Kaggle опубоиковал отчет о состоянии сфер Machine Learning и Data Science за 2020 год
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-02-10 12:30
Международная система организации конкурсов по исследованию данных Kaggle опубликовала отчет о развитии сфер машинного обучения и науке о данных за 2020 год. В исследовании приняло участие более двух тысяч респондентов, работающих в сфере обработки данных. LabelMe подготовил краткую выжимку самых интересных аспектов статьи.

Как проходило исследование
Kaggle запустил опрос, состоящий из 35 вопросов. В течение 3,5 недель, начиная с октября 2020, исследователи получили более 20 тысяч ответов. Немалая часть опроса была отведена под изучение демографических особенностей распространения профессии и повышения количества кадров на рынке труда, а также изучению самых актуальных методов, способов и технологий работы с данными.
Отчет содержит графики и анализ некоторых характеристик респондентов опроса, включая:
- Профиль специализации
- Образование и опыт
- Занятость и рабочая среда
- Технологии и платформы, используемые в работе
В лучших традициях Kaggle, был объявлен призовой фонд в 30 000 долларов за самые информативные и подробные доклады по теме. При этом осветить свой опыт и знания можно было в разных формах. Это позволило организаторам составить более комплексный отчет о состоянии Data Science . Оценивались работы по трем критериями:
