Как я учил нейронные сети играть в казино
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-11-24 20:28

Hello, world!
Привет, Хабр! Меня зовут Михаил, я учусь на втором курсе Южно-Уральского государственного Университета и одни из самых любимых вещей в моей жизни - это программирование и азартные игры.
Уже около года я занимаюсь машинным обучением, а значит пора закрепить полученные навыки на практике. Тема исследования казино давно меня интересовала, а знакомство с sklearn и компанией дало мне обширный арсенал для этого.
Сегодня мы будем считать чужие деньги, писать парсер, исследовать данные, создавать модели машинного обучения и смотреть мемы.
Идея обыграть рулетку не нова, в отличие от идеи сделать это с помощью нейронных сетей. Немного погуглив, я наткнулся в основном на модели для игры в блекджек(21).
P.S. Данная статья не является рекламой азартных игр или конкретного сайта. Автор неоднократно проигрывал крупные суммы и не рекомендует никому связываться с казино или ставками.
Представляем вам злодея
В качестве противника будет выступать популярный сайт-рулетка по Counter Strike: Global Offensive - CSGOFAST. На этом сайте присутствует более десяти видов азартных игр, а в качестве валюты используются скины на оружия из игры CS:GO.
Мы будем пытаться обыграть евро рулетку, вернее её аналог c сокращенным количеством номеров. Выбор именно этого сайта обусловлен несколькими причинами, одна из них - личные счеты:) Об остальном будет сказано далее.

Правила игры
Руле?тка — азартная игра, представляющая собой вращающееся колесо с 36 секторами красного и чёрного цветов и 37-м зелёным сектором «зеро» с обозначением нуля. Игроки, играющие в рулетку, могут сделать ставку на выпадение шарика на цвет (красное или чёрное), чётное или нечётное число, диапазон (1—18 или 19—36) или конкретное число. Крупье запускает шарик над колесом рулетки, который движется в сторону, противоположную вращению колеса рулетки, и в конце концов выпадает на один из секторов. Выигрыши получают все, чья ставка сыграла (ставка на цвет, диапазон, чётное-нечётное или номера).
Вот какое определение предлагает нам Википедия. Мы же будем иметь дело с упрощенной версией, в которой ставки принимаются только на выпадение цвета, а количество номеров уменьшено. Да и никакого крупье тут нет, обычные числа, сгенерированные компьютером :)
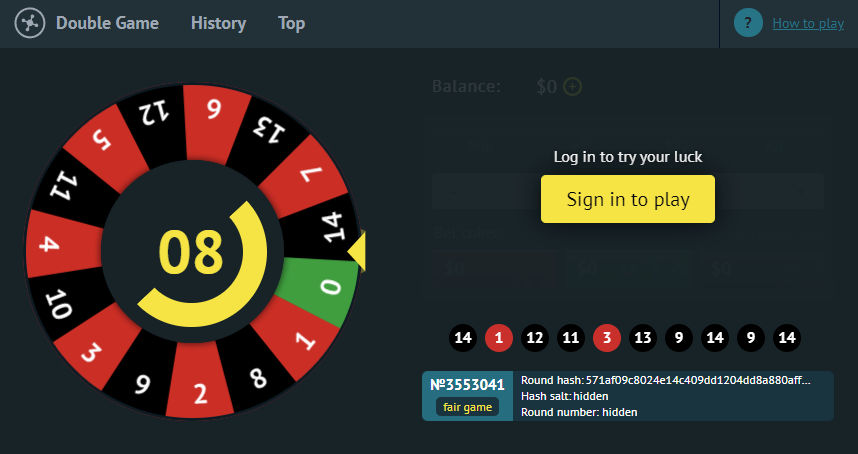
Как работает рандом
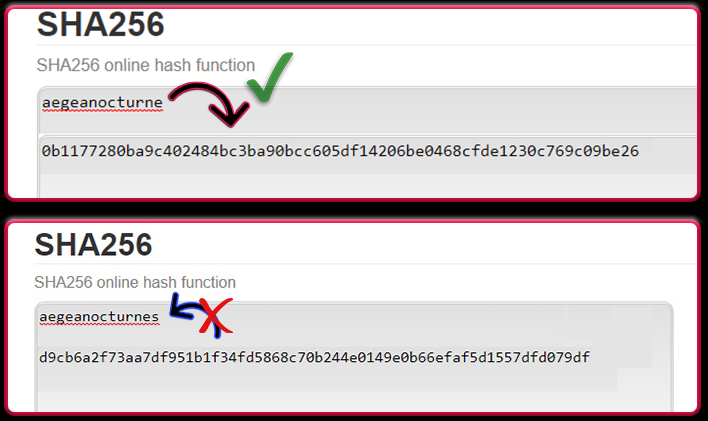
В начале раунда(то есть до ставок) на стороне сайта выбирается случайное число от 0 до 1. По окончании раунда оно домножается на 15 и округляется до целого в меньшую сторону. Получившееся число - номер победного сектора. Чтобы сайт не подкручивал рулетку как угодно ему, с самого начала раунда нам доступен SHA-256 хеш случайного числа, которое выбрал сайт, а после раунда и само число, соответственно пользователь может самостоятельно пропустить его через SHA-256 алгоритм и убедиться в честности.
