Что случилось: придумали симулятор CyberBattleSim, в котором нейронка взламывает систему и пытается постепенно захватить компьютерную сеть или нанести ей максимальный урон.
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-05-14 16:00

Что случилось: придумали симулятор CyberBattleSim, в котором нейронка взламывает систему и пытается постепенно захватить компьютерную сеть или нанести ей максимальный урон. Программистам-защитникам нужно своевременно обнаружить проникновение, обезвредить противника или помешать его планам — напоминает соревнование Capture the Flag (CTF), только с противостоянием людей и компьютеров.
Зачем: для тренировки специалистов по безопасности — чтобы они лучше понимали действия хакеров и могли быстро реагировать на любые угрозы.
Кто: компания Microsoft.
Исходный код: https://github.com/microsoft/CyberBattleSim
Геймификация машинного обучения для повышения безопасности и моделей искусственного интеллекта
Чтобы опередить противников, которые не проявляют сдержанности в принятии инструментов и методов, которые могут помочь им достичь своих целей, Microsoft продолжает использовать искусственный интеллект и машинное обучение для решения проблем безопасности. Одна из областей, в которой мы экспериментировали, - это автономные системы. В моделируемой корпоративной сети мы исследуем, как автономные агенты, представляющие собой интеллектуальные системы, которые независимо выполняют набор операций с использованием определенных знаний или параметров, взаимодействуют в среде и изучают, как методы подкрепляющего обучения могут быть применены для повышения безопасности.
Сегодня мы хотели бы поделиться некоторыми результатами этих экспериментов. Мы открываем исходный код Python исследовательского инструментария, который мы называем CyberBattleSim, экспериментального исследовательского проекта, который исследует, как автономные агенты работают в моделируемой корпоративной среде, используя высокоуровневую абстракцию компьютерных сетей и концепций кибербезопасности. Инструментарий использует основанный на Python интерфейс OpenAI Gym для обучения автоматизированных агентов с использованием алгоритмов обучения подкреплению. Код доступен здесь: https://github.com/microsoft/CyberBattleSim
CyberBattleSim предоставляет способ построения высоко абстрактного моделирования сложности компьютерных систем, что позволяет сформулировать проблемы кибербезопасности в контексте обучения с подкреплением. Широко распространяя этот исследовательский инструментарий, мы призываем сообщество опираться на нашу работу и исследовать, как киберагенты взаимодействуют и развиваются в моделируемых средах, а также исследовать, как высокоуровневые абстракции концепций кибербезопасности помогают нам понять, как киберагенты будут вести себя в реальных корпоративных сетях.
Это исследование является частью усилий Microsoft по использованию машинного обучения и ИИ для непрерывного повышения безопасности и автоматизации большей работы для защитников. Недавнее исследование, проведенное по заказу Microsoft, показало, что почти три четверти организаций говорят, что их команды тратят слишком много времени на задачи, которые должны быть автоматизированы. Мы надеемся, что этот инструментарий вдохновит больше исследований для изучения того, как автономные системы и подкрепляющее обучение могут быть использованы для создания устойчивых технологий обнаружения угроз в реальном мире и надежных стратегий киберзащиты.
Применение подкрепляющего обучения к безопасности
Подкрепляющее обучение-это тип машинного обучения, с помощью которого автономные агенты учатся принимать решения, взаимодействуя со своей средой. Агенты могут выполнять действия для взаимодействия со своим окружением, и их цель-оптимизировать некоторое понятие вознаграждения. Одно популярное и успешное приложение можно найти в видеоиграх, где среда легко доступна: компьютерная программа, реализующая игру. Игрок в игре-это агент, команды , которые он принимает, - это действияи конечная награда это победа в игре. Лучшие алгоритмы обучения с подкреплением могут научиться эффективным стратегиям через повторный опыт, постепенно изучая, какие действия следует предпринять в каждом состоянии окружающей среды. Чем больше агенты играют в эту игру, тем умнее они становятся. Последние достижения в области обучения с подкреплением показали, что мы можем успешно обучать автономных агентов, которые превосходят человеческий уровень, играя в видеоигры.
В прошлом году мы начали изучать применение подкрепляющего обучения для обеспечения безопасности программного обеспечения. Для этого мы рассматривали проблемы безопасности программного обеспечения в контексте обучения с подкреплением: атакующего или защитника можно рассматривать как агентов, эволюционирующих в среде, обеспечиваемой компьютерной сетью. Их действия-это доступные сетевые и компьютерные команды. Целью злоумышленника обычно является кража конфиденциальной информации из сети. Цель защитника состоит в том, чтобы изгнать нападающих или смягчить их действия в системе, выполнив другие виды операций.

