Энтропия и сложность раскрывают ландшафт эволюции мемов
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-12-23 12:45

Абстрактный
В Интернете информация распространяется быстро и широко, а форма контента адаптируется в соответствии с когнитивными способностями пользователей. Мемы являются новым аспектом интернет-системы обозначения, и их визуальные схемы развиваются, приспосабливаясь к разнородному контексту. Фундаментальный вопрос заключается в том, представляют ли они культурные и временные трансцендентные характеристики в своих организационных принципах. В этой работе мы изучаем эволюцию 2 миллионов визуальных мемов, опубликованных на Reddit за десять лет, с 2011 по 2020 год, с точки зрения их статистической сложности и энтропии. Комбинация глубокой нейронной сети и алгоритма кластеризации используется для группировки мемов в соответствии с базовыми шаблонами. Группировка мемов является краеугольным камнем для отслеживания кривой роста этих объектов. Мы наблюдаем экспоненциальный рост числа новых созданных шаблонов со временем удвоения примерно в 6 месяцев и обнаруживаем, что долговечные шаблоны связаны с сильным ранним внедрением. Примечательно, что создание новых мемов сопровождается увеличением визуальной сложности содержания мемов в рамках постоянных усилий по представлению социальных тенденций и взглядов, что соответствует тенденции, наблюдаемой также в живописи.
Вступление
Социальные сети радикально изменили то, как мы потребляем информацию и взаимодействуем в онлайне1,2,3. Онлайн-взаимодействия, действительно, влияют на социальную динамику, способствуя формированию гомофильных групп вокруг общих повествований и взглядов и, таким образом, усиливая групповую поляризацию4,5,6. В этом случае мультимедийный контент, такой как видео, фотографии и картинки, представляет собой существенную часть онлайн-общения, особенно на платформах социальных сетей. Онлайн-общение можно рассматривать через призму культурных мемов Докинза7, определение которых применимо почти ко всем средствам передачи информации в Интернете. Культурные мемы представляют собой единицу культурной информации, передаваемой и тиражируемой; написание постов, обмен личными видео, выражение “нравится” являются примерами этой концепции. Хотя модель культурной эволюции Докинза в настоящее время считается недостаточной для понимания сложных культурных явлений передачи информации8,9, 10, 11, ее эволюционная модель по-прежнему представляет собой надежную основу для описания фундаментальных особенностей распространения мемов. В этой работе мы исследуем роль и эволюцию определенного вида культурных мемов, а именно шаблонных изображений, которые претерпевают изменения или перекрываются некоторым текстом, условно называемых просто мемами. В дальнейшем мы принимаем эту конвенцию. Согласно гипотезе Докинза, культурные мемы12 характеризуются тремя основными элементами эволюционной теории: репликацией, изменчивостью и отбором. В случае визуальных мемов механизм репликации очевиден. Он состоит в изменении изображения, например, с помощью некоторого текста, для представления данной ситуации. Кроме того, тиражированию мемов способствует их согласованность с другими культурными мемами, присутствующими в онлайн-среде, такими как короткие видео, картинки или короткие тексты. Вариативность - неотъемлемая особенность визуальных мемов. Действительно, постоянно создаются новые мемы, нацеленные на забавные ситуации или шутки о политических или общественных событиях и конкурирующие за внимание пользователей, проходящих через онлайн-сообщества. Наконец, отбор происходит, когда мем не может привлечь внимание человека или адаптироваться для передачи нового контента и исчезает, адаптируясь к быстрой онлайн-среде. Среди онлайн-культурных мемов, которые подверглись относительно сильному отбору, мы находим, например, блоги и дискуссионные форумы, которые были заменены в основном онлайн-социальными сетями; аналогичным образом, введение эмодзи сильно сократило использование символов ascii.
