Распространяющиеся ошибки меток в наборах данных ML дестабилизируют бенчмарки
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-04-06 13:40

Никак не можете понять, почему ваша нейросеть ошибается при распознавании объектов? Возможно, ей просто не повезло с «учебниками».
Группа исследователей из Массачусетского технологического института провела анализ популярных датасетов и выявила, что примерно в 3,5% случаев объекты на изображениях там размечены неверно. Например, регулярно встречаются ошибки с породами собак, видами рыб и даже с определением цифр. Больше всего проблем было обнаружено в датасете QuickDraw — больше 10% ошибок!
Как следствие, эти неточности, допущенные ещё на этапе разметки объектов, приводят к ошибкам во время работы нейросети. К счастью, исследователи не только указали на существующие ошибки, но и исправили их, опубликовав доработанные датасеты.
Хорошо известно, что наборы данных ML не имеют идеальной маркировки. Но не было много исследований, чтобы систематически количественно оценить, насколько подвержены ошибкам наиболее часто используемые наборы данных ML в масштабе. Предыдущая работа была сосредоточена на ошибках в поездных наборах наборов данных ML. Но ни в одном исследовании не рассматривалась систематическая ошибка в наиболее цитируемых тестовых наборах ML-наборах, на которые мы полагаемся для оценки прогресса в области машинного обучения.
