? Как выбрать видеокарту для нейронных сетей и глубокого обучения
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-12-11 11:21

1. Разница между ЦП и ГП
 Рис. 1. Архитектура центрального процессора (слева) и графического процессора
Рис. 1. Архитектура центрального процессора (слева) и графического процессора
Центральный процессор (ЦП) не оптимизирован для одновременного выполнения большого количества простых операций. Для параллельных вычислений лучше подходит графический процессор (ГП):
- ГП состоит из множества арифметико-логических устройств (АЛУ);
- бо?льшая часть транзисторов обрабатывает данные, а не занимается кэшированием и управлением потоками;
- процесс создания, управления и удаления потоков происходит эффективнее, чем у ЦП.
 Рис. 2. Иллюстрация сравнения скорости работы центрального процессора («рисует» смайлик) и графического процессора («рисует» Мону Лизу)
Рис. 2. Иллюстрация сравнения скорости работы центрального процессора («рисует» смайлик) и графического процессора («рисует» Мону Лизу)
2. Устройство ГП
2.1. CUDA
Графический процессор состоит из набора независимых мультипроцессоров, которые включают в себя:
- CUDA-ядра;
- модули вычисления математических функций SFU;
- конвейер;
- разделяемую память и кэш.
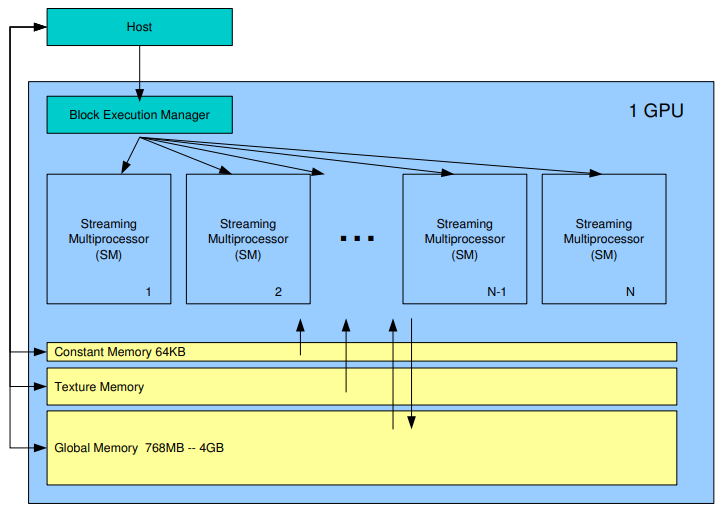 Рис. 3. Структура графического процессора
Рис. 3. Структура графического процессора
На одном ядре CUDA (архитектура параллельных вычислений от NVIDIA) выполняется одна нить, иначе – поток. Каждому потоку соответствует один элемент вычисляемых данных. Потоки образуют блоки, которые общаются между собой через:
- разделяемую память;
- барьерную синхронизацию.
При частоте 1 ГГц процессор делает 109 циклов в секунду. Операции занимают больше времени, чем один цикл, поэтому создается конвейер, где для начала новой операции необходимо дождаться окончания предыдущей.
Мультипроцессор на каждом такте выполняет одну и ту же инструкцию над варпом (warp) – группой из 32 потоков. Потоки одного варпа принадлежат одному блоку и могут взаимодействовать только между собой. Каждому потоку и блоку присваивается идентификатор – трехмерный целочисленный вектор:
threadIdx– номер потока в блоке;blockIdx– номер блока, в котором находится поток.
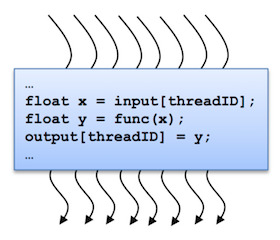 Рис. 4. Переменные нитей в CUDA
Рис. 4. Переменные нитей в CUDA
Блоки группируются в сетки блоков. Размеры блока и сетки блоков задаются переменными blockDim и gridDim при вызове ядра. Потокам из одного блока доступна разделяемая память (shared memory). Их выполнение может быть синхронизировано.