До сих пор в большом объеме исследований количественно изучались особенности различных онлайн-культурных мемов, не ограничиваясь изображениями. Текстовые мемы были проанализированы Лесковцом и др.13 как показатель цикла потребления онлайн-новостей. Иенко и др.14 изучали проблему ранжирования мемов, т.е. выбора тех мемов, которые будут отображаться пользователям, чтобы максимизировать сетевую активность на платформе. Ромеро и др.15 изучали распространение онлайн-мемов в виде хэштегов в Твиттере. Bauckhage16 исследовал эпидемическую динамику 150 известных мемов, применяя модели математической эпидемиологии для учета роста и снижения визуальных мемов. Раткевич и его коллегаи17 разработали систему анализа распространения твитов, связанных с политикой. Венг и др.18 изучали вирусность мемов с помощью агентного подхода, учитывая ограниченное внимание, которое каждый пользователь может уделять в онлайн-среде. Механизмы конкуренции и сотрудничества между мемами, которые определяют успешный переход мема от поколения к поколению, были исследованы Coscia19 вместе с правилами, лежащими в основе популярности мемов20,21. Эти исследования показывают, что динамика вирусности мемов (как визуальной, так и текстовой) не линейно зависит от приверженности шаблону новых экземпляров мемов. Популярность мемов исследуется также с помощью базовой структуры сетевого сообщества22. Феррара и др.23 использовали методы кластеризации для идентификации текстовых мемов, используя контент, метаданные и сетевую структуру социальных данных. Данг и др.24 использовали триграммы для группировки сообщений из Reddit и отслеживания распространения мемов. Лингвистические особенности25 также были исследованы в качестве предикторов популярности текстовых мемов. Адамик и др.26 исследовали большой массив текстовых данных из Facebook, моделируя распространение информации как святочный процесс. Научные мемы27 в форме слов были исследованы с изучением закономерностей наследования в научной литературе. Дубей и др.28 использовали архитектуру глубокого обучения для обработки мемов, извлечения базового шаблона и изучения его вариаций. Заннетту и его коллегии29 проводят обширный анализ визуальных мемов, используя хеширование восприятия для объединения визуальных мемов в группы и изучения связей между содержанием мемов и сообществами, в которых они распространяются. В30 предлагается классификатор мемов с глубоким обучением для изучения роли мемов вместо изображений, не являющихся мемами, во время выборов. В ходе этих исследований были разработаны соответствующие идеи и инструменты для обработки и исследования мира интернет-мемов. Тем не менее, фундаментальным аспектам эволюции мемов с точки зрения визуальных особенностей и передаваемой информации уделяется мало внимания. В конечном счете, не сообщается никаких доказательств гипотезы об интернет-мемах, составляющих метаязык интернета10,11.
В этой работе мы исследуем общую закономерность эволюции мемов как артефакта онлайн-коммуникации. С этой целью мы используем эволюционистский подход для определения и измерения скорости эволюции, т.е. количества новых шаблонов, появляющихся онлайн в единицу времени, скорости изменения, т.е. количества новых экземпляров одного и того же шаблона, которые создаются во времени; это количество особенно важно в отношении популярности мемов. Поскольку художественные выражения были эффективно исследованы с использованием концепций сетевой науки и физики31, мы вычисляем траекторию мемов в плоскости энтропийной сложности. В частности, эти меры, основанные на физике сложных систем, были использованы для исследования искусства живописи32, выявляя временную закономерность в направлении более высокой сложности.
В основе этого расследования лежит массивный набор данных из 2 миллионов мемов Reddit за десять лет. Каждое изображение было классифицировано и отнесено к шаблону с помощью конвейера машинного обучения, составленного неконтролируемым классификатором на основе глубокого обучения, за которым следует алгоритм кластеризации на основе плотности (см. Методы). Наше исследование показывает, что размер экосистемы мемов экспоненциально увеличивается, причем время удвоения составляет примерно шесть месяцев, что указывает на то, что репликация в настоящее время является ведущим процессом. Что касается отбора, мы наблюдаем, что в стойкости мемов преобладает быстрое раннее принятие. Схема изменения отражается траекторией в плоскости энтропия–сложность. Подобно тому, что происходит в живописи, мы наблюдаем тенденцию к структурам с возрастающей визуальной сложностью; ранние мемы состояли из простых изображений переднего плана (например, животных или явных человеческих выражений) на простом фоне, в то время как более поздние включают более четко сформулированные сцены (например, модифицированные кадры фильма).).
Как культурные знаки, мемы строго связаны с более широкой культурной системой, в которую они встроены. Хотя их окончательное теоретическое определение все еще неуловимо и обсуждается с точки зрения методологических рамок, наши результаты показывают, что мемы предстают как одна из наиболее продуктивных и адаптируемых областей цифровой коммуникации, функционирующая как метаязык культурной динамики и развивающаяся в прогрессивных формах текстовой сложности.