Сайт не может подкрутить, так как победный цвет известен до ставок.
P.S. Для тех, кто не знаком с шифрованием, SHA-256 это такая штука, которая преобразует одну последовательность символов в другую, при этом в обратную сторону так сделать довольно тяжело(практически невозможно). В этом и прикол.
Перейдем к делу
Для начала нужно определиться с данными, на основе которых наша модель будет предсказывать цвет следующего выпадшего числа. Максимум, доступный на сайте в реальном времени - результаты 50 последних игр, а также денежные ставки на текущую игру. Чтобы наша модель не нуждалась в дополнительном сборе наблюдений и её можно было использовать из коробки без ожидания, будем делать предсказание следующего цвета на 50 играх. Соответственно, наш первый шаг - написать парсер для сбора данных.
Мы будем использовать Python и библиотеку Requests-HTML, обычный requests не подойдет, поскольку для доступа к результатам игр нужно предварительно выполнить на странице весь JavaScript. Результаты будем записывать в .csv файлы. Также я не стал заморачиваться над причесыванием данных во время сбора, ведь гораздо легче сделать это парой команд из Pandas.
Объявим класс парсера. Он будет иметь две функции, одна из них будет подгружать историю игр, другая собирать информацию о проходящей в данный момент(это две разные страницы, соответственно и функции две). То есть, информацию о денежных ставках мы можем получить только из текущей игры, а выпавшие номера для всех 50 прошедших.
from requests_html import HTMLSession class CSGOFastParser(): def __init__(self, url="http://csgofastx.com"): self.url = url self.history_url = url + "/history/double/all" self.current_game_url = url + "/game/double" Функция для загрузки и выделения данных из истории игр
def parse_history(self): try: #Создаем HTML сессию history_session = HTMLSession() #Получаем html страницу, и выполняем на ней JS resp = history_session.get(self.history_url) resp.html.render() #Ищем раздел "history-wrap" resp = resp.html.find('.history-wrap', first=True) #Разделяем игры по подстроке "Game #" history = resp.text history = history.split("Game #") #Превращаем все в удобный список rounds = [] for record in history: rounds.append(record.split(' ')[:6]) #В первом элементе содержится мусор return rounds[1:] except BaseException: #Иногда сайт может спать return False Парсер будет загружать HTML страницу, рендерить весь JavaScript, выбирать текст из контейнера '.history-wrap'(он содержит результаты 50 последних игр - то, что нам надо) а затем возвращать удобный список из результатов игр.
Аналогичным образом работает и вторая функция. Иногда случается момент, когда на странице отсутствует '.game-bets-header', поэтому добавлена проверка.
Сбор информации о денежных ставках
def parse_current_game(self): try: current_game_session = HTMLSession() resp = current_game_session.get(self.current_game_url) resp.html.render() results = resp.html.find('.game-bets-header') #Если что-то пошло не так все останется на -1. #Отрицательные данные в будущем будут отброшены red_bet = -1 green_bet = -1 black_bet = -1 #Если страница корректно загрузилась if len(results) > 1: red_bet = results[0].text green_bet = results[1].text black_bet = results[2].text time_till_raffle = resp.html.find('.bonus-game-timer' )[0].text game_id = resp.html.find('.game-num')[0].text #Время до розыгрыша, id игры, ставки на каждый цвет return (time_till_raffle, game_id, red_bet, green_bet, black_bet) except BaseException: #Сайт может не отвечать return False Поместим все это дело в цикл, который будет скачивать данные с заданными интервалами и записывать полученные результаты в файл. Он будет скачивать информацию о денежных ставках гораздо чаще, чем длится одна игра, поэтому запись будет создаваться когда таймер до начала меньше единицы, либо равен 25(момент, в который рулетка крутится и информация о ставках уже не может изменится)
Парсер готов к работе
from time import time from Parsers import CSGOFastParser if __name__ == "__main__": parser = CSGOFastParser() history_output_path = "./train.csv" money_info_output_path = "./bets.csv" history_latest_parse_time = 0 current_game_latest_parse_time = 0 history_cooldown = 1200 current_game_cooldown = 3 while(True): current_time = time() #Если кулдаун кончился - выполняем алгоритм сбора данных if(current_time - history_latest_parse_time > history_cooldown): history_data = parser.parse_history() #Если сбор прошел удачно, записываем в файл if (history_data): history_latest_parse_time = current_time with open(history_output_path, "a+") as file: for line in history_data: for element in line: file.write(element) file.write(',') file.write(' ') if(current_time - current_game_latest_parse_time > current_game_cooldown): current_game_info = parser.parse_current_game() if(current_game_info): current_game_latest_parse_time = current_time #Собранные данные близки к концу раунда if int(current_game_info[0]) < 1 or int(current_game_info[0]) == 25: with open(money_info_output_path, "a+") as file: for element in current_game_info[1:]: file.write(element) file.write(',') file.write(' ') Ну, теперь оставляем все наше дело на парочку недель, чтобы оно в фоне сохраняло результаты игр
Поиграем
Пару дней прошло, данные собираются, но их еще слишком мало для анализа, а значит... пока можно заняться другим. Пойдем на эту рулетку и посмотрим, какую точность предсказаний мы получим без использования математики(повторяю, исключительно в исследовательских целях!).