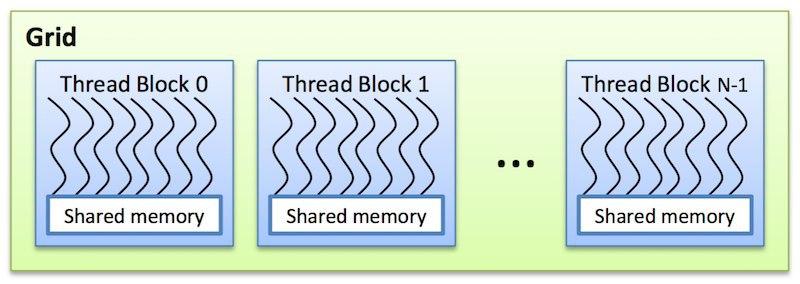 Рис. 5. Сетка блоков в CUDA
Рис. 5. Сетка блоков в CUDA
Алгоритм работы технологии CUDA выглядит следующим образом.
- Выделение памяти на ГП.
- Копирование расчетных данных в выделенную память ГП.
- Вычисления на ядрах ГП.
- Перенос результатов вычислений в оперативную память для обработки ЦП.
- Освобождение памяти ГП.
2.2. Иерархия памяти
Локальная память (local memory):
- у каждого потока есть своя локальная память;
- она существует на протяжении жизни потока.
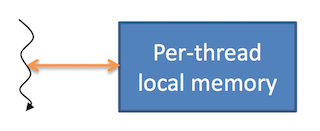 Рис. 6. Локальная память в CUDA
Рис. 6. Локальная память в CUDA
Разделяемая память (shared memory):
- доступна потокам внутри одного блока;
- существует в течение жизни блока;
- быстрее, чем локальный и глобальный виды.
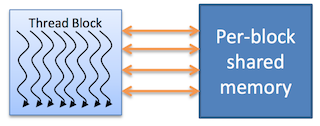 Рис. 7. Разделяемая память блока нитей в CUDA
Рис. 7. Разделяемая память блока нитей в CUDA
Глобальная память (global memory):
- доступна всем потокам во всех блоках;
- сохраняет состояние в течение работы программы.
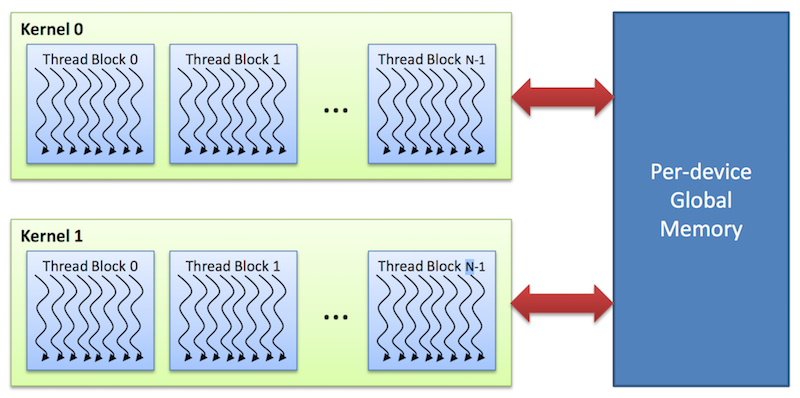 Рис. 8. Глобальная память сетки блоков в CUDA
Рис. 8. Глобальная память сетки блоков в CUDA
Константная память (constant memory):
- кэширует данные.
Текстурная память (texture memory):
- адресует и фильтрует данные.
