Могут ли человеческие эксперты предсказать растворимость лучше, чем компьютеры?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-02-03 10:25
В этом исследовании мы разрабатываем и проводим исследование, прося экспертов-людей предсказать водную растворимость лекарственных органических соединений. Мы исследуем, могут ли эти эксперты, привлеченные в основном из фармацевтической промышленности и научных кругов, соответствовать или превосходить предсказательную силу алгоритмов. Наряду с этим мы реализуем 10 типичных алгоритмов машинного обучения на одном и том же наборе данных. Лучший алгоритм, разновидность нейронной сети, известной как многослойный персептрон, дал RMSE 0,985 логарифмических единиц и R2 0,706. Мы не могли заранее предсказать относительный успех этого конкретного алгоритма. Мы обнаружили, что лучший индивидуальный человеческий предиктор генерирует почти одинаковое качество предсказания с RMSE 0,942 логарифмических единиц и R2 0,723. Набор алгоритмов содержал более высокую долю достаточно хороших предсказателей, девять из десяти по сравнению с примерно половиной людей. Мы обнаружили, что, как для людей, так и для алгоритмов, объединение отдельных предсказаний в консенсусный предиктор путем взятия их медианы создает отличную предсказательную способность. В то время как наш консенсусный человеческий предиктор достигал очень немного лучших показателей заголовков по различным статистическим показателям, разница между ним и консенсусным предиктором машинного обучения была как небольшой, так и статистически незначимой. Мы пришли к выводу, что специалисты-люди могут предсказывать водную растворимость молекул, похожих на лекарства, практически так же хорошо, как и алгоритмы машинного обучения. Мы находим, что для людей или алгоритмов объединение индивидуальных предсказаний в консенсусный предсказатель, взяв их медиану, является мощным способом извлечь выгоду из мудрости толпы.
Фон
Растворимость-это свойство химического растворенного вещества растворяться в растворителе с образованием однородной системы [1]. Растворимость зависит от используемого растворителя, а также от давления и температуры, при которых он был зарегистрирован. Растворимость в воде является одним из ключевых требований лекарств, гарантируя, что они могут всасываться через слизистую оболочку желудка и тонкого кишечника, в конечном итоге проходя через печень в кровоток. Это означает, что низкая растворимость связана с плохой биодоступностью [2]. Еще одно типичное требование к лекарству-доставка в таблетированной форме, опять же необходима адекватная растворимость. Таблетки сильно предпочтительны для внутривенной доставки лекарств, не в последнюю очередь из-за комплаентности пациента, простоты контроля дозы и самостоятельного введения. Существуют также проблемы токсичности, связанные с низкой растворимостью лекарств, например кристаллурия, вызванная образованием препарата в организме кристаллического твердого вещества [3]. Кроме того, плохая фармакокинетика и токсичность являются основными причинами неудач на поздних стадиях разработки лекарств. На самом деле 40% неудач лекарств происходят из-за плохой фармакокинетики [4].
Прогнозирование ключевых фармацевтических свойств становится все более важным с использованием высокопроизводительного скрининга (HTS). По мере того как HTS набирал популярность, кандидаты на лекарственные препараты имели все более высокую молекулярную массу и липофильность, что приводило к снижению растворимости, что считается преобладающей проблемой [5]. Очень важно, чтобы растворимость можно было понять и предсказать, чтобы уменьшить количество неудач на поздних стадиях из-за плохой биодоступности. Таким образом, возникает необходимость в способах точного прогнозирования как растворимости, так и основных свойств, часто называемых ADMET (абсорбция, распределение, метаболизм, элиминация и токсичность), в которых растворимость является ключевым фактором. Как способ увеличить успех разработки эффективных лекарств, популярное “правило пяти” Липинского было эмпирическим анализом атрибутов успешных лекарств, дающим рекомендации о том, что делает хорошую фармацевтику [2]. Он обнаружил, что эффективные препараты имеют молекулярную массу < 500, липофильность log P < 5 и количество атомов-доноров и акцепторов водородных связей < 5 и < 10 соответственно. Все чаще подходы in silico используются для прогнозирования свойств ADMET, чтобы оптимизировать количество кандидатов, проходящих через HTS.
Растворимость сама по себе трудно измерить. Как правило, журналы, логарифм по основанию 10 растворимости как указано в единицах моль/дм3, - говорится в сообщении. Существует множество различных определений растворимости и различных экспериментальных способов ее измерения, что может привести к плохой воспроизводимости измерений растворимости. Таким образом, при различных источниках данных, особенно когда точные детали методологии растворимости не определены, сбор высококачественного набора данных для прогнозирования растворимости может быть затруднен. Термодинамическая растворимость - это растворимость, измеряемая в равновесных условиях. Его можно определить с помощью метода встряхивания колбы или с помощью метода, подобного CheqSol [6], где равновесие ускоряется путем перемещения между супер - и субсыщенными растворами путем добавления небольших титров кислоты или щелочи. Задача растворимости [7, 8] использовала свой собственный заказной набор данных, измеряя внутреннюю термодинамическую растворимость воды с помощью метода CheqSol. Его авторы сообщили о высокой воспроизводимости и утверждали, что случайные ошибки составляют всего 0,05 логарифмических единиц. Несмотря на это, изучение литературы показывает, что общие ошибки в сообщаемых внутренних растворимостях лекарственно-подобных молекул составляют около 0,6–0,7 логарифмических единиц, как это обсуждалось Палмером и Митчеллом и ранее Йоргенсеном и Даффи [9, 10].
Это означает, что наилучшие возможные вычислительные предсказания будут иметь среднеквадратичные ошибки (RMSE), аналогичные экспериментальной ошибке в сообщаемых разрешимостях. Возможная точность предсказания будет зависеть от набора данных. Используя различные методы машинного обучения (ML), аналогичные используемым здесь, мы получили наилучший RMSE в 0,69 логарифмических единиц для тестового набора из 330 лекарственных молекул, 0,90 для другого тестового набора из 87 таких соединений, 0,91 для тестового набора с вызовом растворимости из 28 молекул и в той же работе 1,11 логарифмических единиц для десятикратной перекрестной валидации нашего набора DLS-100 из 100 лекарственных соединений [11,12,13,14,15]. Далее, мы определяем полезное предсказание как предсказание с RMSE, меньшим, чем стандартное отклонение экспериментальных растворимостей, чтобы избежать превосходства наивного присвоения средней экспериментальной растворимости всем соединениям [13].
