Brain2Pix: полностью сверточная натуралистическая видео реконструкция мозговой активности
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-03-15 10:49

Восстановление сложного и динамичного зрительного восприятия на основе мозговой активности остается одной из основных задач в применении машинного обучения к нейробиологии. Здесь мы представляем новый метод реконструкции натуралистических изображений и видео из очень больших функциональных магнитно-резонансных данных с одним участником, который использует недавний успех сетей преобразования изображений в изображения. Это достигается за счет использования пространственной информации, полученной из ретинотопических отображений по всей зрительной системе. Более конкретно, мы сначала определяем, какое положение каждый воксель в конкретной области интереса будет представлять в поле зрения на основе его соответствующего местоположения рецептивного поля. Затем 2D-изображение, представляющее мозговую активность в поле зрения, передается в полностью сверточную сеть "изображение-изображение", обученную восстанавливать исходные стимулы с помощью потери функции VGG с помощью состязательного регуляризатора. В наших экспериментах мы показываем, что наш метод предлагает значительное улучшение по сравнению с существующими методами реконструкции видео.
Введение
Большой интерес системной нейробиологии представляет понимание того, как сенсорная информация представлена в паттернах нейронной активности. Декодирование визуальных стимулов из нейронной активности с помощью глубокого обучения является перспективным подходом для приближения нас к такому пониманию. Последние достижения позволяют успешно декодировать простые статические изображения из данных мозга [9,43, 28, 30,16, 23,11,39]. Реконструкция естественных фильмов значительно более сложна [32], но важна, учитывая, что нейроны реагируют на сигналы, которые разворачиваются как в пространстве, так и во времени [31Трудности с реконструкцией природных фильмов в значительной степени обусловлены ограниченной временной информацией, предоставляемой методами визуализации, такими как фМРТ, а также сложной динамикой природного мира, которую должна изучать модель.
Сверточные модели изображения к изображению недавно достигли беспрецедентных результатов в нескольких задачах, таких как семантическая сегментация [27, 34, 33, 26,48], передача стиля [50,10,40, 21], раскрашивание [46, 19, 47] и сверхразрешение [22, 5, 49Сверточные сети типа "изображение-изображение" имеют большое преимущество в сохранении топографии входных изображений во всех слоях сети. Следовательно, сеть не нуждается в изучении переназначения между местоположениями и может сосредоточиться на обработке локальных объектов. Восстановление воспринимаемых естественных образов из реакций мозга можно рассматривать как форму задачи "изображение-изображение", поскольку зрительная кора обрабатывает информацию топографически организованным образом [13,14, 20] таким образом, что топология входных изображений сохраняется в каждой визуальной области. Ретинотопическое картирование зрительно-рефлекторных нейронов выявляет взаимосвязи между зрительным полем и его кортикальной репрезентацией у отдельных испытуемых и раскрывает многие важные аспекты зрительной коры у различных видов [17, 6Однако это не так просто использовать в архитектуре ConvNet типа "образ-образ". Сам кортекс можно грубо рассматривать как пару топологических сфер, встроенных в трехмерное пространство. В это кортикальное пространство встроено несколько отдельных зрительных представлений, соответствующих нескольким зрительным областям (например, V1,V2,V3). Кроме того, эти представления искажаются геометрией коры головного мозга и неравномерной выборкой различных участков зрительного поля. Таким образом, не существует естественного способа построения сверточной архитектуры, которая использует характер изображения к изображению проблемы, сохраняя топографию между воксельными откликами и яркостью и цветом пикселей.
В этой работе мы используем картирование рецептивного поля зрительных областей для преобразования воксельных реакций, определенных в мозге, в активации в пиксельном пространстве. Функциональные визуальные области идентифицируются с помощью функциональных локализаторов. Воксельные активации каждой области затем преобразуются в изображения с помощью отображения рецептивного поля. Важно отметить, что эти образы (визуальные репрезентации) действительно имеют пиксельное соответствие с изображениями, используемыми в качестве стимулов. Затем мы преобразуем эти визуальные представления в реалистичные изображения с помощью U-сети "изображение-изображение", обученной с использованием комбинации пиксельных, функциональных и состязательных потерь.