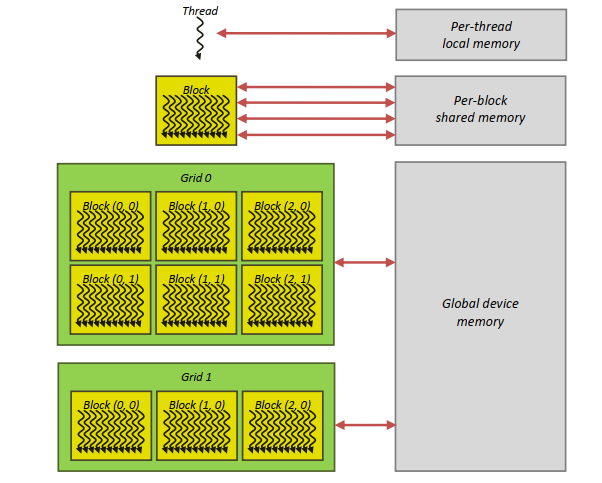 Рис. 9. Иерархия памяти в CUDA: поток (локальная память) ? блоки (разделяемая память) ? сетка блоков (глобальная память)
Рис. 9. Иерархия памяти в CUDA: поток (локальная память) ? блоки (разделяемая память) ? сетка блоков (глобальная память)
Примечание
Подробнее о структуре CUDA читайте в нашей статье «Знакомство с программно-аппаратной архитектурой CUDA».
3. Как выбрать ГП
Последовательность шагов при выборе ГП.
- Определить область применения: соревнования в Kaggle, глубокое обучение, исследования в области компьютерного зрения, обработка естественного языка и т. д.
- Выбрать необходимый объем памяти.
- Узнать: сколько видеокарт поместится в системном блоке; правильно ли организована циркуляция воздуха в системном блоке; хватит ли мощности блока питания.
3.1. Когда достаточно менее 11 ГБ памяти
Базовые навыки в глубоком обучении можно освоить, тренируясь на небольших задачах с малыми входными параметрами, поэтому достаточно RTX 3070 (8 ГБ, GDDR6) и RTX 3080 (10 ГБ, GDDR6X). Для прототипирования лучший выбор – RTX 3080.
 Рис. 10. Видеокарта NVIDIA RTX 3080
Рис. 10. Видеокарта NVIDIA RTX 3080
3.2. Когда нужно больше 11 ГБ памяти
Не менее 11 ГБ памяти нужно при работе с архитектурой Transformer, распознаванием медицинских изображений, компьютерным зрением и работой с большими изображениями.
3.3. Тензорные ядра
Тензорные ядра быстрее CUDA-ядер, потому что им требуется меньше циклов для операций с матрицами. В чипах Ampere (линейка RTX 30) стало меньше тензорных ядер, но возросла их производительность.
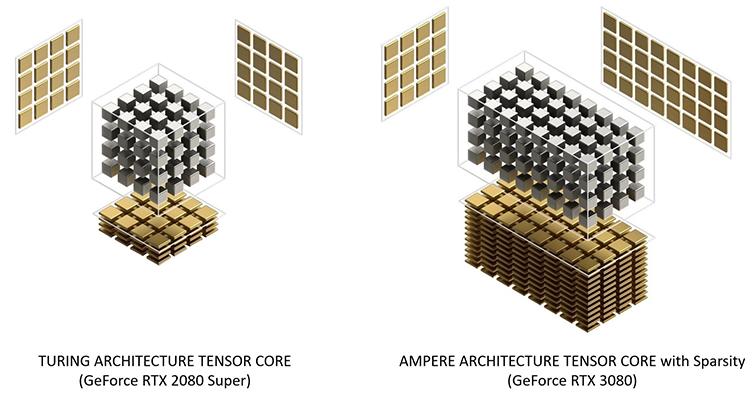 Рис. 11. Архитектура тензорных ядер в GeForce RTX 2080 Super и GeForce RTX 3080
Рис. 11. Архитектура тензорных ядер в GeForce RTX 2080 Super и GeForce RTX 3080
3.4. Пропускная способность памяти
Тензорные ядра быстрые и обычно простаивают до 70% времени, ожидая данные из глобальной памяти. Поэтому выбирайте ГП с максимальной пропускной способностью памяти. Еще нужна большая разделяемая память и кэш L1, чтобы сократить число обращений к внешней памяти и держать данные ближе к АЛУ.
Сколько нужно памяти:
- при использовании предобученных моделей в Transformer ? 11 ГБ;
- обучение больших моделей в Transformer или в сверточных нейронных сетях ? 24 ГБ;
- прототипирование нейронных сетей ? 10 ГБ;
- для Kaggle ? 8 ГБ;
- компьютерное зрение ? 10 ГБ.