Использование человеческих участников широко распространено в социальных науках, но остается относительно неиспользуемым инструментом в химии. Это во многом связано с характером вопросов, которые задают химики. Однако эксперты-люди часто используются в опросах о будущем исследовательских областей в науке, например, просят экспертов по изменению климата ответить на ряд заявлений о будущем этой области [16]. Точно так же в 2016 году были опубликованы результаты экспертного опроса о будущем искусственного интеллекта [17].
Мудрость толпы-это благотворный эффект привлечения множества независимых предсказателей для решения проблемы [18, 19]. Более 100 лет назад Гальтон описал соревнование на сельской ярмарке, где участники должны были оценить массу коровы. Некоторые предположения были сильно завышены, а другие-существенно занижены. Тем не менее, ансамбль оценок смог сделать точный прогноз, о чем сообщается в Nature [20]. Если некоторые предикторы, вероятно, будут очень ненадежными, то лучше использовать медианную оценку в качестве выбранного прогноза, избегая потенциально чрезмерного влияния нескольких нелепых догадок на среднее значение [21]. В химинформатике та же идея была использована Bhat et al. [22] для предсказания точек плавления, используя ансамбль искусственных нейронных сетей, а не толпу людей. Они сообщили о значительном повышении точности, причем ансамблевое предсказание было лучше, чем даже самая эффективная одиночная нейронная сеть. Использование нескольких независимых моделей также имеет фундаментальное значение для других ансамблевых предикторов, таких как Случайный лес, и для консенсусных методов восстановления пристыкованных белково–лигандных комплексов [23]. Использование мудрости толпы требует алгоритма или эксперимента, который может создать множество независимых предикторов, хотя и основанных, по существу, на одном и том же пуле входных данных.
Насколько нам известно, было только одно недавнее исследование, в котором для решения химических проблем использовались специалисты-люди. Орфанные лекарства-это потенциальные фармацевтические препараты, которые остаются коммерчески неразвитыми, часто потому, что они лечат болезни, слишком редкие для разработки коммерчески жизнеспособных лекарств фармацевтическими компаниями на конкурентном рынке. Регуляторы стимулируют разработку этих препаратов, допуская исключительность рынка; новый препарат для этих условий утверждается только в том случае, если он считается достаточно непохожим на продукты, уже имеющиеся на рынке. Оценка того, являются ли два соединения похожими или нет, занимает много времени для команды экспертов. Так, Франко и др. [24] задались вопросом, могут ли компьютеры воспроизводить решения экспертов. Человеческим специалистам показали 100 пар молекул и попросили количественно оценить их сходство. Их результаты были статистически сопоставлены со сходствами, вычисленными с помощью методов 2D-отпечатков пальцев. Авторы пришли к выводу, что методы 2D-отпечатков пальцев “могут предоставить полезную информацию” регулирующим органам для оценки молекулярного сходства.
Значительное значение для текущего проекта имеет проблема растворимости [7, 8]. Признавая трудности измерения растворимости в сочетании с ее жизненно важной важностью для разработки лекарственных препаратов, ее авторы сообщили о растворимости 100 лекарственно-подобных молекул с помощью высококачественного набора данных и последовательного использования метода CheqSol [6]. Затем исследовательскому сообществу было предложено представить прогнозы растворимости в воде еще 32 соединений, которые были измерены собственными силами, но не были представлены. Впоследствии сообщенные результаты этой задачи дали меру уровня техники в прогнозировании растворимости [8]. Тем не менее, результат этого слепого вызова был бы более интересным и более полезным, если бы участников попросили предоставить подробную информацию о вычислительных методах и любых экспериментальных данных за пределами обучающего набора, которые они использовали в своих прогнозах.
Машинное обучение-это подмножество Искусственного интеллекта (ИИ), где модели могут изменяться при воздействии новых данных [25]. В общем случае можно использовать свойства большого обучающего набора для предсказания свойств обычно меньшего тестового набора. Машинное обучение нашло множество применений от распознавания изображений и обнаружения вторжений до коммерческого использования в интеллектуальном анализе данных [26,27,28]. В химии применение машинного обучения широко распространено при открытии лекарств, и оно может быть использовано для обнаружения токсичности, прогнозирования свойств ADMET или получения структурно–активных связей (SAR) [29,30,31,32,33,34]. Контролируемые задачи машинного обучения можно разделить на классификацию и регрессию. В классификационных моделях предсказываемым свойством является категориальная переменная, и предсказание заключается в том, к какому из этих классов следует отнести новый экземпляр, например к растворимому или нерастворимому. Регрессионные задачи имеют дело с предсказанием непрерывных переменных, например log S. В химических приложениях машинного обучения задача обычно состоит из двух частей: во-первых, кодирование молекулярной структуры в компьютере и, во-вторых, поиск алгоритмического или математического способа точного отображения кодировок структур на значения или категории выходного свойства [21, 35]. Кодирование обычно состоит из молекулярных дескрипторов, также известных как признаки или атрибуты. Существуют тысячи используемых дескрипторов, начиная от тех, которые получены исключительно из химической структуры, таких как количество атомов каждого элемента в молекуле и топологические и электронные индексы, до экспериментально полученных величин, таких как log P или точка плавления [36].
Методы
Набор данных и дескрипторы
Наш набор данных представляет собой тот же набор из 100 лекарственных молекул, что и в предыдущей работе нашей группы, который мы называем набором DLS-100 [13,14,15]. Мы выбрали это, потому что это удобный набор высококачественных данных, для которых у нас есть эталон производительности других вычислительных методов. Примерно две пятых молекул были измерены их растворимость с помощью метода CheqSol [7, 8, 37, 38], а остальные данные были получены из небольшого числа, насколько мы можем судить, в целом достоверных источников [39,40,41,42,43]. Все наши данные являются внутренними водными растворимостями, которые соответствуют растворимости только нейтральной формы, как и наши предыдущие исследования растворимости [9, 11,12,13, 37, 44, 45]. Для нескольких молекул должен был быть сделан несколько произвольный выбор между слегка различными цитируемыми в литературе растворимостями.

