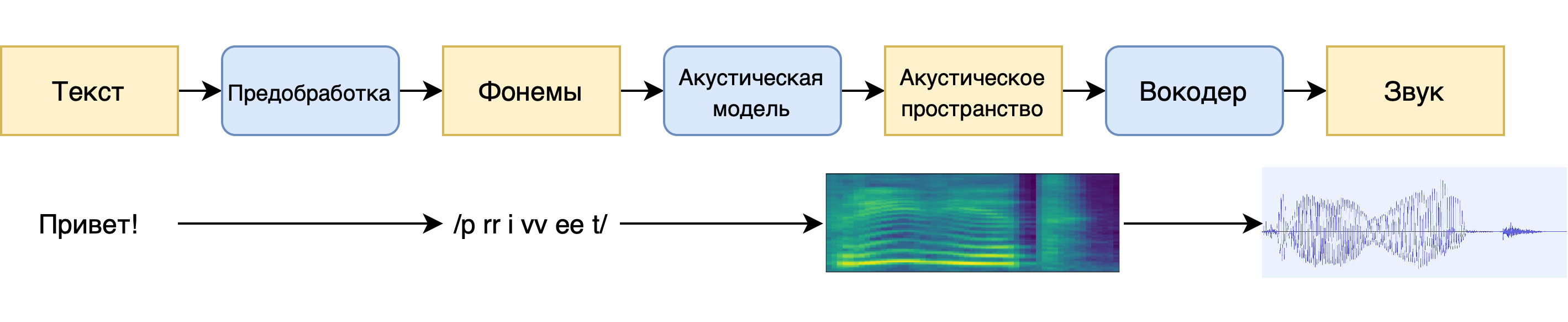
Это стандартная архитектура для любой ранней параметрики со своими достоинствами и недостатками. Главный плюс — для обучения модели нужно мало данных (нам хватило 5-10 часов записей человеческой речи). Можно синтезировать любой произвольный текст, который даже будет плавно звучать. К сожалению, слишком плавно: недостатком раннего параметрического синтеза было то, что полученный голос звучал неестественно. Он был слишком гладким, лишённым интонаций и эмоций, звенел металлом. Люди так не говорят.
Вот как звучал голос при раннем параметрическом синтезе:

Конкатенативный синтез: рождение Алисы
В 2016 году мы решили создать Алису — сразу было понятно, что это более амбициозная задача, чем всё, чем занимались раньше. Дело в том, что в отличие от простых TTS-инструментов, голосовой помощник должен звучать человечно, иначе люди просто не станут с ним (или с ней) общаться. Предыдущая архитектура совершенно не подходила. К счастью, был и другой подход. Точнее, даже два.
Тогда как раз набирал обороты нейропараметрический подход, в котором задачу вокодера выполняла сложная нейросетевая модель. Например, появился проект WaveNet на базе свёрточной нейросети, которая могла обходиться и без отдельной акустической модели. На вход можно было загрузить простые лингвистические данные, а на выходе получить приличную речь.
Первым импульсом было пойти именно таким путём, но нейросети были совсем сырые и медленные, поэтому мы не стали их рассматривать как основное решение, а исследовали эту задачу в фоновом режиме. На генерацию секунды речи уходило до пяти минут реального времени. Это очень долго: чтобы использовать синтез в реальном времени, нужно генерировать секунду звука быстрее, чем за секунду.
Что же делать? Если нельзя синтезировать живую речь с нуля, нужно взять крошечные фрагменты речи человека и собрать из них любую произвольную фразу. Напомню, что в этом суть конкатенативного синтеза, который обычно ассоциируется с методом unit selection. Пять лет назад он уже давал наилучшее качество (при достаточном количестве данных) в задачах, где была нужна качественная речь в реальном времени. И здесь мы смогли переиспользовать нейросети нашей старой параметрики. Работало это следующим образом:
- На первом шаге мы использовали нейросетевую параметрику, чтобы синтезировать речь с нуля — подобному тому, как делали раньше. Напомню, что по качеству звучания результат нас не устраивал, но мог использоваться как референс по содержанию.