Результаты
Наше исследование начинается с гипотезы Докинза о меме как основной единице культурной эволюции в связи с постмеметическим анализом мемов как культурных знаков. Мы изучали эволюцию визуальных интернет-мемов, то есть изображений с (обычно) перекрывающимися текстовыми строками, в течение 10 лет. Набор данных содержит около 2 миллионов изображений, которые были сгруппированы вместе с использованием неконтролируемой процедуры машинного обучения (см. Методы). Такой расширенный набор данных позволяет нам исследовать некоторые свойства этого конкретного культурного мема. Кластеры, полученные с помощью нашей процедуры, соответствуют шаблонам различных мемов. В дальнейшем мы будем ссылаться на “мем” как на шаблон, в то время как каждое изображение, принадлежащее данному шаблону, является “экземпляром” мема.
Чтобы количественно оценить рост распространения мемов, мы вычислили скорость их эволюции. Для каждого кластера мы храним время создания его первого экземпляра. Затем, за каждую неделю выборки, мы вычисляем количество новых шаблонов. Результат представлен на рис. 1, на котором скорость роста оценивается с помощью экспоненциальной подгонки, что дает время удвоения количества шаблонов T~6 месяцев
. Внезапное падение графика - это эффект конечного размера набора данных. А именно, для субредитов r/memes и r/dankmemes не удалось загрузить данные за 2019 год из-за экспоненциальной тенденции количества мемов (см. рис. 4). Подгонка была проведена с учетом данных до января 2019 года.

Скорость эволюции интернет-мемов. Количество новых шаблонов за каждый месяц указывается в зависимости от времени. Скорость роста оценивается с помощью экспоненциальной подгонки со временем удвоения T~6
Другой важной величиной с точки зрения культурной эволюции является частота мутаций. Частоту мутаций можно приблизительно оценить, посмотрев на экземпляры каждого мема. Для каждого шаблона мы вычислили распределение различий (?t
) между временем создания экземпляра и следующим. Это распределение раскрывает характер роста каждого кластера: распределение, смещенное в сторону низких значений ?t, соответствует очень быстрой и стремительной динамике роста. И наоборот, большие значения ?t
может выявить более устойчивый шаблон, экземпляры которого происходят с большим интервалом во времени. На рис. 2 показано распределение времени “между экземплярами” (синие гистограммы, левый столбец) вместе с распределением продолжительности жизни кластеров (оранжевые гистограммы, правый столбец), т.е. временной интервал между первым и последним экземпляром данного мема. Эти распределения вычисляются для различных типичных размеров кластеров (обозначаются как CS).
Figure 2
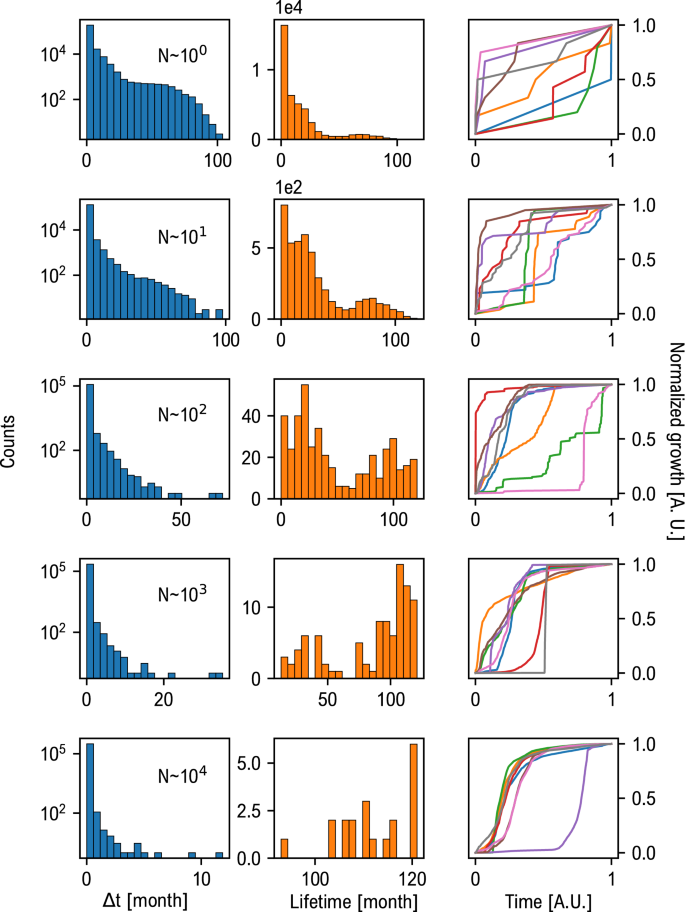
Частота мутаций мемов. Левая колонка: распределение времени между поступлениями инстансов (?t
); центральная колонка: пожизненное распространение мемов; правая колонка: примерная кривая роста распространения мемов. Каждая строка соответствует типичному размеру кластера мемов. Интересно, что чем больше размер кластера, тем дольше срок его службы. Тем не менее, шаблон долговременных мемов показывает искаженные распределения для времени между прибытиями (?t
). Это подчеркивает тенденцию к сильному раннему внедрению долговременных мемов.
