Градиентный бустинг с CatBoost. (часть 1/3)
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-12-07 07:01

CatBoost – библиотека, которая была разработана Яндексом в 2017 году, представляет разновидность семейства алгоритмов Boosting и является усовершенствованной реализацией Gradient Boosting Decision Trees (GBDT). CatBoost имеет поддержку категориальных переменных и обеспечивает высокую точность. Стоит сказать, что CatBoost решает проблему смещения градиента (Gradient Bias) и смещения предсказания (Prediction Shift), это позволяет уменьшить вероятность переобучения и повысить точность алгоритма.
Открываем Jupyter Notebook и начинаем работать с CatBoost.
Импортируем нужные нам библиотеки:
import pandas as pd import os import numpy as np np.set_printoptions(precision=4) import catboost from catboost import * from catboost import datasets Загружаем набор данных:
(train_df, test_df) = catboost.datasets.amazon()Посмотрим на нашу выборку:
train_df.head()
ACTION – это метка, дали сотруднику доступ или нет. Так же в нашем наборе данных мы имеем 9 признаков, все они числовые, но на самом деле все эти строки хешированные и сравнивать их не имеет смысла.
Отделим таргет и фичи. В X кладем фичи, а в y отправляется таргет.
X = train_df.drop("ACTION", axis=1) y = train_df["ACTION"] Catboost необходимо сказать, какие признаки категориальные, для этого необходимо передать массив с индексами категориальных фичей:
cat_features = list(range(0, X.shape[1])) print(cat_features) [0, 1, 2, 3, 4, 5, 6, 7, 8] Посмотрим на соотношение классов в нашем датасете, для этого посчитаем количество нулей и единиц:
print(f"Labels: {set(y)}") print(f"Zero count: {len(y)-sum(y)}, One count: {sum(y)}") Labels: {0, 1} Zero count: 1897, One count: 30872 Нулей в выборке 1897, а единиц 30872, это свидетельствует о дисбалансе классов, на это надо обращать внимание.
Прежде чем обучить модель, необходимо подготовить данные, данный кусок кода позволяет это сделать:
dataset_dir = "./amazon" if not os.path.exists(dataset_dir): os.makedirs(dataset_dir) train_df.to_csv(os.path.join(dataset_dir, 'train.tsv'), index=False, sep=' ', header=False) test_df.to_csv(os.path.join(dataset_dir, 'test.tsv'), index=False, sep=' ', header=False) train_df.to_csv(os.path.join(dataset_dir, 'train.csv'), index=False, sep=',', header=True) test_df.to_csv(os.path.join(dataset_dir, 'test.csv'), index=False, sep=',', header=True) Посмотрим, как записался наш датасет:
!head amazon/train.csv ACTION,RESOURCE,MGR_ID,ROLE_ROLLUP_1,ROLE_ROLLUP_2,ROLE_DEPTNAME,ROLE_TITLE,ROLE_FAMILY_DESC,ROLE_FAMILY,ROLE_CODE 1,39353,85475,117961,118300,123472,117905,117906,290919,117908 1,17183,1540,117961,118343,123125,118536,118536,308574,118539 1,36724,14457,118219,118220,117884,117879,267952,19721,117880 1,36135,5396,117961,118343,119993,118321,240983,290919,118322 1,42680,5905,117929,117930,119569,119323,123932,19793,119325 0,45333,14561,117951,117952,118008,118568,118568,19721,118570 1,25993,17227,117961,118343,123476,118980,301534,118295,118982 1,19666,4209,117961,117969,118910,126820,269034,118638,126822 1,31246,783,117961,118413,120584,128230,302830,4673,128231 Чтобы Catboost правильно считал наши данные, ему надо понимать, что и в какой колонке лежит, напишем код, который генерирует column description file, где будет описано какая колонка чем является:
from catboost.utils import create_cd feature_names = dict() for column, name in enumerate(train_df): if column == 0: continue feature_names[column-1] = name create_cd( label=0, cat_features=list(range(1, train_df.columns.shape[0])), feature_names=feature_names, output_path=os.path.join(dataset_dir, 'train.cd') ) Посмотрим на сгенерированный файл:
!cat amazon/train.cd 0 Label 1 Categ RESOURCE 2 Categ MGR_ID 3 Categ ROLE_ROLLUP_1 4 Categ ROLE_ROLLUP_2 5 Categ ROLE_DEPTNAME 6 Categ ROLE_TITLE 7 Categ ROLE_FAMILY_DESC 8 Categ ROLE_FAMILY 9 Categ ROLE_CODE Перед нами три колонки: первая колонка – это индексы колонок в файле с обучающей выборкой, вторая колонка – тип, третья колонка – фичи.