Рис. 1. Сопоставление концепций обучения подкреплению с безопасностью
В этом проекте мы использовали OpenAI Gym, популярный инструментарий , который предоставляет интерактивную среду для исследователей обучения подкреплению для разработки, обучения и оценки новых алгоритмов обучения автономных агентов. Известные примеры сред, построенных с использованием этого инструментария, включают видеоигры, симуляторы робототехники и системы управления.
Компьютерные и сетевые системы, конечно, значительно сложнее, чем видеоигры. В то время как видеоигра обычно имеет несколько разрешенных действий одновременно, существует огромное количество действий, доступных при взаимодействии с компьютером и сетевой системой. Например, состояние сетевой системы может быть гигантским и не поддающимся легкому и надежному восстановлению, в отличие от конечного списка позиций в настольной игре. Тем не менее, несмотря на эти проблемы, OpenAI Gym предоставил хорошую основу для наших исследований, что привело к развитию кибербаттлсима.
Как работает CyberBattleSim
CyberBattleSim фокусируется на моделировании угроз на стадии бокового движения после взлома кибератаки. Среда состоит из сети компьютерных узлов. Он параметризуется фиксированной топологией сети и набором предопределенных уязвимостей, которые агент может использовать для бокового перемещения по сети. Цель имитируемого злоумышленника состоит в том, чтобы завладеть некоторой частью сети, используя эти заложенные уязвимости. В то время как имитируемый злоумышленник перемещается по сети, агент защитника наблюдает за сетевой активностью, чтобы обнаружить присутствие злоумышленника и сдержать атаку.
Для иллюстрации на приведенном ниже графике показан игрушечный пример сети с машинами, работающими под управлением различных операционных систем и программного обеспечения. Каждая машина имеет набор свойств, значение и заранее назначенные уязвимости. Черные края представляют собой трафик, проходящий между узлами, и помечаются протоколом связи.
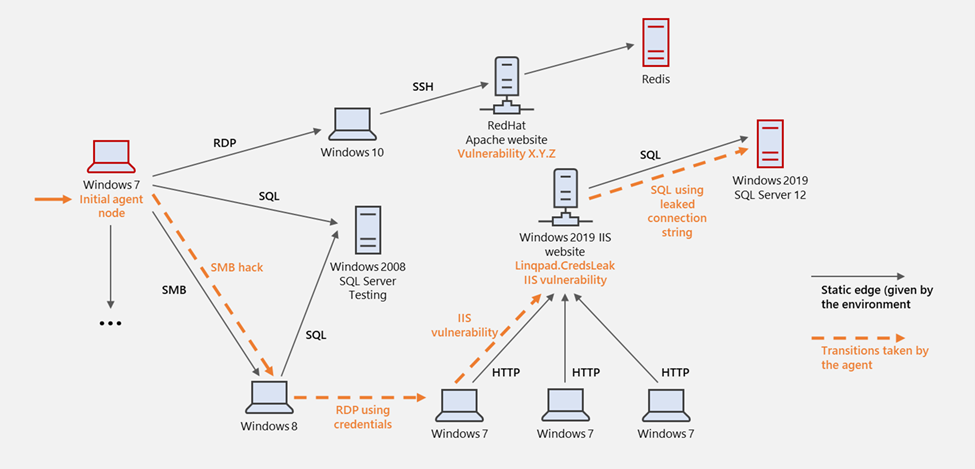
Рис. 2. Визуальное представление бокового движения при моделировании компьютерной сети
Предположим, что агент представляет атакующего. Предположение после взлома означает, что один узел изначально заражен кодом злоумышленника (мы говорим, что злоумышленник владеет узлом). Цель имитируемого злоумышленника - максимизировать совокупное вознаграждение, обнаружив и завладев узлами сети. Среда частично наблюдаема: агенту не удается заранее увидеть все узлы и ребра сетевого графа. Вместо этого злоумышленник предпринимает действия, чтобы постепенно исследовать сеть с узлов, которыми он в настоящее время владеет. Есть три вида действий, предлагая агенту сочетание возможностей эксплуатации и разведки: выполнение локальной атаки, выполнение удаленной атаки и подключение к другим узлам. Действия параметризуются исходным узлом, на котором должна выполняться базовая операция, и разрешаются только на узлах, принадлежащих агенту. Награда-это поплавок, представляющий внутреннюю ценность узла (например, SQL-сервер имеет большую ценность, чем тестовая машина).