- Структура — последовательность повествования, точность формулировок, использование подтвержденных данных, наличие визуализации и пруфов.
- Оригинальность — новизна темы для научного и IT-сообщества, никакого плагиата, высокий процент уникальности.
- Доказательная база — уместное использование цитат и источников, наглядные примеры кода, глубокий анализ данных, логичное обоснование гипотез с опорой на факты.
Всего Kaggle предусмотрел пять призовых мест с разным размером наград, от 10 до 1 тысячи долларов.
Некоторые результаты исследования
На основании полученных данных исследовательская команда Kaggle смогла сделать выводы о том, что подавляющее большинство специалистов по Data Science — моложе 35 лет, две трети респондентов имеют ученую степень, а большинство из них имеют опыт программирования менее 10 лет. Около 55% участников имеют опыт работы с машинным обучением менее трех лет. В слайдере мы отобрали наиболее примечательную инфографику.
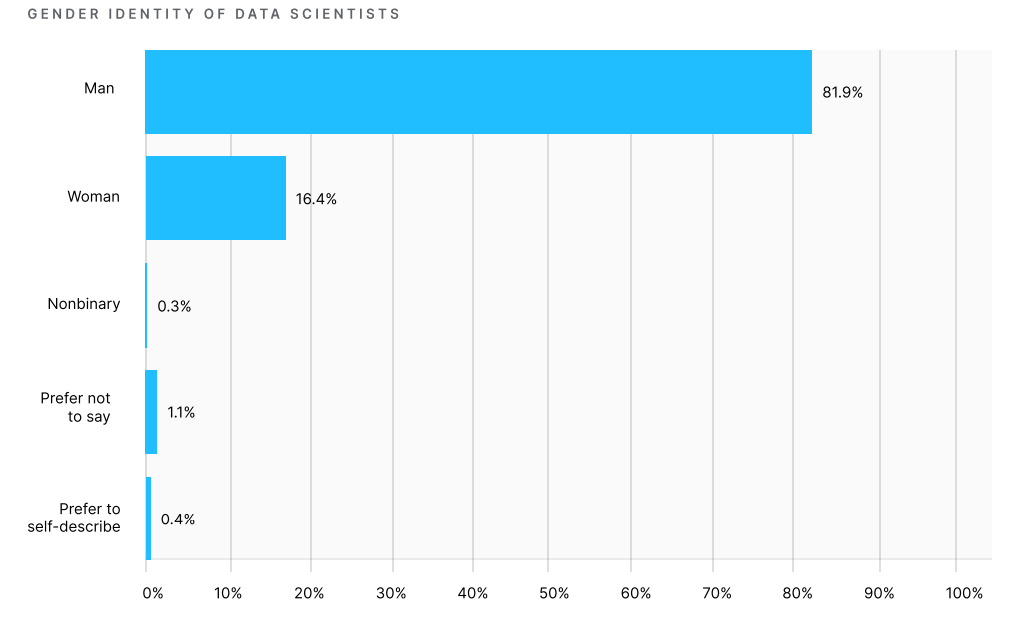
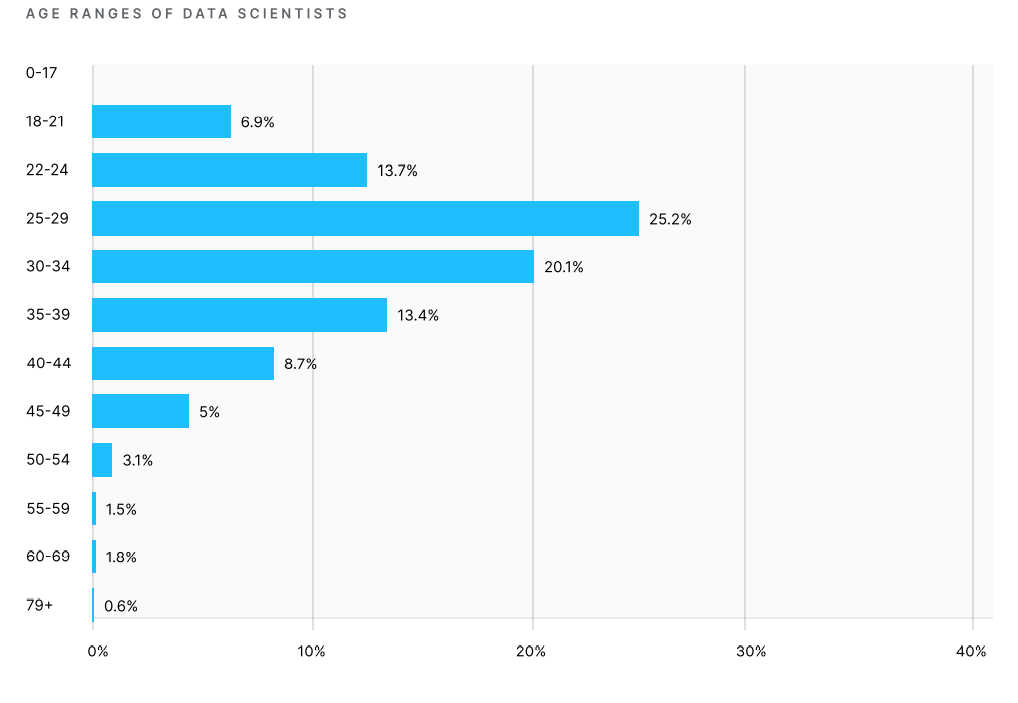
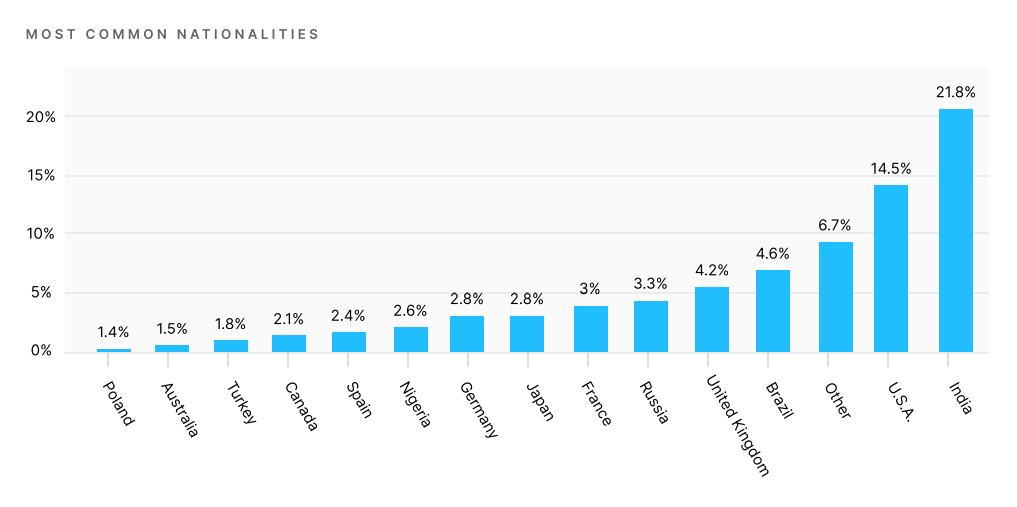
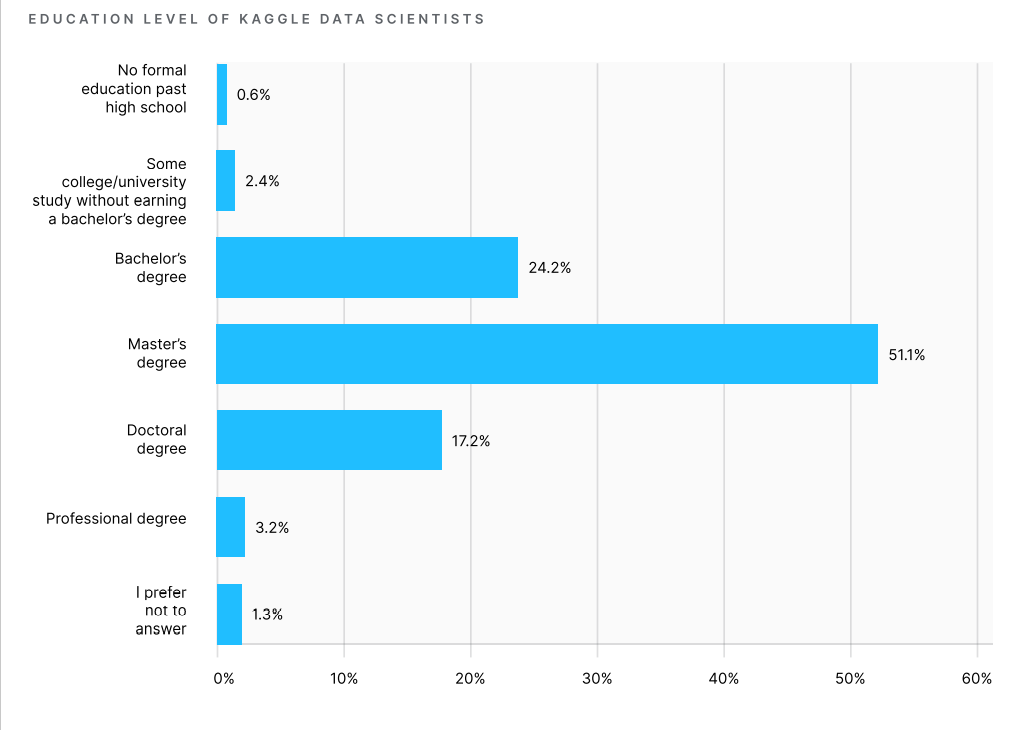
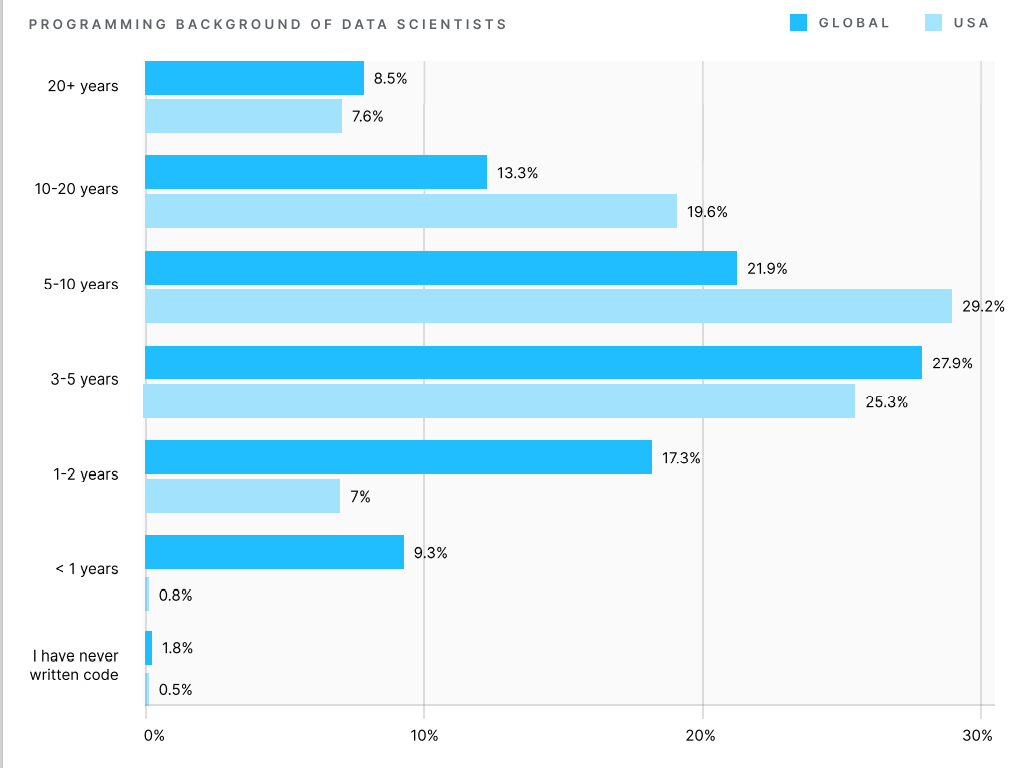
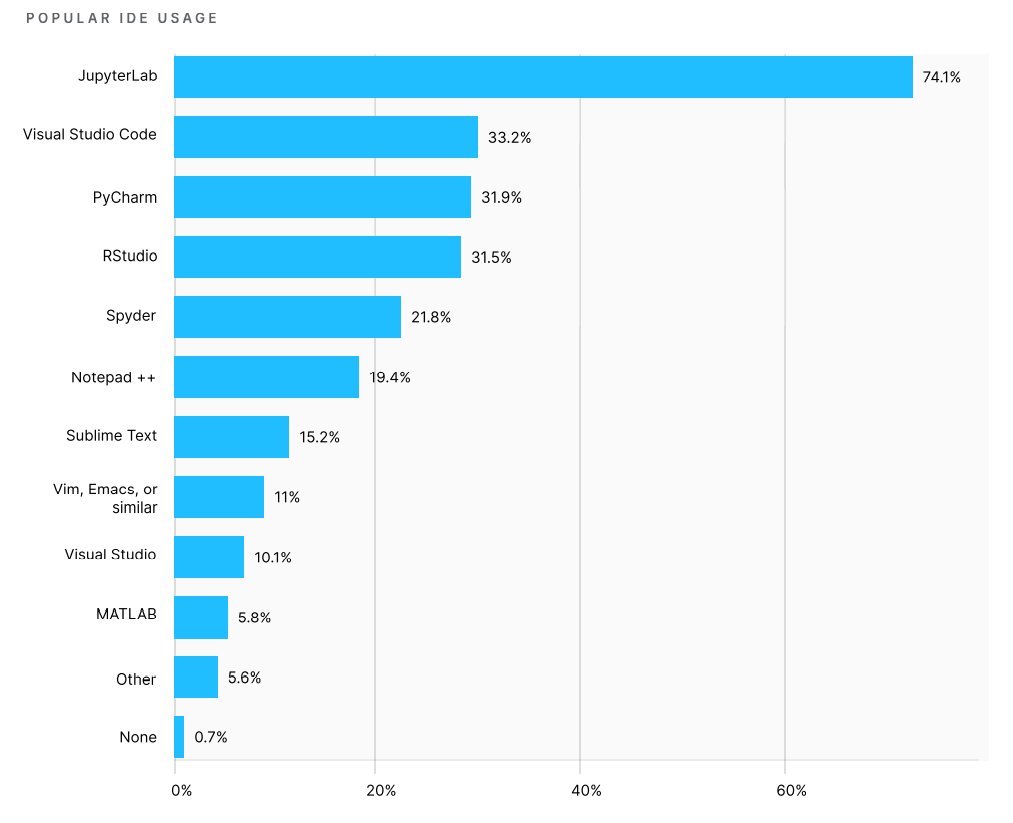
Раздел опроса, посвященный используемым технологиям, строился на выборе конкретных ответов. Это позволило получить точную статистику и сопоставить актуальность различных методов обработки данных.