Для классификации молекул было применено решение на основе машинного обучения https://indev.pro/services/machine-learning
Молекулы были разделены на две группы: 75 в тренировочном наборе и 25 в тестовом. Разделение было сделано при следующих условиях: ни одна молекула в тестовом наборе вышеупомянутой Проблемы растворимости не была бы в нашем тестовом наборе, если бы участники были вовлечены в Проблему растворимости; самые известные фармацевтические препараты, такие как парацетамол, были помещены в обучающий набор; и наименее растворимые и наиболее растворимые одиночные молекулы также были помещены в обучающий набор, чтобы избежать необходимости экстраполяции. После того как эти требования были выполнены, остальная часть раскола была выбрана наугад. Дополнительный файл 1 показывает названия и структуры 75 соединений в обучающем наборе, их растворимость и литературный источник для определения растворимости; Дополнительный файл 2 делает то же самое для 25 молекул тестового набора. Дополнительный файл 3 содержит следующие сведения в электронном виде (.XLSX-файл), в том числе и улыбается.
Мы используем SMILES (Simplified Molecular Input Line Entry System) для представления молекул для ввода данных, причем буквы и цифры удобно показывают связность каждого атома, где атомы водорода явно не показаны, например Oc1ccccc1-это фенол [46, 47]. Эти строки SMILES затем используются для вычисления молекулярных дескрипторов, которые формируют кодирование молекулярной структуры. Для этого исследования мы использовали точно такой же набор дескрипторов 123 Chemistry Development Kit (CDK) [48], как и ранее, повторно используя файлы, первоначально полученные в 2012 году, а не пересчитывая дескрипторы [13]. Это обеспечивает сопоставимость с предыдущей работой.
Машинное обучение
Деревья решений, названные в честь способа ветвления, в котором структурирован алгоритм, делают прогнозы на основе ряда разделов данных [49]. Когда новый экземпляр вычисляется, он направляется вдоль ветвей дерева в соответствии со значениями его дескриптора и в каждой точке ветви, называемой узлом, проходит один из двух возможных маршрутов, пока не достигнет конечного листового узла. Предсказание дерева решений значения свойства затем основывается на этом разбиении данных. Если это категория, например красная или синяя, то экземпляр запроса будет отнесен к категории в соответствии с распределением обучающих экземпляров на соответствующем листе. Если выходным свойством является непрерывная переменная, то регрессионная модель основана на данных на достигнутом листе, и дерево технически является деревом регрессии. Разбиения в узлах выбираются таким образом, чтобы получить все более однородные разбиения и минимизировать энтропию. Это реализуется через примесь Джини, вариант индекса Джини, который измеряет энтропию выходных свойств экземпляров [50]. Минимизация этой энтропии благоприятствует деревьям, которые группируют вместе экземпляры с одинаковыми значениями свойств в одном и том же листовом узле, что очень желательно для точного прогнозирования.
Метод машинного обучения Random Forest (RF) может быть использован либо для классификации, либо, как в настоящей работе, для регрессии [51, 52]. RF использует мудрость толпы, используя лес, состоящий из нескольких стохастически различных деревьев, каждое из которых основано на отдельно отобранных наборах данных, взятых из общего пула данных. Деревья выращиваются на основе рекурсивного разбиения обучающих данных, состоящих из нескольких признаков для каждого объекта, причем объекты здесь являются составными. Деревья были рандомизированы во-первых, основываясь на отдельных образцов начальной загрузки из пула данных, выборки из N из N объектов, выбранного с заменой. Во-вторых, деревья также рандомизируются , поскольку им разрешается использовать только стохастически выбранное подмножество дескрипторов, определяемое параметром, известным как m try, причем новое подмножество дескрипторов m try выбирается в каждом узле по мере построения дерева. Для каждого узла выбирается оптимальное по Джини разделение [50], так что данные собираются во все более однородные группы вниз по дереву, и таким образом набор молекул, назначенных каждому конечному листовому узлу, будет иметь сходные значения предсказываемого свойства. Таким образом, Случайный лес имеет ряд стохастически различных деревьев, каждое из которых получено из свежей начальной выборки обучающих данных. Такой Случайный лес регрессионных деревьев может затем использоваться для предсказания невидимых числовых тестовых данных, причем предсказания от различных деревьев объединяются с помощью их среднего значения для получения общего прогноза леса.
В этой работе также используются другие древовидные ансамблевые предикторы, и большая часть приведенного выше обсуждения в равной степени относится и к ним. Bagging-еще один древовидный ансамблевый предиктор [53]. Как объяснил Светник, пакетирование эквивалентно RF с m try, равным общему числу известных дескрипторов, то есть все дескрипторы доступны для оптимизации расщепления в каждом узле [52]. Алгоритм Дополнительных деревьев (или Чрезвычайно рандомизированных деревьев) также связан с RF, но третий уровень рандомизации вводится в виде порога для каждого решения, выбираемого случайным образом, а не оптимизируемого [54].
Ada Boost (Adaptive Boosting) [55] - это еще один ансамблевый метод, также основанный, в нашем использовании, на древовидных классификаторах. Общий классификатор подгоняется к набору данных с помощью последовательности слабых учащихся, которые в этой реализации являются деревьями решений. Веса каждого экземпляра обучающего набора изначально равны, но с каждым циклом эти веса корректируются для оптимизации классификатора в процессе повышения. Многие такие циклы выполняются, и модель все больше фокусируется на предсказании сложных случаев; эти потенциальные выбросы оказывают здесь большее влияние, чем в большинстве других методов. Процесс, с помощью которого оптимизируются веса, является своего рода линейной регрессией, хотя лежащие в ее основе слабые ученики сами по себе не являются линейными.