Теперь создадим объекты выборки, родной формат для Catboost является Pool, это такой класс, в котором содержатся данные, в конструктор он принимает разные параметры, создаем такие Pool’ы:
pool1 = Pool(data=X, label=y, cat_features=cat_features) pool2 = Pool( data=os.path.join(dataset_dir, 'train.csv'), delimiter=',', column_description=os.path.join(dataset_dir, 'train.cd'), has_header=True ) pool3 = Pool(data=X, cat_features=cat_features) X_prepared = X.values.astype(str).astype(object) pool4 = Pool( data=FeaturesData( cat_feature_data=X_prepared, cat_feature_names=list(X) ), label=y.values ) print("Dataset shape") print(f"Dataset 1: {str(pool1.shape)}") print(f"Dataset 2: {str(pool2.shape)}") print(f"Dataset 3: {str(pool3.shape)}") print(f"Dataset 4: {str(pool4.shape)}") print() print("Column names") print(f"Dataset 1: {pool1.get_feature_names()}") print(f"Dataset 2: {pool2.get_feature_names()}") print(f"Dataset 3: {pool3.get_feature_names()}") print(f"Dataset 4: {pool4.get_feature_names()}") Dataset shape Dataset 1: (32769, 9) Dataset 2: (32769, 9) Dataset 3: (32769, 9) Dataset 4: (32769, 9) Column names Dataset 1: ['RESOURCE', 'MGR_ID', 'ROLE_ROLLUP_1', 'ROLE_ROLLUP_2', 'ROLE_DEPTNAME', 'ROLE_TITLE', 'ROLE_FAMILY_DESC', 'ROLE_FAMILY', 'ROLE_CODE'] Dataset 2: ['RESOURCE', 'MGR_ID', 'ROLE_ROLLUP_1', 'ROLE_ROLLUP_2', 'ROLE_DEPTNAME', 'ROLE_TITLE', 'ROLE_FAMILY_DESC', 'ROLE_FAMILY', 'ROLE_CODE'] Dataset 3: ['RESOURCE', 'MGR_ID', 'ROLE_ROLLUP_1', 'ROLE_ROLLUP_2', 'ROLE_DEPTNAME', 'ROLE_TITLE', 'ROLE_FAMILY_DESC', 'ROLE_FAMILY', 'ROLE_CODE'] Dataset 4: ['RESOURCE', 'MGR_ID', 'ROLE_ROLLUP_1', 'ROLE_ROLLUP_2', 'ROLE_DEPTNAME', 'ROLE_TITLE', 'ROLE_FAMILY_DESC', 'ROLE_FAMILY', 'ROLE_CODE'] Следующим шагом мы разобьем нашу выборку на тестовую и тренировочную, сделаем это с помощью train_test_split из библиотеки Scikit Learn:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.45, random_state=42) Теперь переходим к обучению, здесь у нас будет два параметра – количество итераций и скорость обучения. Напомню, градиентный бустинг – это композиция решающих деревьев, каждое дерево строится последовательно, каждое последующее дерево компенсирует ошибки предсказания предыдущего дерева. По сути, число итераций – это количество деревьев. Если выставить скорость обучения высокой, то мы получим быстро переобучение, если слишком маленькой, то будем долго идти до некого оптимума.