- На втором шаге другая нейросеть подбирала из базы фрагментов записанной речи такие, из которых можно было собрать фразу, достаточно близкую к сгенерированной параметрикой. Вариантов комбинаций фрагментов много, поэтому модель смотрела на два ключевых показателя. Первый — target-cost, точность соответствия найденного фрагмента гипотезе, то есть сгенерированному фрагменту. Второй показатель — join-cost, насколько два найденных соседних фрагмента соответствуют друг другу. По сути, нужно было выбрать вариант, для которого сумма target-cost и join-cost минимальна. Эти параметры можно считать разными способами — для join-cost мы использовали нейросети на базе Deep Similarity Network, а для target-cost считали расстояние до сгенерированной параметрикой гипотезы. Сумму этих параметров, как и принято в unit selection, оптимизировали динамическим программированием.
Кстати, подобный подход использовался и при создании Siri 2.0, согласно опубликованной в 2017 году статье разработчиков Apple, которую мы нашли после того, как запустили прототип Алисы.

У такого подхода тоже есть плюсы и минусы. Среди достоинств — более естественное звучание голоса, ведь исходный материал не синтезирован, а записан вживую. Правда, есть и обратная сторона: чем меньше данных, тем более грубо будут звучать места склейки фрагментов. Для шаблонных фраз всё более-менее хорошо, но шаг влево или вправо — и вы замечаете склейку. Поэтому нужно очень много исходного материала, а это требует многих часов записи голоса диктора. К примеру, в первые несколько лет работы над Алисой нам пришлось записать несколько десятков часов. Это несколько месяцев непрерывной работы с актрисой Татьяной Шитовой в студии.
При этом нужно не просто «прочитать текст по листочку». Чем более нейтрально будет звучать голос, тем лучше. Обычно от актёров ждут эмоциональности, проявления темперамента в своей речи. У нас ровно обратная задача, потому что нужны универсальные «кубики» для создания произвольных фраз.
Вот характерный пример работы синтеза:
Иногда они возвращаются: опять параметрический синтез
В результате мы вернулись к архитектуре из двух последовательных блоков: акустическая модель и вокодер. Правда, на более низком уровне обновилось примерно всё.
1. Акустическая модель
В отличие от старой параметрики, новую модель мы построили на основе seq2seq-подхода с механизмом внимания.
Помните проблему с потерей контекста в нашей ранней параметрике? Если нет нормального контекста, то нет и нормальной интонации в речи. Решение пришло из машинного перевода.
Дело в том, что в машинном переводе как раз возникает проблема глобального контекста — смысл слов в разных языках может задаваться разным порядком или вообще разными структурами, поэтому порой для корректного перевода предложения нужно увидеть его целиком. Для решения этой задачи исследователи предложили механизм внимания — идея в том, чтобы рассмотреть всё предложение разом, но сфокусироваться (через softmax-слой) на небольшом числе «важных» токенов.
При генерации каждого нового выходного токена нейросеть смотрит на обработанные токены (фонемы для речевого синтеза или символы языка для перевода) входа и «решает», насколько каждый из них важен на этом шаге. Оценив важность, сеть учитывает её при агрегировании результатов и получает информацию для генерации очередного токена выхода.
Таким образом нейросеть может заглянуть в любой элемент входа на любом шаге и при этом не перегружается информацией, поскольку фокусируется на небольшом количестве входных токенов. Для синтеза важна подобная глобальность, так как интонация сама по себе глобальна и нужно «видеть» всё предложение, чтобы правильно его проинтонировать.
На тот момент для синтеза была хорошая seq2seq-архитектура Tacotron 2 — она и легла в основу нашей акустической модели.
2. Мел-спектрограмма
Параметрическое пространство можно сжать разными способами. Более сжатые представления лучше работают с примитивными акустическими моделями и вокодерами — там меньше возможностей для ошибок. Более полные представления позволяют лучше восстановить wav, но их генерация — сложная задача для акустической модели. Кроме того, восстановление из таких представлений у детерминированных вокодеров не очень качественное из-за их нестабильности. С появлением нейросетевых вокодеров сложность промежуточного пространства стала расти и сейчас в индустрии одним из стандартов стала мел-спектрограмма.