Я выделил 3 консервативных метода игры:
1) Игра без стратегии
Я просто полагался на удачу и интуицию, угадывая числа. На поле присутствует 7 черных, 7 красных и 1 зеленый сектор. Значит, при ставке на красное/черное мы имеем вероятность победы 7/15 или же 0.466. По факту так играет большинство
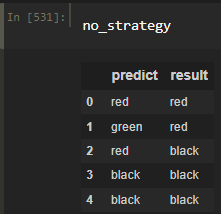
Сыграв 100 игр(без ставок), я угадал верно 45/100 выпадений, что уже довольно близко к аналитически вычисленному значению. Забегая вперед, построим графики с помощью matplotlib и Pandas.
Код графиков
#Разделим предсказания на правильные и неправильные valid_preds = no_strategy[no_strategy['predict'] == no_strategy['result']] invalid_preds = no_strategy[no_strategy['predict'] != no_strategy['result']]#Мои предсказания plt.figure(figsize=(20,5)) plt.title('Мои предсказания',fontsize=30) plt.xlabel('Номер игры', fontsize =16) plt.ylabel('Цвет',fontsize=12) plt.xticks(np.arange(0,101, 10)) #Небольшой костыль, чтобы поменять порядок меток по оси y plt.scatter([0,1,2], ['red','black','green'], c='white') plt.scatter(no_strategy.index, no_strategy['predict'], c='b')#Выпавшие значения plt.figure(figsize=(20,5)) plt.title('Выпавшие значения',fontsize=30) plt.xlabel('Номер игры', fontsize =16) plt.ylabel('Цвет',fontsize=12) plt.xticks(np.arange(0,101, 10)) plt.scatter(no_strategy.index, no_strategy['result'], c='grey')#Совместим 2 графика plt.figure(figsize=(20,5)) plt.title('Результаты игры без стратегии',fontsize=30) plt.xlabel('Номер игры', fontsize =16) plt.ylabel('Цвет',fontsize=12) plt.xticks(np.arange(0,101, 10)) plt.scatter(valid_preds.index, valid_preds['predict'], c='g') plt.scatter(invalid_preds.index, invalid_preds['predict'], c='r') plt.scatter(invalid_preds.index, invalid_preds['result'], c='grey')Мои предсказания / выпавшие значения
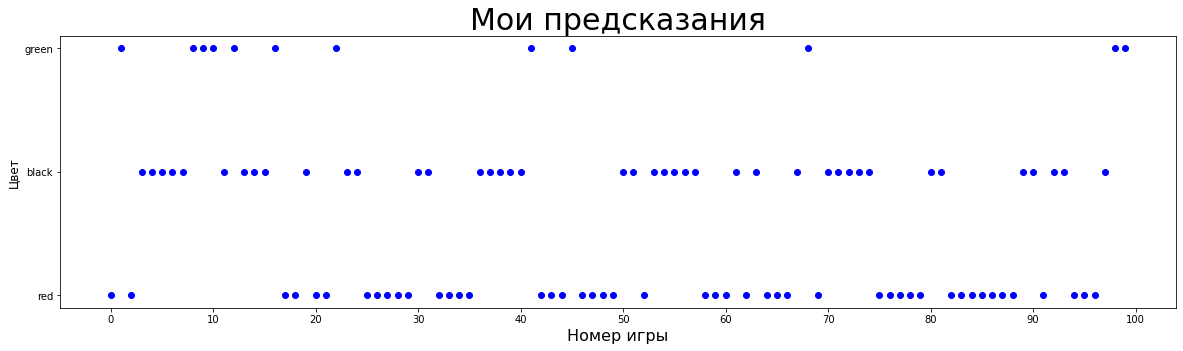
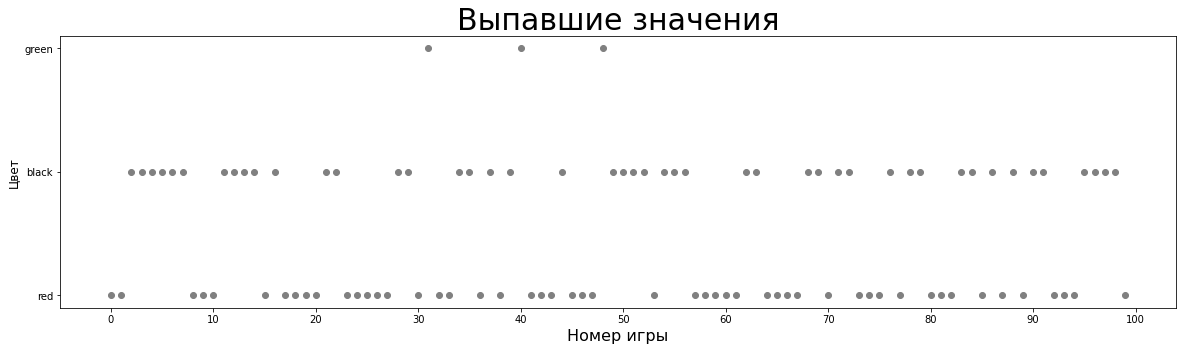
Совместим эти 2 графика.