from catboost import CatBoostClassifier model = CatBoostClassifier( iterations=200, learning_rate=0.15 ) Далее переходим к функции fit, которая запускает обучение нашей модели:
model.fit(X_train, y_train, cat_features=cat_features, eval_set=(X_test, y_test), verbose=False ) print(f"Model is fitted: {str(model.is_fitted())}") print(f"Model params: {model.get_params()}") Здесь мы выставили параметр Verbose равный False, чтобы в stdout не выводилась никакая информация во время обучения. После обучения вызовем метод is_fitted(), он показывает обучилась ли модели, второй параметр get_params(), он покажет нам с какими параметрами происходило обучение модели. Выполним данный блок кода:
Model is fitted: True Model params: {'iterations': 200, 'learning_rate': 0.15} Обучим модель вновь, но на этот раз будет показан прогресс нашего обучения, здесь параметр Verbose будет иметь значение равное 35, это значит, что каждые 35 итераций будет выводиться прогресс обучения нашей модели:
from catboost import CatBoostClassifier model = CatBoostClassifier( iterations=200, learning_rate=0.15 ) model.fit(X_train, y_train, cat_features=cat_features, eval_set=(X_test, y_test), verbose=35 ) 0: learn: 0.5308996 test: 0.5289152 best: 0.5289152 (0) total: 7.51ms remaining: 1.49s 35: learn: 0.1685548 test: 0.1553164 best: 0.1553164 (35) total: 425ms remaining: 1.93s 70: learn: 0.1593061 test: 0.1527978 best: 0.1527978 (70) total: 947ms remaining: 1.72s 105: learn: 0.1512245 test: 0.1519111 best: 0.1518266 (103) total: 1.46s remaining: 1.3s 140: learn: 0.1442951 test: 0.1518200 best: 0.1514874 (124) total: 1.95s remaining: 814ms 175: learn: 0.1381953 test: 0.1520130 best: 0.1514874 (124) total: 2.46s remaining: 336ms 199: learn: 0.1342670 test: 0.1519438 best: 0.1514874 (124) total: 2.79s remaining: 0us bestTest = 0.1514873617 bestIteration = 124 Shrink model to first 125 iterations. В выводе мы видим время обучения, лучшую итерацию и лучшее значение на тестовой выборке.
Catboost имеет параметр custom_loss, чтобы посмотреть обучение модели на других метриках. Передадим список метрик в этот параметр и эти самые метрики будут считаться на каждой итерации. Надо отметить, что по умолчанию в Catboost стоит метрика LogLoss и нельзя не обратить внимание на параметр Plot, который установлен с флагом True, это встроенный визуализатор, он показывает в Real-Time ход обучения модели. Запустим данную часть кода:
from catboost import CatBoostClassifier model = CatBoostClassifier( iterations=200, random_seed=63, learning_rate=0.15 custom_loss=['AUC', 'Accuracy'] ) model.fit(X_train, y_train, cat_features=cat_features, eval_set=(X_test, y_test), verbose=False, plot=True ) Визуализатор показывает ход обучения по трем метрикам:
- LogLoss
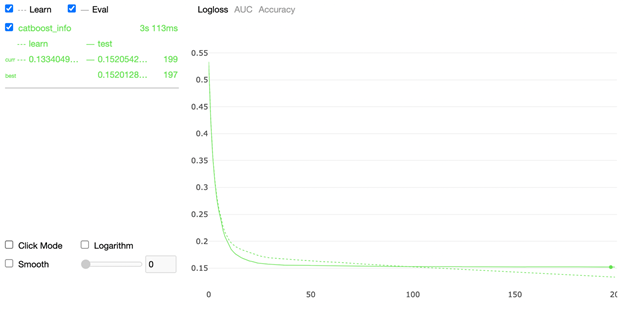
2. AUC
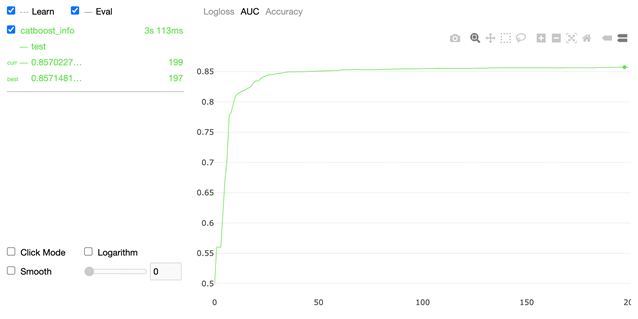
3. Accuracy
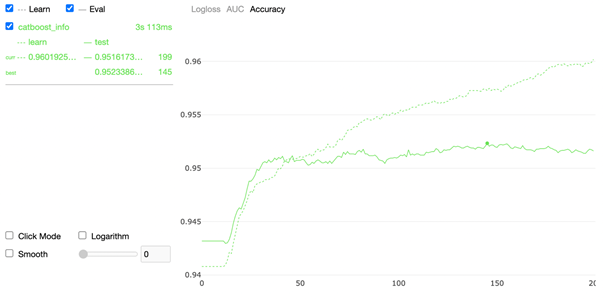
На графике рисуется точка, которая дает понять, в какой момент наша модель переобучилась, по сути, все то, что идет после этой точки нам не нужно, оно только ухудшает наши предсказания, все деревья, после итерации, на которой мы получили переобучение, просто отбрасываются.