3.5. Система охлаждения
В конструкции системы охлаждения Reference RTX 30 (NVIDIA) первый вентилятор расположен на верхней стороне видеокарты. Он выдувает воздух в пространство, где расположена оперативная память и процессор. Второй вентилятор выдувает воздух сразу из корпуса (Рис. 12).
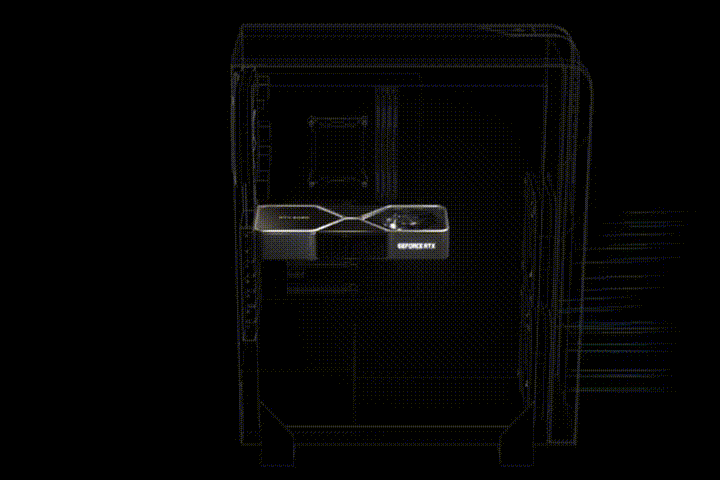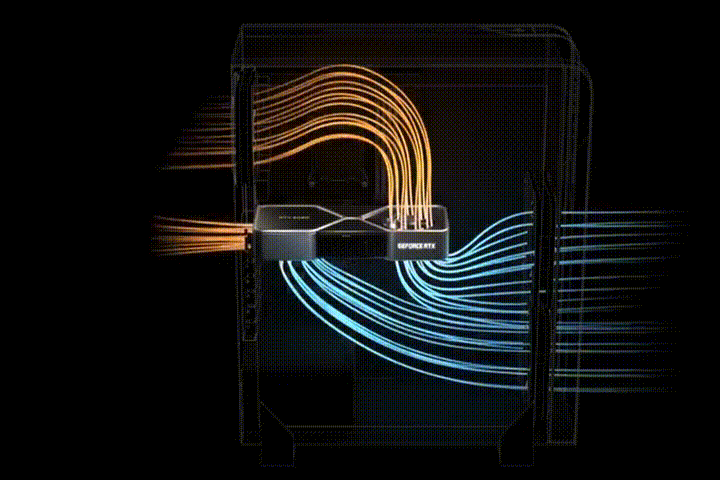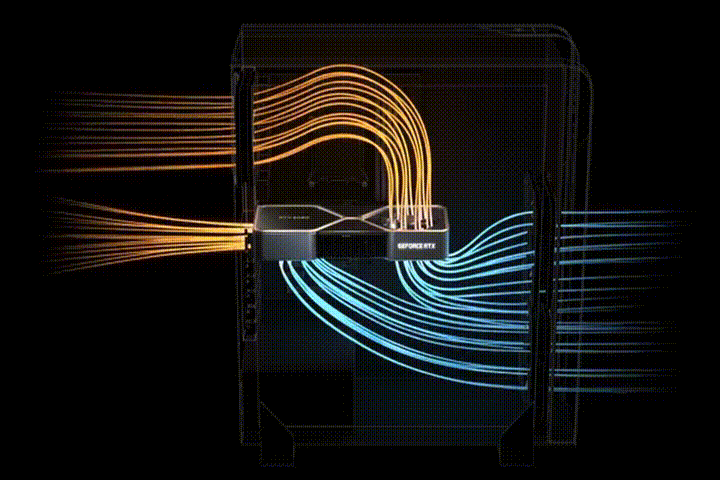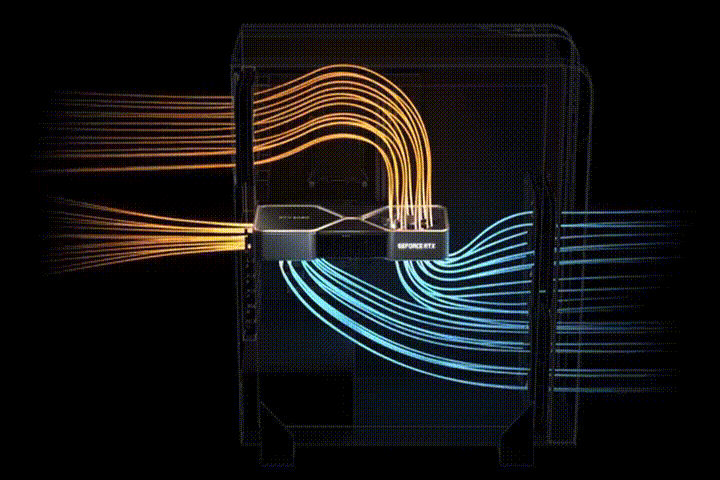 Рис. 12. Cистема охлаждения Reference RTX 30
Рис. 12. Cистема охлаждения Reference RTX 30
Еще нет тестов, подтверждающих эффективность решения и необходимость замены штатной системы охлаждения. Установка нескольких ГП в одном корпусе может негативно сказаться на циркуляции потоков воздуха внутри корпуса и охлаждении видеокарт.
3.6. Электропитание
Картам может не хватить мощности блока питания. Четыре карты RTX 3090 потребляют на пике 1400 Вт. Продаются блоки питания на 1600 Вт, но остальным комплектующим 200 Вт может быть недостаточно.
 Рис. 13. Блок питания Super Flower Leadex Titanium SF-1600F14HT на 1600 Вт
Рис. 13. Блок питания Super Flower Leadex Titanium SF-1600F14HT на 1600 Вт
3.7. Рекомендации для кластеров
Для кластеров важно надежное электропитание, доступное в дата-центрах, но по лицензионному соглашению карты RTX в них размещать запрещено. Для небольшой системы подойдет Supermicro 8 GPU.