Зеленое - я угадал цвет, красное - я ошибся, серое - правильный ответ при моих ошибках. Стоит заметить, что precision и recall зеленого составляют два ноля:) Иначе говоря, ни один раз, предсказав ноль, я не оказался прав и не угадал ни одного действительно выпавшего ноля
2) Мартингейл
Стратегия заключается в том, чтобы начиная с малой суммы увеличивать ее на 2 в случае пройгрыша и ставить на тот же самый цвет.
Пример: 1 красное-проиграл-2 красное-проиграл-4 красное-проиграл-8 красное- выйграл(окупился на 1 единицу)- 1 красное-... Тогда выйгрыш всегда будет покрывать потери, а еще и давать прибыль в размере первой ставки.
Пусть S - начальная сумма.
Сформулировать это математически можно так: для того, чтобы сделать n ставок, нужно потратить S*(2^(n) - 1) валютных единиц. При этом вероятность проиграть будет выглядеть так: 0.54 ^ n. Данная стратегия не терпит единого поражения, поскольку оно означает потерю баланса. Главный минус - сумма растет в два раза с каждой ставкой. С другой же стороны очень сложно поверить в выпадение, допустим, 20 черных подряд без подкруток(на деле автор видел 23 черных подряд). Измусоленная тема - ошибка игрока.
Сделаем вывод о данной стратегии во время анализа.
Посмотрим на сумму ставки при количестве игр n:
| n=10 | 1023 |
| n=11 | 2047 |
| n=12 | 4095 |
| n=13 | 8191 |
| n=14 | 16383 |
| n=15 | 32767 |
| n=16 | 65535 |
| n=17 | 131071 |
| n=18 | 262143 |
| n=19 | 524287 |
| n=20 | 1048575 |
Иначе говоря, играя по Мартингейлу с запасом на 20 пройгрышей, вы будете рисковать миллионом ради одного рубля в почти самом плохом случае(в самом плохом вы проиграете:)). Хочу напомнить, что одна игра идет порядка 40 секунд, а вы будете получать по 1 единице прибыли с каждой игры. Для реальной прибыли надо начинать хотя бы с 10 рублей, и иметь в запасе 10 миллионов на запас из 20 игр.
3) Мартингейл++
До этой стратегии я(как и миллион других гениев-игроманов) додумался сам. Ждем, пока на рулетке выпадет 6-7 одинаковых цветов на холостом ходу, а затем начинаем ставить по Мартингейлу.

Проблема в том, что если играть по 10 рублей и ждать выпадение 7 цветов в ряд, вы скорее состаритесь, чем станете миллионером.
Тем временем, наблюдения уже собрались.
