Распознавание изображений (т. е. классификация того, какой объект отображается на изображении) является основной задачей в области компьютерного зрения, так как она позволяет использовать различные последующие приложения (автоматическая маркировка фотографий, помощь слабовидящим людям и т. д.) и стала стандартной задачей, по которой можно проводить сравнение алгоритмов машинного обучения (ML). Алгоритмы глубокого изучения (DL) за последнее десятилетие стали наиболее конкурентоспособными алгоритмами распознавания образов. Однако по умолчанию это алгоритмы «чёрного ящика»: трудно объяснить, почему они делают конкретный прогноз. Почему это является проблемой? Пользователи моделей ML часто хотят иметь возможность интерпретировать, какие части изображения привели к прогнозу алгоритма, по многим причинам:
Разработчики машинного обучения могут анализировать интерпретации к отладочным моделям, идентифицировать заблуждения и прогнозировать, обобщается ли модель на новые изображения.
Пользователи моделей машинного обучения могут больше доверять модели, если модели объясняют, почему был сделан конкретный прогноз.
Законодательное регулирование относительно ML, такое как GDPR, требует некоторых алгоритмических решений, которые можно объяснить с человеческой точки зрения.
Мотивированные такими условиями, в течение последнего десятилетия исследователи разработали множество различных методов для открытия «чёрного ящика» глубокого обучения с целью сделать базовые модели более объяснимыми. Некоторые методы специфичны для определённых видов алгоритмов, в то время как другие являются общими. В этой статье представлен обзор методов интерпретации, изобретённых для распознавания образов, а также примеры и код, чтобы попробовать их самостоятельно с помощью Gradio. Автор статьи Али Абдалла — сооснователь Gradio и инженер по машинному обучению. До этого он работал в Tesla, iRobot и MIT. Он опубликовал несколько научных статей и участвовал во многих проектах с открытым исходным кодом.