В целом, результаты жизненного цикла положительно коррелировали с размером кластера. Небольшие кластеры показывают неоднородное распределение времени между поступлениями экземпляров, включающее как кластеры с небольшими всплесками, так и кластеры с небольшими медленными темпами. Срок службы достигает пика в сторону низких значений. Такое поведение также демонстрируют совсем недавние кластеры, фактический размер которых не может быть оценен в нашем наборе данных, поскольку их эволюция продолжается. По мере увеличения размера кластера мы наблюдаем сдвиг распределения между временами в сторону низких значений, демонстрируя более быструю динамику, в то время как распределение времени жизни сосредоточено вокруг больших значений. Просматривая соответствующие кривые роста, мы наблюдаем совокупность траекторий, которые, как правило, демонстрируют быстрое начальное наращивание популярности, за которым следует более медленное распространение, определяющее более длительные значения продолжительности жизни. И наоборот, есть также примеры мемов, которым требуется больше времени для достижения широкой популярности. Этот аспект может быть связан с нетривиальной динамикой популярности, требующей дальнейших исследований.
Следуя Сигаки и др.32, мы исследовали эволюцию мемов в плоскости энтропийной сложности. Для каждого экземпляра мема мы вычислили значения H(P) и C(P), а затем усреднили полученные значения по годам. Результаты представлены для каждого субреддита на рис. 3. Мы наблюдаем, что каждое сообщество движется к более высоким значениям сложности, за исключением r/AdviceAnimals, чьи правила публикации ограничивают естественную эволюцию создаваемых мемов; этот эффект также может быть связан с общим снижением производства мемов, наблюдаемым для этого сообщества. Интересно, что картины также следовали аналогичной траектории в плоскости энтропия-сложность: довольно локализованы вдоль оси энтропии, но со временем смещаются в сторону более высокой сложности.
Figure 3
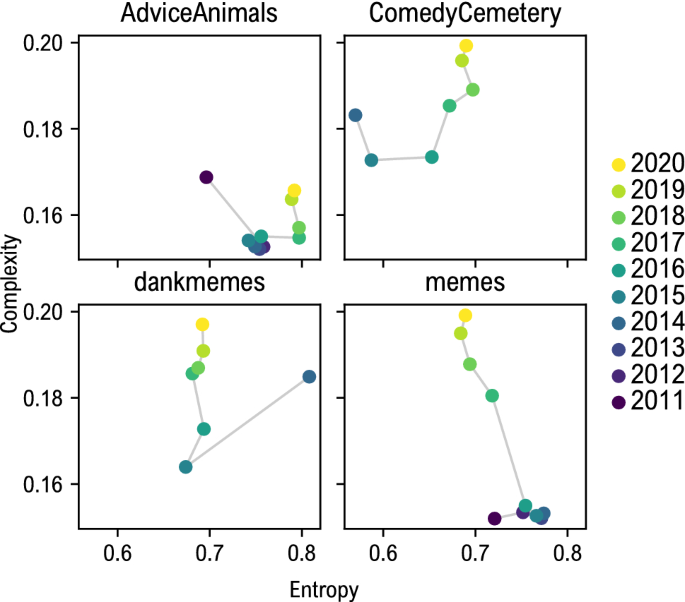
Траектории в плоскости энтропии-сложности для четырех сообществ Reddit. Все, кроме r/AdviceAnimals, демонстрируют эволюцию к более высоким значениям сложности, которая напоминает искусство живописи 32. Каждая точка представляет собой среднее значение энтропии и сложности за каждый год. Визуально сложные шаблоны могут быть связаны с тенденцией использования мемов для постоянного представления социальных тенденций и взглядов, что подтверждает гипотезу о том, что мемы являются частью формирующегося метаязыка Интернета.