В изображенном примере имитируемый злоумышленник проникает в сеть с имитируемого узла Windows 7 (слева, на который указывает оранжевая стрелка). Он продолжает боковое перемещение к узлу Windows 8, используя уязвимость в протоколе обмена файлами SMB, а затем использует некоторые кэшированные учетные данные для входа в другую машину Windows 7. Затем он использует удаленную уязвимость IIS для владения сервером IIS и, наконец, использует утечку строк подключения для доступа к базе данных SQL.
Эта среда имитирует гетерогенную компьютерную сеть, поддерживающую несколько платформ, и помогает показать, как использование новейших операционных систем и поддержание этих систем в актуальном состоянии позволяют организациям использовать преимущества новейших технологий упрочнения и защиты в таких платформах, как Windows 10. Среда simulation Gym параметризуется определением макета сети, списком поддерживаемых уязвимостей и узлами, в которых они размещены. Моделирование не поддерживает выполнение машинного кода, и, следовательно, никакой эксплойт безопасности на самом деле не происходит в нем. Вместо этого мы моделируем уязвимости абстрактно с предварительным условием, определяющим следующее: узлы, в которых уязвимость активна, вероятность успешной эксплуатации и высокоуровневое определение результата и побочных эффектов. Узлы имеют предварительно назначенные именованные свойства, над которыми предварительное условие выражается в виде логической формулы.
Результаты уязвимости
Существуют предопределенные результаты, которые включают следующее: утечка учетных данных, утечка ссылок на другие компьютерные узлы, утечка свойств узла, получение права собственности на узел и повышение привилегий на узле. Примеры удаленных уязвимостей включают: сайт SharePoint, предоставляющий учетные данные ssh, уязвимость ssh, предоставляющая доступ к машине, проект GitHub, утечка учетных данных в истории фиксации, и сайт SharePoint с файлом, содержащим токен SAS для учетной записи хранения. Между тем, примеры местных уязвимости включают в себя: извлечение маркера аутентификации или учетных данных из системного кэша, эскалацию до системных привилегий, эскалацию до прав администратора. Уязвимости могут быть либо определены на месте на уровне узла, либо определены глобально и активированы логическим выражением предварительного условия.
Контрольный показатель: Измерение прогресса
Мы предоставляем базовый стохастический защитник, который обнаруживает и смягчает текущие атаки на основе предопределенных вероятностей успеха. Мы реализуем смягчение путем переосмысления зараженных узлов-процесс, абстрактно смоделированный как операция, охватывающая несколько этапов моделирования. Чтобы сравнить производительность агентов, мы рассмотрим два показателя: количество шагов моделирования, предпринятых для достижения их цели, и совокупное вознаграждение за этапы моделирования в разные периоды обучения.
Моделирование проблем безопасности
Параметризуемый характер среды тренажерного зала позволяет моделировать различные проблемы безопасности. Например, приведенный ниже фрагмент кода вдохновлен задачей захвата флага, где цель злоумышленника состоит в том, чтобы завладеть ценными узлами и ресурсами в сети:

Рис. 3. Код, описывающий экземпляр среды моделирования
Мы предоставляем блокнот Jupyter для интерактивного воспроизведения атакующего в этом примере:
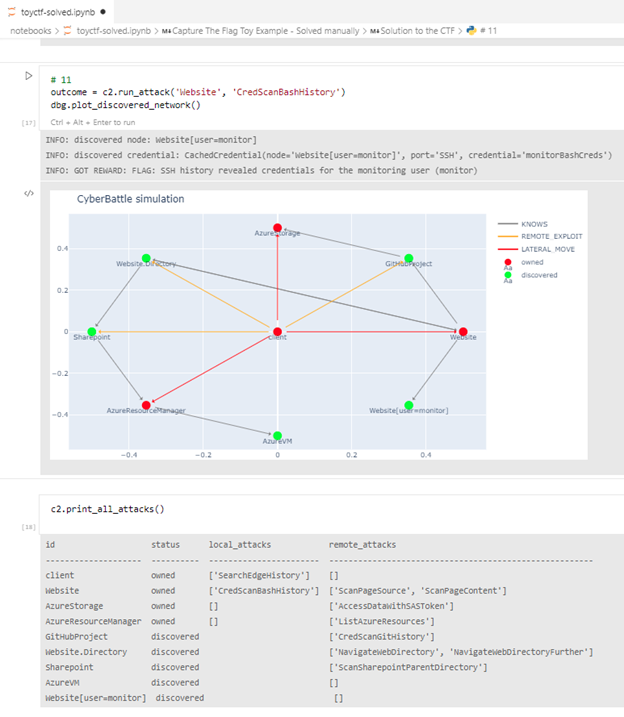
Рисунок 4. Интерактивное воспроизведение симуляции
С помощью интерфейса Gym мы можем легко создавать экземпляры автоматизированных агентов и наблюдать, как они развиваются в таких средах. На скриншоте ниже показан результат запуска случайного агента в этой симуляции—то есть агента, который случайным образом выбирает, какое действие выполнять на каждом шаге симуляции.