 Рис. 14. Сервер SuperMicro Superserver 4028gr-tvrt, до 8 Tesla v100 sxm2
Рис. 14. Сервер SuperMicro Superserver 4028gr-tvrt, до 8 Tesla v100 sxm2
Для кластера из 256+ ГП – NVIDIA DGX SuperPOD.
 Рис. 15. Суперкомпьютер NVIDIA DGX SuperPOD
Рис. 15. Суперкомпьютер NVIDIA DGX SuperPOD
При 1024+ ГП – Google TPU Pod и NVIDIA DGX SuperPod.
 Рис. 16. Суперкомпьютер Google TPU Pod на тензорных процессорах
Рис. 16. Суперкомпьютер Google TPU Pod на тензорных процессорах
3.8. Не покупайте эти карты
Не покупайте более одной видеокарты RTX Founders Editions или RTX Titans, если нет PCIe-удлинителей для решения проблем с охлаждением.
 Рис. 17. Видеокарта NVIDIA RTX Titan
Рис. 17. Видеокарта NVIDIA RTX Titan
Tesla V100 или A100 рентабельны только в кластерах. Карты серии GTX 16 имеют низкую производительность, так как из них убрали тензорные ядра. Аналоги GTX 16: б/у RTX 2070, RTX 2060 или RTX 2060 Super.
 Рис. 18. Видеокарта NVIDIA Tesla V100
Рис. 18. Видеокарта NVIDIA Tesla V100
При наличии RTX 2080 Ti и выше, обновление до RTX 3090 невыгодно. Прирост производительности мал, а риск получить проблемы с питанием и охлаждением в картах RTX 30 высокий. Апгрейд оправдан, если для задач требуется больше памяти.
3.9. Нужен ли PCI 4.0?