Leave-One-Out
Перед тем как углубиться в исследование, давайте начнём с самого основного алгоритма, который работает для любого типа классификации изображений: Leave-Оne-Оut (LOO).
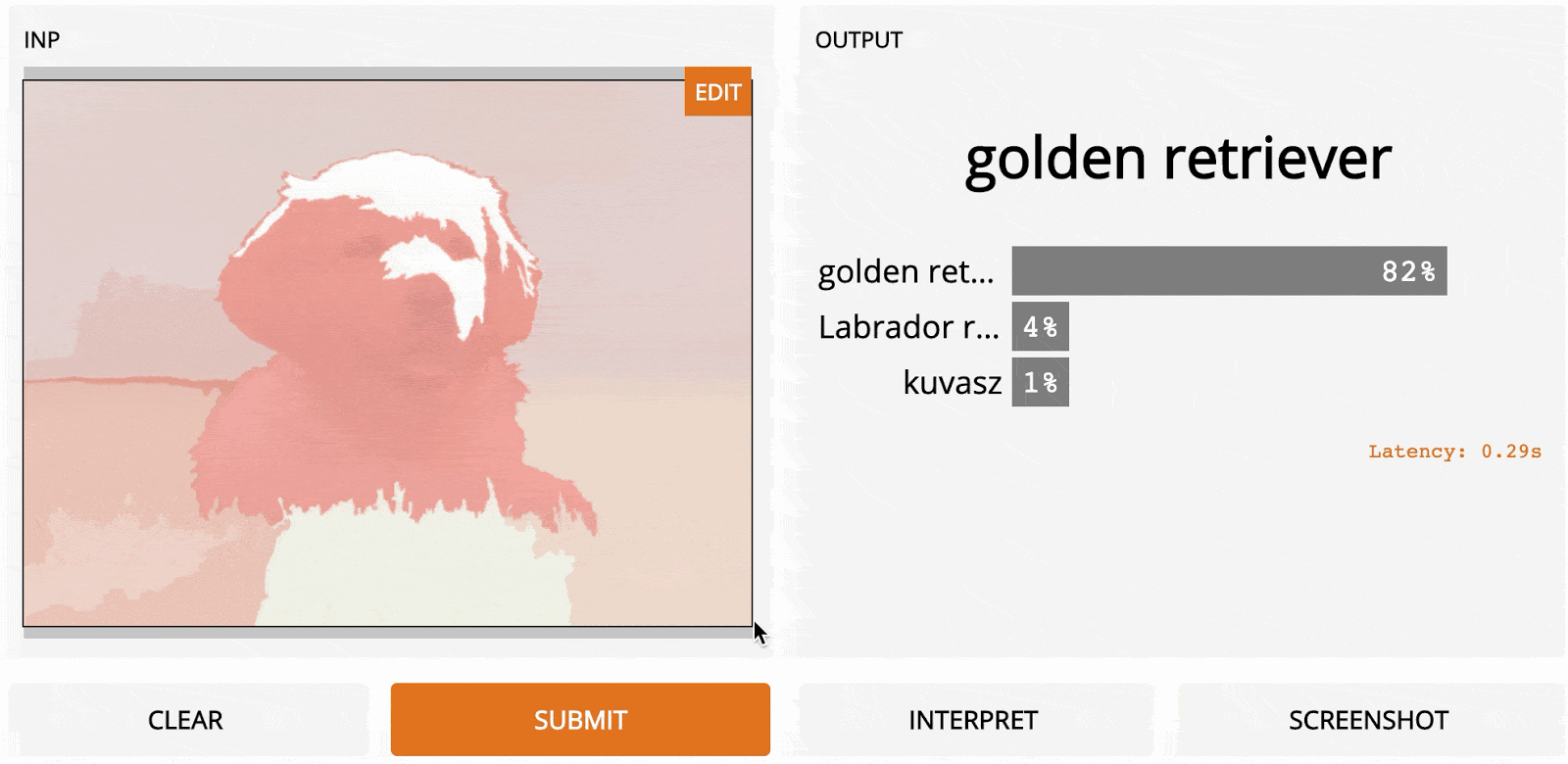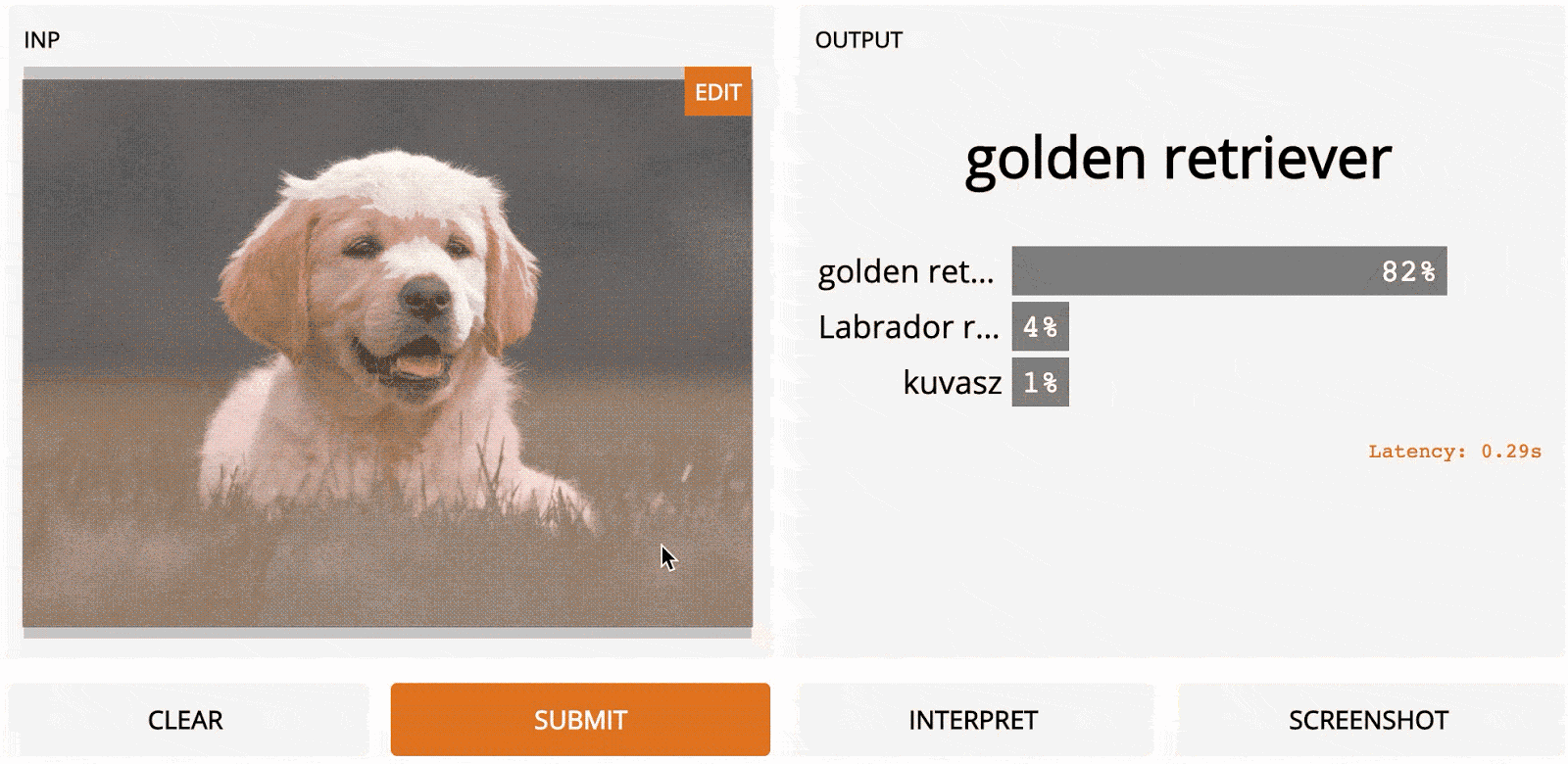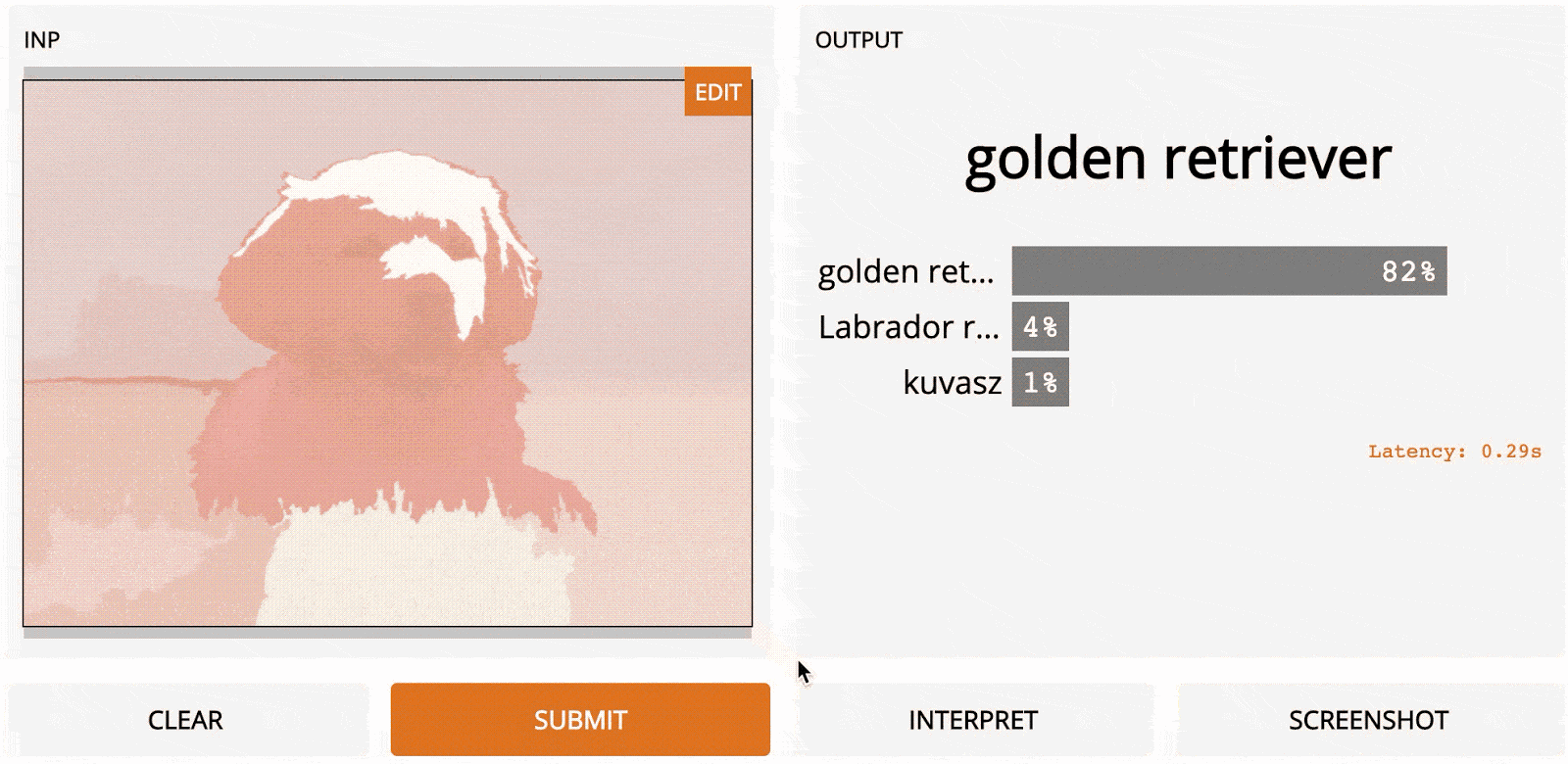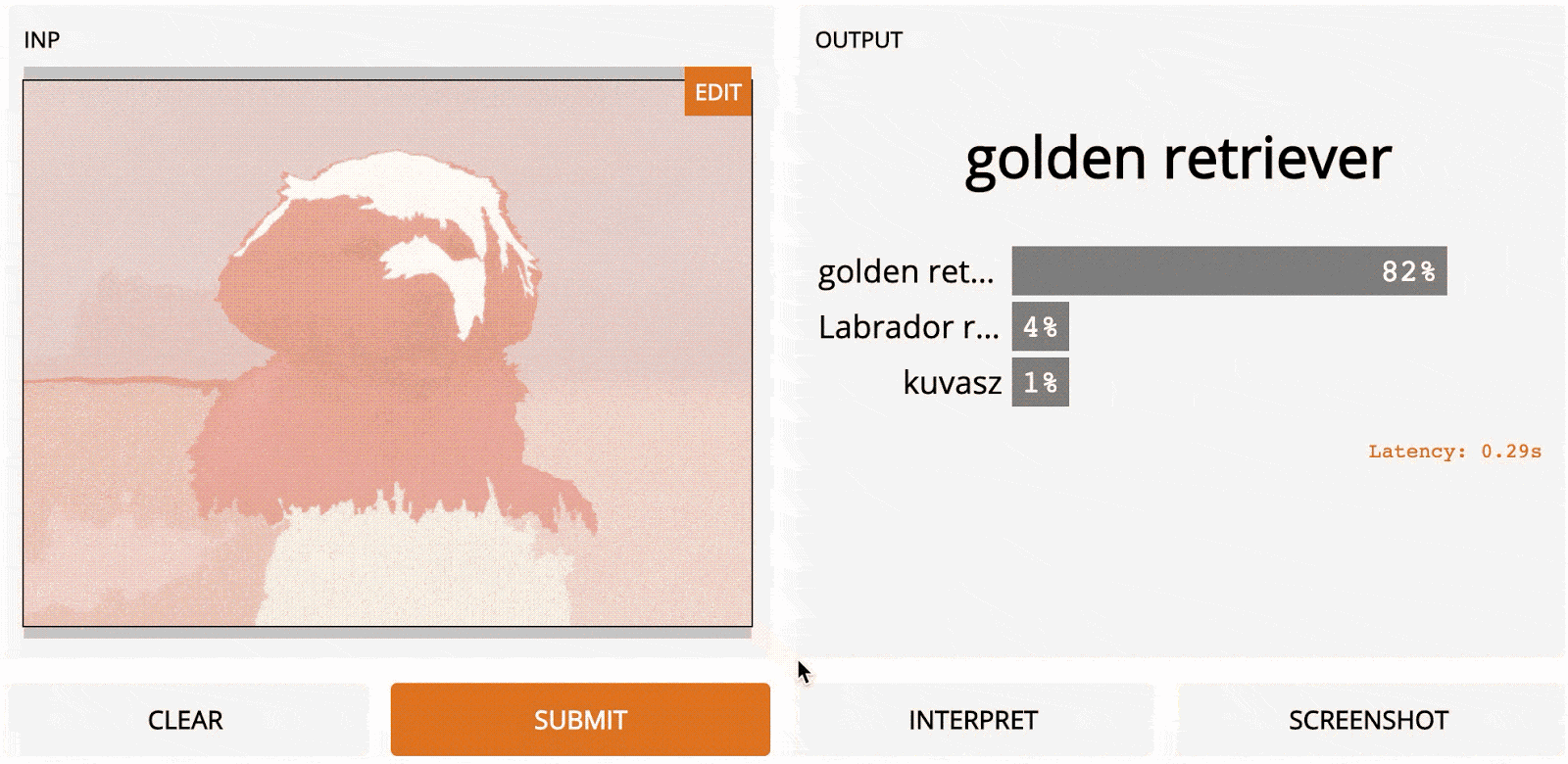
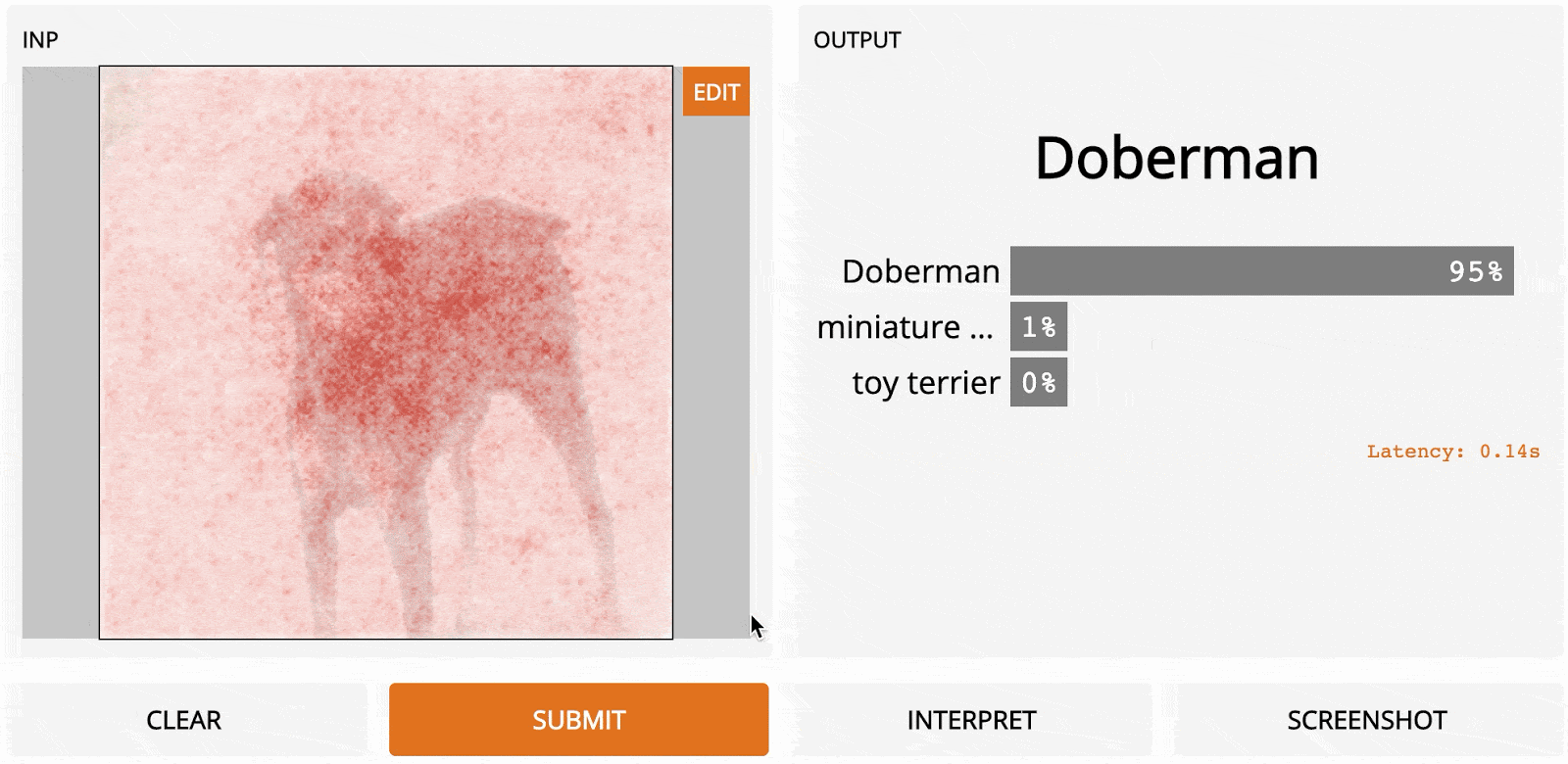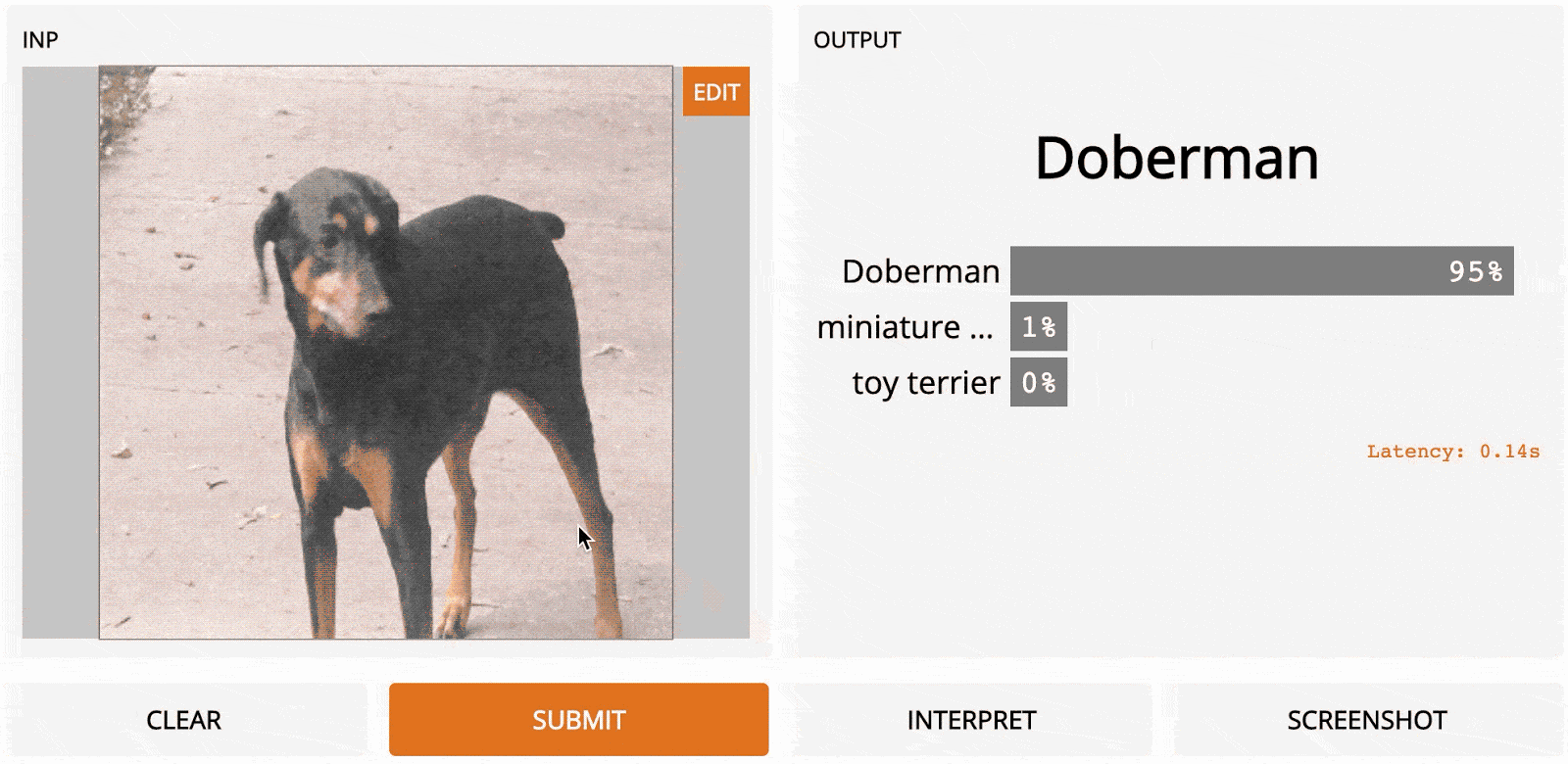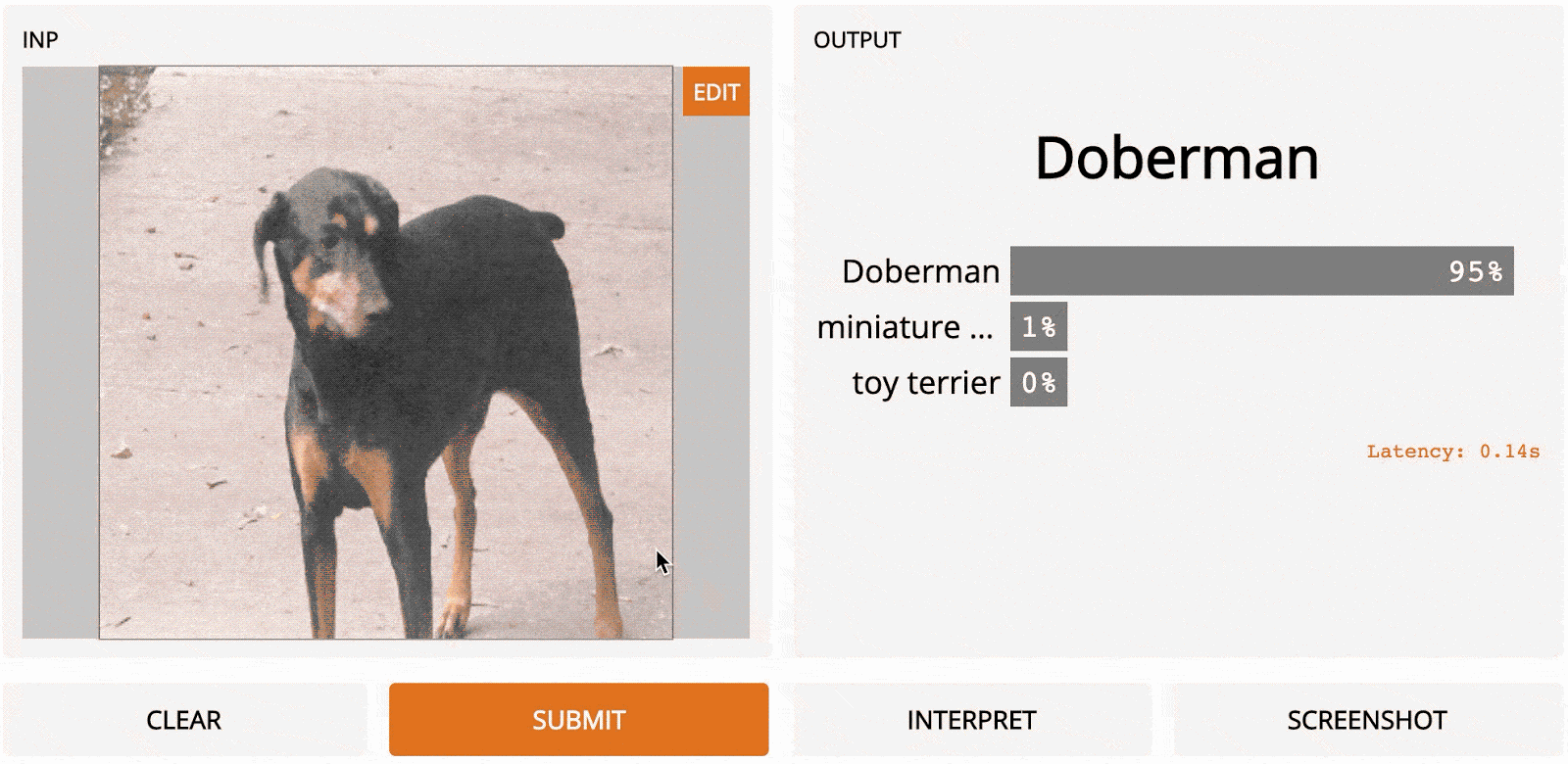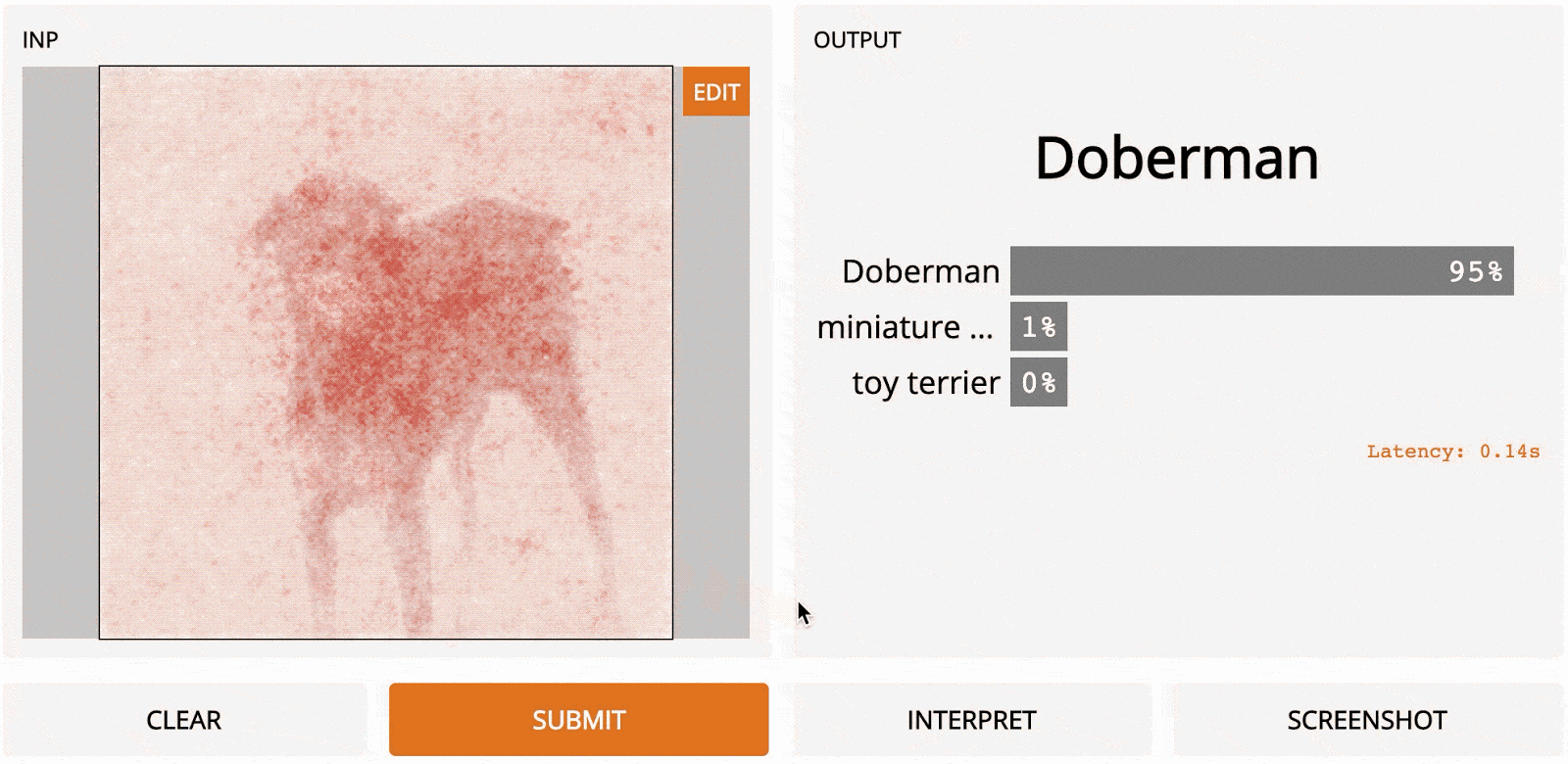
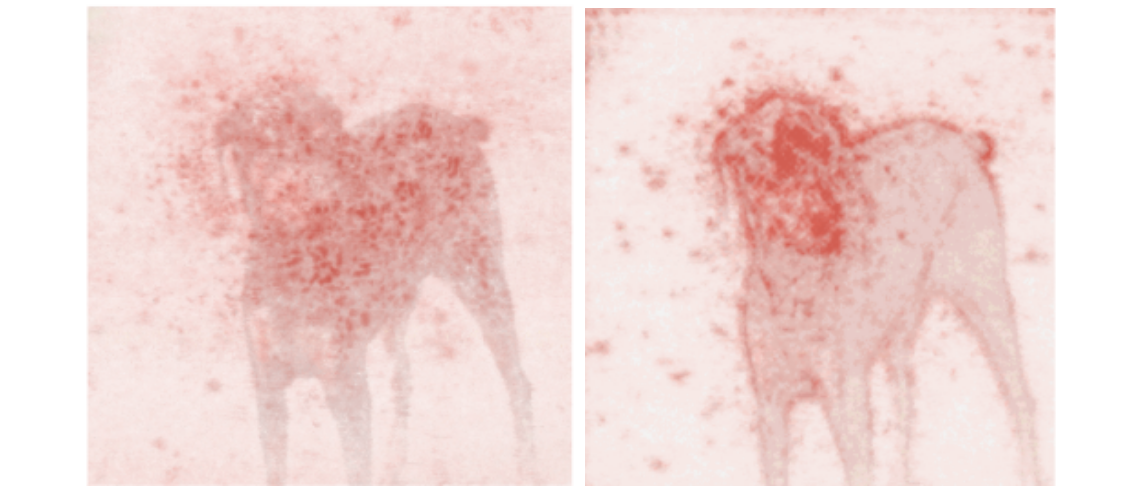
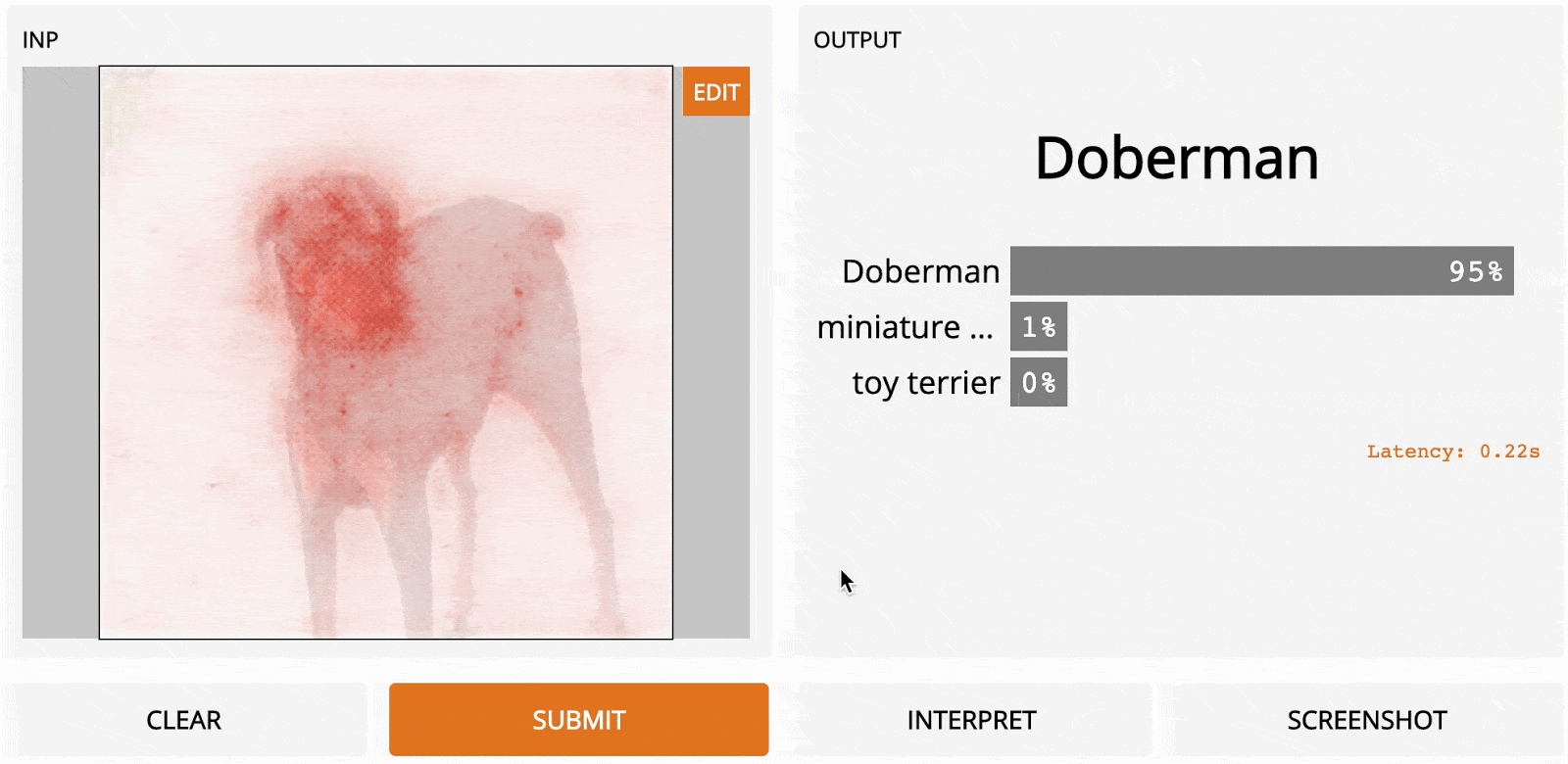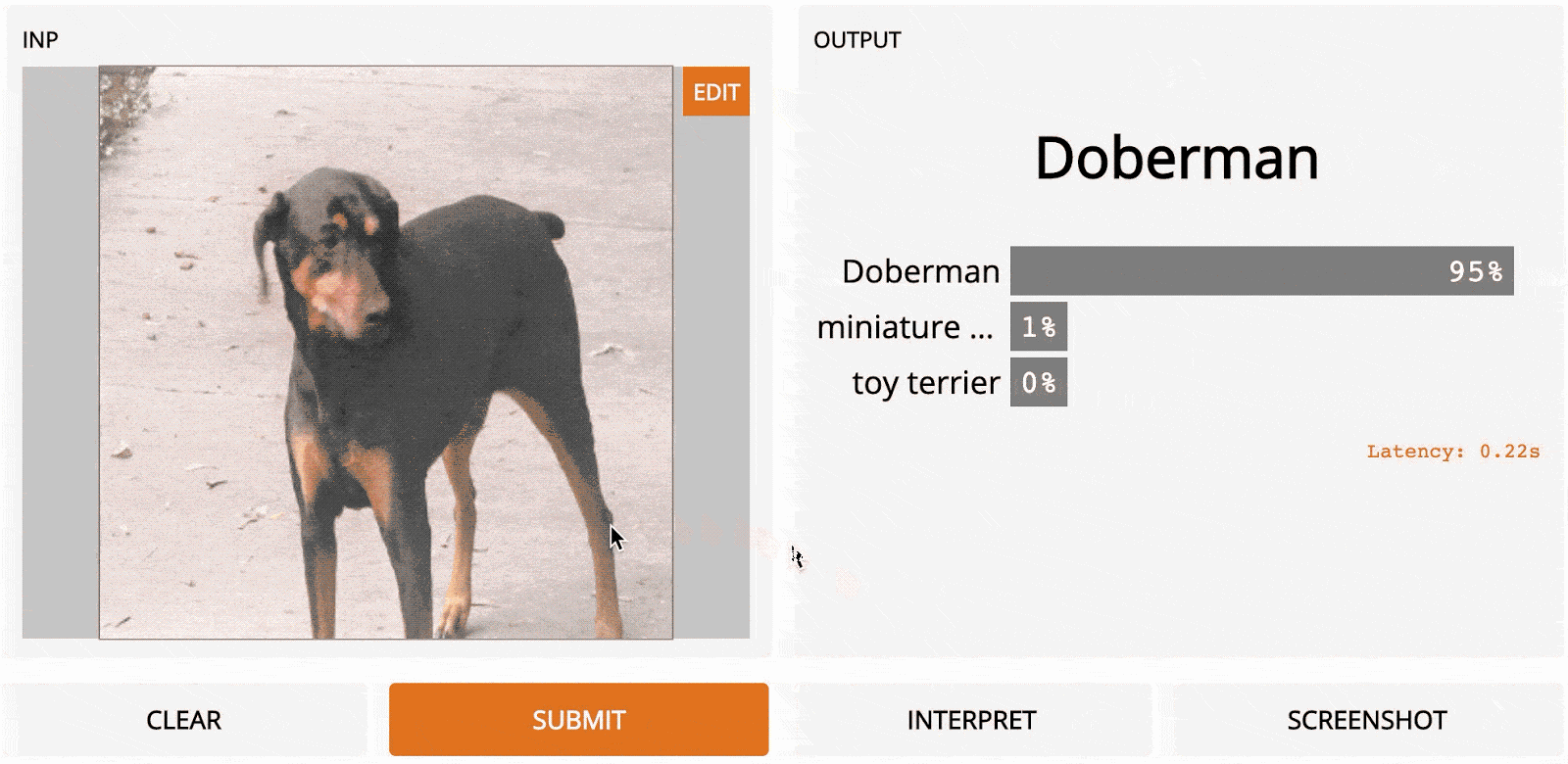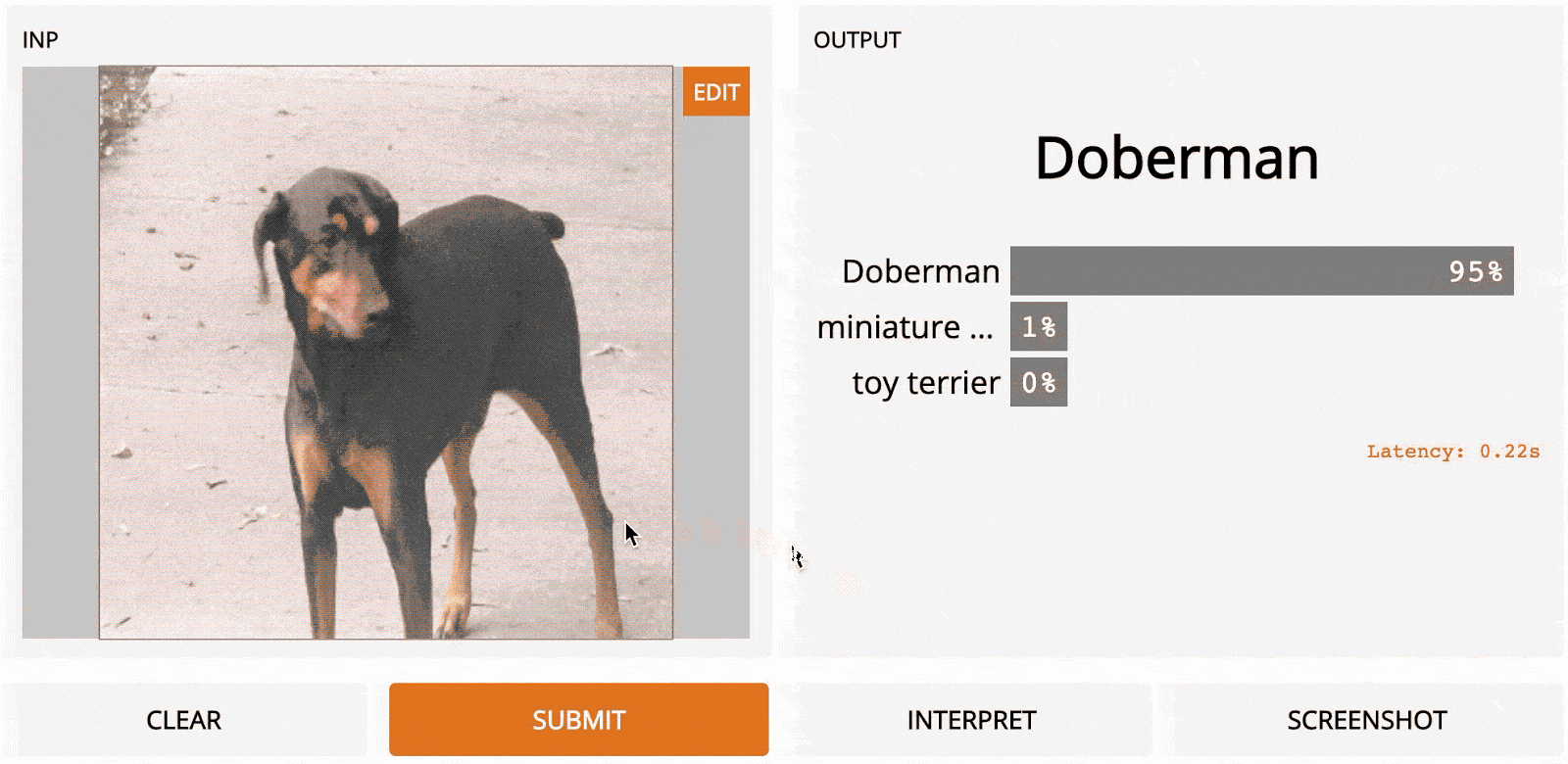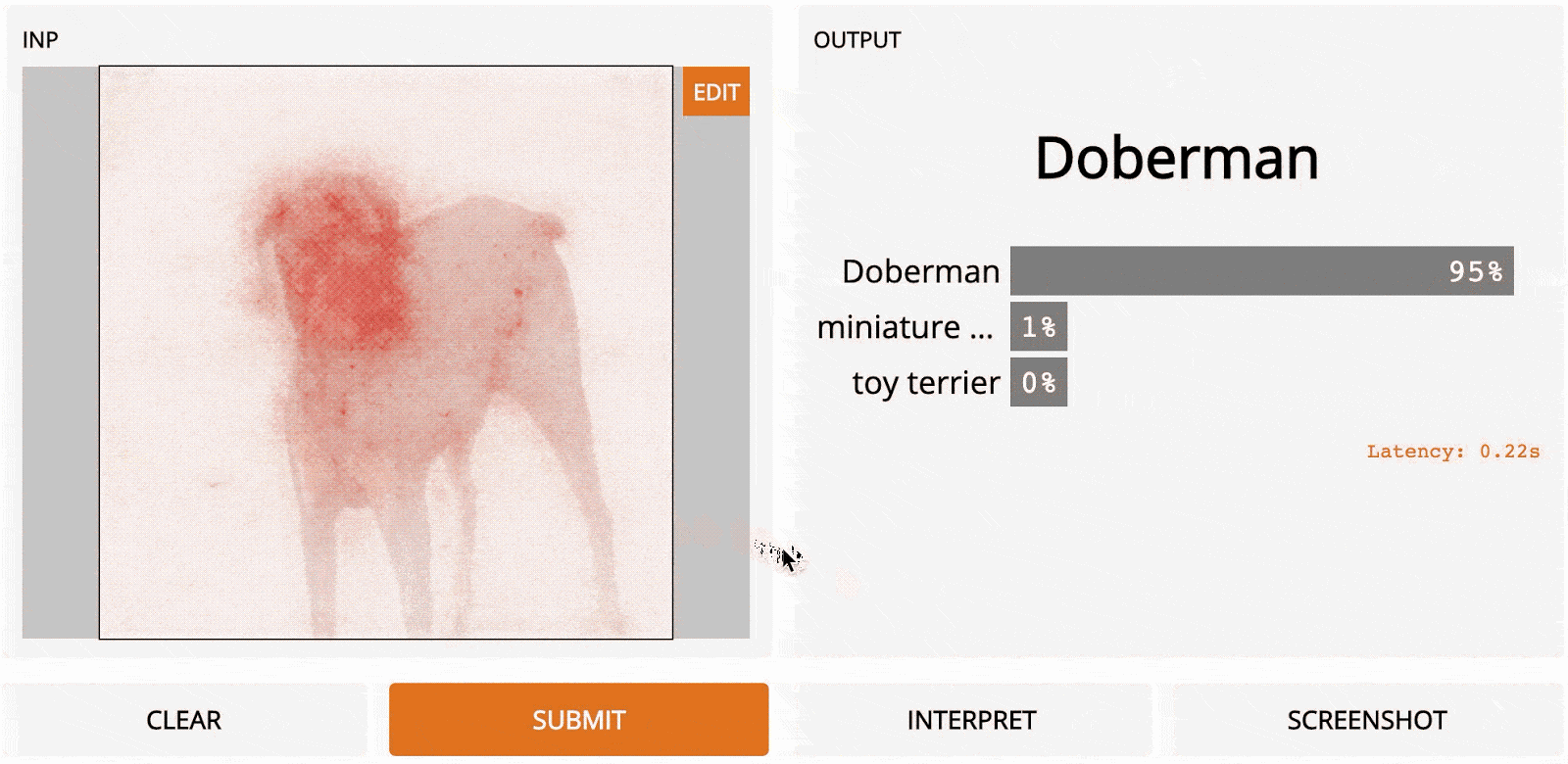