Изображение в натуральную величину
Тенденцию мемов эволюционировать в сторону более сложных структур можно объяснить, рассматривая этот объект как часть формирующегося интернет-метаязыка. Фактически, мемы используются для быстрого создания контекстно-ориентированного контента, который, в свою очередь, развивается в направлении все более и более специфических шаблонов. Это может привести к эффекту сегрегации с определенным диалектом в зависимости от сообщества, в котором распространен мем. На самом деле мем, созданный для определенного сообщества, например игрового сообщества, не обязательно должен быть общедоступным в Интернете. Этот аспект приводит к использованию более сложных и специфических шаблонов.
Обсуждение
Интернет обеспечивает среду, в которой информация быстро распространяется и адаптируется в соответствии с когнитивными способностями пользователей. Основополагающий вопрос о мемах заключается в том, представляют ли они культурно и временно трансцендентные характеристики в своих организационных принципах и как они развиваются. Такое значительное увеличение и распространение визуальных мемов можно прочесть в свете теорий постмеметики. Визуальным мемам благоприятствует быстрая, изменчивая, постоянно меняющаяся интернет-среда из-за их простоты, удобства в обращении и широкой применимости с точки зрения предметов и ситуаций. Мы находим подтверждение гипотезе о том, что мемы являются частью формирующейся формы интернет-метаязыка: с одной стороны, мы наблюдаем экспоненциальный рост со временем удвоения около 6 месяцев; с другой стороны, сложность содержания мемов возрастает, позволяя своевременно представлять социальные тенденции и отношения. Наш анализ показывает, что мемы являются реляционными сущностями, функционирующими как гибкие элементы метаязыка, который декодирует и перекодирует культурную систему. Они предстают как фундаментальные компоненты органического процесса, который влияет и обуславливает цифровую среду и создает развивающиеся формы визуальной и текстовой сложности.
Методы
Разбивка данных
Reddit - это онлайн-платформа социальных сетей, которая объединяет пользователей в сообществах по интересам. В последние годы он широко используется для проведения академических исследований онлайн-сообществ, и число активных пользователей на этой платформе постоянно увеличивается33.
Визуальные мемы, использованные в качестве набора данных для этого исследования, были загружены через набор данных Pushshift Reddit34, в котором были выбраны четыре сообщества (субреддиты), явно предназначенные для обмена и обсуждения мемов, а именно: r/AdviceAnimals, r/memes, r/CemeteryComedy и r/dankmemes. Данные были собраны с учетом десятилетнего периода, с 2011 по 2020 год. На рис. 4 указывается количество загруженных сообщений в каждом сообществе в зависимости от времени. Не все сообщества начали свою деятельность одновременно. Список всех URL-адресов изображений, использованных в этом исследовании, доступен в онлайне35.
Figure 4
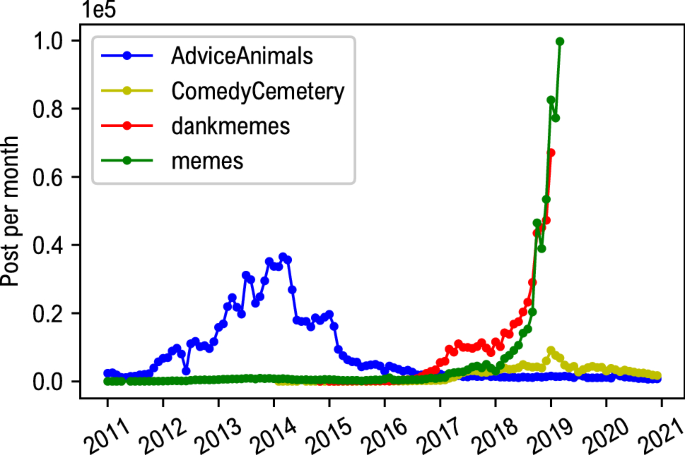
Набор данных, используемый в этой работе. Каждая кривая показывает количество сообщений в месяц, загруженных с Reddit. Каждый пост соответствует изображению. Общее количество загруженных мемов составляет около 2 миллионов.