Приведем данные в порядок
data = pd.read_csv('./train.csv') data.columns = ["time","result", "Round hash", "hash salt", "round number"]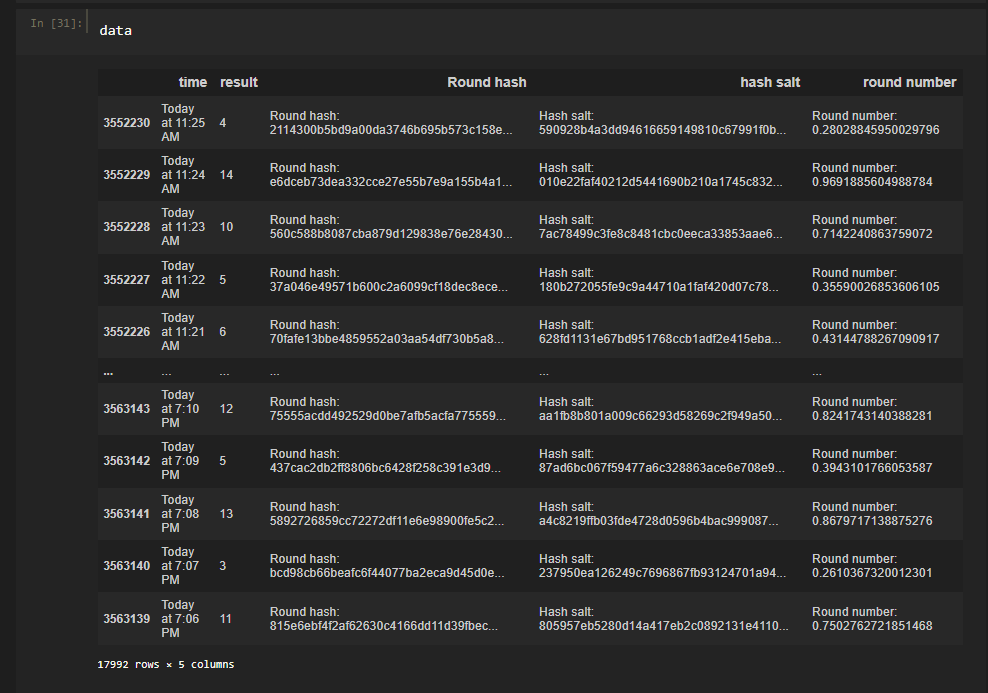
Вряд ли мы будем учить нейронку предсказывать соленый хэш, поэтому эти данные нам ни к чему. Время дается с точность до минут, оно мне не пригодилось.
Обработка датасета игр
#Убираем дубликаты и сортируем по индексу data.drop_duplicates(inplace=True) data.sort_index(inplace=True) #Оставляем нужные колонки data = data[['result','round number']] #Преобразуем строки в числовые данные data['round number'] = data['round number'].str.replace('Round number: ','') data['round number'] = data['round number'].astype('float32')
Денежный датасет
bets_data = pd.read_csv('./bets.csv', error_bad_lines=False) bets_data.columns = ['bet on red', 'bet on green', 'bet on black'] bets_data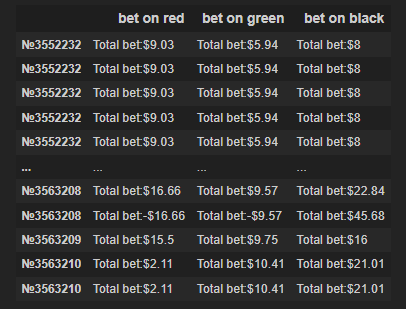
Обработка
# Приводим в порядок индекс bets_data.index = bets_data.index.str.replace('№','') bets_data.index = bets_data.index.astype('int32') bets_data.sort_index(inplace=True) #Достаем из текста числа for col in bets_data.columns: bets_data[col] = bets_data[col].apply(lambda x: x.replace('Total bet:', '')) bets_data[col] = bets_data[col].apply(lambda x: x.replace('$', '')) bets_data[col] = bets_data[col].astype('float64') #Из-за анимаций сайта есть момент, #в который ставки принимают минусовое значение. #Также почти никогда не бывает нулей, #записи с ними появились после обнуления #счетчика но до начала нового раунда #Оставляем лишь колонки, где ставки больше нуля bets_data = bets_data[bets_data[col] > 0]#Так как мы собирали данные каждые 5 секунд, #в наших данных находится много промежуточных значений. #Чтобы разобраться с этим, будем оставлять те, #где на каждый цвет поставлено больше всего. #Эта функция немного тяжелая. def find_max_bets(df): for i in range(len(df)-1): for col in df.columns: if df.iloc[i+1][col] < df.iloc[i][col]: return df.iloc[i].values return df.iloc[0].values #Сохраним обработанные данные в bets_cleaned_df bets_cleaned = [] for idx in bets_data.index.unique(): sub_df = bets_data[bets_data.index == idx] bets_cleaned.append((idx, *find_max_bets(sub_df))) bets_cleaned = np.array(bets_cleaned) bets_cleaned_df = pd.DataFrame(bets_cleaned) bets_cleaned_df = bets_cleaned_df.set_index(0) bets_cleaned_df.columns = ['bet on red', 'bet on green', 'bet on black']Общий датасет
Теперь мы объединим 2 датасета в один
#Информация для некоторых игр пропущена по техническим причинам парсера, #поэтому в качестве индекса будем использовать range от #первой до последней наблюдаемой игры. game_ids = np.arange(data.index.min(), data.index.max()) main_df = pd.DataFrame(index=game_ids) main_df = main_df.join(data) main_df = main_df.join(bets_cleaned_df) main_df = main_df[~main_df.index.duplicated(keep='last')]Добавим колонку с выпавшим цветом
def get_color(num): if num < 1: return 'green' elif num < 8: return 'red' else: return 'black' return main_df['color'] = main_df['result'].agg(get_color)import seaborn as sns sns.heatmap(main_df.isnull())")
Главный датасет

Исследование
2 вещи, которые всегда меня интересовали - какое максимальное количество раз какой-то цвет не выпадал и сколько казино получает прибыли. Будем добираться до сути.