Машины опорных векторов (SVM) отображают данные в многомерное пространство. Функции ядра, как правило, нелинейные, используются для отображения данных в многомерное пространство признаков [56, 57]. Оптимальная гиперплоскость строится для разделения экземпляров разных классов или в текущем случае регрессии играет роль линии регрессии. Проще говоря, выбранная гиперплоскость разделяет экземпляры таким образом, что поля между ближайшими точками на каждой стороне, называемые опорными векторами, максимизируются. SVM очень эффективен для задач с большим количеством функций для изучения, где данные имеют высокую размерность, а также для разреженных данных [58].
K ближайших соседей (KNN) - это метод классификации и регрессии, где прогнозирование основано на значениях свойств ближайших экземпляров обучающих данных [59]. Для тестового экземпляра расстояние до каждого обучающего экземпляра в пространстве дескрипторов вычисляется для идентификации его ближайших соседей; обычно это евклидово расстояние, хотя можно использовать и другие метрики, такие как Манхэттенское расстояние. Значения различных дескрипторов следует масштабировать, если их диапазоны существенно отличаются. K относится к числу соседних обучающих экземпляров, которые должны быть учтены при прогнозировании. В классификации прогнозом является большинство голосов K-ближайших соседей, тогда как в регрессии берется среднее значение целевого свойства среди K соседей.
Искусственные нейронные сети (ИНС) основаны на использовании мозгом биологических нейронов, но значительно менее сложны [60, 61]. Типичная ЭНН будет проще и меньше, чем минимальный 302-нейронный мозг нематодного червя C. elegans [62]. Архитектура ANN имеет нейроны как во входном слое, который получает исходные данные, так и в выходном слое, который ретранслирует предсказание целевой переменной. Между входным и выходным слоями лежит один скрытый слой в типичной архитектуре или, как вариант, несколько скрытых слоев в случае Глубокого обучения. Каждое соединение между нейронами несет определенный вес, который оптимизируется на этапе обучения, когда сеть учится наилучшим образом соединять входы и выходы. АНН могут страдать от переобучения и обучения от шума, особенно когда набор обучения мал или разнообразен [63]. Вариант АНН, используемый в данном исследовании, представляет собой многослойный персептрон с обратным распространением (МЛП) [64].
Проекция на латентные структуры, или частичные наименьшие квадраты (PLS), является хорошо зарекомендовавшим себя методом, разработанным на основе полилинейной регрессии [65]. PLS получает линейную регрессию, проецируя входные и выходные переменные в новое пространство и обращаясь к коллинеарности путем уменьшения числа переменных, удаляя те, которые наименее важны для прогнозирования. Это простой метод, но он может оказаться непригодным для решения сложных и особенно нелинейных задач.
Стохастический градиентный спуск (SGD)-это еще один линейный метод, структурирующий задачу как минимизацию функции потерь, описывающей ошибку предсказания, на основе градиентного спуска. SGD оптимизирует гиперплоскость, многомерный аналог линии регрессии, минимизируя функцию потерь до сходимости [66].
Опрос
Этическое одобрение со стороны Комитета по этике Школы психологии и нейробиологии, который действует от имени Комитета по этике преподавания и исследований Университета Сент-Эндрюса (UTREC), более полно описано ниже в Заявлениях. Письмо об одобрении этики можно найти в Дополнительном файле 4. Проект обследования был тщательно спланирован заранее. Для создания онлайн-опроса был использован пакет программного обеспечения Qualtrics [67].
Человек-эксперт определялся как человек с химическими знаниями, работающий или обучающийся в университете или промышленности. Идентифицированным экспертам было разослано в общей сложности 229 приглашений по электронной почте. В начале опроса участников спрашивали об их самом высоком уровне образования и текущей сфере занятости. На каждом экране появилась всплывающая ссылка на веб-страницу с данными обучения: http://chemistry.st-andrews.ac.uk/staff/jbom/group/solubility/.
Это, по сути, HTML - версия Дополнительного файла 1. Обучающие данные отображались в случайном порядке с соответствующими значениями log S. Затем участникам показывали каждую молекулу в тестовом наборе в случайном порядке. Затем их попросили предсказать растворимость в воде на основе обучающих данных. Молекулы отображались в виде скелетных формул, нарисованных с помощью программы ChemDoodle [68]. Все молекулы были показаны с одинаковым разрешением. Полную копию опроса можно найти в Дополнительном файле 5.
Результаты
Выбор консенсусных предикторов на основе медианы
Наш простой экспериментальный проект не дает никакой основы для выбора лучшего метода машинного обучения или лучшего человеческого предиктора перед анализом результатов набора тестов. Поэтому мы заранее решили, что наш согласованный предиктор машинного обучения будет основан на медианной растворимости, предсказанной для каждой молекулы из десяти алгоритмов. Точно так же наш лучший человеческий предиктор будет основан на медианной растворимости, предсказанной для каждой молекулы среди людей-участников. Этот выбор ансамблевых моделей означает, что мы ожидаем, что оба выбранных нами консенсусных предиктора извлекут пользу из мудрости толпы [18,19,20]. Мы также исследуем post hoc лучший индивидуальный метод машинного обучения и лучший человеческий предиктор.
Алгоритмы машинного обучения
Десять алгоритмов машинного обучения были обучены на обучающем наборе и запущены на каждой из 25 молекул тестового набора для получения предсказанной растворимости. Эти вычисленные растворимости приведены в Дополнительном файле 6; их стандартное отклонение составило 1,807 логарифмических единиц. Мы оценивали каждый метод машинного обучения с точки зрения среднеквадратичной ошибки (RMSE), средней абсолютной ошибки (AAE), коэффициента детерминации, представляющего собой квадрат коэффициента корреляции Пирсона (R2), коэффициента ранговой корреляции Спирмена (?) и количества правильных предсказаний в пределах одной логарифмической единицы (NC). Эти результаты приведены в таблице 1.