LOO – это простой для понимания метод; это первый алгоритм, который может прийти в голову, если вы разрабатываете метод интерпретации с нуля. Идея заключается в том, чтобы сначала разделить входное изображение на несколько субрегионов меньше. Затем вы делаете серию прогнозов, каждый раз маскируя (т. е. устанавливая значения пикселей на ноль одного из субрегионов. Каждой области присваивается оценка важности, которая зависит от того, насколько сильно «замаскированность» области повлияла на прогноз по сравнению с исходным изображением. Интуитивно можно сказать, что эти баллы количественно определяют, какие регионы несут наибольшую ответственность за прогноз. Итак, если мы сегментируем изображение на 9 субрегионов в сетке 3x3, вот как будет выглядеть LOO:
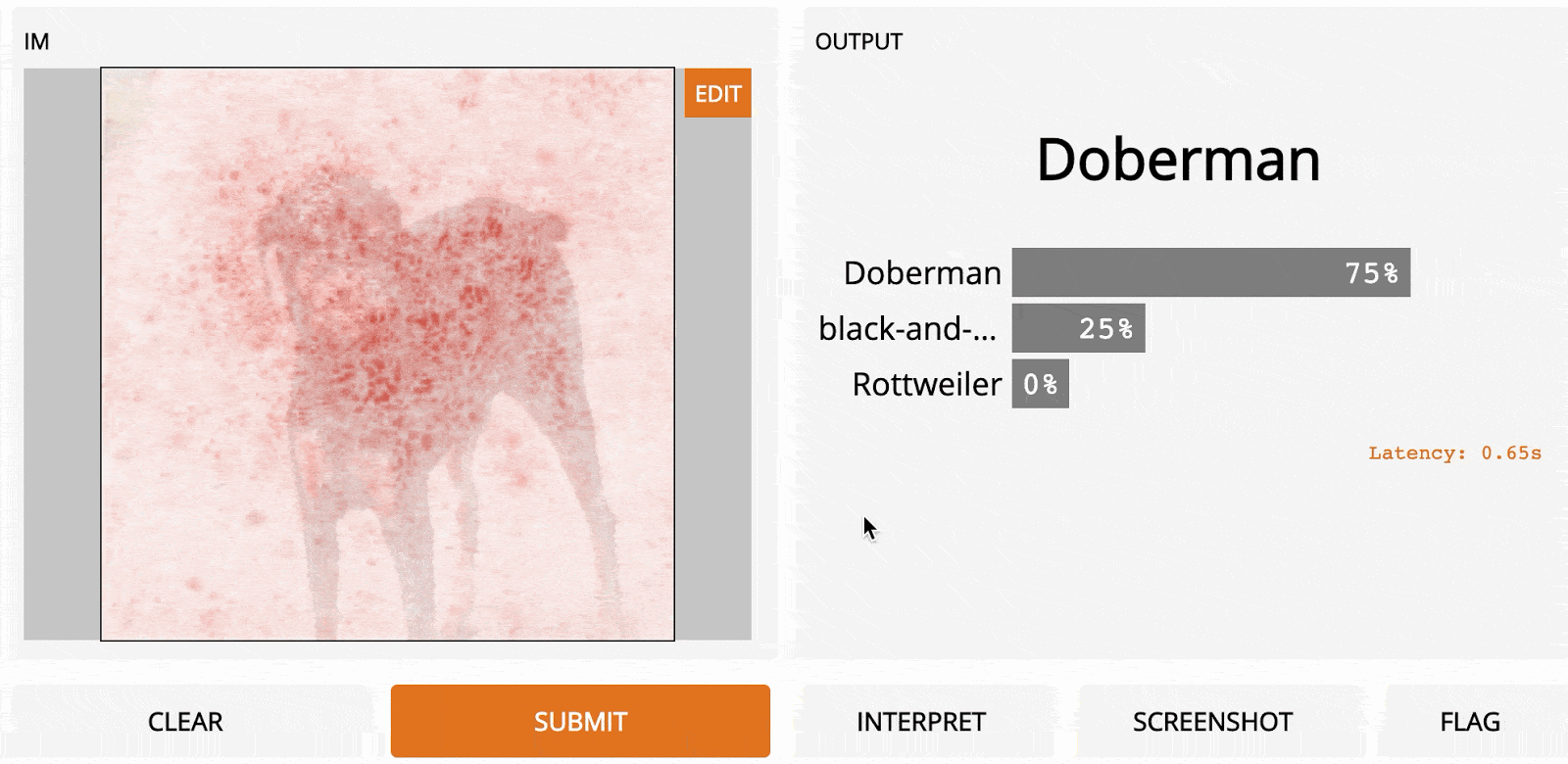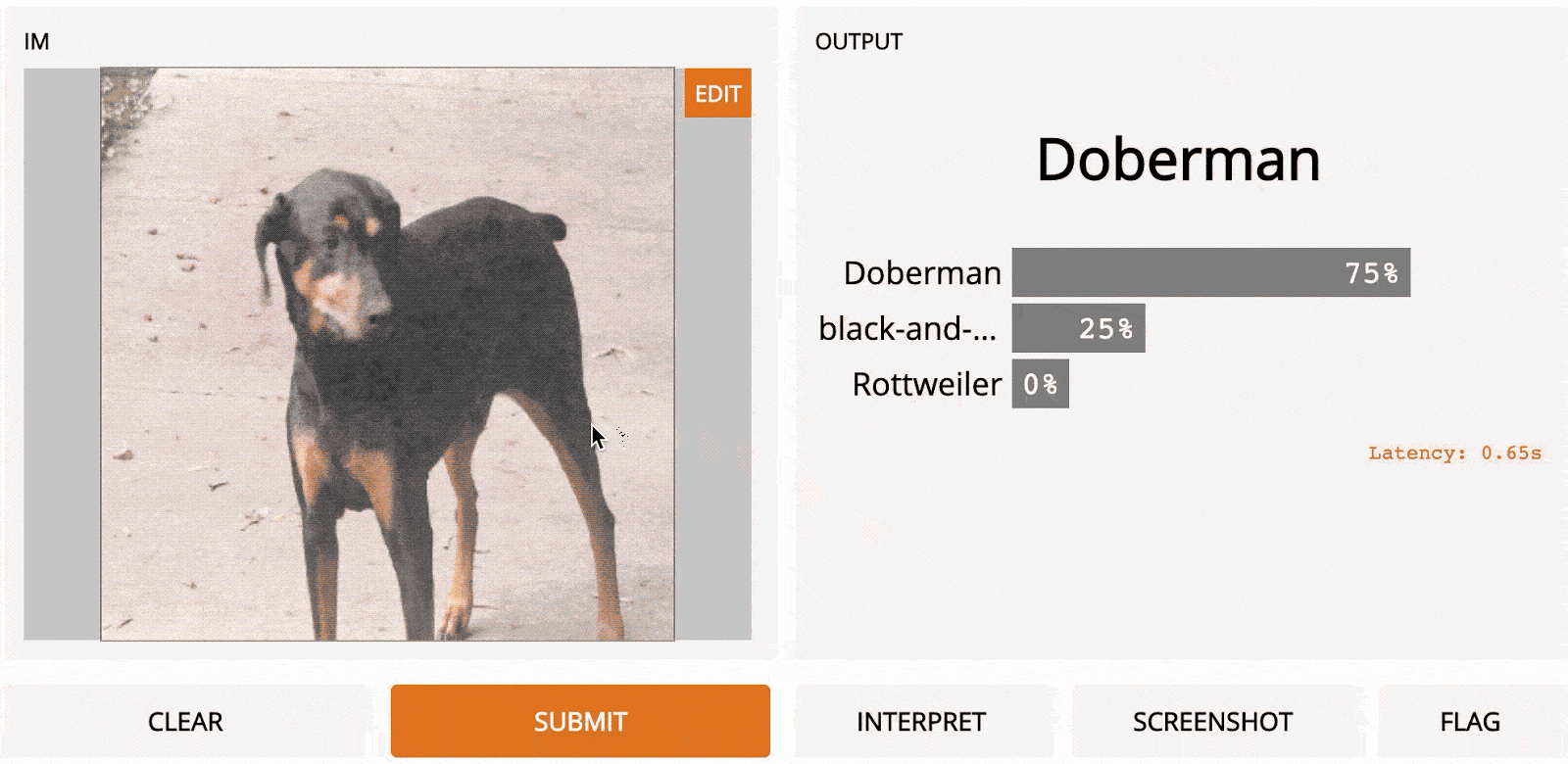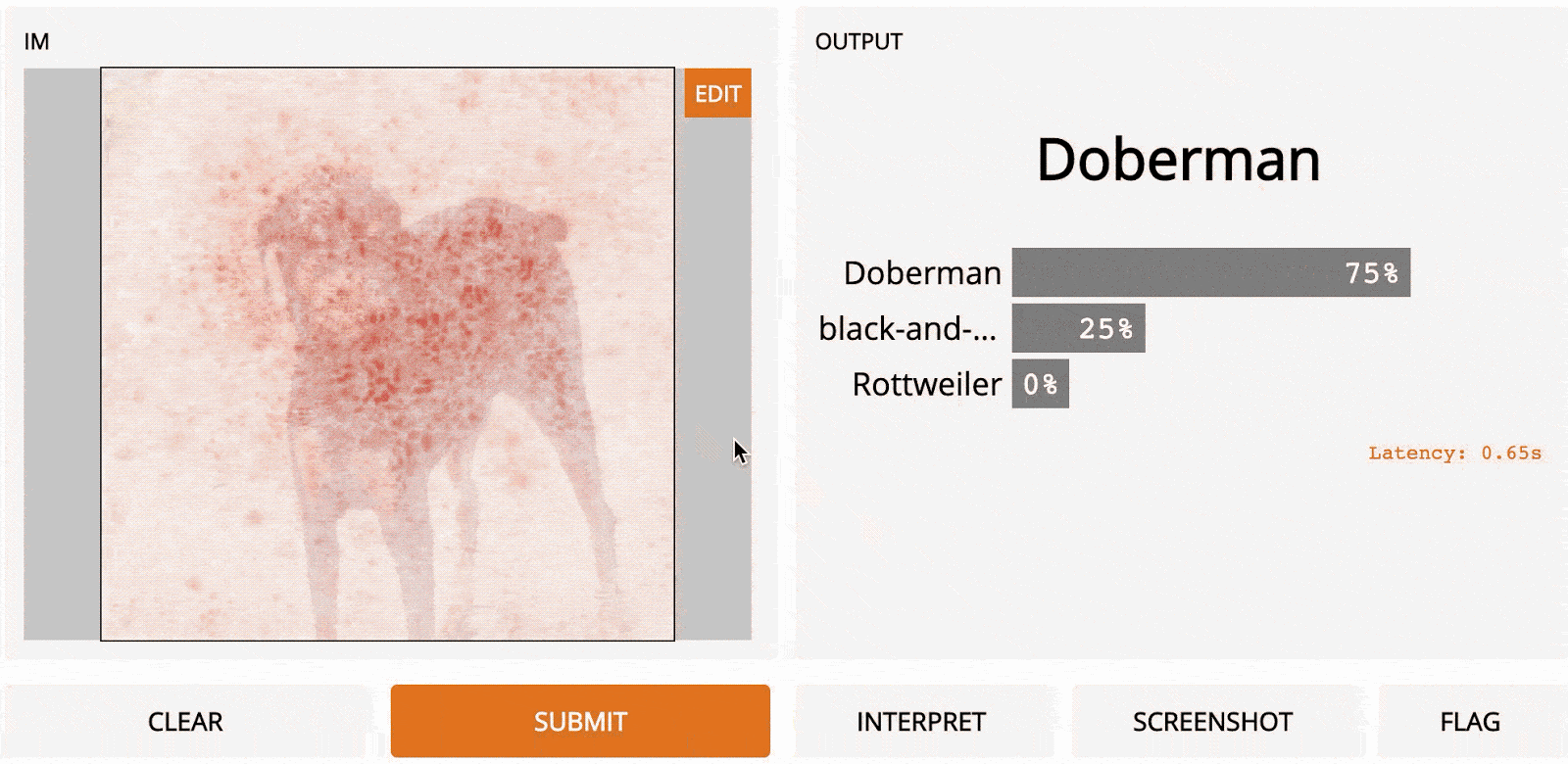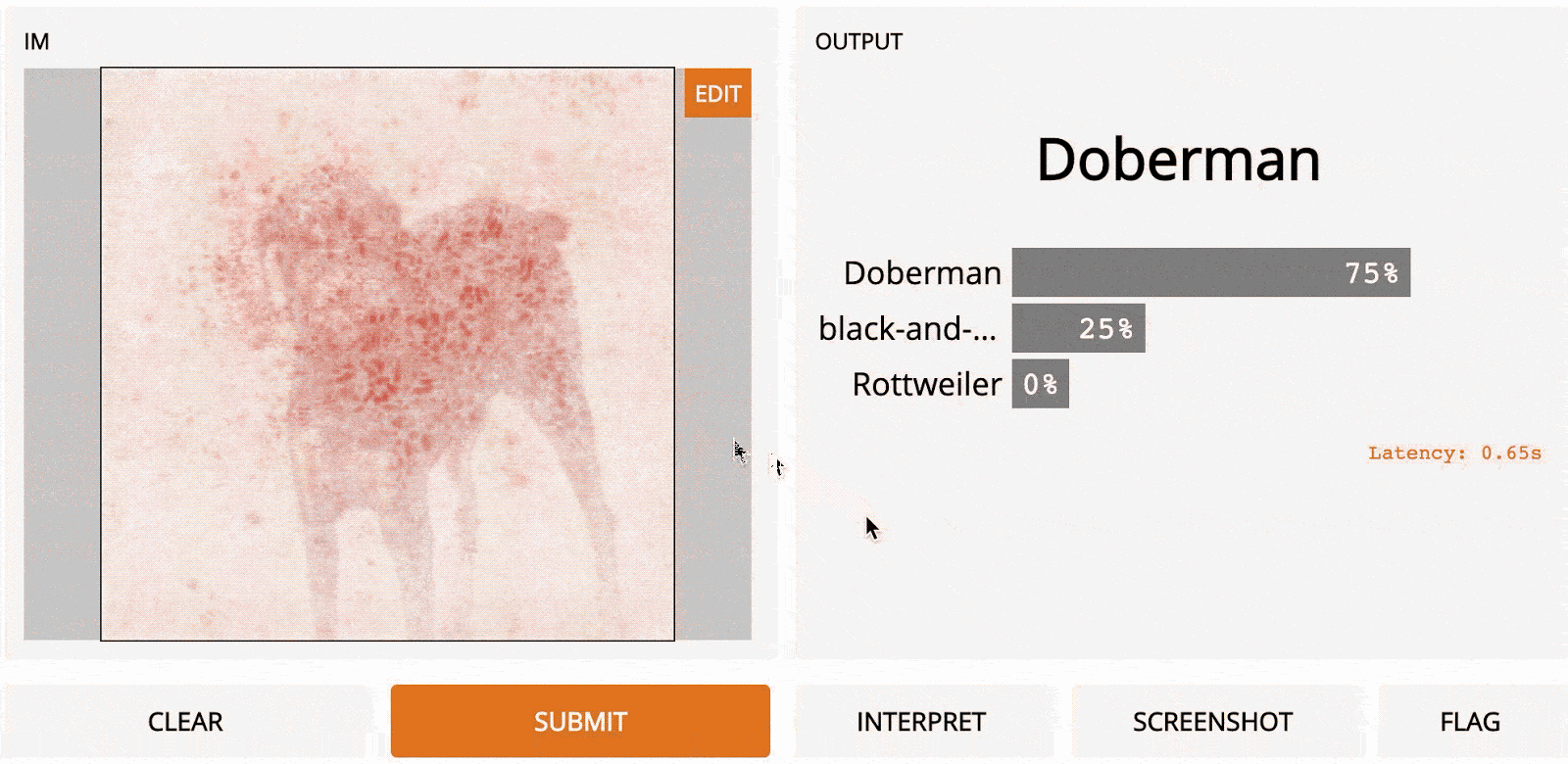