Она отличается от обычного распределения частоты звука по времени тем, что частоты переводятся в особую мел-частоту звука. Другими словами, мел-спектрограмма — это спектрограмма, в которой частота звука выражена в мелах, а не герцах. Мелы пришли из музыкальной акустики, а их название — это просто сокращение слова «мелодия».

{kind=link}
Эта шкала не линейная и основана на том, что человеческое ухо по-разному воспринимает звук различной частоты. Вспомните строение улитки в ухе: это просто канал, закрученный по спирали. Высокочастотный звук не может «повернуть» по спирали, поэтому воспринимается достаточно короткой частью слуховых рецепторов. Низкочастотный же звук проходит вглубь. Поэтому люди хорошо различают низкочастотные звуки, но высокочастотные сливаются.
Мел-спектрограмма как раз позволяет представить звук, акцентируясь на той части спектра, которая значимо различается слухом. Это полезно, потому что мы генерируем звук именно для человека, а не для машины.
Вот как выглядит мел-спектрограмма синтеза текста «Я — Алиса»:
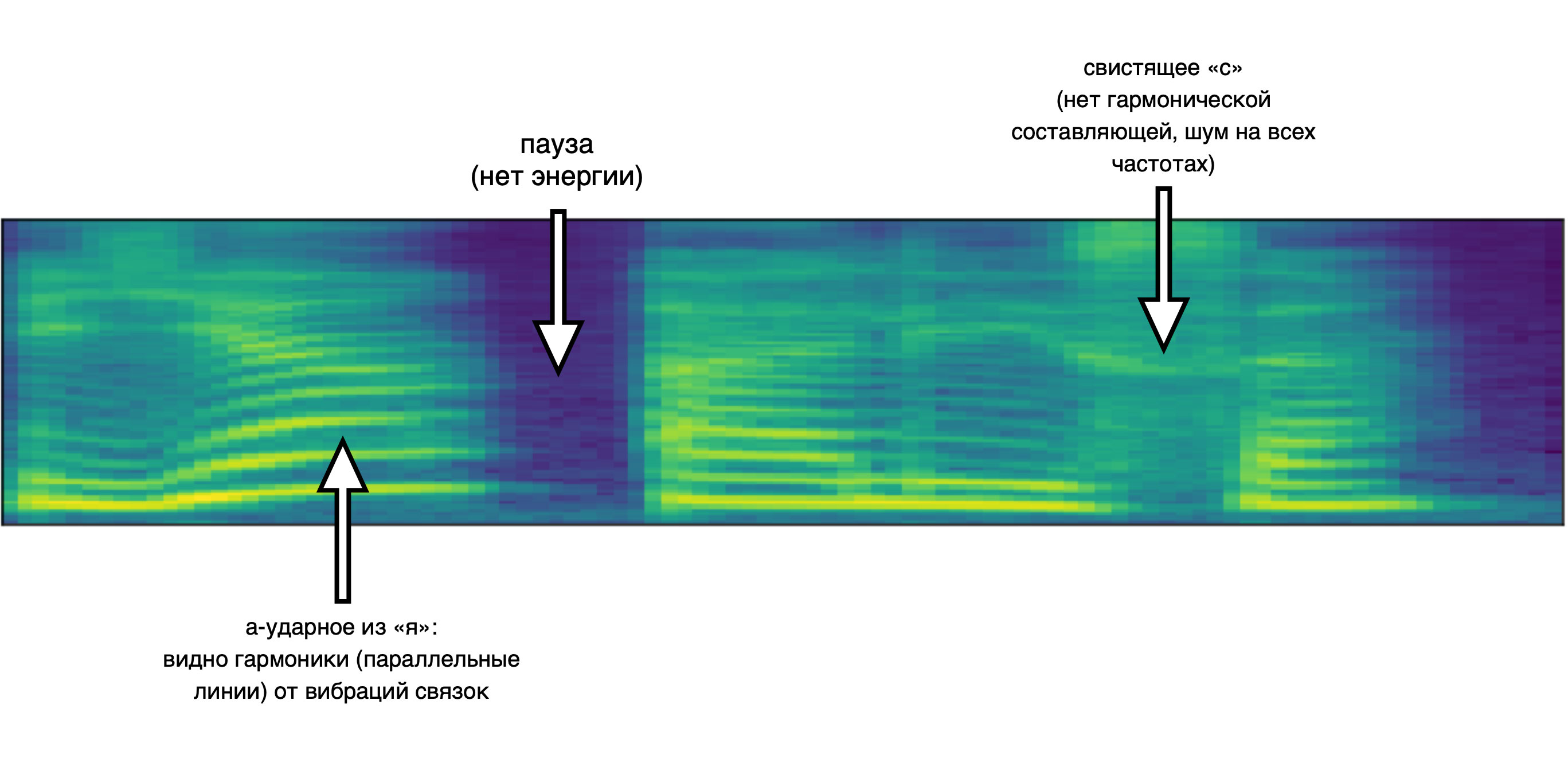
3. Новый вокодер
Вероятно, вы уже догадались, что мы перешли к использованию нового нейросетевого вокодера. Именно он в реальном времени превращает мел-спектрограмму в голос. Наиболее близкий аналог нашего первого решения на основе нейросетей, которое вышло в 2018 году — модель WaveGlow.