Здесь мы алгоритмически определили и проверили на людях, что действительно существуют распространенные ошибки меток в десяти наиболее цитируемых тестовых наборах, а затем изучили, как они влияют на стабильность тестов ML. Здесь мы суммируем наши выводы вместе с ключевыми выводами для практикующих мл.
Ошибки в высоко цитируемых тестовых наборах бенчмарков
Просмотрите все ошибки меток во всех наборах данных объемом 10 мл по адресу labelerrors.com (демо-версии ниже):
Ключевые выводы из распространяющихся ошибок этикеток
Насколько распространенными являются ошибки в тестовых наборах ML?
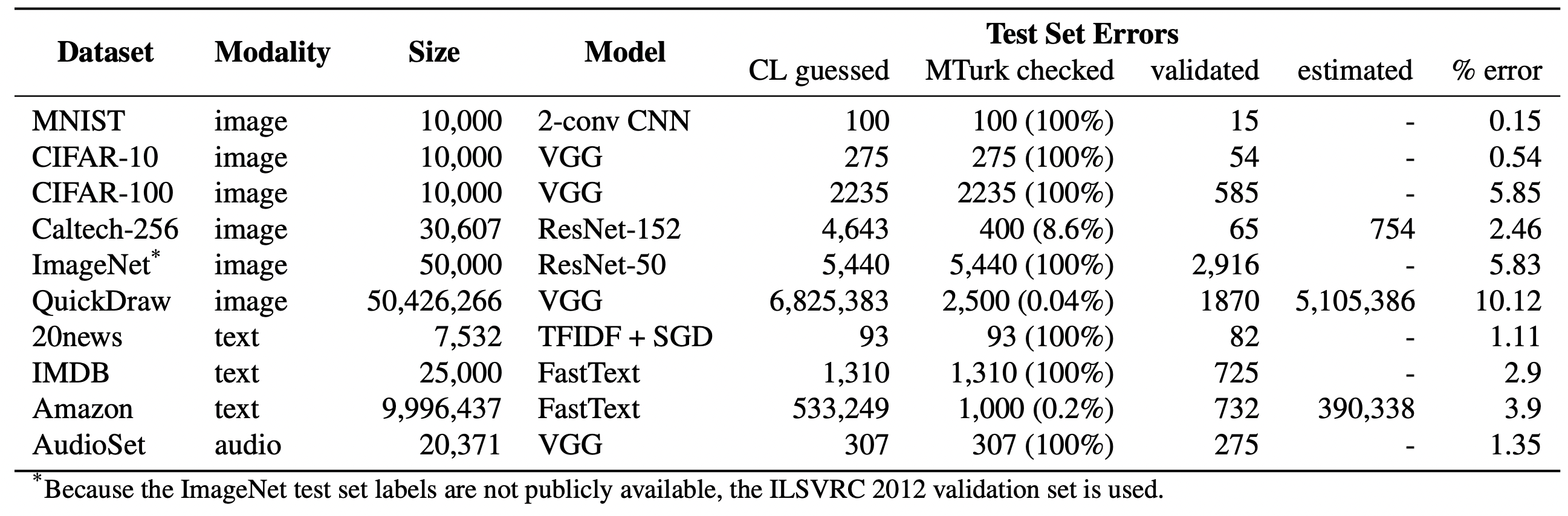
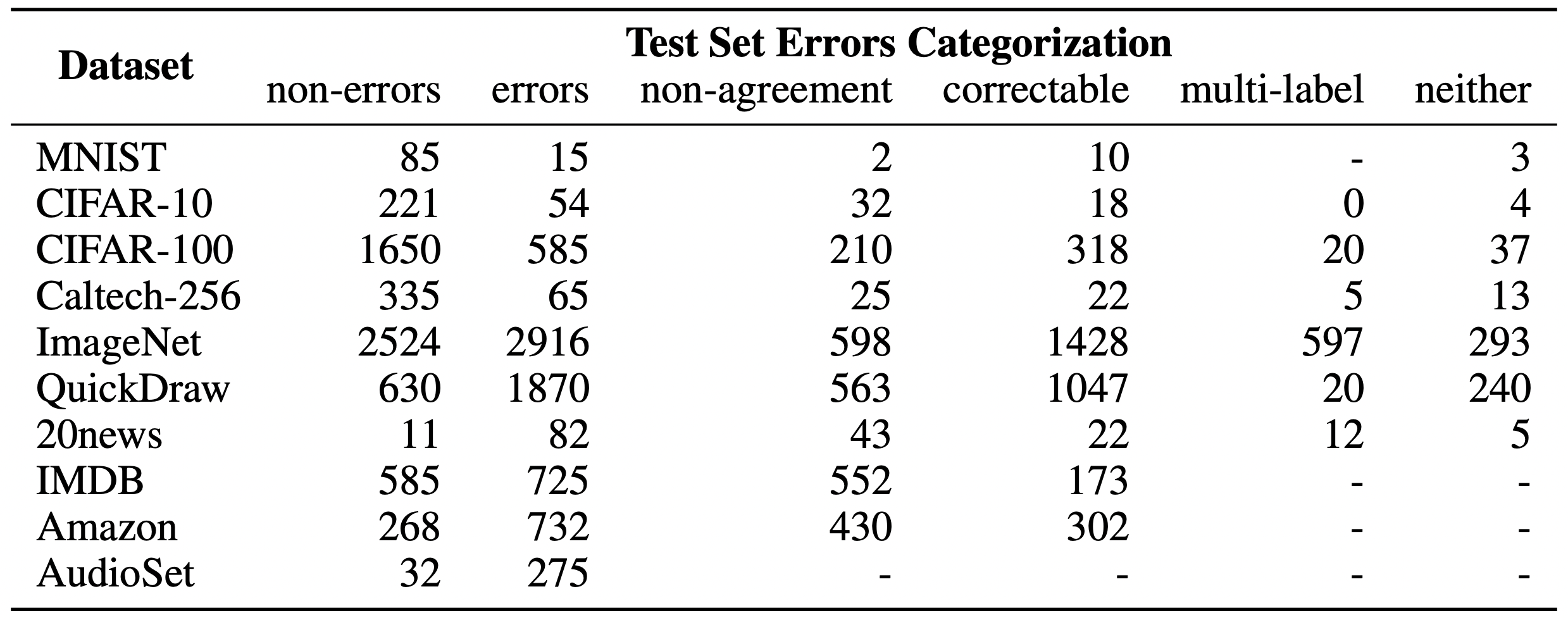
- Мы оцениваем в среднем 3,4% ошибок в 10 наборах данных, где, например, 2916 ошибок меток составляют 6% тестового набора CIFAR-100 и ~390 000 ошибок меток составляют ~4% набора данных Amazon Reviews. Даже набор данных MNIST, считающийся безошибочным и проверенный в десятках тысяч рецензируемых публикаций ML, содержит 15 (проверенных человеком) ошибок меток в тестовом наборе.