MLP лучше всего выполнял алгоритмы машинного обучения на RMSE, AAE, R2 и ?. Его RMSE в 0,985 логарифмических единиц обнадеживает, а R2 в 0,706-достойный результат для этого набора данных, хотя различные методы валидации означают, что сравнение с McDonagh et al. [13] может быть не более чем полуколичественным. RF также дает хорошие результаты с RMSE 1,165 и входит в тройку лучших индивидуальных предикторов машинного обучения по всем критериям. Наряду с тесно связанным методом мешкования RF является одним из двух алгоритмов получения наибольшего числа правильных предсказаний-20. Десять предикторов машинного обучения охватывали диапазон RMSE от 0,985 до 1,813 логарифмических единиц. Худший RMSE получался из одного дерева решений и был по существу идентичен стандартному отклонению (SD) разрешимости тестового набора; остальные девять методов давали прогноз RMSE значительно ниже выборочного SD и, таким образом, удовлетворяли критерию полезности.
Наш консенсусный ансамблевый медианный предиктор машинного обучения превзошел девять из десяти индивидуальных алгоритмов на каждом из RMSE, AAE, R2 и ?. Однако MLP фактически превзошел его по каждому из этих показателей и является post hoc явно лучшим алгоритмом ML. Парные разностные t-тесты на ошибки предсказания, подробно описанные ниже, показывают несколько статистически значимых различий в производительности предикторов ML. Единственные такие примеры значимости заключаются в том, что консенсусный предиктор значительно отличается от PLS и SGD на уровне 5%, а MLP также значительно отличается от SGD. Используемые сценарии машинного обучения приведены в дополнительном файле 7.
Человека предсказателей
Всего было получено 22 набора ответов от участников-людей, что составило 9,6%. Из участников четверо были профессиональными учеными-кандидатами наук, работающими в промышленности, один кандидат наук, занимающийся научными коммуникациями, восемь кандидатов наук, работающих в качестве университетских ученых между постдокторским и профессорским уровнями, четыре нынешних аспиранта и пять нынешних студентов бакалавриата. Среди представленных материалов был набор предсказаний самоидентифицированного разработчика программного обеспечения, каждая растворимость которого цитировалась до пяти знаков после запятой. Мы считали, что косвенные доказательства использования компьютера были достаточно сильны, чтобы исключить эти предсказания из человеческих предсказателей. Интересно, что эти предсказания выполнялись почти идентично тем, которые были получены с помощью нашего метода post hoc best ML, которым был MLP. Результаты разработчика программного обеспечения достигли статистически значимой разницы в производительности по сравнению с ML-методом SGD в парных разностных t-тестах. По конструкции они не способствуют мл консенсус-прогнозом. Исключение предсказаний разработчика программного обеспечения из экспертной части исследования оставило в общей сложности 17 участников, которые сделали предсказание для каждой из 25 молекул, и четыре, которые предсказали подмножество. Эти расчетные растворимости приведены в дополнительном файле 8.
Два лучших набора человеческих ответов были получены от анонимных респондентов, идентифицированных как участники 11 и 7, оба из которых были зарегистрированы как кандидаты наук, работающие в академических исследованиях. Участник 11 сгенерировал RMSE в размере 0,942 логарифмических единиц и R2 в размере 0,723, заняв первое место по RMSE, R2, NC и AAE среди отдельных участников. Это представление включало в себя 18 правильных предсказаний, больше, чем любой другой человек-участник. Участник 7 получил RMSE 1,187 log S единиц, R2 0,637 и 17 правильных прогнозов, а также ранжировал лучшие соединения со значением ? 0,867. 17 полных ответов достигли значений RMSE, охватывающих большой диапазон от 0,942 до 3,020 логарифмических единиц. Из них восемь считались явно полезными со значениями RMSE значительно ниже выборочного SD; четыре были близки к SD, в пределах ± 0,15 единиц от него; пять были вне этого диапазона и считались не квалифицируемыми как полезные предикторы по обычному критерию. Тем не менее, все полные наборы предсказаний были верны с точностью до одной логарифмической единицы по крайней мере для девяти молекул.
Наш консенсусный ансамблевый медианный человеческий предиктор был построен путем взятия медианы всех человеческих предсказаний, полученных для каждого соединения, включая те, которые были получены из частичных записей. Этот предиктор показал очень хорошие результаты, набрав RMSE 1,087 и R2 0,632, соответственно, побив только одного и двух отдельных людей. Средний человеческий предиктор сделал 21 правильный прогноз и достиг AAE в 0,732 логарифмических единицы, что было лучше, чем у любого другого человека. Используя методику парного разностного t-теста на абсолютные ошибки каждого метода, подробно описанную ниже, мы находим, что различия между этим консенсусным предиктором и 13 из 17 человеческих экспертов статистически значимы на уровне 5%. Среди человеческих предсказаний 24 из 136 попарных сравнений показывают статистически значимые различия на уровне 5%. Таким образом, существует значительно больше различий в качестве человеческих предсказаний, чем предсказаний ML.
Сравнение консенсусных медианных показателей машинного обучения и человеческих предикторов
Общее сравнение медианных консенсусных ML и человеческих дескрипторов приведено в таблице 2. Хотя общепринятый человеческий классификатор работает немного лучше по каждому из пяти показателей, нам необходимо установить, является ли разница между ними статистически значимой. Для этого мы проводим парный разностный тест. Для каждого соединения мы рассматриваем абсолютную ошибку, сделанную консенсусными предикторами, независимо от того, были ли предсказания занижены или завышены истинной растворимостью. Они показаны в таблице 3, с разницей, обозначенной как положительная, если человеческий классификатор работает лучше, и отрицательная, если машинное обучение является более точным для этой молекулы. Тест парных различий направлен на то, чтобы установить, существует ли существенная разница в производительности двух классификаторов по сравнению с тестовым набором из 25 соединений. Таким образом, мы оцениваем значение р, вероятность того, что столь большая разница может возникнуть случайно при нулевой гипотезе, что два классификатора имеют одинаковое качество. Используя данные таблицы 3, мы провели как парный разностный t-тест, так и тест перестановок Менке и Мартинеса [69]. Эти тесты дали значения p 0,576 для t - критерия Стьюдента и 0,575 для теста перестановок, которые ясно показывают, что нет статистически значимой разницы между мощностью двух классификаторов. Относительная малость тестового набора, содержащего 25 молекул, несколько ограничивает статистическую силу такого сравнения. Однако во время тестирования опроса мы обнаружили, что предсказание растворимости для больших наборов соединений стало долгой и обременительной задачей, которая, вероятно, окажется за пределами терпения участников. Размер тестового набора и методология также достаточны для выявления значимых различий между отдельными человеческими предикторами; из 153 попарных т-тестов среди этих 18 предикторов, включая консенсусный, 37 являются значимыми на уровне 5%.