Бывает так, что у нас есть модель с разными наборами параметров, в данном случае будет отличаться скорость обучения и мы хотим посмотреть, в какой момент мы получим переобучение модели, это так же можно визуализировать:
model1 = CatBoostClassifier( learning_rate=0.7, iterations=200, random_seed=63, train_dir='learning_rate_0.7' ) model2 = CatBoostClassifier( learning_rate=0.01, iterations=200, random_seed=63, train_dir='learning_rate_0.01' ) model1.fit( X_train, y_train, eval_set=(X_test, y_test), cat_features=cat_features, verbose=False ) model2.fit( X_train, y_train, eval_set=(X_test, y_test), cat_features=cat_features, verbose=False ) from catboost import MetricVisualizer MetricVisualizer(['learning_rate_0.01', 'learning_rate_0.7']).start() 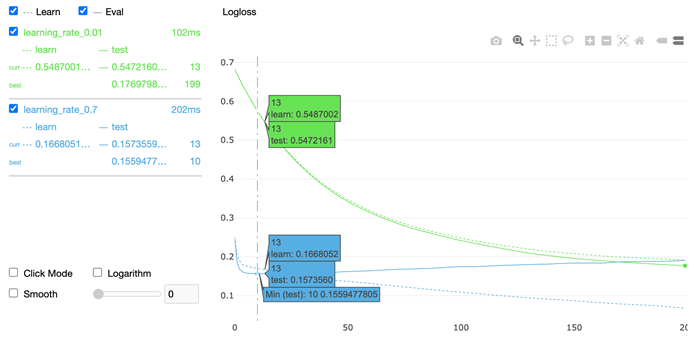
Сразу же видно, что модель с learning_rate в 0.7 моментально получила переобучение, а модель с learning_rate в 0.01 получила переобучение на последних итерациях, исходя из этого можно сказать, что последняя модель более качественная и будет нам давать наилучшие результаты при ее дальнейшем использовании.
Чтобы отбросить ненужные деревья, в ходе обучения модели, в Catboost присутствует параметр use_best_model, по умолчанию он включен и в итоге у нас останется дерево до того момента, когда качество начнет ухудшаться, давайте посмотрим, что это действительно так:
from catboost import CatBoostClassifier model = CatBoostClassifier( iterations=500, random_seed=0, learning_rate=0.15 ) model.fit( X_train, y_train, cat_features=cat_features, eval_set=(X_test, y_test), verbose=False, plot=True ) 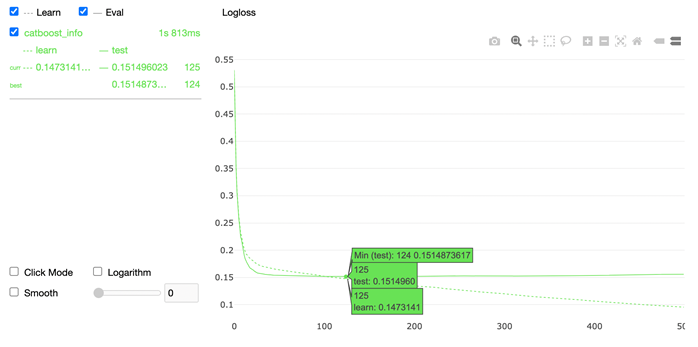
Как видим, после 125 итерации модель ловит переобучение. Чтобы посмотреть количество деревьев, которые содержаться в нашей модели, мы выполним такую строчку:
print(f"Tree count: {str(model.tree_count_)}") Tree count: 125 Да, у нас осталось дерево ровно до того момента, пока мы не получили переобучение нашей модели.
На этом закончим первую часть статьи про градиентный бустинг с использованием CatBoost. В следующей части поговорим про Cross Validation, Overfitting Detector, ROC-AUC, SnapShot и Predict.
До скорого!
Источник: newtechaudit.ru