Одинаковые цвета в ряд
Третий год подряд не могу запомнить написание слова "сосед"...
#Считаем кол-во вхождений подряд, с учетом пропущенных данных. def max_neighbor_entry(vector): ctr_list = [] crr_ctr = 1 idx=0 for i in range(len(vector)-1): if (vector[i]== None or vector[i+1] == None): crr_ctr = 1 continue if vector[i] == vector[i +1]: crr_ctr +=1 else: ctr_list.append((crr_ctr, vector[i],idx)) crr_ctr = 1 idx=i+1 return ctr_list seq = np.array(sorted( max_neighbor_entry(main_df['color'].values))) seq
Выяснили, что красное выпадало подряд 11 раз, черное 12, зеленое - 3.

Также нужно посчитать кол-во игр, которое какой-то цвет, наоборот, не выпадал.
Кол-во невыпадений какого-то числа
colors = main_df['color'].values dist = [] for i in range(len(colors)): crr_cl = colors[i] if (crr_cl == None): continue j = i+1 while (j < len(colors)): if (colors[j] == None): j = len(colors) elif (crr_cl == colors[j]): #кортеж вида : (id игры, цвет, #кол-во игр до такого же цвета) dist.append((j-i-1,colors[i],i)) j = len(colors) j += 1 dist = np.flip(sorted(dist)) green_intervals = dist[dist[:,1] == 'green'] red_intervals = dist[dist[:,1] == 'red'] black_intervals = dist[dist[:,1] == 'black']
Красное не выпадало 16 игр подряд, черное 17, зеленое 95(!). Внимание на графики.
Код графиков
#Зеленое plt.figure(figsize=(20,5)) plt.xticks(np.arange(0,100,5)) plt.hist(green_intervals[:,2].astype('int32'),color='g',bins=100)#Красное plt.figure(figsize=(20,5)) plt.xticks(np.arange(0,20)) plt.hist(red_intervals[:,2].astype('int32'),color='r',bins=16)#Черное plt.figure(figsize=(20,5)) plt.xticks(np.arange(0,20)) plt.hist(black_intervals[:,2].astype('int32'),color='black',bins=17)Графики



17 игр без черного...
Я могу сделать для себя какие-то выводы. Еще совсем недавно я пытался ждать 15-20 игр без зеленого, а затем начинал на него ставить до победного. Зная, что частенько зеленое не выпадает и 30+ раз, больше играть я по такой стратегии я не буду(хотя, кого я обманываю...).
И самое главное - Мартингейл. 17 раз подряд. Рискуем 131 тысячей денежных единиц ради одной. Если же начинать играть с середины, допустим, с восьмого выпадения - будем рисковать 1023 единицами ради одной. И никто не гарантирует, что больше 17 раз подряд серии не будет. Стоит ли оно того? Решает каждый сам.