Сравнение лучших методов машинного обучения и человеческих предикторов
В то время как личности лучших индивидуальных предикторов машинного обучения и человека были известны лишь постфактум, тем не менее представляет интерес идентифицировать и сравнить их. Учитывая характер используемой нами статистической меры, для этого сравнения мы выбираем отдельные классификаторы с наименьшим ААЭ из 25 молекул. В каждом случае это те же классификаторы, которые имеют самый низкий RMSE и самый высокий R2, многослойный персептрон (MLP) и человеческий участник 11. Их общие данные о производительности приведены в таблице 4, а сравнение по каждому соединению-в таблице 5. Различия невелики, хотя можно заметить, что человек работает лучше по трем критериям, а персептрон-по двум.
Тесты статистической значимости привели к p-значениям 0,970 для t-критерия и 0,969 для теста перестановок, что указывает на отсутствие статистически значимой разницы между мощностью двух классификаторов.
Человеческие предикторы: проблемы с данными
Возможная неоднозначность ввода данных
Учитывая, что 74 из 75 соединений в обучающем наборе и 23 из 25 в тестовом наборе имеют отрицательные значения log S, мы ожидали, что подавляющее большинство прогнозов будет иметь отрицательные значения log S. Чтобы предсказать отрицательное значение, участник должен ввести знак минус в качестве части своих входных данных. На самом деле было сделано скромное количество неожиданных индивидуальных положительных прогнозов. Некоторые из них кажутся явными ошибками; есть три предсказания log S между 4,1 и 6,0 для молекул, где медианные предсказания были между - 3,25 и - 4,5. Один человек-участник впоследствии связался с нами, чтобы сообщить, что сделал по крайней мере одну ошибку знака. Пять других положительных предсказаний log S между 0.2 и 3.2 могут быть или не быть преднамеренными.
Хотя результаты, проанализированные выше, относятся к данным в их первоначальном неотредактированном состоянии, мы также рассмотрели эффект " исправления’ вероятных ошибок данных. Только в этом анализе мы поменяли местами знаки любых предсказаний положительных значений log S, где это уменьшило бы ошибку; это означает, что все такие предсказания для соединений с отрицательными экспериментальными значениями log S имели свои знаки, предварительно измененные.
Главным результатом этого изменения было бы улучшение некоторых из более слабых человеческих предикторов. В этом скорректированном наборе результатов 17 полных ответов достигли значений RMSE, охватывающих меньший диапазон от 0,942 до 2,313 логарифмических единиц. Из них девять считались явно полезными со значениями RMSE значительно ниже выборочного SD; пять находились в пределах ± 0,15 единицы SD; три были вне этого диапазона и считались не полезными предикторами по обычному критерию. Все полные наборы человеческих предсказаний были верны по крайней мере для десяти молекул. Хотя диапазон качества предсказания уменьшается, мы все еще отмечаем значительные различия в предсказательной силе между классификаторами, даже когда подозреваемые человеческие предсказания меняются знаками; из 153 попарных t-тестов среди этих 18 предикторов, включая консенсусный, 35 значимы на уровне 5%.
Основанный на медиане подход к построению наших консенсусных классификаторов специально разработан таким образом, чтобы быть устойчивым к присутствию отдаленных индивидуальных прогнозов. Хотя пять медианных прогнозов незначительно изменяются при корректировке подозрительных признаков, общая статистика почти не изменяется при новом RMSE 1,083, R2 0,639, ? 0,809, 21 правильном прогнозе и AAE 0,735. Сравнение с консенсусным классификатором машинного обучения практически не изменяется, при этом значение p из парного разностного t - критерия составляет 0,600. Поскольку идентичность и статистика лучшего человеческого классификатора не затрагиваются, сравнение лучших индивидуальных классификаторов остается неизменным при знаковых свопах. Таким образом, мы отмечаем, что замена признаков предполагаемых случайных положительных логарифмических предсказаний не повлияет на основные результаты этой работы, но улучшит некоторые из более слабых человеческих классификаторов. Мы не рассматриваем его дальше.
Проблемы с данными в учебном наборе обследования
На более позднем этапе, к сожалению, было обнаружено, что данные, использованные в обучающем наборе опроса, соответствуют более раннему проекту, а не окончательному варианту растворимости, использованному McDonagh et al. [13]. Наблюдались нетривиальные (> 0,25 логарифмических единиц) различия между растворимостью, использованной в обучающем наборе обследования, и опубликованной растворимостью DLS-100 для шести соединений. Для сулиндака растворимость DLS-100 составляет - 4,50, взятая у Llinas et al. [7], но значение обучения обследованию составило - 5,00 от Rytting et al. [39], для L-ДОФА значение растворимости DLS-100 составляет - 1,82, взятое из Rytting et al. [39], в то время как временное значение, используемое в опросе тренинг - 1.12; для сульфадиазин ДЛС-100 растворимость значение - 3.53 изначально взято из Rytting и соавт. [39], в то время как значение, используемое в опросе тренинг - 2.73; для гуанин ДЛС-100 растворимость - 4.43, взятых из Llinas и соавт. [7], но значение обучения обследованию составило - 3,58 от Rytting et al. [39]; для циметидина правильная растворимость DLS-100 составляет - 1,69, взятая из Llinas et al. [7], но было использовано ошибочное обучающее значение опроса - 3,60. Для остальных 70 молекул тренировочного набора растворимость DLS-100 и survey training set либо идентична, либо находится в пределах 0,25 логарифмических единиц.
Хотя повторить опрос было невозможно, можно обучить алгоритмы машинного обучения на обоих наборах обучающих данных. Основные результаты машинного обучения, представленные здесь, основаны на правильных растворимостях DLS-100, но мы также исследовали эффект использования неточных предварительных данных из опроса обучения. Влияние результатов машинного обучения невелико, хотя, как ни странно, неточные данные обучения привели к очень незначительному улучшению медианных результатов классификатора машинного обучения (RMSE = 1,095, R2 = 0,632). Похоже, что различия в данных между обучающим набором опроса и набором DLS-100 очень мало повлияли на качество прогнозов машинного обучения и поэтому вряд ли оказали существенное влияние на человеческие прогнозы.