Самые тёмные красные квадраты – это те, которые больше всего изменили выходной сигнал, а самые светлые имеют наименьший эффект. В этом случае, когда регион сверху по центру был замаскирован, уверенность в прогнозе упала больше всего – с первоначальных 95 до 67 %. Если сегментировать лучше (например, используя супер-пиксели вместо сеток), то получим довольно разумную карту заметности, на которой подсвечены морда, уши и хвост добермана.
LOO – простой, но мощный метод. В зависимости от разрешения изображения и способа сегментации может быть получен очень точный и полезный результат. Здесь LOO применяется к изображению золотого ретривера разрешением 1100 ? 825, как и прогнозировалось с помощью InceptionNet.
Одним из огромных преимуществ LOO является то, что методу не нужен доступ к внутреннему содержанию модели и он может работать даже над другими задачами компьютерного зрения, кроме распознавания, что делает его гибким многоцелевым инструментом. Но каковы недостатки? Во-первых, метод медленный. Каждый раз, когда область маскируется, мы делаем вывод на изображение. Чтобы получить карту заметности с разумным разрешением, размер вашей маски должен быть небольшим. Таким образом, если сегментировать изображение на 100 областей, то для получения тепловой карты понадобится 100-кратное время вывода. С другой стороны, если у вас слишком много субрегионов, то маскировка любого из них не обязательно приведёт к большой разнице в прогнозе. Это второе ограничение LOO, которое заключается в том, что метод не учитывает взаимозависимости между областями. Итак, давайте посмотрим на гораздо более быструю и немного более увлекательную технику: Vanilla Gradient Ascent.
Vanilla Gradient Ascent [2013]
Метод был представлен в работе Модели классификации визуализируемых изображений и карты заметности [2013]. Существует концептуальная связь между LOO и градиентным подъёмом. С помощью LOO мы рассмотрели, как изменялся вывод, когда мы маскировали каждую область