Далее - прибыль сайта
Подсчет прибыли с игры
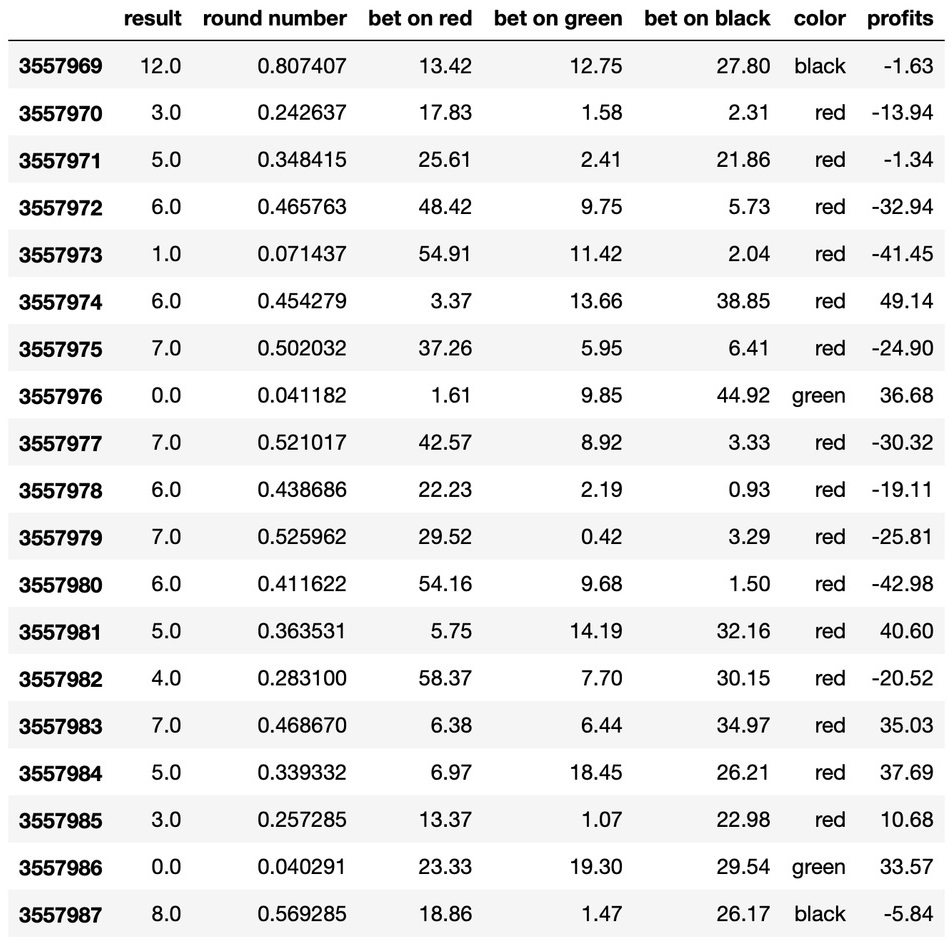
profits = [] for i in range(len(main_df)): #Выбираем по одному объекту game = main_df[i:i+1] #Если есть данные о ставках и цвете на этом объекте if not game['bet on red'].isnull().values[0] and not game['color'].isnull().values[0]: #Считаем профит profit = float(game['bet on green'] + game['bet on red'] + game['bet on black']) loss = game['bet on ' + game['color']] loss = loss.values profit -= float(loss) * 2 profits.append(profit) else: profits.append(None) main_df['profits'] = profitsФункция работает незамысловато, неподготовленного пользователя тут скорее смутит реализация выбора нужной колонки и проверка на Null. Ну и эта функция немного тяжелая.
Мы складываем 2 ставки на не выпавшие цвета и вычитаем ставку на выпавший. Это и есть прибыль с игры.

За одиннадцать тысяч игр, с учетом пропущенных, сайт получил прибыль в размере 62129.7 долларов или 4541059.78 рублей по текущему курсу. Я собирал данные 10 дней. Неплохо, однако...
Ну, напоследок взглянем на то, как выглядит график числа раунда за 200 игр.

Увидеть какие-то паттерны на данном графике невооруженным глазом невозможно.
Построение моделей
from sklearn.linear_model import LogisticRegression, LinearRegression from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score from sklearn.metrics import mean_squared_error from sklearn.preprocessing import PolynomialFeatures, StandardScaler, MinMaxScaler from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor import pickleЯ решил использовать 3 вида входных/выходных данных модели:
1) Предыдущие цвета -> следующий цвет
2) Предыдущие числа -> следующий цвет
3) Предыдущие числа -> следующее число
Создадим колонки с предыдущими выпадениями чисел(иначе говоря лагами)
round_lags = pd.concat([main_df['round number']. shift(lag).rename('{}_lag{}'. format(main_df['round number']. name, lag+1)) for lag in range(51)], axis=1).dropna()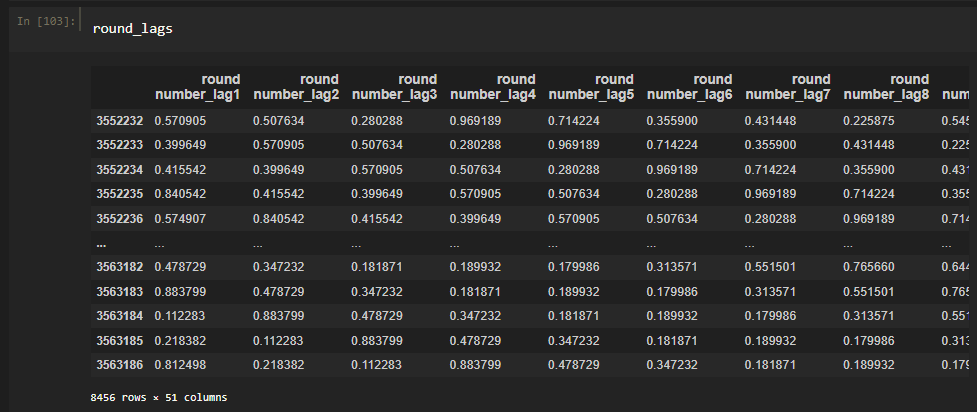
Аналогичным образом будем создавать и лаги цветов для будущих моделей.