Изображение в натуральную величину
Кластеризация
Одной из главных особенностей визуальных мемов является их повторяющийся характер: начиная с исходного шаблона, мемы создаются путем модификации текста или изображения, в результате чего каждый раз создается новый экземпляр, основанный на исходном шаблоне. Чтобы измерить эволюцию и скорость изменения визуальных мемов, крайне важно сгруппировать их в соответствии с базовым шаблоном. Поскольку количество собранных мемов составляет около двух миллионов, такое большое количество изображений требует применения методов автоматической классификации.
Наша процедура неконтролируемой кластеризации состоит из двух этапов: во-первых, мы применяем, насколько нам известно, современную реализацию глубокого обучения для неконтролируемой кластеризации изображений, которая называется SCAN36 (Семантическая кластеризация с использованием ближайших соседей), за которой следует дальнейшая процедура кластеризации с помощью HDBSCAN (Иерархическая пространственная кластеризация приложений с шумом на основе плотности) алгоритм 37.
В частности, алгоритм сканирования работает в два этапа. В первом случае самообучение используется для обучения нейронной сети с параметрами?
который отображает изображения (xi,i=1...N) в представления объектов??(xi)?Rd. Следовательно, каждое изображение представлено вектором размерности d, где d является размерностью пространства вложения, несущего семантически значимую информацию о его содержимом. Параметры? определяются путем минимизации функции потерь, заданной расстоянием?
между представлением изображения и представлением их дополнений:
min??(??(xi),??(T[xi])).
мин??(??(xi),??(Т[xi])).
Увеличение изображения может быть поворотом, аффинным или перспективным преобразованием и т.д.
На втором этапе создается нейронная сеть с параметрами?
используется для классификации изображения xi и его ближайших соседей, отобранных с использованием соответствующего представления??(xi). Поскольку вторая задача представляет собой классификацию, результатом является распределение вероятностей по рассматриваемым классам для данного изображения: ??(x)?[0,1]C
, где C - количество рассматриваемых кластеров.
Функция потерь, в данном случае, состоит из двух членов
=-1|D|?x?D?k?Nx???(x),??(k)?+??x?C??c?лог(??c?), с??c?=-1|D|?x?D?c?(x),
где D
набор данных содержит все изображения, Nx - набор ближайших соседей изображения x, C - набор кластеров и??? является точечным продуктом. Первый термин направлен на то, чтобы максимизировать вероятность того, что изображение и его ближайшие соседи отнесены к одному и тому же классу. Второй член позволяет избежать формирования единого кластера, содержащего все изображения, и обеспечивает равномерное распределение предсказаний по кластерам. В конечном итоге для каждого обработанного изображения мы получаем вектор представления размером d=2048
и набор, к которому он принадлежит.
Алгоритм сканирования предоставляет нам информативное и компактное представление каждого изображения в нашем наборе данных вместе с первой высокоуровневой кластеризацией. СКАНИРОВАНИЕ делит корпус на четыре группы, которые группируют визуальные мемы в три широкие и общие категории: животные (два набора), люди и другие. Два кластера с изображениями животных были объединены вместе. Другими словами, мемы, содержащие людей, составляют 50% корпуса, за которыми следуют 25% животных и 25% другого контента.
Чтобы получить кластеризацию на основе шаблонов, мы использовали HDBSCAN37,38. Для каждого кластера высокого уровня, полученного в результате СКАНИРОВАНИЯ, весь набор мемов может быть представлен матрицей, строки которой являются представлениями??(xi)
. Чтобы сделать задачу более понятной в вычислительном отношении, был использован анализ главных компонентов для уменьшения размерности объектов с 2048 до 20. Это позволило нам лучше использовать наши вычислительные ресурсы и не привело к снижению качества кластеризации. Применив HDBSCAN к такой матрице, мы смогли получить метку для каждого изображения нашего корпуса и разделить мемы по их шаблону. Примечательно, что HDBSCAN может отделять кластеры от зашумленных точек. Часть корпуса не принадлежит ни одному шаблону и поэтому помечена как шум и сгруппирована в большой “кластер шума”. Несмотря на это подходящее свойство алгоритма, некоторые кластеры могут быть составлены из изображений, шаблон которых не одинаков для всех. Поэтому требуется измерение чистоты, чтобы исключить из анализа слишком разнородные кластеры, т.е. кластеры ниже заданного порога чистоты.