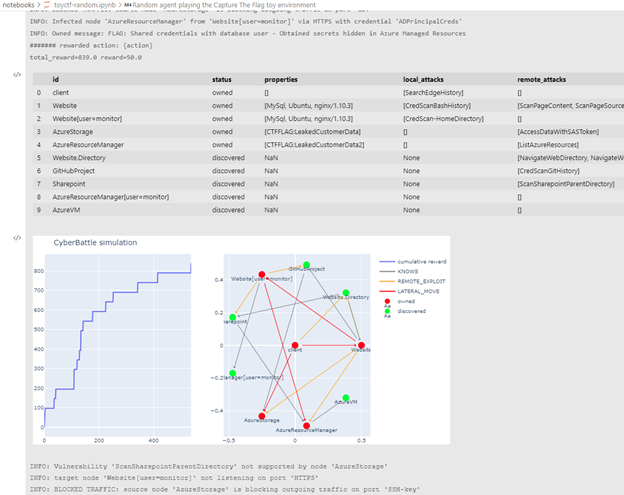
Рисунок 5. Случайный агент, взаимодействующий с симуляцией
Приведенный выше график в записной книжке Jupyter показывает, как функция кумулятивного вознаграждения растет вдоль эпох моделирования (слева) и исследуемого сетевого графика (справа) с зараженными узлами, отмеченными красным цветом. Потребовалось около 500 шагов агента, чтобы достичь этого состояния в этом пробеге. Журналы показывают, что многие попытки действий потерпели неудачу, некоторые из-за того, что трафик был заблокирован правилами брандмауэра, некоторые из-за использования неправильных учетных данных. В реальном мире такое неустойчивое поведение должно быстро вызвать тревогу, и защитная система XDR, такая как Microsoft 365 Defender, и система SIEM/SOAR, такая как Azure Sentinel, быстро отреагируют и вытеснят злоумышленника.
Такой игрушечный пример позволяет создать оптимальную стратегию для атакующего, который предпринимает всего около 20 действий, чтобы полностью завладеть сетью. Человеку требуется в среднем около 50 операций, чтобы выиграть эту игру с первой попытки. Поскольку сеть статична, после многократного воспроизведения человек может запомнить правильную последовательность вознаграждающих действий и быстро определить оптимальное решение.
Для целей бенчмаркинга мы создали простую игрушечную среду переменных размеров и испробовали различные алгоритмы подкрепления. Следующий график суммирует результаты, где ось Y-это количество действий, предпринятых для полного владения сетью (чем меньше, тем лучше) в течение нескольких повторяющихся эпизодов (ось X). Обратите внимание, как некоторые алгоритмы, такие как Q-learning, могут постепенно улучшаться и достигать человеческого уровня, в то время как другие все еще борются после 50 эпизодов!