Архитектура WaveGlow основана на генеративных потоках — довольно изящном методе создания генеративных сетей, впервые предложенном в статье про генерацию лиц. Сеть обучается конвертировать случайный шум и мел-спектрограмму на входе в осмысленный wav-сэмпл. За счёт случайного шума на входе обеспечивается выбор случайной wav-ки — одной из множества соответствующих мел-спектрограмме. Как я объяснил выше, в домене речи такой случайный выбор будет лучше детерминированного среднего по всем возможным wav-кам. В отличие от WaveNet, WaveGlow не авторегрессионен, то есть не требует для генерации нового wav-сэмпла знания предыдущих. Его параллельная свёрточная архитектура хорошо ложится на вычислительную модель видеокарты, позволяя за одну секунду работы генерировать несколько сотен секунд звука. Затем вышла модель HiFi-GAN, которая сильно выигрывала по качеству у других решений. HiFi-GAN — доработка генеративно-состязательной сети MelGAN, создающей wav-сэмплы на основе мел-спектрограммы. Главное отличие, за счёт которого HiFi-GAN обеспечивает гораздо лучшее качество, заключается в наборе подсетей-дискриминаторов. Они валидируют натуральность звука, смотря на сэмплы с различными периодами и на различном масштабе. Как и WaveGlow, HiFi-GAN не имеет авторегрессионной зависимости и хорошо параллелится, при этом новая сеть намного легковеснее, что позволило при реализации ещё больше повысить скорость синтеза. Кроме того, оказалось, что HiFi-GAN лучше работает на экспрессивной речи, что в дальнейшем позволило запустить эмоциональный синтез — об этом подробно расскажу чуть позже. Летом 2021 года мы полностью перешли на HiFi-GAN.
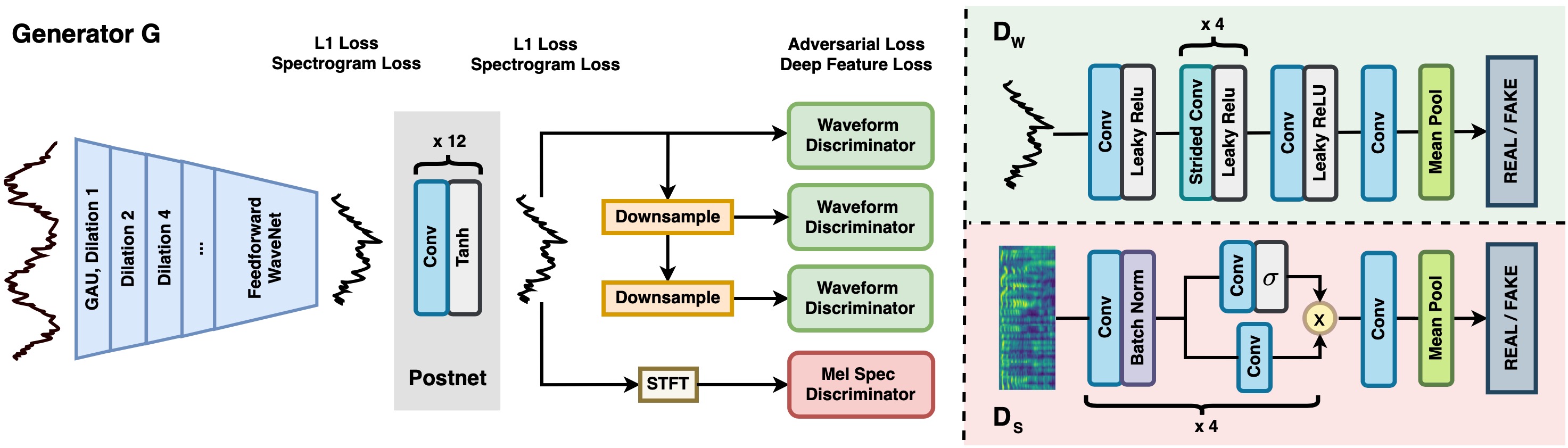
Комбинация этих трёх компонентов позволила вернуться к параметрическому синтезу голоса, который звучал плавно и качественно, требовал меньше данных и давал больше возможностей в кастомизации и изменении стиля голоса.