Сопутствующая работа
Недавняя работа по реконструкции изображений по данным фМРТ продемонстрировала успех использования глубоких нейронных сетей (Днн) и генеративных состязательных сетей (Ган) в нейронном декодировании [15, 11,45,39,12,41,42]. Например, [39] использовал GAN для восстановления естественных изображений в оттенках серого, а также более простых рукописных символов. Совсем недавно, [41] показали, что даже при ограниченном наборе данных - порядка тысяч по сравнению с миллионами, к которым привыкло поле, - можно было обучить сквозную модель реконструкции естественного стимула изображения, обучив GAN с дополнительной потерей признаков высокого уровня. Их реконструкции соответствовали нескольким высокоуровневым и низкоуровневым характеристикам представленных стимулов. Однако для натуралистических видеостимулов сопоставимых результатов пока не достигнуто. Самое последнее заметное исследование реконструкции видео, проведенное [12] использовал вариационный автокодер и смог реконструировать только очень низкоуровневые свойства изображений, где реконструкции в лучшем случае напоминали тени или силуэты стимулирующих изображений.
Простейший способ применения Конвнетов к воксельным ответам фМРТ-это рассматривать срезы фМРТ как отдельные изображения, сложенные в размер канала [36]. Однако эти изображения не учитывают топографию нейронных репрезентаций и содержат большую долю невосприимчивых вокселов, соответствующих белому веществу и спинномозговой жидкости. Это приводит к тому, что большая часть контраста изображений зависит от несущественных анатомических факторов. Другая возможность заключается в использовании пространственных 3D-сверток на объеме мозга [1Этот метод имеет преимущество сохранения топографии нейронных реакций, но в остальном имеет те же проблемы, что и 2D-подход. Эти недостатки делают такие методы непригодными для декодирования и реконструкции мозга. Более жизнеспособной стратегией является отображение воксельных ответов на сетку, представляющую кортикальную поверхность [8], и применение метода геометрического глубокого обучения [29, 7,4, 24].
Материал и методы
Наша архитектура brain2pix имеет два компонента: 1) отображение рецептивного поля, которое преобразует мозговую активность зрительных областей в тензор в пиксельном пространстве, используя топографическую организацию зрительной коры; 2) сеть pix2pix, которая преобразует мозговые реакции в пиксельном пространстве в реалистичные естественные изображения. Далее мы подробно опишем эти два компонента.
От вокселей к пикселям
Рецептивное отображение поля - это функция (потенциально много к одному), которая отображает трехмерную координату вокселов визуальной области в Декартовые координаты в пространстве стимулов. Эта координата определяется как область изображения, которая вызывает наибольший отклик в вокселе. Учитывая визуальный ROI, мы можем ссылаться на эти отображения, используя следующую нотацию:  где (r1r2,r3) - воксельные координаты, а (x, y) - пара координат в пространстве изображений. Поскольку визуальные области топографически организованы, эту карту можно рассматривать как приближенный гомеоморфизм (т. е. функцию, которая сохраняет топологию). Обратите внимание, что RF не учитывает метрическую структуру изображения, поскольку представление ямки раздувается, а периферия сжимается. Мы обозначим функцию, связывающую измеренную нейронную активацию (жирный ответ) с каждым вокселем как n(r1,r2,r3Используя отображение рецептивного поля, мы можем перенести эту карту активации в пиксельное пространство следующим образом:
где (r1r2,r3) - воксельные координаты, а (x, y) - пара координат в пространстве изображений. Поскольку визуальные области топографически организованы, эту карту можно рассматривать как приближенный гомеоморфизм (т. е. функцию, которая сохраняет топологию). Обратите внимание, что RF не учитывает метрическую структуру изображения, поскольку представление ямки раздувается, а периферия сжимается. Мы обозначим функцию, связывающую измеренную нейронную активацию (жирный ответ) с каждым вокселем как n(r1,r2,r3Используя отображение рецептивного поля, мы можем перенести эту карту активации в пиксельное пространство следующим образом:  где M(x’, y’) - число вокселов, которые соответствуют координатам (x’, y’). Эквалайзер. 1 ограничивается случаем точечных рецептивных полей. В более общем виде транспортная карта РФ может быть записана в виде линейного оператора:
где M(x’, y’) - число вокселов, которые соответствуют координатам (x’, y’). Эквалайзер. 1 ограничивается случаем точечных рецептивных полей. В более общем виде транспортная карта РФ может быть записана в виде линейного оператора:  где тензор веса W является (псевдо -) обратным линейной функции отклика коры головного мозга при однопиксельном моделировании. Эта вторая формулировка имеет то преимущество, что позволяет каждому вокселю вносить свой вклад в несколько пикселей и быть пригодным для обучения градиентному спуску.
где тензор веса W является (псевдо -) обратным линейной функции отклика коры головного мозга при однопиксельном моделировании. Эта вторая формулировка имеет то преимущество, что позволяет каждому вокселю вносить свой вклад в несколько пикселей и быть пригодным для обучения градиентному спуску.
