? Наивный байесовский алгоритм классификации: преимущества и недостатки
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-11-13 10:20

Что это такое?
Наивный Байес – это самый простой алгоритм, который вы можете применить к своим данным. Как следует из названия, этот алгоритм делает предположение, что все переменные в наборе данных "наивные", т.е. не коррелируют друг с другом.
Предположим, что вы видите перед собой что-то зеленое. Этот зеленый объект может быть ежиком, собакой или мячом. Естественно, вы предположите, что это будет мяч. Но почему?
Вы создаете алгоритм и вашей целью является проблема выше: классифицировать объект между мячом, ежиком и собакой. Сначала вы подумаете об определении символов объекта, а затем об их сопоставлении с объектами классификации, например, если объект – круг, то это будет мяч, если объект – колючее живое существо, то это будет ежик, а если наш объект лает, то, вероятно, это будет собака.
Причина проста: мы с детства видим зеленый шар, но собака или ежик такого цвета крайне маловероятны для нас. Таким образом, в нашем случае мы можем классифицировать объект, сопоставив его признаки с нашим классификатором по отдельности. Зеленый цвет был сопоставлен с ежом, собакой и мячом, и в итоге мы получили наибольшую вероятность принадлежности зеленого объекта к мячу. Это и есть причина, почему мы классифицировали его как мяч.
Теоретическая составляющая алгоритмаТеорема Байеса позволяет рассчитать апостериорную вероятность P(A | B) на основе P(A), P(B) и P(B | A).
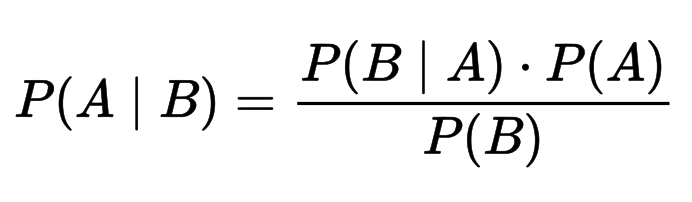
Где:
- P(A | B) – апостериорная вероятность (что A из B истинно)
- P(A) – априорная вероятность (независимая вероятность A)
- P(B | A) – вероятность данного значения признака при данном классе. (что B из A истинно)
- P(B) – априорная вероятность при значении нашего признака. (независимая вероятность B)
Реализация на языке python
### Загружаем библиотеки и данные import numpy as np import pandas as pd from sklearn.datasets import load_iris from scipy.stats import norm data = load_iris() X, y, column_names = data['data'], data['target'], data['feature_names'] X = pd.DataFrame(X, columns = column_names) ### Разбиваем данные from sklearn.model_selection import train_test_split X_train, X_val, y_train, y_val = train_test_split(X, y, random_state=44) means = X_train.groupby(y_train).apply(np.mean) stds = X_train.groupby(y_train).apply(np.std) ### Вычисляем априорную вероятность класса probs = X_train.groupby(y_train).apply(lambda x: len(x)) / X_train.shape[0] ### Вычисляем вероятность для Теоремы Байеса для каждого элемента y_pred = [] # каждый элемент в валидационной части данных for elem in range(X_val.shape[0]): p = {} # для каждого возможного класса for cl in np.unique(y_train): # априорная вероятность взятого ранее класса p[cl] = probs.iloc[cl] # для каждого столбца в датасете for index, param in enumerate(X_val.iloc[elem]): # умножаем вероятность того, что данное значение столбца # будет принадлежать распределению для выбранного класса p[cl] *= norm.pdf(param, means.iloc[cl, index], stds.iloc[cl, index]) y_pred.append(pd.Series(p).values.argmax()) ### Посмотрим точность нашего предсказания несколькими методами # ручной классификатор from sklearn.metrics import accuracy_score accuracy1 = accuracy_score(y_val, y_pred) # классификатор из библиотеки sklearn from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X_train, y_train) accuracy2 = accuracy_score(y_val, model.predict(X_val)) print(accuracy1) print(accuracy2) Результат работы кода:
0.9210526315789473 0.9210526315789473 Базовая модель с самой простой настройкой дает нам точность более чем в 90% на задаче классификации цветков ириса.
Плюсы и минусы
Плюсы
- Алгоритм легко и быстро предсказывает класс тестового набора данных. Он также хорошо справляется с многоклассовым прогнозированием.
- Производительность наивного байесовского классификатора лучше, чем у других простых алгоритмов, таких как логистическая регрессия. Более того, вам требуется меньше обучающих данных.
- Он хорошо работает с категориальными признаками(по сравнению с числовыми). Для числовых признаков предполагается нормальное распределение, что может быть серьезным допущением в точности нашего алгоритма.
Минусы
- Если переменная имеет категорию (в тестовом наборе данных), которая не наблюдалась в обучающем наборе данных, то модель присвоит 0 (нулевую) вероятность и не сможет сделать предсказание. Это часто называют нулевой частотой. Чтобы решить эту проблему, мы можем использовать технику сглаживания. Один из самых простых методов сглаживания называется оценкой Лапласа.
- Значения спрогнозированных вероятностей, возвращенные методом predict_proba, не всегда являются достаточно точными.
- Ограничением данного алгоритма является предположение о независимости признаков. Однако в реальных задачах полностью независимые признаки встречаются крайне редко.
В каких областях использовать?
Алгоритм наивного Байеса – это классификатор, обучение которого идет очень быстро. Следовательно, данный инструмент идеально подходит для составления прогнозов в реальном времени.
Также этот алгоритм также хорошо известен благодаря функции многоклассового прогнозирования. Мы можем предсказать вероятность нескольких классов целевой переменной.
Таким образом, идеальные области для применения наивного байесовского классификатора это:
- Система рекомендаций. В сочетании алгоритма с методами коллаборативной фильтрации (Collaborative Filtering) мы можем создать рекомендательную систему, которая использует машинное обучение и методы добычи данных для учета невидимой информации (такой, как поиск фильмов пользователем и длительность просмотра). Цель – предсказание того, понравится ли пользователю данный ресурс/продукт или нет.
- Фильтрация спама и классификация текста. Наивный байесовский классификатор в основном используются для классификации текстов (благодаря лучшему результату в многоклассовых проблемах и правилу независимости) и имеет более высокую точность по сравнению с другими алгоритмами. В результате он широко используется в фильтрации спама (в электронной почте) и анализе настроений (к примеру, социальных сетей, для выявления положительных и отрицательных настроений клиентов).
***
Из этого руководства вы узнали о наивном байесовском алгоритме классификации, его работе, проблемах, реализации, преимуществах и недостатках.
Параллельно вы также научились реализовывать его на языке Python. Наивный Байесовский классификатор – одих из самых простых и эффективных алгоритмов машинного обучения.
Несмотря на значительные успехи других методов за последние несколько лет, Байес все так же доказывает свою ценность. Он успешно применяется во многих приложениях, от текстовой аналитики и спам-фильтров до систем рекомендаций.
Источник: proglib.io