Из 10 наборов данных мл, которые вы просмотрели, в каком было больше всего ошибок?
- Тестовый набор QuickDraw содержит более 5 миллионов ошибок, составляющих около 10% тестового набора. Просмотр ошибок меток QuickDraw.
Как вы обнаружили ошибки меток в наборах данных vision, text и audio?
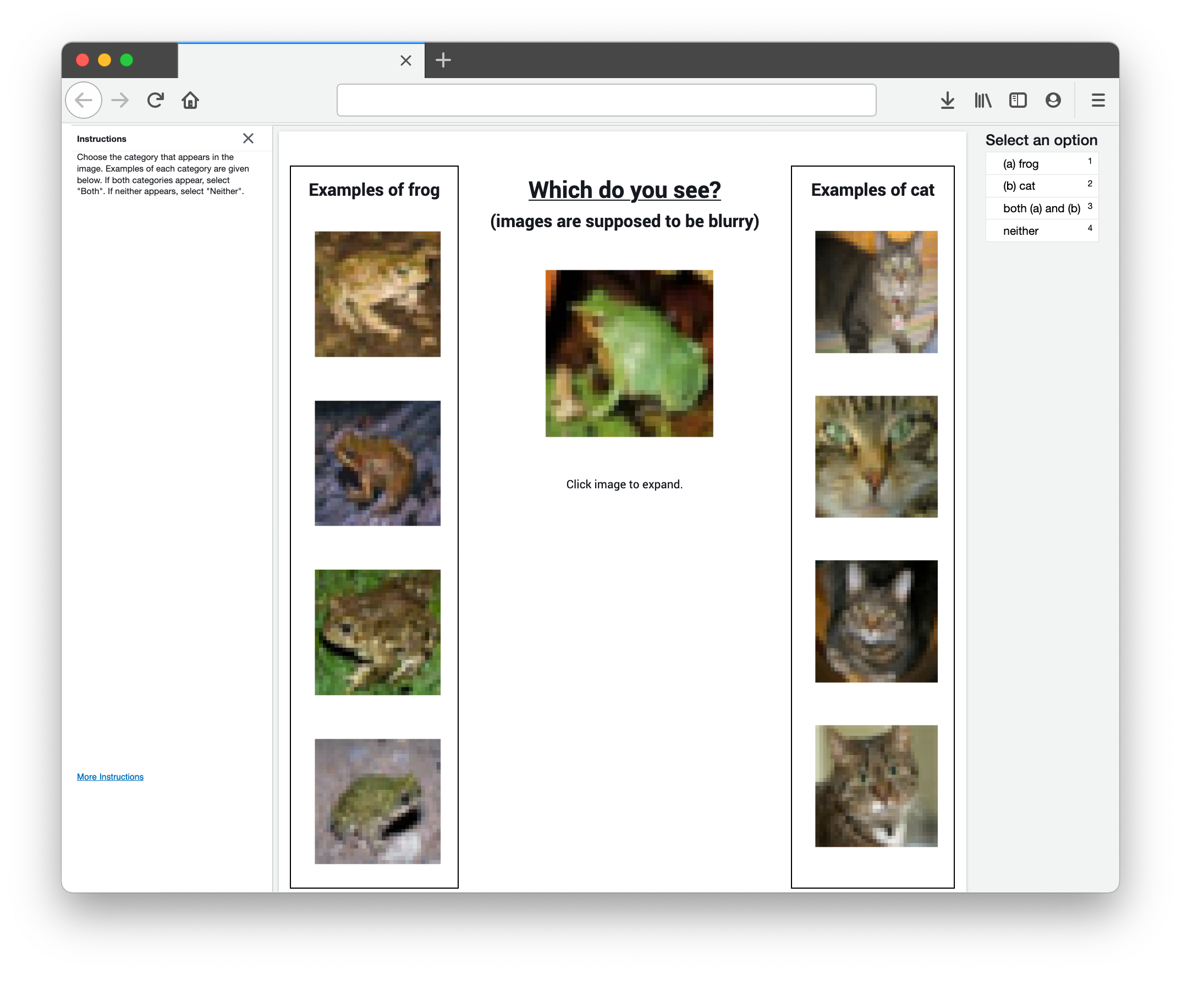
- Во всех 10 наборах данных ошибки меток идентифицируются алгоритмически с помощью уверенного обучения, а затем проверяются человеком с помощью краудсорсинга (54% алгоритмически помеченных кандидатов действительно ошибочно помечены). Структура уверенного обучения не связана с конкретной модальностью или моделью данных, что позволяет нам находить ошибки меток во многих типах наборов данных.