Для бюджетной домашней сборки PCI 4.0 не нужен. PCI 4.0 позволит лучше распараллелить и ускорить передачу данных на 1-7% в сравнении с PCIe 3.0 при использовании более четырех ГП. При работе с большими файлами «узким местом» может оказаться SSD-диск, но не передача данных с ГП на ЦП.
3.10. Необходимы только 8x/16x PCIe-слоты?
Использовать исключительно 8x и 16x PCIe-слоты необязательно. Допускается работа двух ГП на слотах 4х. При установке четырех ГП предпочтение отдавайте слотам 8x на каждый ГП, так как производительность слота 4x ниже на 5-10%.
 Рис. 19. Слоты PCIe x1, x4, x16
Рис. 19. Слоты PCIe x1, x4, x16
3.11. Можно ли использовать разные карты вместе?
Да, можно! Но будет сложно эффективно распараллелить графические процессоры разных типов, т. к. быстрый ГП будет ждать, пока медленный ГП дойдет до точки синхронизации.
3.12. Что такое NVLink и полезно ли это?
NVLink – высокоскоростное соединение между ГП. В небольших кластерах (< 128 ГП) он не даст преимущества по сравнению с передачей по PCIe.
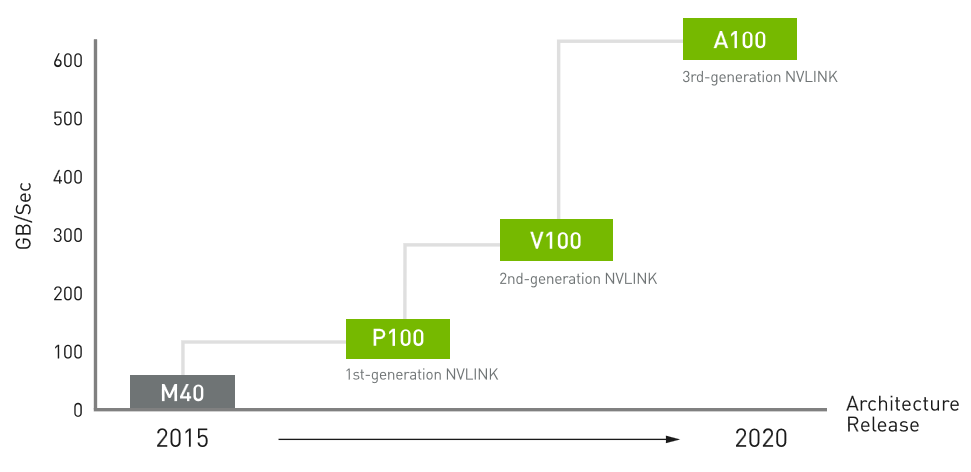 Рис. 20. Производительность NVLink M40, P100, V100 и A100
Рис. 20. Производительность NVLink M40, P100, V100 и A100
3.13. Что делать, если не хватает денег на топовые ГП?
Купить подержанные ГП, либо воспользоваться облачными сервисами. Бюджетные варианты (в порядке убывания цены и производительности):
- RTX 2070 или RTX 2060;
- GTX 1070 или GTX 1070 Ti;
- GTX 980 Ti (6 GB) или GTX 1650 Super.
3.14. Итог
- топовые карты: RTX 3080, RTX 3090;
- вторая лига: RTX 3070, RTX 2060 Super;
- бюджетный вариант: RTX 2070, RTX 2060, GTX 1070, GTX 1070 Ti, GTX 1650 Super, GTX 980 Ti;
- новичкам: RTX 3070;
- просто попробовать: RTX 2060 Super, GTX 1050 Ti, облачные сервисы;
- соревнования Kaggle: RTX 3070;
- компьютерное зрение, машинный перевод: четыре RTX 3090;
- NLP с простыми вычислениями: RTX 3080;
- кластеры менее 128 ГП: 66% 8x RTX 3080 и 33% 8x RTX 3090;
- кластеры от 128 до 512 ГП: 8x Tesla A100;
- кластеры более 512 ГП: DGX A100 SuperPOD;
Напоследок несколько сравнительных гистограмм характеристик различных GPU.