Например, самой популярной средой разработки среди датасаентистов стал Jupyter. Им пользуется порядка 74% респондентов. Следом за ним идет Visual Studio с результатом в 43%. Третье место делят PyCharm, и RStudio: у них по 30% голосов.
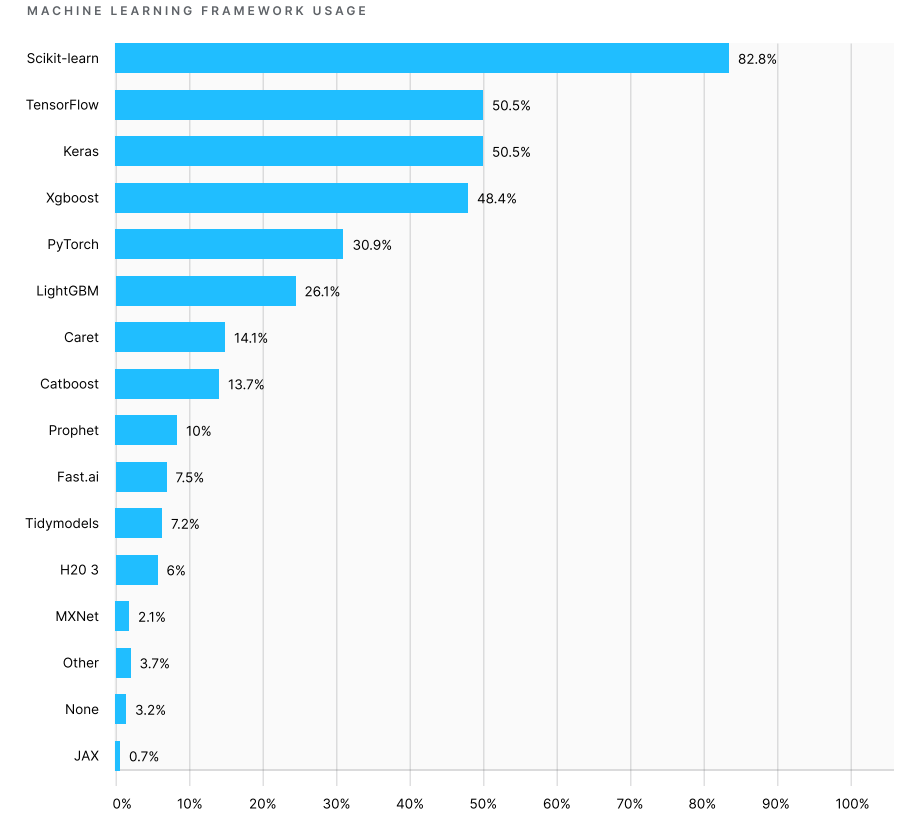
Что касается фреймворков и библиотек, то более 80% респондентов используют scikit-learn , а около 50% — фреймворк Google для глубокого обучения TensorFlow. Другой популярный фреймворк глубокого обучения — PyTorch, разработанный Facebook, используют около 31%, по сравнению с 26% в 2019 году.