В этой статье мы используем две стратегии для определения W. Первый подход состоит в том, чтобы применить готовую оценку рецептивного поля и использовать эквалайзер 1. Второй, более ориентированный на машинное обучение подход, заключается в изучении весовой матрицы вместе с сетью. Чтобы сохранить топографическую организацию, мы включаем обучаемую часть в качестве возмущения оценки рецептивного поля:  где
где  является дискретной Дельта-функцией и Весами
является дискретной Дельта-функцией и Весами  являются изучаемыми параметрами.
являются изучаемыми параметрами.
Сеть "изображение-изображение"
Вход в сеть pix2pix - это тензор, полученный путем укладки карт активации, по одной карте для каждой комбинации ROI и временного лага. Фактически, сеть должна интегрировать топографически организованную информацию,содержащуюся в нескольких слоях визуальной иерархии (V1, V2 и V3 в нашем случае), но также и ответы в разные временные лаги, поскольку смелый ответ вводит временной сдвиг.
Архитектура
Архитектура модели brain2pix вдохновлена архитектурой pix2pix [21], которая включает сверточный генератор на основе U-сети [34] и сверточный дискриминатор на основе Патчгана (Рис. 1). Первый и последний слои генератора являются соответственно сверточными и деконволюционными с четырьмя стандартными блоками U-netskip между ними. Все пять слоев дискриминатора являются сверточными с пакетной нормализацией и негерметичной функцией активации ReLU.

Рисунок 1.
А) визуализация архитектуры brain2pix. Во-первых, каждый отдельный воксель мозга фМРТ извлекается и сортируется по соответствующей области интереса (ROI). Каждый воксель отображается на визуальное пространство на основе ретинотопического отображения этого ROI, чтобы стать RFSimages. Входные данные для каждой выборки состоят из отклика в 5 временных точках (0,7 с), таким образом, входные каналы получаются путем объединения временного измерения. Генератор получает в качестве входных данных RFSimages, а затем выводит реконструкцию. Затем потери между этой реконструкцией и целью рассчитываются с учетом потерь vgg. Реконструкция также проходит через дискриминатор, объединенный с RFSimages. Потеря BCE выходного сигнала дискриминатора суммируется с потерей функции, которая затем возвращается обратно для обновления параметров генератора. Обучение дискриминатора это делается путем сравнения выходных данных дискриминатора на основе восстановленного изображения и целевого изображения (объединенного с RFSimages), используя потерю BCE. Б) пример результатов тестового набора. Реконструкция кадра из мозгового сигнала участника, наблюдающего эпизод Dr. Кто в фМРТ-сканере.
Дискриминатор был обучен отличать стимулы от их реконструкций, итеративно минимизируя функцию потерь с единственной состязательной потерей (двоичная кросс-энтропия) и используя буфер истории, чтобы побудить дискриминатор помнить прошлые ошибки.
Генератор был обучен преобразованию мозговых реакций на реконструкцию стимулов путем итеративной минимизации функции потерь с тремя взвешенными компонентами: i) потеря пикселей, которая была принята за абсолютную разницу между основными истинами и предсказаниями, ii) потеря признаков, которая была принята за Евклидово расстояние между предварительно обученными слоями 10 VGG признаков основных истин и предсказаний и iii) состязательная потеря, которая была принята за “обратную” от состязательной потери, которая использовалась для обучения дискриминатора.
Все модели были реализованы на Python с помощью фреймворка MXNet [3]. Они были обучены и протестированы на графических процессорах Nvidia GeForce 2080 Ti.
Оценка рецептивного поля
Рецептивные поля для дорсальных и вентральных зрительных областей V1, V2 и V3 оценивались управляемым данными способом с использованием нейронного информационного потока [37Срезы видео в оттенках серого были пропущены через три трехмерных сверточных слоя нейронной сети, соответствующих визуальной ROIs. Перед специфичными для ROI слоями использовался линейный слой с одним каналом 1 x 3 x 3, позволяющий изучать этапы предварительной обработки сетчатки и ЛГН. Среднее объединение применялось после каждого слоя для учета увеличения размеров рецептивного поля, временное измерение было усреднено до TR 700 мс перед применением моделей наблюдения, и пространственно-временные рецептивные поля были ограничены положительными. Для обучения этой нейронной сети была применена декомпозиция тензора низкого ранга для оценки векторов воксельного пространственного, временного и канального наблюдения (считывания), которые использовались для прогнозирования воксельной активности по тензорам активности нейронной сети. Местоположение рецептивного поля (x, y) для каждого вокселя затем оценивалось как его центр масс карт рецептивного поля низкого ранга.