Предсказания для различных соединений
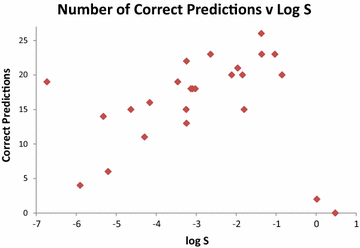
Существует значительная разница в точности предсказания между различными молекулами в нашем наборе данных. В таблице 6 ниже мы ранжируем 25 соединений по размерам ошибок двух консенсусных предикторов. Для каждого соединения мы определяем среднее значение этих двух беззнаковых консенсусных ошибок как Среднюю абсолютную медианную ошибку (MAME), которую мы показываем на рис. 1, а также вместе с количеством правильных прогнозов в таблице 6. На рис. 2 показана MAME как функция log S, а на рис. 3 иллюстрирует, как число правильных предсказаний изменяется в зависимости от растворимости. Как общая тенденция, соединения с растворимостью около середины диапазона хорошо прогнозируются. Две наиболее растворимые молекулы, птеридин и антипирин, являются двумя худшими прогнозируемыми по обоим показателям. Для наименее растворимых соединений картина неоднозначна. Второе и четвертое наиболее нерастворимые соединения, мифепристон и тригексифенидил, плохо обрабатываются, будучи третьим и четвертым худшими прогнозируемыми по обоим показателям. Однако наиболее нерастворимое соединение, трифенилен, хорошо предсказано, а третье по степени нерастворимости, эстрон, умеренно хорошо предсказано с 14 правильными предсказаниями.

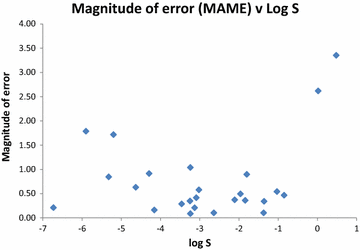
Как уже отмечалось ранее, многие соединения имеют множественные, а иногда и значительно отличающиеся значения растворимости, о которых сообщается в литературе [9]. Может возникнуть путаница между различными определениями растворимости, включение или исключение ионизированных форм, неоднозначность между полиморфами, систематические различия между экспериментальными методами, кинетическая растворимость может быть ошибочно идентифицирована как термодинамическая, или растворимость неправильного соединения может быть измерена из-за непредвиденных химических реакций, происходящих в экспериментальной установке. Хотя мы не утверждаем, что плохая предсказуемость всегда подразумевает вероятную ошибку в экспериментальном значении, это не является неизвестным. В задаче растворимости индометацин был очень плохо предсказан вычислительными методами по сравнению с другими соединениями с аналогичной заявленной растворимостью [8]. Последующее исследование Comer et al. показало, что индометацин подвергся гидролизу во время первоначального эксперимента CheqSol, и дало скорректированное значение его внутренней растворимости [70].
В распределении знаковых ошибок в настоящем наборе данных только два соединения производят ошибки (MAME), которые лежат более чем на два стандартных отклонения от среднего значения; это антипирин и птеридин (рис. 1). Для антипирина, наихудшей предсказанной молекулы в нашем наборе данных, внутренняя водная растворимость, которую мы использовали, составляет log S = 0,48, как указано в наборе данных, подготовленном Rytting et al. [39] на основе более ранней работы Германа и Венг-Педерсена [71]. Альтернативное значение log S = - 0.56 взято из базы данных Aquasol [72]. Даже используя это альтернативное значение, антипирин все равно будет одним из двух или трех худших предсказанных соединений в нашем исследовании. Yalkowsky et al. [73] перечисляют семь различных значений log S комнатной температуры для антипирина в диапазоне от - 0,66 до 0,55, их аннотации предполагают, что они считают более высокие растворимости более точными. Для птеридина растворимость log S = 0,02 была измерена с помощью CheqSol и сообщена в Palmer et al. [37] В двух отчетах Albert et al. в 1950-х годах растворимость “одной части птеридина с 7,2 или 7 частями воды” была переведена Ялковским и др. в молярные единицы дают log S = - 0,02 и - 0,03 соответственно и, следовательно, практически не отличаются от результата CheqSol [73,74,75].
Обсуждение
Мы провели сравнение консенсусных предикторов из алгоритмов машинного обучения и от экспертов-людей, причем предикторы были построены таким образом, чтобы не требовать предварительного выбора алгоритма или человека, ожидаемого для получения наилучших результатов. Сравнивая ряд статистических показателей точности, мы обнаруживаем, что существует очень небольшая разница в качестве предсказания между машинным обучением и человеческими консенсусными предикторами. В то время как человеческий медианный предиктор получает несколько лучшие заголовочные цифры во всех измерениях, разница между ними невелика и намного ниже статистической значимости. Мы наблюдаем, что согласованный подход между различными алгоритмами машинного обучения, вероятно, будет улучшением по сравнению с предварительным определением одного конкретного алгоритма, если только вы не были очень уверены в том, какой именно алгоритм выбрать. Здесь мы не рассматривали бы MLP как нашу лучшую перспективу, прежде чем увидеть результаты. Аналогичный вывод относится и к человеческим предикторам.
Кроме того, мы провели аналогичное сравнение лучшего алгоритма машинного обучения и лучшего эксперта-человека. Выбор их в качестве "лучших" предикторов потребовал бы пост-специального знания результатов. Здесь даже результат заголовка был виртуальной связью между лучшим человеком и лучшим алгоритмом, и явно не было никакой существенной разницы в предсказательной силе.