Параллельно мы работали над улучшением отдельных элементов синтеза:
- Летом 2019 года выкатили разрешатор омографов (homograph resolver) — он научил Алису правильно ставить ударения в парах «зАмок» и «замОк», «белкИ» и «бЕлки» и так далее. Здесь мы нашли остроумное решение. В русском языке эти слова пишутся одинаково, но в английском написание отличается, например, castle и lock, proteins и squirrels. Поэтому мы воспользовались моделью машинного перевода: взяли энкодер переводческой нейросети ru->en и извлекли эмбеддинг русского текста. Из этого представления легко выделить информацию о том, как произносить омограф, ведь перевод должен различать формы для корректного подбора английского варианта. Буквально на 20 примерах можно выучить классификатор для нового омографа, чтобы по эмбеддингу перевода понимать, какую форму нужно произнести.
- Летом 2020 года допилили паузер для расстановки пауз внутри предложения. Язык — хитрая штука. Не все знаки препинания в речи выражаются паузами Например, после вводного слова «конечно» на письме мы ставим запятую, но в речи обычно не делаем паузу. А там, где знаков препинания нет, мы часто делаем паузы. Если эту информацию не передавать в акустическую модель, то она пытается её выводить и не всегда успешно. Первая модель Алисы из-за этого могла начать вздыхать в случайных местах длинного предложения. Задача паузера — предсказать класс паузы (отсутствует/короткая/средняя/длинная) после каждого слова. Для этого мы взяли датасет, разметили его детектором активности голоса, сгруппировали паузы по длительности, ввели класс длины паузы, на каждое слово навесили тэг и на этом корпусе обучили ещё одну голову внимания из тех же нейросетевых эмбеддингов, что использовались для детекции омографов.
- Осенью 2020 года мы перевели на трансформеры нормализацию — в синтезе она нужна, чтобы решать сложные случаи, когда символы читаются не «буквально», а по неким правилам. Например, «101» нужно читать не как «один-ноль-один», а как «сто один», а в адресе yandex.ru нужно произносить точку — «яндекс точка ру». Обычно нормализацию делают через комбинацию взвешенных трансдьюсеров (FST) — правила напоминают последовательность замен по регулярным выражениям, где выбирается замена, имеющая наибольший вес. Мы долго писали правила вручную, но это отнимало много сил, было очень сложно и не масштабируемо. Тогда решили перейти на трансформерную сеть, «задистиллировав» знания наших FST в нейронку. Теперь новые «правила раскрытия» можно добавлять через доливание синтетики и данных, размеченных пользователями Толоки, а сеть показывает лучшее качество, чем FST, потому что учитывает глобальный контекст.
Итак, мы научили Алису говорить с правильными интонациями, но это не сделало ее человеком — ведь в нашей речи есть еще стиль и эмоции. Работа продолжалась.
С чувством, толком, расстановкой: стили голоса Алисы
Один и тот же текст можно произнести десятком разных способов, при этом сам исходный текст, как правило, никаких подсказок не содержит. Если отправить такой текст в акустическую модель без дополнительных меток и обучить её на достаточно богатом различными стилями и интонациями корпусе, то модель сойдёт с ума — либо переусреднит всё к металлическому «голосу робота», либо начнёт генерировать случайный стиль на каждое предложение. Это и произошло с Алисой: в начале она воспроизводила рандомные стили в разговоре. Казалось, что у неё менялось настроение в каждом предложении.