Сбор данных
Мы использовали большой набор данных фМРТ из ответов одного участника на натуралистические стимулы [38]. Точные эксперименты, проведенные для получения этих данных, подробно описаны в оригинальном исследовании [38Короче говоря, участник фиксировался на фиксирующем кресте на экране во время просмотра 30 эпизодов Би-би-си "Доктор Кто". Видео были представлены в то время как смелый ответ был измерен от мозга в нескольких запусках; 121 запуск был использован для тренировочного набора и 7 запусков для тестового набора. Каждое испытание набора тестов повторялось 10 раз и в конечном итоге усреднялось по повторениям для оценки модели. Наши эксперименты проводились на предварительно записанных данных, которые строго соответствовали правилам безопасности данных (GDPR), а экспериментальные процедуры были одобрены соответствующими этическими комитетами.
Предварительная обработка данных
Перед использованием входных данных для обучения модели 3D-матрицы мозга были преобразованы в 2D-изображения сигналов рецептивного поля (RFSimages) в два основных этапа. Во-первых, области интересов (ROI) были выбраны из мозга (V1, V2, V3), основываясь на их соответствующих масках. Во-вторых, каждый воксель в этой области мозга был нанесен на соответствующее ему визуальное пространство на основе ретинотопической карты. Размер 2D RFSImages был изменен до 96 x 96 пикселей и разделен пятью временными каналами (TRs) и количеством областей мозга (V1, V2, V3).
Видео были уменьшены пространственно (96 x 96 x 3) и временно, чтобы соответствовать TRs записей фМРТ (один кадр каждые 0,7 с). В результате было получено в общей сложности 7459 видеокадров для обучения и 1034 видеокадра для оценки модели. Учитывая гемодинамическую задержку, мы перестроили стимулы и сигналы мозга таким образом, чтобы текущие сигналы соответствовали стимулам, которые были представлены на 4 временных шага раньше, позволяя временное окно задержки 2,8 с - 5,4 с. Наконец, каждый кадр претерпел трансформацию рыбьего глаза, которая имитирует биологический эксцентриситет сетчатки [2Центры рецептивного поля, которые мы использовали для отображения мозговых сигналов в зрительном пространстве, были основаны на образах, прошедших эту трансформацию.
Экспериментальное проектирование
Мы сравнили нашу окончательную модель с альтернативными моделями реконструкции. Это включало в себя базовое сравнение, где наша модель сравнивается с традиционными моделями. Поскольку мы хотели сосредоточиться на ранних визуальных областях, мы также обучили нашу модель на V1, V2 и V3 индивидуально (что мы назвали экспериментом ROI). Наконец, мы проверили, является ли наша модель устойчивой к различным абляциям.
Во всех экспериментах использовались одни и те же четыре оценочные метрики: коэффициент корреляции произведение-момент Пирсона (corr.) и Евклидово расстояние (dist.) между признаками тестовых стимулов и их реконструкциями. Объекты были извлечены из слоев pool2, pool5 и fc6 модели AlexNet [25] и модели C3D [44]. Обе модели были предварительно обучены на ImageNet [35]. Дополнительные сведения об экспериментах, дополнительные результаты и ссылка на исходный код приведены в дополнительных материалах.
Результаты
Эксперименты
Эта статья состоит из 7 экспериментов: 1) архитектура brain2pix, обученная на синтетических данных с фиксированными местоположениями рецептивного поля, 2) обучение brain2pix с использованием реальных данных фМРТ с фиксированным рецептивным полем (Fixed RF) для реконструкции 3) обучение brain2pix на реальных данных с обучаемыми рецептивными полями (LearnedRF) для реконструкции 4) обучение традиционных моделей для сравнения с моделью brain2pix (базовый эксперимент) 5) обучение brain2pix на данных фМРТ из различных областей мозга с фиксированным RF (эксперимент ROI) 6) удаление существенных компонентов из архитектуры brain2pix с фиксированным RF (эксперимент абляции) и 7) экспериментирование с различными размерами обучающих данных с фиксированным RF.
Brain2Pix на синтетических данных
Прежде чем экспериментировать с реальными данными, мы использовали синтетические данные для проверки осуществимости и настройки гиперпараметров brain2pix. Вместо того чтобы сопоставлять сигналы мозга на ROI в визуальном пространстве, мы сопоставили целевые стимулы в визуальном пространстве, используя тот же самый точный метод. Эта фильтрация целевых изображений с помощью радиочастотных центров дала нам одинаковое количество входных пикселей для модели в одном и том же месте. Однако их активация была основана не на реальных сигналах мозга, а на самом целевом изображении. Из этого мы получили очень четкие восстановительные изображения, которые подтвердили, что количество RF-пикселей, предоставленных ROIs V1 + V2 + V3, теоретически может нести достаточно пространственной информации для модели, чтобы генерировать реалистичные и точные результаты.
Варианты Brain2Pix
Варианты brain2pix отличались только тем, как они трансформировали мозговые реакции от объемного представления к представлению изображения.