Оба этих результата приводят к выводу, что алгоритмы машинного обучения и специалисты-люди предсказывают растворимость в воде практически одинаково хорошо. У обучающихся машин был доступ к более чем сотне дескрипторов для каждого соединения, практически безошибочная память и возможность реализовать сложные алгоритмические процедуры с быстрыми и точными численными вычислениями. Поэтому, возможно, удивительно, что они не смогли превзойти людей в этой задаче. Наш опыт в этом исследовании, однако, показывает, что предсказание растворимости более чем для 25 молекул за один присест стало бы обременительной задачей для большинства людей, в то время как компьютер вряд ли будет жаловаться, если его попросят сделать предсказания для тысячи соединений. Таким образом, наш экспериментальный проект был несколько изобретен, чтобы свести к минимуму присущее машинам преимущество практически неограниченного объема внимания.
Даже если бы человек и машина были шахматистами одинаковой силы, можно было бы ожидать, что они рассчитают свои лучшие ходы по-разному, опыт и понимание человека против быстрых, точных и обширных вычислений машины. Можно было бы предположить, применима ли здесь подобная дихотомия подхода. Хотя мы не просили участников объяснять свои методы в самом опросе, два эксперта впоследствии неофициально сообщили о применении своего рода алгоритма ближайшего соседа, ища обучающие молекулы набора, подобные соединению запроса, а затем вынося суждение о том, будут ли химические вариации между ними увеличивать или уменьшать растворимость. Может показаться удивительным, что компьютер не может, с описанными выше преимуществами, превзойти человека в такой задаче. Тем не менее, люди-участники проекта FoldIt смогли внести полезный вклад даже в такой явно вычислительной области, как сворачивание белков, по крайней мере, после того, как проблема была соответствующим образом геймифицирована [76]. Возможно, некоторые из экспертов были достаточно уверены в своей интуиции химика, чтобы оценить растворимость без сознательного выполнения явных вычислений. Однако наш тестовый набор был выбран, чтобы содержать относительно незнакомые соединения, чтобы свести к минимуму риск того, что такая задача будет выполнена просто путем отзыва.
Минимально полезный прогноз имеет RMSE, очень близкий к стандартному отклонению растворимости образца, и может быть эмулирован очень простой и наивной процедурой оценки вычисления средней растворимости и последующего прогнозирования этого значения для каждого соединения. В нашем эксперименте только около половины людей превзошли этот стандарт. Однако девять из десяти обучающихся машин справились с этим, так что общее качество машинного обучения существенно лучше, чем минимально полезный предиктор. Таким образом, мы не видим причин отклоняться от довольно устоявшегося мнения о том, что современные машинные предикторы не настолько плохи, чтобы не соответствовать критерию полезности (RMSE около 1,8 логарифмических единиц в данном исследовании), и не настолько хороши, чтобы их достижения ограничивались только неопределенностью экспериментальных данных растворимости (RMSE примерно 0,6–0,7) [9]. Машинное предсказание в настоящее время несколько лучше, чем середина этого диапазона, в данном исследовании при RMSE около 1,0 логарифмических единиц. Восемь алгоритмов машинного обучения и четыре эксперта-человека, наряду с обоими консенсусными предикторами, по-видимому, превосходят метод первых принципов, который получил RMSE 1,45 на аналогичном и перекрывающемся, хотя и не идентичном, наборе из 25 молекул [44]. Последний подход, однако, систематически совершенствуется и дает ценное понимание, разбивая растворимость на отдельные термины сублимации и гидратации, а также энтальпии и энтропии. Учитывая наилучшие и консенсусные предикторы машинного обучения и человека, эти четыре показателя были выполнены в диапазоне RMSE примерно 0,95–1,15, что численно немного лучше, чем модели машинного обучения, ранее описанные для того же общего набора данных из 100 молекул [13]. Однако различные экспериментальные проекты и стратегии валидации исключают прямое количественное сравнение. Тем не менее, эти индивидуальные подходы к машинному обучению, общие для двух исследований, RF, SVM и PLS, давали аналогичные RMSE с точностью до ± 0,1 в каждом случае.
Мы наблюдаем, что консенсусные предсказатели, и человеческий в частности, существенно выигрывают от эффекта мудрости толпы. Основанный на медиане консенсусный человеческий предиктор был значительно лучше, чем 13 из 17 отдельных людей, в отношении его ошибок предсказания, даже для небольшого набора данных, статистическую значимость которого трудно продемонстрировать. Можно утверждать, что этот эффект маскирует превосходство отдельных методов машинного обучения по крайней мере в одном аспекте производительности, учитывая, что девять из десяти алгоритмов генерируют полезные предсказания по сравнению с примерно половиной людей. Однако среди людей было по крайней мере два очень сильных предиктора, конкурирующих с любым подходом машинного обучения.
Выводы
Мы пришли к выводу, что специалисты-люди могут предсказывать водную растворимость молекул, похожих на лекарства, практически так же хорошо, как и алгоритмы машинного обучения. Мы обнаружили, что лучший человеческий предсказатель и лучший алгоритм машинного обучения-многослойный персептрон-дают почти одинаковое качество предсказания. Мы построили основанные на медиане консенсусные предикторы как для человеческих предсказаний, так и для предсказаний машинного обучения. В то время как консенсусный человеческий предиктор достигал очень немного лучших показателей заголовков по различным статистическим показателям, разница между ним и консенсусным предиктором машинного обучения была как небольшой, так и статистически незначимой. Мы наблюдаем, что набор алгоритмов машинного обучения имел более высокую долю полезных предикторов, девять из десяти по сравнению с примерно половиной людей. Несмотря на некоторые слабые индивидуальные человеческие предикторы, мудрость эффекта толпы, присущая основанному на медиане консенсусному предиктору, обеспечивала высокий уровень точности ансамблевого предсказания. Лучшие и консенсуса предсказатели дают по мере приближения примерно 0.95–1.15 войдите с единицы, как машинное обучение и кадровых специалистов. Учитывая предполагаемую неопределенность имеющихся экспериментальных данных, наилучшие возможные предикторы на существующих данных могут достигать RMSEs около 0,6–0,7, хотя эта цифра является предметом дискуссий, в то время как минимально полезный предиктор будет составлять около 1,8 логарифмических единиц для нашего набора данных. Таким образом, текущее состояние предсказания, как для людей, так и для машин, несколько лучше, чем середина диапазона между минимально полезными и наилучшими реально возможными предсказателями.
Телеграм: t.me/ainewsline
Источник: jcheminf.biomedcentral.com