Окрашивание изображений
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-11-20 13:43
Привет, Хабр. Сегодня мы будем раскрашивать.

8 лет назад НЛО выдало мне инвайт за статью про окрашивание изображений. Сегодня мы вернемся к этой теме и посмотрим на одну из свежих работ в этой области: Color2Embed: Fast Exemplar-Based Image Colorization using Color Embeddings. Здесь будет мой вольный пересказ с реализацией и комментариями, ну и много картинок.
TL;DR:
В статье я расскажу как переносить цвет с одной картинки на другую с помощью смеси из U-Net и StyleGAN v2. Если эти слова вам ни о чем не говорят — пролистайте вниз, там красивые картинки. Мой код здесь, код авторов тут, еще я сделал Google Colab тетрадку, можно попробовать свои картинки.
Инструкция по запуску Google Colab
Google Colab - Это такой способ от Гугла запускать Jupyter Notebook в браузере на их мощностях с доступом к GPU и TPU и делиться ими.
-
Открыть ссылку;
-
Нажать справа сверху Подключиться (Connect) если нужно, если нет там будет информация об ОЗУ и диске;
-
Нажать в меню сверху Среда выполнения -> выполнить все (Runtime -> run all);
-
Прокрутить вниз до куска с кодом:
target_image_uploaded = files.upload() ref_image_uploaded = files.upload() target_image_path = list(target_image_uploaded.keys())[0] ref_image_path = list(ref_image_uploaded.keys())[0] predict_colors(target_image_path, ref_image_path, model)Подождать, пока выполнится до него (клонирование репозитория, загрузка весов и т.д., займет минуту-две) и появится кнопка:

Кнопка выбора картинки -
Выбираем сперва картинку (по одной за раз, там две кнопки на каждую картинку, вторая появится после выбора первой), которую хотим покрасить, потом картинку, с которой хотим взять цвета;
-
Работает меньше секунды (~300 мс) после загрузки картинок. Пример, как это выглядит:

Обучение, вид сверху
Процесс обучения, картинка из оригинальной статьи:
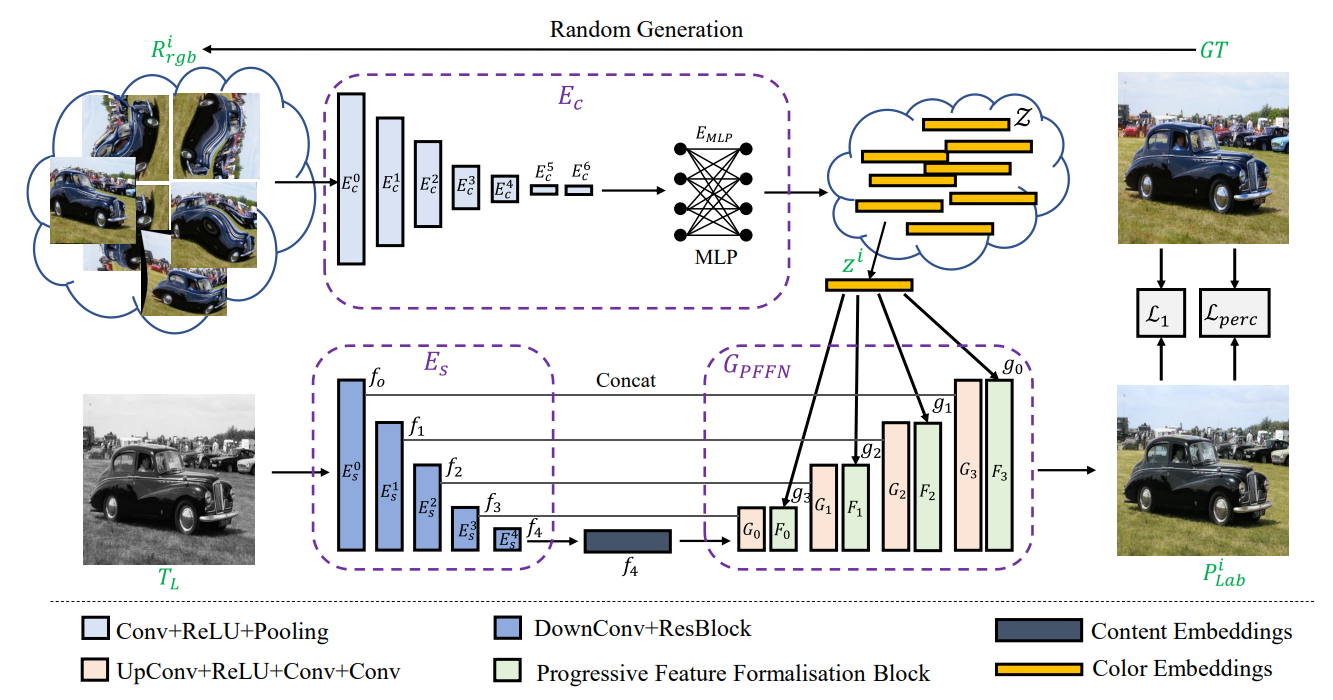
Для обучения за раз нужна только одна цветная картинка,  (ground truth). Из нее делается два входа: с помощью аугментаций (об этом ниже) получаем измененную трехканальную RGB картинку, на схеме это
(ground truth). Из нее делается два входа: с помощью аугментаций (об этом ниже) получаем измененную трехканальную RGB картинку, на схеме это  ; вторую получаем с помощью преобразования
; вторую получаем с помощью преобразования  в пространство Lab — берем только один канал L (lightness), на схеме это
в пространство Lab — берем только один канал L (lightness), на схеме это  . Каналы
. Каналы  и
и  тоже сохраняем, они пригодятся для функции потерь в дальнейшем, обозначаются они
тоже сохраняем, они пригодятся для функции потерь в дальнейшем, обозначаются они .
.
Выходом являются два предсказанных цветных канала для заданной  — каналы
— каналы  и
и  , обозначаются они
, обозначаются они  , или, когда соединяем с
, или, когда соединяем с  , —
, —  .
.
Подавать одну картинку на вход очень удобно, так мы можем брать базу без разметки, не нужны ни классы, ни какие-то другие дополнительные характеристики.
Система состоит из трех частей: Кодировщика цвета (Color encoder,  ), кодировщика контента (Content encoder,
), кодировщика контента (Content encoder,  ) и непереводимой PFFN (progressive feature formalisation network). Кодировщик цвета сжимает цветную картинку до вектора с информацией о цвете, Кодировщик контента сжимает одноканальную картинку до вектора "смысла", а PFFN на основе всего этого генерирует цветовые каналы.
) и непереводимой PFFN (progressive feature formalisation network). Кодировщик цвета сжимает цветную картинку до вектора с информацией о цвете, Кодировщик контента сжимает одноканальную картинку до вектора "смысла", а PFFN на основе всего этого генерирует цветовые каналы.
Функций потерь две:
-
 — reconstruction loss, он же SmoothL1Loss, сравнивает
— reconstruction loss, он же SmoothL1Loss, сравнивает  и
и  .
. -
 — perceptual loss, тот же L1Loss, но на выходах VGG сети. На вход получает исходную картинку в RGB
— perceptual loss, тот же L1Loss, но на выходах VGG сети. На вход получает исходную картинку в RGB  и предсказанную картинку в RGB
и предсказанную картинку в RGB  , полученную из
, полученную из  .
.
Общий лосс является взвешенной суммой: 
Для себя во время реализации я нарисовал такую схему — может, кому-то она будет понятней:

Аугментации цветного изображения
Авторы выдвигают логичный тезис: если просто подавать цветную картинку как есть и пытаться ее же раскрасить, то у сетки появится соблазн переобучиться, так как появится однозначное соответствие пикселей. Поэтому они предлагают сделать ряд аугментаций, от простых (повороты и шум), до интересной: давайте применим к картинке thin plate spline (TSP), что позволяет достаточно забавно искажать её:

В моем блокноте можно посмотреть пример вызова из кода (секция TSP Example), сам код в tsp.py
Кодировщик цвета
Кодировщик цвета  является самой простой частью системы — это обычная сеть для классификации. Авторы изобрели что-то простое свое, я не увидел смысла в этом костылестроении и взял классический быстрый и маленький resnet18.
является самой простой частью системы — это обычная сеть для классификации. Авторы изобрели что-то простое свое, я не увидел смысла в этом костылестроении и взял классический быстрый и маленький resnet18.
Выходом является вектор, содержащий информацию о цвете, обозначен  . Это очень похоже на вектор стиля в StyleGAN. Размерность его авторы предлагают взять 512, тут я с ними спорить не стал.
. Это очень похоже на вектор стиля в StyleGAN. Размерность его авторы предлагают взять 512, тут я с ними спорить не стал.
Кодировщик контента+ PFFN
Кодировщик контента и PFFN вместе представляют собой похожую на U-Net сеть с одним большим отличием: в части «развертки», кроме информации с предыдущих этапов, нам добавляется информация о цвете с кодировщика цвета. Авторы называют это PFFN, идея взята из StyleGANv2, и сердцем ее является нечто под название Modulated Convolution. Modulated Convolution — это такая свертка, с весами которой мы немного поиграем.Остановимся на этом подробнее, схема из статьи:

Код на PyTorch
class ModulatedConv2d(nn.Module): def __init__( self, in_channel, out_channel, kernel_size, style_dim ): # Part from https://github.com/rosinality/stylegan2-pytorch/blob/a2f38914bb5049894c37f2d7a9854bc130cf8a27/model.py super().__init__() self.eps = 1e-8 self.kernel_size = kernel_size self.in_channel = in_channel self.out_channel = out_channel fan_in = in_channel * kernel_size ** 2 self.scale = 1 / math.sqrt(fan_in) self.padding = kernel_size // 2 self.weight = nn.Parameter( torch.randn(1, out_channel, in_channel, kernel_size, kernel_size) ) self.weight_linear = nn.Parameter(torch.randn(in_channel, style_dim)) self.bias_linear = nn.Parameter(torch.zeros(in_channel).fill_(1)) def __repr__(self): return ( f"{self.__class__.__name__}({self.in_channel}, {self.out_channel}, {self.kernel_size})" ) def forward(self, input_, style): batch, in_channel, height, width = input_.shape # Linear style = F.linear(style, self.weight_linear * self.scale, bias=self.bias_linear) # Dot weight = self.scale * self.weight * style.view(batch, 1, in_channel, 1, 1) # Norm Fnorm = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + 1e-8) weight = weight * Fnorm.view(batch, self.out_channel, 1, 1, 1) # Convolve weight = weight.view(batch * self.out_channel, in_channel, self.kernel_size, self.kernel_size) input_ = input_.view(1, batch * in_channel, height, width) out = F.conv2d(input_, weight, padding=self.padding, groups=batch) _, _, height, width = out.shape out = out.view(batch, self.out_channel, height, width) return out Входа у нас два: вектор цвета  и выход предыдущего слоя-свертки
и выход предыдущего слоя-свертки  . Кроме того у нас есть набор весов: веса свертки и веса линейного слоя. Линейный слой нам нужен, чтобы изменить размерность вектора
. Кроме того у нас есть набор весов: веса свертки и веса линейного слоя. Линейный слой нам нужен, чтобы изменить размерность вектора  ,так как количество каналов в свертке зависит от того, на каком мы этапе (чем ближе к выходу, тем меньше каналов). То есть, после него будет вектор цвета, но уже размерностью не 512, а
,так как количество каналов в свертке зависит от того, на каком мы этапе (чем ближе к выходу, тем меньше каналов). То есть, после него будет вектор цвета, но уже размерностью не 512, а  .
.
Второе наше действие ключевое: мы умножаем веса свертки  на полученный вектор цвета (dot product), получаем
на полученный вектор цвета (dot product), получаем  . Кроме того, после умножения мы нормируем полученные веса, получаем
. Кроме того, после умножения мы нормируем полученные веса, получаем  .
.
Нам осталось только одно действие — непосредственно свертка, полученные фичи  идут в следующий этап.
идут в следующий этап.
Подробный разбор этого приема описан в статье, там он был придуман для удаления артефактов при генерации изображений.
Modulated Convolution вставляется после каждого блока "развертки" U-Net, и только этим PFFN отличается от классического варианта.
Предсказание
На этапе обучения для получения цвета мы берем ту же картинку, что и хотим окрасить. Очевидно, на предсказании так сделать не получится. Но наши аугментации оказали нам услугу: если взять похожую цветную картинку, то все хорошо работает, при этом совсем не обязательно брать полутоновое изображение для окраски (хотя информация о цвете не будет никак учитываться).
Посмотрим, как воспроизвелись результаты из оригинальной статьи:

К чести авторов, моя реализация воспроизводит результаты из статьи практически один в один. Правда, есть ложка дёгтя: в статье приведены хорошие примеры, а если взять примеры из другой статьи, которую авторы улучшают и с которой сравниваются, то проблемы становятся видны:

Также можно перекрасить одну картинку разными:

Когда я пробовал другие картинки, заметил, что найти удачные примеры сильно сложнее, чем неудачные. Многие картинки остаются бесцветными, или скатываются в сепию, например, как этот кот:

Бонус: картинка, которую я красил 8 лет назад все еще красится хорошо:

Напомню, что в colab можно попробовать свои картинки.
Критика
-
Результаты, показанные в статье, можно воспроизвести — это очень здорово и не часто встречается в наше время.
-
Использование той же самой картинки в обучении — это очень удобно, но, я думаю, это является причиной узкого диапазона работ: картинки должны быть очень похожи для хорошего результата. Предыдущая идея — брать картинку из того же класса — кажется более робастной.
-
Скорость является киллер-фичей работы, она в разы выше, чем у конкурентов, составляющие части маленькие и быстрые.
-
Мы используем только одну картинку, с которой будем брать цвет. Идея со статьи предшественника — использовать несколько картинок-источников цвета — кажется, может достаточно легко улучшить качество, технических трудностей для реализации немного.
Полезные ссылки:
-
Сама статья: https://arxiv.org/abs/2106.08017
-
Статья-ориентир: https://arxiv.org/abs/1807.06587
-
StyleGANv2 (Modulated Convolutional): https://arxiv.org/abs/1912.04958
-
Код авторов (PyTorch): https://github.com/zhaohengyuan1/Color2Embed
-
Код мой (PyTorch): https://github.com/Kwentar/Color2Embed_pytorch
-
Colab: https://colab.research.google.com/drive/1Xyq-kuTWzvoQH4r7d5C7YN7sVe19pUv0#scrollTo=6Nm25AlJzmyn
Источник: habr.com