FixedRF
Протокол для нашей основной модели заключается в использовании (фиксированных) оценок рецептивного поля. Как только сигналы мозга были нанесены на карту зрительного пространства и модель была собрана, мы запустили ее, чтобы получить реконструкции (см. рис. 2 и рис. 3 в разделе Brain2pix > Fixed RF). Результаты показывают отдельные кадры из фрагмента набора тестов Dr. Who. Рисунок содержит выборку кадров из тестового набора и соответствующие им реконструкции. Этот рисунок показывает, что модель успешно реконструировала кадры, которые содержали формы головы, силуэты, выражения лица, а также объекты (например, белое одеяло в кадрах 289-292). На рисунке также изображен плавный переход между кадрами, что позволяет хорошо реконструировать видеоклипы. Таблица 1 и таблица 2 показаны количественные результаты работы модели под B2P-fixedRF. Эта модель содержит самые высокие значения корреляции для большинства слоев объектов, однако для значений расстояний только один слой объектов показывает наилучшие результаты.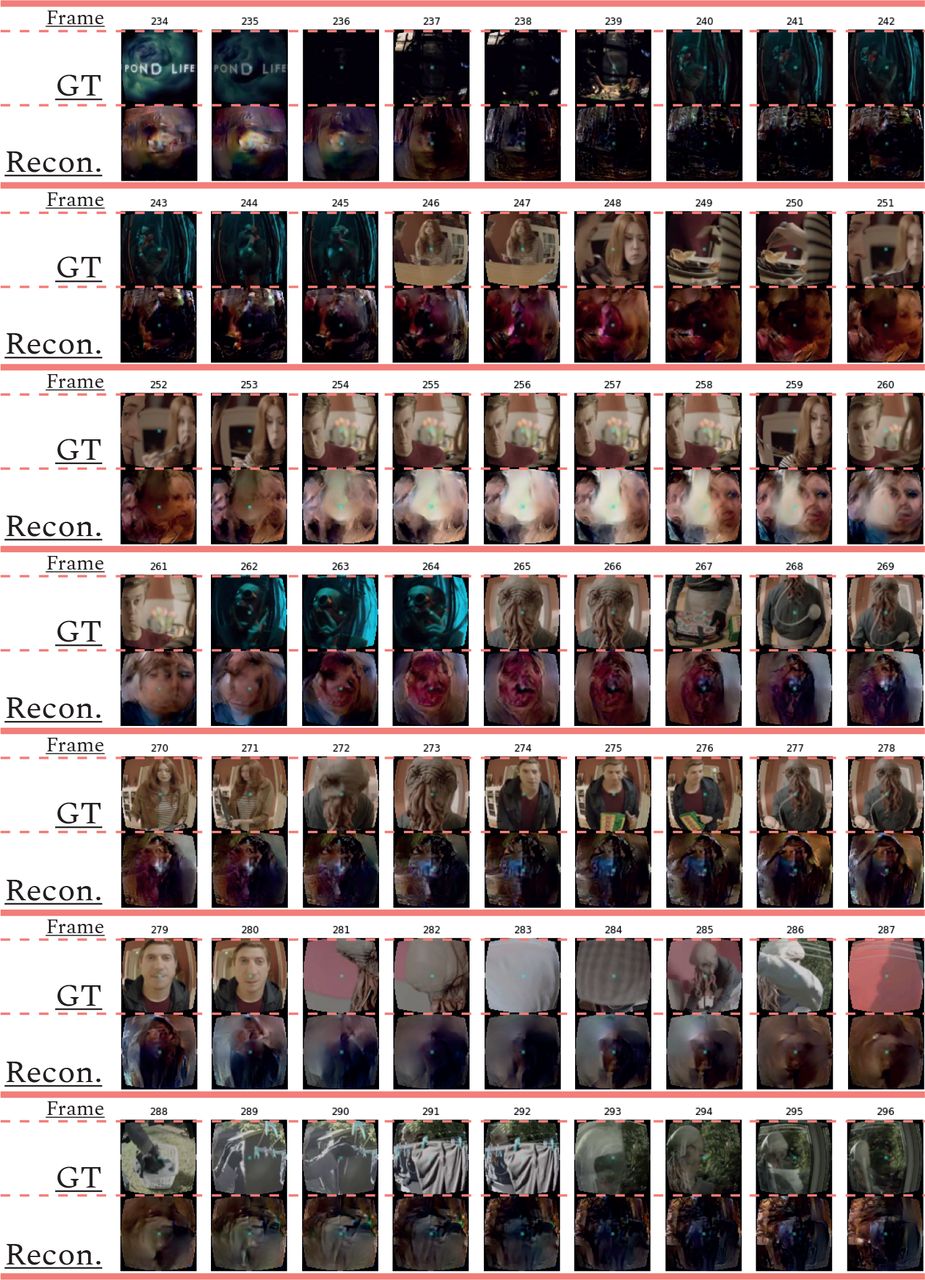
Рис. 2. Последовательность реконструированных кадров
последовательная последовательность кадров из видеофрагмента тестового набора данных (GT) и соответствующих реконструкций (Recon.). Числа в строках “фрейма” указывают на N-ю выборку набора данных.