Теперь первую колонку(без задержек) можно использовать в качестве вектора ответов, а 50 колонок лагов в качестве матрицы признаков.
Перебор
Я опробовал линейные и логистические регрессии с разными гиперпараметрами на трех вариантах входных/выходных данных. Код практически не отличается, поэтому прикреплю один пример
Логистическая регрессия из цветов в цвета
model1 = LogisticRegression() #Создам лаги X = pd.concat([main_df['color'].shift(lag). rename('{}_lag{}'.format(main_df['color'].name, lag+1)) for lag in range(51)], axis=1).dropna() y = X[X.columns[0:1]] X = X[X.columns[1:]] X = pd.get_dummies(X,drop_first=True) #Поиск гиперпараметров по сетке grid = { 'C': [1,2,3,5,10,20,50,100,1000], 'fit_intercept' : [True,False], 'max_iter' : [200,500,1000,2000], } gscv = GridSearchCV(model1, grid, scoring='accuracy') gscv.fit(X,y.values.ravel())
Модель не смогла уйти сильно дальше человека и показала почти ожидаемую точность.

Итого опробовав 5 регрессий, а затем и пару полиномиальных и все это с разными гиперпараметрами, добиться точности выше 0.48 не удалось(да и такая точность скорее всего получилась из-за удачно подобранного random seed, т.е. случайного фактора)
Полиномиальная регрессия
model5 = LinearRegression() X = pd.concat([main_df['round number'].shift(lag). rename('{}_lag{}'.format(main_df['round number'].name, lag+1)) for lag in range(51)], axis=1) X = X.join(main_df['round number']) X = X[X.columns[1:]] X = X.dropna() y = X['round number'] X = X.drop('round number',axis=1) pf = PolynomialFeatures(2) X = pf.fit_transform(X) scaler = MinMaxScaler() X = scaler.fit_transform(X) X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state = 60) model5.fit(X_train, y_train) preds = model5.predict(X_test) y_test = pd.Series(y_test).agg(lambda x: get_color(x * 15)) preds = pd.Series(preds).agg(lambda x: get_color(x * 15))
Далее в бой пошли случайные леса. И код, и результат там сильно схожи с предыдущими, поэтому прикреплять их не вижу смысла.
Neural Networks
На самом деле, результаты простых моделей уже подбили мою веру в успех, но, как говорится, попытка - не пытка.
import tensorflow as tf from tensorflow import keras from tensorflow.keras import layersmodel7 = keras.Sequential( [ layers.Dense(256,activation="relu", name="layer1"), layers.Dense(128,activation="relu", name="layer2"), layers.Dense(3,name="layer3"), layers.Softmax() ] ) optimizer = tf.keras.optimizers.Adam() loss = tf.losses.CategoricalCrossentropy() model7.compile(optimizer,loss)
Попробуем обучить модель с двумя скрытыми слоями по 256 и 128 нейронов в каждом, и выходным слоем из трех нейронов, отвечающим за вероятность выпадения каждого цвета.
X = pd.concat([main_df['round number'].shift(lag). rename('{}_lag{}'.format(main_df['round number'].name, lag+1)) for lag in range(51)], axis=1) X = X.join(main_df['color']) X = X[X.columns[1:]] X = X.dropna() y = X['color'] y = pd.get_dummies(y).values X = X.drop('color',axis=1) X = X.astype('float32') X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3) model7.fit(X_train,y_train,epochs=25)Внимание на последние эпохи:
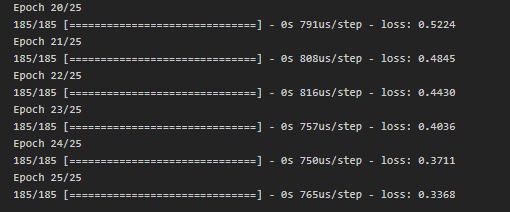
Внезапно(или нет?) количество потерь сократилось до 0.33. Ура? Нет. Наша модель просто переобучилась и заучила ответы на тренировочной выборке. Посчитав accuracy, получаем 0.45, что даже хуже, чем у полиномиальной регрессии...
Напоследок я попробовал другие конфигурации нейронов и даже модель с денежными ставками, но ничего путного из этого не вышло. Жаль...

Заключение
К сожалению, нейронные сети это не магия, а всего лишь крутое применение математики. Я не стал миллионером, но зато получил ответы на вопросы, которые не давали спать по ночам и прокачал свои скиллы. Возможно, собрав больше данных, закономерность получится найти, но об этом мы узнаем уже в следующей части статьи, если она будет)
А на этом я с вами прощаюсь. Надеюсь, не навсегда.
Телеграм: t.me/ainewsline
Источник: habr.com