Каковы последствия распространяющихся ошибок меток тестовых наборов?
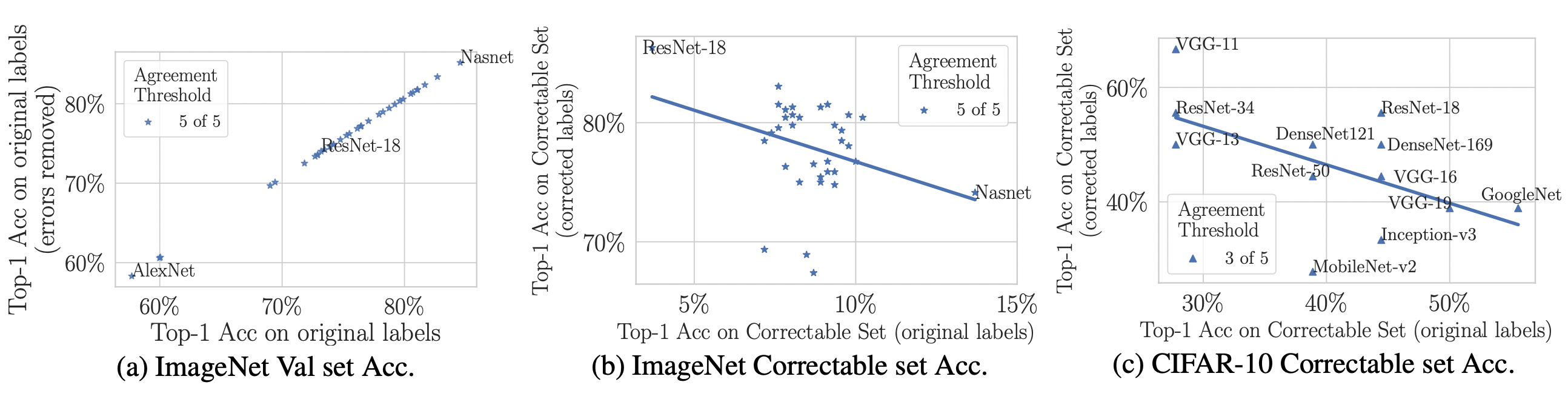
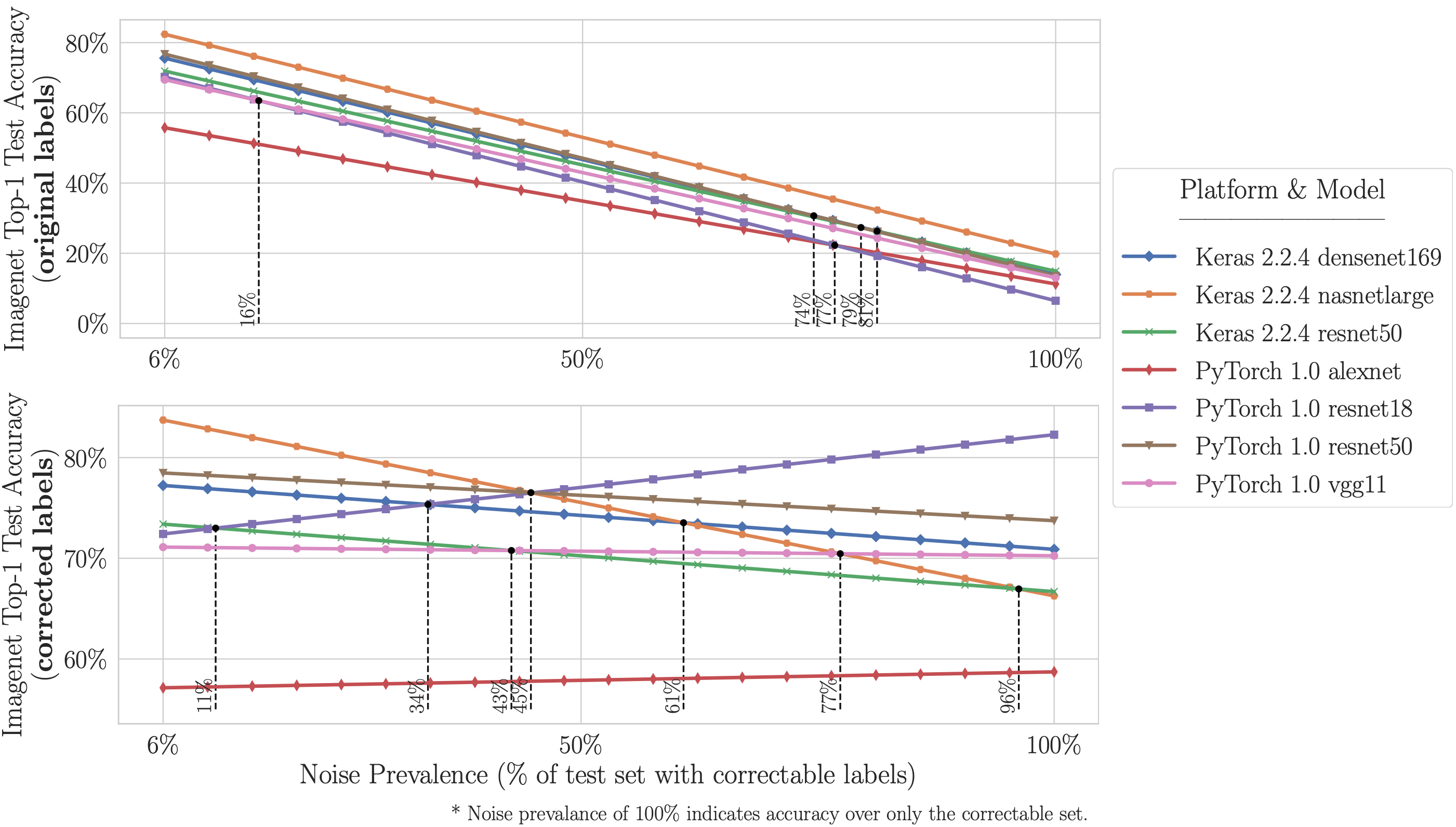
- Более высокая емкость/сложные модели (например, ResNet-50) лучше работают с исходными неправильно маркированными тестовыми данными (то есть с тем, что традиционно измеряется), но модели с более низкой емкостью (например, ResNet-18) дают более высокую точность на исправленных метках (то есть с тем, что на практике важно, но не может быть измерено без предоставленных нами вручную исправленных тестовых данных). Это, вероятно, происходит из-за того, что модели с более высокой производительностью перестраиваются на шум метки набора поездов во время обучения и/или перестраиваются на набор валидации/тестирования путем настройки гиперпараметров на наборе тестов (даже если набор тестов предположительно невидим).
Сколько шума может дестабилизировать бенчмарки ImageNet и CIFAR?