Рис. 3. базовый эксперимент
Сравнение реконструкций brain2pix с базовыми моделями. Реконструкции brain2pix показаны в колонках 2 и 4, с их соответствующей основной истиной (GT) (колонка 3) и входными данными (колонки 1 и 5). Реконструкция базовых моделей показана в колонках 6 и 8 с соответствующими им ГТ (колонка 7).
Таблица 1.
Значения корреляции базового эксперимента : значения корреляции между реконструкциями базового эксперимента и целевыми объектами различных слоев, полученными при прохождении через предварительно обученную сеть (Alexnet и C3D). Здесь сравниваются модели brain2pix и базовые модели. Жирным шрифтом выделены самые высокие значения корреляции.
Таблица 2.
Базовые экспериментальные значения расстояний: расстояния между реконструкцией и целевыми объектами различных слоев, полученные при прохождении через предварительно обученную сеть (Alexnet и C3D). Здесь сравниваются модели brain2pix и базовые модели. Жирным шрифтом выделены самые низкие значения расстояний.
LearnedRF
Второй вариант (называемый изученным РЧ) использовал плотный слой для возмущения представления изображения в фиксированном РЧ варианте в зависимости от объемного представления. Реконструкция этой модели показана на рис. 3 в разделе Brain2pix > Learned RF. Мы обнаружили, что изученный вариант RF имеет самые высокие значения корреляции для слоев Alexnet pool2 и Alexnet fc6 (см. табл. 1 и табл. 2).
Различия в количественных и качественных результатах между learnedRF и fixedRF были невелики, что говорит о том, что обе модели RF фиксируют правильные топографические структуры. Оба варианта brain2pix содержат значительно более высокие показатели уровня вероятности (Р < 0,05; t-критерий Стьюдента) и значительно превосходят оба исходных уровня (Р < 0,05; биномиальный тест) (Рис.3).
Исходные данные
Базовый Уровень Нисимото
Мы сравнили наши результаты brain2pix с базовыми моделями, основанными на современных моделях реконструкции. Первая базовая линия основана на методе, введенном Нишимото и др. , который использует набор естественных изображений в качестве эмпирического априора [30, 32В нашем эксперименте мы использовали меньшее, но более целенаправленное естественное изображение, предварительно построенное из обучающего набора. Короче говоря, мы обучили модель кодирования, которая предсказывает смелую активность из обучающих выборок, которые мы использовали в качестве предварительного распределения. Затем мы построили апостериорную вероятность, усреднив входные данные, соответствующие 10 самым высоким коррелированным жирным шрифтом активности из предыдущего с тестовой выборкой.
Реконструкции, полученные в результате этого метода, показаны на рис. 3 в колонках под заголовком “Baselines > Nishimoto et al. > > Rec.”. в отличие от нашего метода, этот метод не использовал ретинотопическую информацию и переоснащен обучающими изображениями. Это привело к тому, что модель затрудняла реконструкцию вещей, которые не присутствуют в обучающем наборе, таких как характер потока. Кроме того, в отличие от результатов нашей модели, некоторые реконструкции даже не приближаются к цели перцептивно, например, 10 - я строка на рис. 3 где компьютер реконструируется, хотя предполагается, что это человек. Количественные результаты приведены в Табл. 1 и табл. 2, где указаны все более низкие значения корреляции и в основном более высокие расстояния (за исключением C3D pool5 и C3D fc6) по сравнению с нашей моделью. Корреляции, как правило, ниже, чем базовая линия Shen, но выше, чем модель только с FC-слоями.
Базовый Уровень Shen
Вторая базовая модель, которую мы обучили, - это генеративная состязательная сеть с потерей признаков, которая основана на модели сквозной реконструкции от Shen et al. [41]. Мы использовали модули генератора и дискриминатора, присутствующие в brain2pix, однако не строили RFSimages для ввода модели. Вместо этого эта базовая модель принимает необработанные данные фМРТ в качестве входных сигналов, поэтому она не использует топографическую информацию зрительной коры и пространственную природу стимула.