Вот пример записи с явными перебоями в стилях:
Дальше началось самое интересное. Мы взяли образцы синтезированной «мягкой» речи Алисы и фрагменты речи актрисы Татьяны Шитовой, которые относились к более резкому стилю. Затем эти образцы с одним и тем же текстом протестировали вслепую на толокерах. Оказалось, что люди выбирают синтезированный вариант Алисы, несмотря на более плохое качество по сравнению с реальной речью человека. В принципе, этого можно было ожидать: уверен, многие предпочтут более ласковый разговор по телефону (то есть с потерей в качестве) живому, но холодному общению.
К примеру, так звучал резкий голос:
Бодрая или спокойная: управляем эмоциями Алисы
Когда вы включаете утреннее шоу Алисы или запускаете автоматический перевод лекции на YouTube, то слышите разные голоса — бодрый в первом случае и более флегматичный в другом. Эту разницу сложно описать словами, но она интуитивно понятна — люди хорошо умеют распознавать эмоции и произносить один и тот же текст с разной эмоциональной окраской. Мы обучили этому навыку Алису с помощью той же разметки подсказок, которую применили для стилей. У языка есть интересное свойство — просодия, или набор элементов, которые не выражаются словами. Это особенности произношения, интенсивность, придыхание и так далее. Один текст можно произнести со множеством смыслов. Как и в случае со стилями речи, можно, например, выделить кластеры «веселая Алиса», «злая Алиса» и так далее. Поскольку стилевой механизм отделяет просодию («как говорим») от артикуляции («что говорим»), то новую эмоцию можно получить буквально из пары часов данных. По сути, нейросети нужно только выучить стиль, а информацию о том, как читать сочетания фонем, она возьмёт из остального корпуса. Прямо сейчас доступны три эмоции. Например, часть пользователей утреннего шоу Алисы слышат бодрую эмоцию. Кроме того, её можно услышать, спросив Алису «Кем ты работаешь?» или «Какую музыку ты любишь?». Флегматичная эмоция пригодилась для перевода видео — оказалось, что голос по умолчанию слишком игривый для этой задачи. Наконец, радостная эмоция нужна для ответов Алисы на специфические запросы вроде «Давай дружить» и «Орёл или решка?». Ещё есть негативная эмоция, которую пока не знаем, как использовать — сложно представить ситуацию, когда людям понравится, что на них ругается робот.
Первый корпус эмоций мы записали ещё при WaveGlow, но результат нас не устроил и выкатывать его не стали. С переходом на HiFi-GAN стало понятно, что он хорошо работает с эмоциями, это позволило запустить полноценный эмоциональный синтез.
Наконец, мы решили внедрить шёпот. Когда люди обращаются к Алисе шёпотом, она должна и отвечать шёпотом — это делает её человечнее. При этом шёпот — не просто тихая речь, там слова произносятся без использования голосовых связок. Спектр звука получается совсем другим.
С одной стороны, это упрощает детекцию шёпота: по «картинке» мел-спектрограммы можно понять, где заканчивается обычная речь и начинается шепот. С другой стороны, это усложняет синтез шёпота: привычные механизмы обработки и подготовки речи перестают работать. Поэтому шёпотный синтез нельзя получить детерминированным преобразованием сигнала из речи.