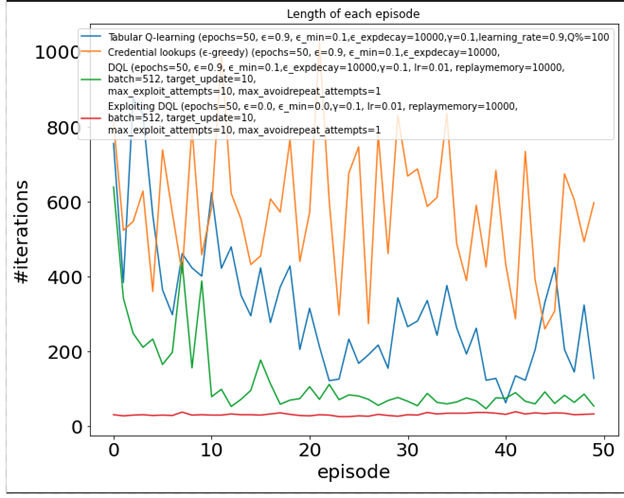
Рис. 6. Количество итераций по эпохам для агентов, обученных различным алгоритмам обучения с подкреплением
График кумулятивного вознаграждения предлагает другой способ сравнения, когда агент получает вознаграждение каждый раз, когда он заражает узел. Темные линии показывают медиану, в то время как тени представляют одно стандартное отклонение. Это еще раз показывает, как некоторые агенты (красный, синий и зеленый) работают заметно лучше, чем другие (оранжевый).
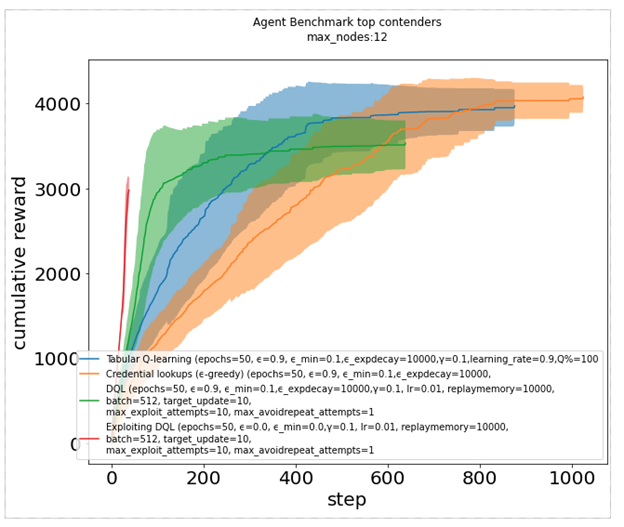
Рисунок 7. График кумулятивного вознаграждения для различных алгоритмов обучения подкреплению
Обобщение
Изучение того, как хорошо работать в фиксированной среде, не очень полезно, если усвоенная стратегия не приносит успеха в других средах—мы хотим, чтобы стратегия хорошо обобщалась. Наличие частично наблюдаемой среды предотвращает чрезмерное приспособление к некоторым глобальным аспектам или измерениям сети. Однако это не мешает агенту изучать не обобщаемые стратегии, такие как запоминание фиксированной последовательности действий по порядку. Чтобы лучше оценить это, мы рассмотрели набор сред различных размеров, но с общей сетевой структурой. Мы обучаем агента в одной среде определенного размера и оцениваем его на больших или меньших. Это также дает представление о том, как агент будет действовать в среде, которая динамично растет или сжимается, сохраняя при этом ту же структуру.
Чтобы хорошо работать, агенты теперь должны учиться на наблюдениях, которые не являются специфичными для экземпляра, с которым они взаимодействуют. Они не могут просто запомнить индексы узлов или любое другое значение, связанное с размером сети. Вместо этого они могут наблюдать временные особенности или свойства машины. Например, они могут выбрать наилучшую операцию для выполнения, основываясь на том, какое программное обеспечение присутствует на машине. Два графика совокупного вознаграждения ниже иллюстрируют, как один такой агент, ранее обученный на экземпляре размера 4, может очень хорошо работать на более крупном экземпляре размера 10 (слева) и взаимно (справа).