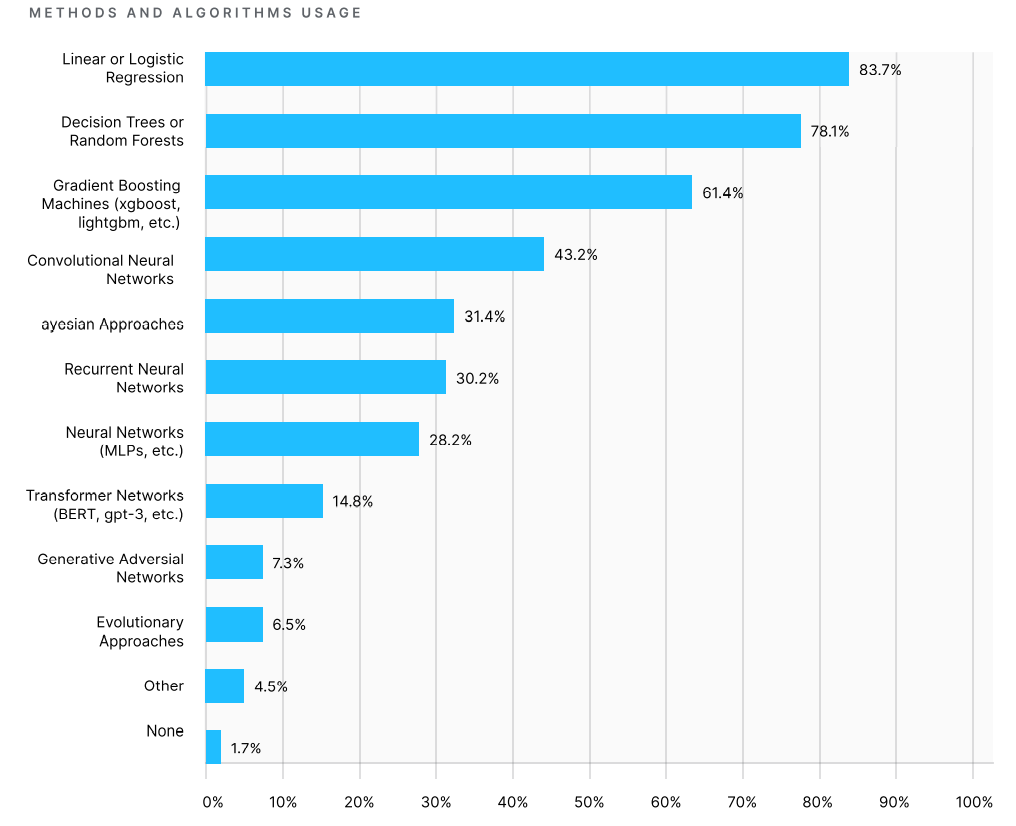
Если говорить о самом популярном алгоритме машинного обучения, то им стала линейная регрессия. Ее использует более 80% специалистов. Второе и третье место занимают дерево решений и градиентный бустинг, соответственно. Некоторые участники поделились своим опытом работы с различными архитектурами нейросетей: 43% использовали сверточную нейронную сеть (CNN), 30% — рекуррентную нейронную сеть (RNN) и 15% — нейронную сеть Transformer.