Реконструкция этого метода показана на рис. 3 ниже “исходные данные > Шен и соавт. > Зап.”. Хотя мы тренировались как на моделях с тем же количеством эпох и того же объема данных, количественные и качественные результаты показывают, что наша модель выигрывает у Шен Эт. Аль. basline модели (см. табл. 1 и табл. 2. Например, некоторый статический черно-белый шум присутствует в реконструкциях строк 2, 4, 6. Кроме того, характер потока не распознается. Эта модель, по-видимому, работала лучше, чем базовая линия Nishimoto et al. в наборе данных Doctor Who.
Наш анализ показывает, что наш метод превосходит оба исходных уровня. Детали реализации можно найти в исходных кодах этих базовых линий, которые включены в дополнительный материал в подпапке репозитория GitHub “dcgan_baseline” и “nishimoto_baseline” соответственно.
Эксперименты с окупаемостью инвестиций
Для того чтобы выделить роль интересующих нас регионов, мы провели серию последующих экспериментов, в которых Сети был присвоен только один ROI. Мы использовали фиксированную матрицу рецептивного поля (Eq. 1). Все экспериментальные детали идентичны основному эксперименту. Рисунок 4 показывает специфичные для ROI реконструкции. Реконструкции, основанные на V1, как правило, имеют более четкое пиксельное соответствие, в то время как некоторые высокоуровневые функции, такие как глобальное освещение, были захвачены не очень хорошо. Комбинированная модель brain2pix со всеми реконструкциями ROIs и V3, с другой стороны, смогла очень хорошо запечатлеть цветовой профиль сцен. Эти две модели генерировали изображения, которые в дальнейшем легко интерпретировались на высоком уровне информации, такой как существование человека в сцене и даже выражения на лицах людей в сценах. Интересно отметить, что ROIs не содержал высокоуровневых областей мозга, таких как латеральная затылочная кора, играющая большую роль в восприятии объекта, и веретенообразная область лица, специализирующаяся на обработке лица.

Рис. 4. эксперимент ROI
Реконструкции из фиксированного RF-метода brain2pix тренируются на различных участках мозга. Столбцы 1-3 показывают входные данные (in), реконструкции (re) и основные истины (gt) всех объединенных областей (V1-V3) соответственно. Столбцы 4-6 показывают эти результаты только для V1, столбцы 7-9 для V2 и, наконец, столбцы 10-12 являются результатами, принадлежащими модели, обученной только на V3.
Количественные результаты приведены в Табл. 3 и табл .4. Комбинированная модель работает существенно лучше, чем отдельные модели, причем модель V1 имеет наихудшую производительность. V2 и V3 были похожи друг на друга по количественным показателям. Плохая производительность ofV1, вероятно, связана с тем, что состязательные и функциональные потери имели больший вес в процессе обучения, смещая модель в сторону использования функций более высокого порядка для реконструкции.
Таблица 3.
Значения корреляции эксперимента ROI: корреляция между функциями Alexnet и C3D для эксперимента ROI. V1, V2, V3-это отдельные области интересов, а V1-V3-это все три визуальных слоя вместе взятые.
Таблица 4.
Значения расстояния эксперимента ROI: расстояния между объектами Alexnet и C3D для эксперимента ROI. V1, V2, V3-это отдельные области интересов (ROI), а V1-V3-это все три ROI вместе взятые.
Эксперименты по абляции
Исследования абляции были проведены для проверки влияния VGG-потерь и состязательных потерь на производительность модели (см. табл. 5 и табл. 6“Отсутствие состязательности” относится к brain2pix без потери дискриминатора, используя только потерю функции VGG для оптимизации модели. В этом случае абляции модель не училась реконструировать изображения, а скорее выводила квадратные паттерны, которые повторялись на всех изображениях. Вторая модель-это модель “без признаков”, которая была обучена без VGG-потерь, таким образом, используя только состязательные потери. Это привело к получению изображений, которые выглядят как реконструкции, но не приближаются к цели.
Таблица 5.
Значения корреляций абляционного эксперимента. Корреляция между особенностями Alexnet и C3D тестовых стимулов и их реконструкциями. Brain2pix сравнивается с двумя моделями либо без потери функций, либо без потери состязательности.
Таблица 6.
Значения расстояния эксперимента по абляции. Расстояния между реконструкцией и целевыми объектами различных слоев, полученными при прохождении через предварительно подготовленную сеть (Alexnet и C3D). Здесь сравниваются модели brain2pix и модели абляции.