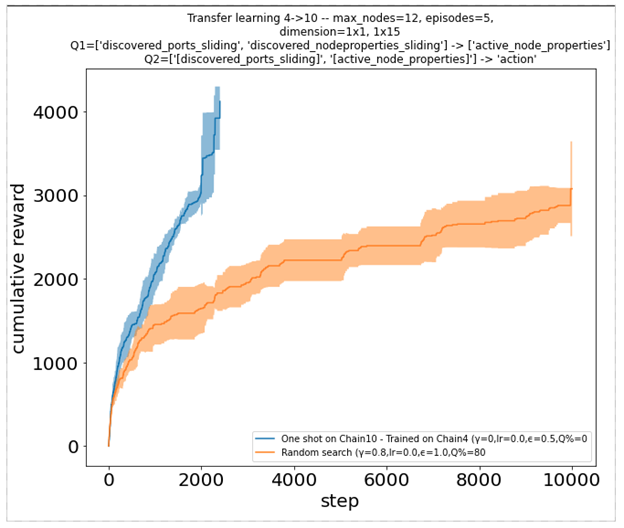
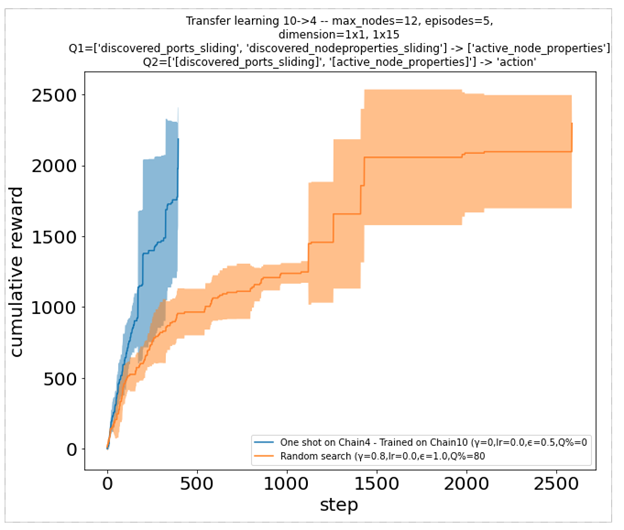
Рисунок 8. Функция кумулятивного вознаграждения для агента, предварительно обученного в другой среде
Приглашение продолжить изучение применения обучения подкреплению в области безопасности
Абстрагируясь от некоторой сложности компьютерных систем, можно сформулировать проблемы кибербезопасности как примеры проблемы подкрепления обучения. С помощью инструментария OpenAI мы могли бы построить высоко абстрактные модели сложных компьютерных систем и легко оценить современные алгоритмы подкрепления, чтобы изучить, как автономные агенты взаимодействуют с ними и учатся у них.
Потенциальной областью для улучшения является реалистичность моделирования. Моделирование в CyberBattleSim является упрощенным, что имеет свои преимущества: его высоко абстрактная природа запрещает прямое применение к реальным системам, обеспечивая тем самым защиту от потенциального гнусного использования автоматизированных агентов, обученных с его помощью. Это также позволяет нам сосредоточиться на конкретных аспектах безопасности, которые мы стремимся изучить и быстро поэкспериментировать с новейшими алгоритмами машинного обучения и искусственного интеллекта: в настоящее время мы фокусируемся на методах бокового перемещения с целью понимания того, как топология и конфигурация сети влияют на эти методы. Имея в виду такую цель, мы чувствовали, что моделирование реального сетевого трафика не является необходимым, но это существенные ограничения, которые могут быть рассмотрены в будущем.
Что касается алгоритмической стороны, то в настоящее время мы предоставляем только некоторые базовые агенты в качестве базовой линии для сравнения. Нам было бы любопытно узнать, как современные алгоритмы обучения подкреплению сравниваются с ними. Мы обнаружили, что большое пространство действий, присущее любой компьютерной системе, представляет собой особую проблему для обучения с подкреплением, в отличие от других приложений, таких как видеоигры или управление роботами. Обучение агентов, которые могут хранить и извлекать учетные данные, является еще одной проблемой, с которой сталкиваются при применении методов обучения с подкреплением, когда агенты обычно не имеют внутренней памяти. Это другие области исследований, где моделирование может быть использовано для целей бенчмаркинга.
Код, который мы выпускаем сегодня, также может быть превращен в онлайн-соревнование Kaggle или AICrowd и использован для тестирования производительности новейших алгоритмов подкрепления в параметризуемых средах с большим пространством действий. Другие области, представляющие интерес, включают ответственное и этичное использование автономных систем кибербезопасности. Как можно спроектировать корпоративную сеть, которая дает внутреннее преимущество агентам-защитникам? Как можно проводить безопасные исследования, направленные на защиту предприятий от автономных кибератак, предотвращая при этом гнусное использование таких технологий?
С помощью CyberBattleSim мы просто царапаем поверхность того, что, по нашему мнению, является огромным потенциалом для применения подкрепляющего обучения к безопасности. Мы приглашаем исследователей и специалистов по обработке данных опираться на наши эксперименты. Мы рады видеть, что эта работа расширяется и вдохновляет на новые и инновационные подходы к решению проблем безопасности.
Уильям Блюм
Источник: www.microsoft.com