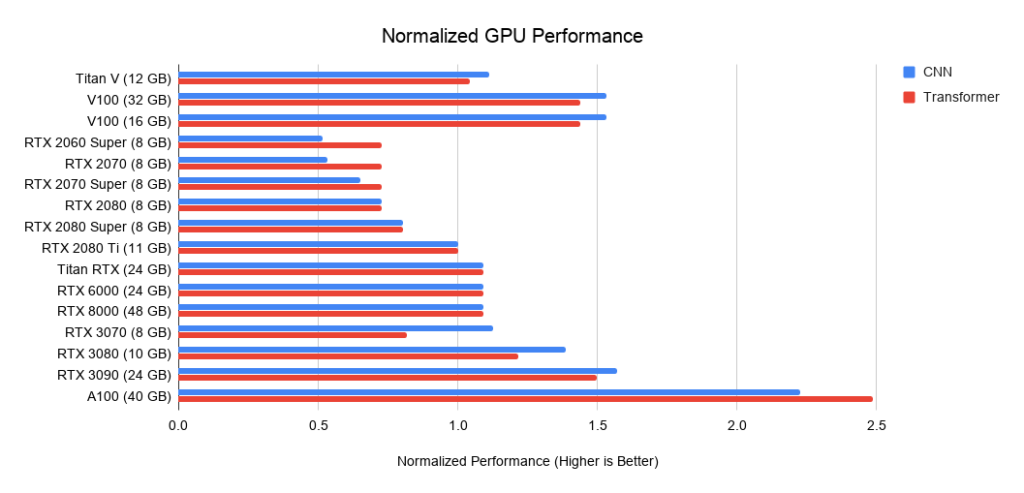 Рис. 21. Производительность видеокарт относительно RTX 2080 Ti.
Рис. 21. Производительность видеокарт относительно RTX 2080 Ti.
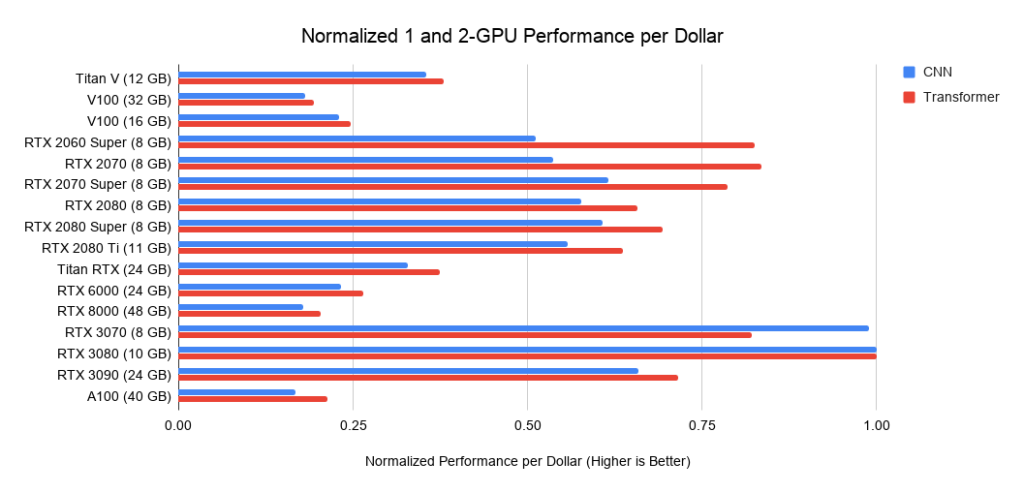 Рис. 22. Производительность на доллар (US) ГП относительно RTX 3080.
Рис. 22. Производительность на доллар (US) ГП относительно RTX 3080.