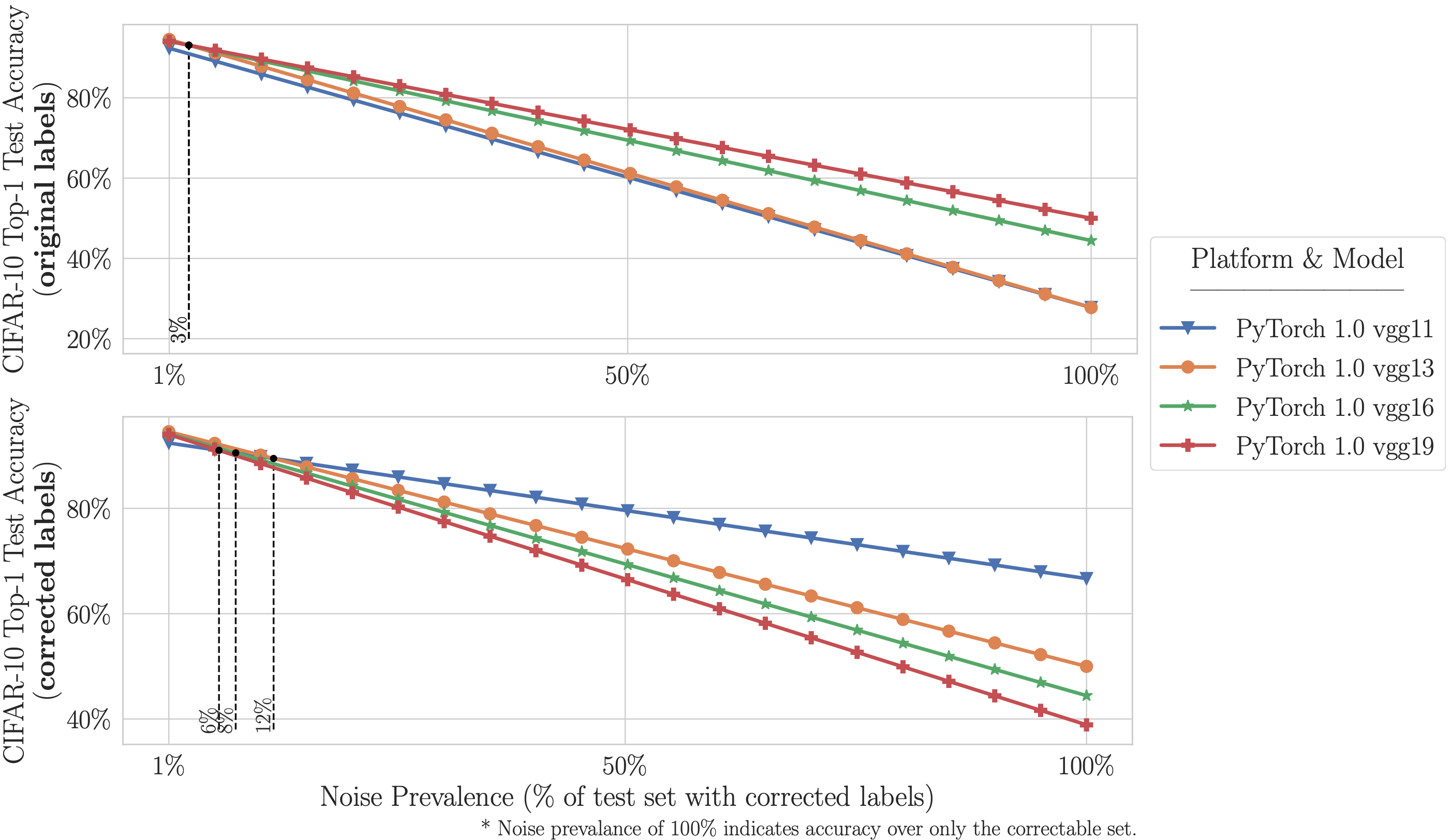
- На ImageNet с исправленными метками: ResNet-18 превосходит ResNet-50, если Распространенность неправильно маркированных тестовых примеров увеличивается всего на 6%. На CIFAR-10 с исправленными метками: VGG-11 превосходит VGG-19, если Распространенность неправильно маркированных тестовых примеров увеличивается на 5%.