В полностью неконтролируемой среде качество кластеризации, как правило, оценить нелегко39. Величина, которая обычно используется в качестве целевой функции для кластеризации, представляет собой среднее попарное расстояние S???k
, который оценивает внутрикластерную однородность40, т.е. насколько каждый элемент кластера в среднем похож на все остальные. Его определение дается
S???k=1N2k?xi,xj?CkNk||??(xi)-??(xj)||2.
В нашем случае мы использовали последнее значение для измерения чистоты кластеров, идентифицированных HDBSCAN, вместе с размером кластера. На рис. 5(а) для каждого кластера указано S???k
и размер кластера. Красные точки - это кластеры, которые не рассматриваются для последующего анализа. Четыре из них соответствуют “шумным кластерам”, полученным с помощью HDBSCAN. Все они приводят к отклонениям в отношении размера соединения и S???k
распределение, распределение маргинальных значений которого представлено в панелях (b) и (c) соответственно. Производительность HDBSCAN зависит от нескольких параметров. Мы использовали в основном значения по умолчанию, установив значения min_cluster_size и min_samples равными 20 и 3 соответственно.
Figure 5

Панель (а): совместное распределение среднего попарного расстояния S???
и размер кластера. Каждая точка соответствует кластеру, то есть шаблону для мемов. Красные точки представляют “шумные кластеры”, идентифицированные HDBSCAN, которые являются выбросами по отношению к размеру кластера и S???k
распределения, показанные соответственно на панелях (b) и (c). Шумные кластеры удаляются из анализа.
Изображение в натуральную величину
Энтропия и сложность
Энтропия перестановки H и статистическая сложность C - это две величины, которые можно использовать для синтеза общих свойств изображений на основе значения и относительного расположения их пикселей. Далее мы даем минимальное описание обеих величин и отсылаем читателя к оригинальным статьям для получения более формальных подробностей41, 42, 43,44,45. Перестановочная энтропия измеряет степень беспорядка в расположении пикселей. Высокие значения указывают на высокую случайность пикселей, в то время как низкие значения соответствуют более регулярным шаблонам. Статистическая сложность вместо этого измеряет величину “структурной” сложности. Нетривиальные пространственные паттерны приводят к положительным значениям, в то время как чрезвычайно упорядоченные или неупорядоченные паттерны соответствуют низким значениям.
Для вычисления H и C все цветные изображения были преобразованы в оттенки серого. Таким образом, каждое изображение состоит из двумерной матрицы. Далее, для всех 2х2
подматрицы, содержащиеся в изображении, вычисляют относительный порядок пикселей 32. Для набора из четырех элементов число 4!=24
возможные перестановки могут быть получены. Подсчитывая относительное вхождение каждой перестановки, функция массы вероятности
Р={p1...pN }с?i=1Npi=1,
может быть построен. Энтропия Шеннона затем вычисляется по этому распределению вероятностей для получения энтропии перестановки
H(P)=S(P) журнал(N)=1log(N)?i=1Npilog(1pi).
(1)
Учитывая функцию массы вероятности P, ее несоответствие относительно равномерного распределения U
U={u1...UN}с?i=1Nui=1,
получается путем вычисления дивергенции Дженсена-Шеннона
D(P,U)=S(P+U2)-S(P)2-S(U)2.
Объединяя эту величину с H(P), статистическую сложность можно вычислить как
C(P)=D(P,U)H(P)Д*,
(2)
с нормализующим коэффициентом
D*=mAxpd(P,U)=-12[N+1Nlog(N+1)+журнал(N)-2log(2N)].
Эволюцию визуальных паттернов можно изучать как траекторию в описанной выше плоскости энтропийной сложности42,43, следуя тому же подходу, который использовался для живописей32.
Доступность данных
Список всех изображений, использованных в этом исследовании, доступен в онлайне35. Все программное обеспечение, используемое для вычислений, должным образом указано в основном тексте.
Источник: www.nature.com