Так выглядят мел-спектрограммы обычной речи и шёпота при произнесении одной и той же фразы:
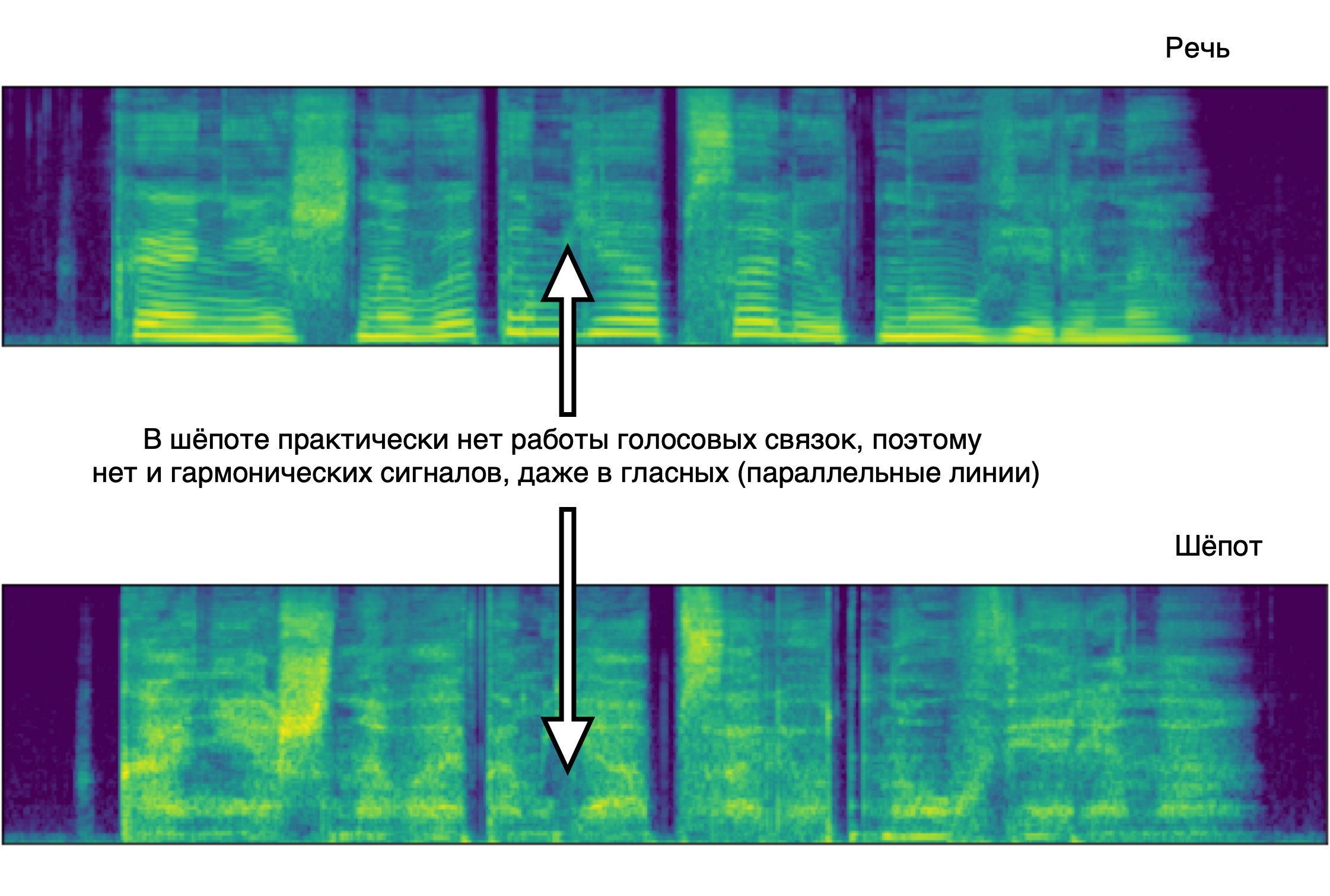
Затем записанные данные добавили в обучающий корпус акустической модели. Мы решили рассматривать шёпот как еще один «стиль» речи или, в терминах нашего синтеза, «эмоцию». Добавив данные в трейнсет, мы дали акустической модели на вход дополнительную информацию — шёпот или эмоцию она сейчас проигрывает. По этому входу модель научилась по команде пользователя переключаться между генерацией речи и шёпота.
Сгенерированный шёпот по качеству не отличался от обычной речи. По нашей метрике PSER (Pronunciation Sentence Error Rate — средняя доля ошибок произношения в предложении) он оказался даже лучше. Оказалось, что ряд ошибок интонации в шёпотной речи были значительно менее ярко выражены.
Этот голос будет полезен при общении с Алисой ночью, чтобы не мешать близким. Можно задавать вопросы тихим голосом и Алиса будет отвечать шёпотом. Кроме того, такой стиль ещё и звучит очень приятно — поклонники ASMR оценят.
Послушайте, как шепчет Алиса:
Источник: habr.com