Доступна ли очищенная версия каждого набора тестов?
- Да, [очищенные тестовые наборы ML здесь]. В этих очищенных наборах люди исправляли большую часть ошибок меток. Мы надеемся, что будущие исследования по этим тестам будут использовать эти улучшенные тестовые данные вместо первоначальных ошибочных меток.
Могу ли я взаимодействовать с ошибками меток в каждом наборе данных?
- Да! Ошибки из десяти тестовых наборов ML, которые мы проанализировали, можно просмотреть по адресу labelerrors.com. Чтобы услышать звуковые ошибки, выберите “Dataset: AudioSet.” Чтобы просмотреть ошибки естественного языка (текст), выберите набор данных из [“20news”, “IMDB” и "Amazon”]. Чтобы просмотреть ошибки компьютерного зрения (изображения), выберите один из вариантов [“MNIST”, “CIFAR-10”, “CIFAR-100”, “Caltech-256”, “ImageNet” и “QuickDraw”].
Являются ли ошибки маркировки точными на 100%?
- Результаты не идеальны. В некоторых случаях рабочие механического турка соглашаются на неправильный ярлык. Мы все еще, вероятно, фиксируем только нижнюю границу ошибки, учитывая, что мы проверили только небольшую часть наборов данных на наличие ошибок. Хотя наши исправленные этикетки не являются точными на 100%, при осмотре они кажутся значительно превосходящими оригинальные этикетки.
Что должны делать практикующие мл по-другому?
Традиционно практикующие ML выбирают, какую модель развертывать, основываясь на точности тестов — наши результаты советуют соблюдать осторожность здесь, предполагая, что оценка моделей по правильно помеченным тестовым наборам может быть более полезной, особенно для шумных реальных наборов данных. Мы предлагаем две рекомендации для практикующих мл:
- Исправьте метки вашего тестового набора (например, используя наш подход)
- чтобы измерить точность реального мира, о которой вы заботитесь на практике.
- чтобы выяснить, страдает ли ваш набор данных от дестабилизированных бенчмарков.
- Рассмотрите возможность использования более простых/меньших моделей для наборов данных с шумными метками
- особенно для приложений, обученных/оцененных с помощью помеченных данных, которые могут быть более шумными, чем наборы данных золотого стандарта ML Benchmark.
Поиск ошибок меток
Человеческая валидация ошибок меток
Влияние ошибок тестовых меток на контрольные показатели
Нестабильность контрольных показателей мл
Узнать больше
Подробное обсуждение этой работы доступно в [нашей статье arXiv].
Эти результаты основаны на обширной работе , проделанной в Массачусетском технологическом институте по созданию уверенного обучения-подполя машинного обучения, которое рассматривает наборы данных для поиска и количественной оценки шума меток. В этом проекте уверенное обучение используется для алгоритмической идентификации всех ошибок метки до проверки человеком.
Мы упростили другим исследователям репликацию их результатов и поиск ошибок меток в их собственных наборах данных с помощью cleanlab, пакета python с открытым исходным кодом для машинного обучения с шумными метками.
Сопутствующая Работа
- Введение в уверенное обучение: [просмотр этого поста]
- Введение в пакет cleanlab Python для ML с шумными метками: [просмотреть этот пост]
Подтверждения
Эта работа была частично поддержана финансированием MIT-IBM Watson AI Lab, MIT Quanta Labи MIT Quest for Intelligence. Мы благодарим Джесси Лин за ее помощь с ранними версиями этой работы (принятой в качестве рабочего документа на семинаре NeurIPS 2020 Workshop on Dataset Curation and Security).
Была ли эта статья полезной? Можно ли его улучшить? Что тебе понравилось? Комментарий ниже!
Источник: l7.curtisnorthcutt.com