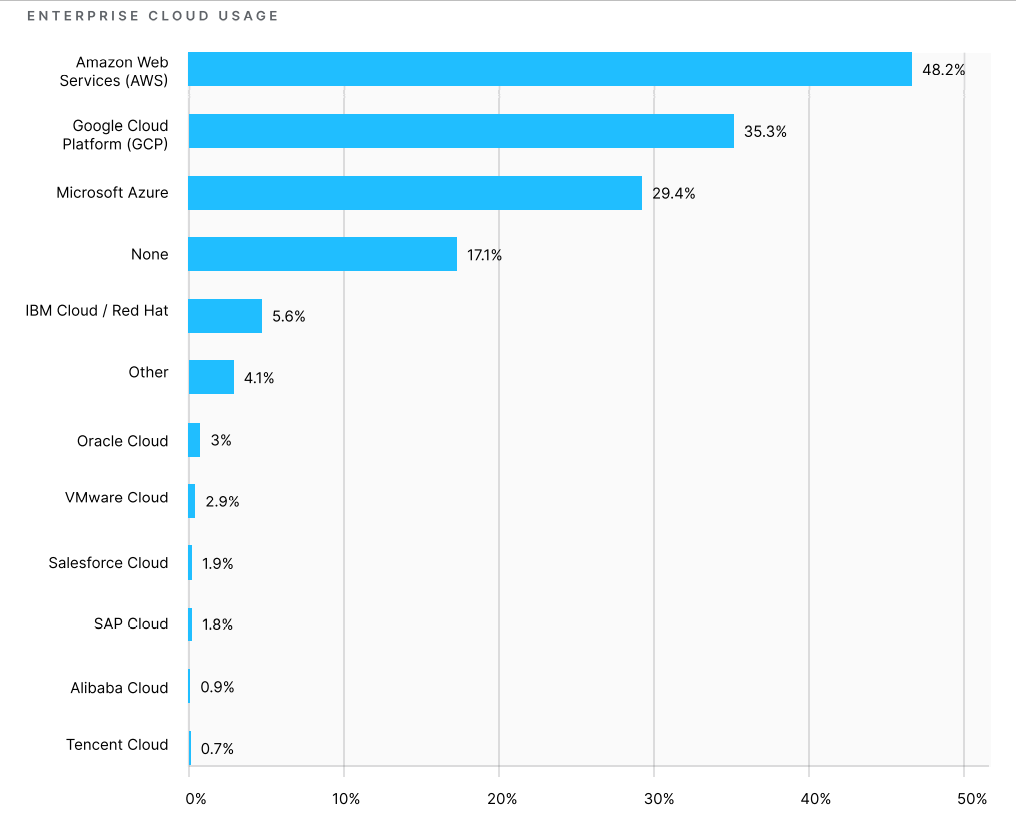
Также Kaggle определили фаворитов среди поставщиков облачных хранилищ и вычислительных мощностей. Лидером стал Amazon Web Services (AWS) — почти 50% опрошенных выбрали его. Около трети специалистов предпочли Google Cloud Platform (GCP) и еще 29% используют Microsoft Azure.
Это далеко не все результаты. Ознакомиться с полной версией отчета можно по этой ссылочке.
Вывод
Для Kaggle это уже четвертое ежегодное исследование изменений в сфере Data Science. Динамика роста респондентов, появление новых методов сбора и обработки данных, а также увеличение числа компаний говорят нам о росте спроса и актуальности сферы обучения ИИ и работы с разметкой данных.
Еще больше укрепляют этот тезис и другие масштабные исследования. Например, Anaconda (создатель популярного среди специалистов по обработке данных дистрибутива Python) недавно опубликовала свой отчет о состоянии науки о данных. В нем приняло участие 2360 респондентов более чем из 100 стран мира. Или производитель ПО обучения для искусственного интеллекта Algorithmia опубликовал отчет о состоянии машинного обучения на предприятиях. В нем опрашиваются тысячи компаний на разных стадиях развития машинного обучения, подчеркивая проблемы, связанные с операциями Machine Learning.
Обобщая всё это, мы можем сказать, что все больше компаний смотрят в сторону создания и обучения собственных нейросетей, адаптированных под конкретные бизнес-модели. И тот факт, что эффективность обучения зависит от количества и качества собранных данных, создает новый спрос. Спрос на поставщиков уже размеченных датасетов.
Как раз этим мы и занимаемся. LabelMe специализируется на подготовке датасетов для компаний, использующих искусственный интеллект и машинное обучение в своих продуктах. Благодаря отлаженным внутренним процессам и работой на собственном ПО, мы можем гарантировать быстрый, а главное качественный сбор и разметку данных под любые цели клиента.
LabelMe предоставляет тестовый датасет бесплатно. Так вы сможете оценить качество наших услуг, не потратив и копейки.
Телеграм: t.me/ainewsline
Источник: labelme.medium.com