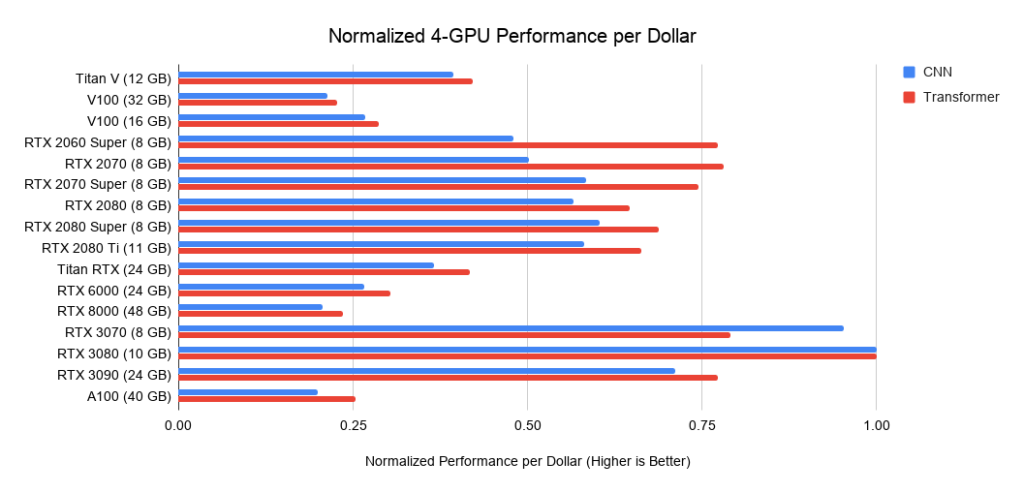 Рис. 23. Производительность на доллар (US) четырех ГП относительно четырех RTX 3080.
Рис. 23. Производительность на доллар (US) четырех ГП относительно четырех RTX 3080.
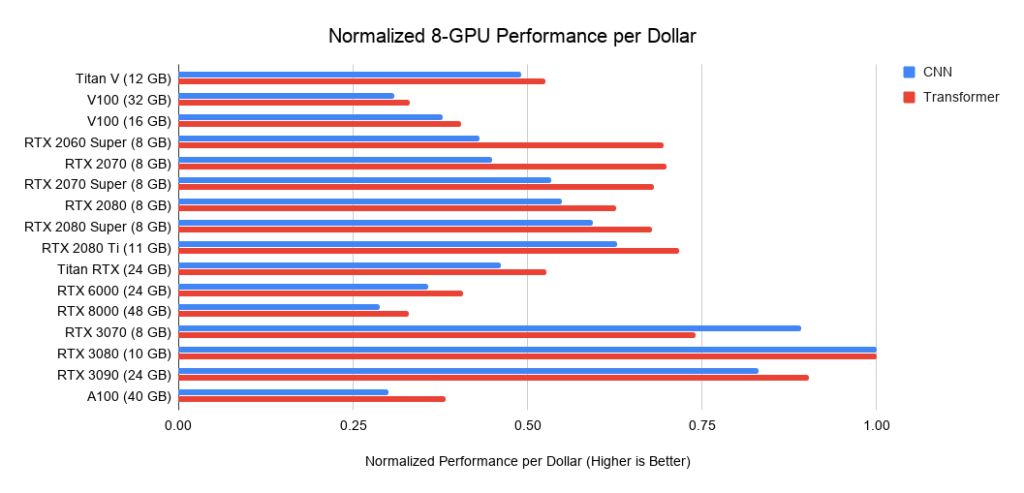 Рис. 24. Производительность на доллар (US) восьми ГП относительно восьми RTX 3080.
Рис. 24. Производительность на доллар (US) восьми ГП относительно восьми RTX 3080.
***
В этом руководстве мы рассмотрели устройство графического процессора и определили параметры, которые влияют на производительность в задачах глубокого обучения. Если запускаете расчет нейросеток время от времени, то апгрейд можно проводить через одно поколение графических процессоров.
Источники
- Введение в GPU (англ.)
- Основы CUDA (pdf, англ.)
- Использование технологии CUDA при разработке приложений для параллельных вычислительных устройств (pdf)
- Какой GPU выбрать для глубокого обучения (англ.)
Больше полезной информации вы найдете на наших телеграм-каналах «Библиотека программиста» и «Книги для программистов».
Интересно, перейти к каналу «Библиотека программиста»
Источник: proglib.io