Экспериментируйте с различными размерами данных
Наконец, мы хотели посмотреть, как работает модель, когда в сеть поступает меньше данных. Это было сделано путем обучения нашей модели на выбранном количестве кадров Doctor Who из обучающего набора. Полный тренировочный набор, который стоил ? 24 часов данных, был разделен на следующие части:  и используется для обучения модели в течение 50 эпох каждая. Затем реконструкции расщепленных данных сравниваются с полными данными стоимостью ~ 24 часа (также обученными на 50 эпохах). Реконструкции этого эксперимента показаны на Рис. 5. Хотя самый большой объем данных показывает лучшие реконструкции, мы все еще видим реконструкции, возникающие в результате меньшего объема данных, предполагающих, что нет абсолютной необходимости в 24-часовом объеме данных для достижения реконструкций с помощью модели brain2pix. Количественные результаты можно найти в таблице 7 и таблице 8.
и используется для обучения модели в течение 50 эпох каждая. Затем реконструкции расщепленных данных сравниваются с полными данными стоимостью ~ 24 часа (также обученными на 50 эпохах). Реконструкции этого эксперимента показаны на Рис. 5. Хотя самый большой объем данных показывает лучшие реконструкции, мы все еще видим реконструкции, возникающие в результате меньшего объема данных, предполагающих, что нет абсолютной необходимости в 24-часовом объеме данных для достижения реконструкций с помощью модели brain2pix. Количественные результаты можно найти в таблице 7 и таблице 8.

Рисунок 5. временной эксперимент
Реконструкции от метода brain2pix фиксированного RF натренированного на различном количестве данных по fmri после 50 эпох тренировки. Земная правда (GT), ~24hr весь dataset, ~19hr  , ~14hr является
, ~14hr является  , ~10hr является
, ~10hr является  , ~5hr является
, ~5hr является  из набора данных.
из набора данных.
Таблица 7.
Разделенные значения корреляции данных: модель была обучена на данных стоимостью 5, 10, 14, 19 и 24 часа.
Таблица 8.
Разделенные значения расстояния данных: модель была обучена на данных стоимостью 5, 10, 14, 19 и 24 часа.
Обсуждение
В этой статье мы представили новый метод реконструкции мозга, brain2pix, который использует топографическую организацию зрительной коры путем отображения активации мозга в линейное пиксельное пространство, где она затем обрабатывается полностью сверточной сетью изображений. Насколько нам известно, это первый сквозной подход, способный генерировать семантически точные реконструкции из натуралистического непрерывного видеопотока. Кроме того, было показано, что наш подход превосходит другие базовые методы декодирования.
Мы заметили несоответствия между корреляциями и результатами дистанции. Наша модель обеспечила самые высокие корреляции между всеми функциональными слоями Alexnet и c3d. Однако, принимая во внимание расстояния между этими объектами, наша модель иногда не дает наименьших расстояний. Это может означать, что малые расстояния между объектами всех слоев не имеют перцептивного значения.
Одна из следующих задач, которую мы можем попытаться решить, - это декодирование с более высокой частотой кадров, а не использование того же количества кадров, что и сигналы мозга. Кроме того, в наших текущих экспериментах мы сосредоточились главным образом на оптимизации нашей модели на основе ответов из ранних визуальных областей V1, V2, V3. Естественным продолжением текущей работы является распространение нашего внимания на области более высокого уровня в височной и теменной коре. Поскольку эти области обрабатывают крупнозернистую семантическую информацию, эксперименты, передающие их ответы на более глубокие слои сети, могут выявить реконструкции, обусловленные семантикой. Мы также можем применить эту модель к данным изображений.
Исследования нейронного декодирования имеют решающее значение для понимания функционирования человеческого мозга, что в целом приносит пользу области нейробиологии. Кроме того, алгоритмы нейронного декодирования составляют основной компонент интерфейсов мозг-компьютер (BCIs). Интерфейсы мозг-компьютер позволяют инвалидам выполнять задачи, которые они не смогли бы выполнить в противном случае, заменяя свои утраченные способности. Эти технологии могут варьироваться от коммуникационного интерфейса для заблокированного пациента до нейропротезирования конечности и многого другого. Хотя алгоритмы, которые мы разрабатываем и изучаем в этой статье, специализируются на реконструкции зрительных стимулов из реакций мозга, мы предполагаем, что предложенные принципы могут быть применены к различным приложениям с некоторыми адаптациями. Например, мы используем относительно медленный сигнал (жирный ответ), который отражает нейронные реакции, происходящие за несколько секунд до них. Критичная по времени система ИМК должна была бы использовать сигнал без таких задержек, чтобы хорошо работать. Хотя, по общему признанию, перспективность алгоритмов, реконструирующих внутренние или внешние перцепции, еще не полностью достигнута, ученые, пытающиеся извлечь информацию из мозга, должны обеспечить безопасность и конфиденциальность пользователей [18]. Будущие исследования должны обязательно следовать аналогичным строгим правилам, гарантируя только положительное влияние этих увлекательных методов, которые позволяют заглянуть в человеческий разум.
Источник: www.biorxiv.org