на изображении, по очереди. При градиентном подъёме мы вычисляем, как на выходной сигнал влияет каждый отдельный пиксель, но не по очереди, а все сразу. Как это делается? С помощью модифицированной версии обратного распространения. С помощью стандартного обратного распространения мы вычисляем градиент потери модели по отношению к весам. Градиент – это вектор, который содержит значение для каждого веса, отражающее, насколько небольшое изменение этого веса повлияет на вывод, по сути, говорящее о том, какие веса наиболее важны для потери. Принимая отрицательную величину этого градиента, мы минимизируем потери во время обучения. Для градиентного подъёма мы вместо этого берем градиент оценки класса относительно входных пикселей, который указывает, какие входные пиксели наиболее важны при классификации изображения. Этот единственный шаг по сети даёт нам значение важности для каждого пикселя, который мы отображаем в виде тепловой карты, как показано ниже.
Примеры карт заметности из работы Simonyan et al., рассчитанных с помощью одного прохода обратного распространения. Вот как это выглядит на нашем изображении добермана:
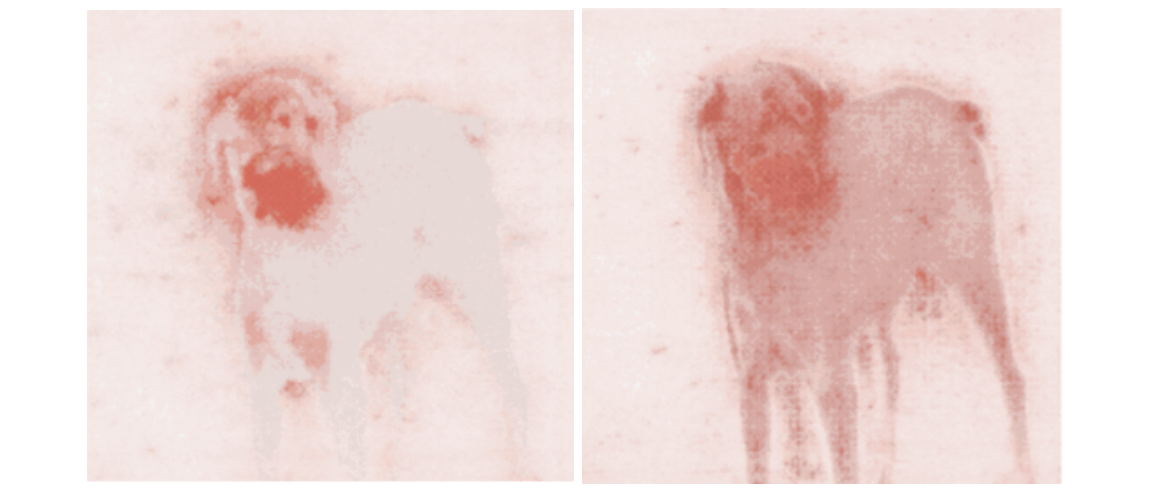
Главное преимущество здесь – скорость; поскольку нам нужно сделать только один проход по сети, градиентный подъём намного быстрее LOO, хотя полученная тепловая карта немного зернистая.
LOO (слева) по сравнению с Vanilla Gradient Ascent (справа) на изображении добермана. Здесь модель – InceptionNet. Хотя градиентный подъём работает, было обнаружено, что эта первоначальная формулировка, vanilla gradient ascent, имеет существенный недостаток: распространяет отрицательные градиенты, которые в конечном счёте вызывают помехи и шумный вывод. Чтобы решить эти проблемы, был предложен новый метод – «направленное обратное распространение ошибки».
Направленное обратное распространение [2014]
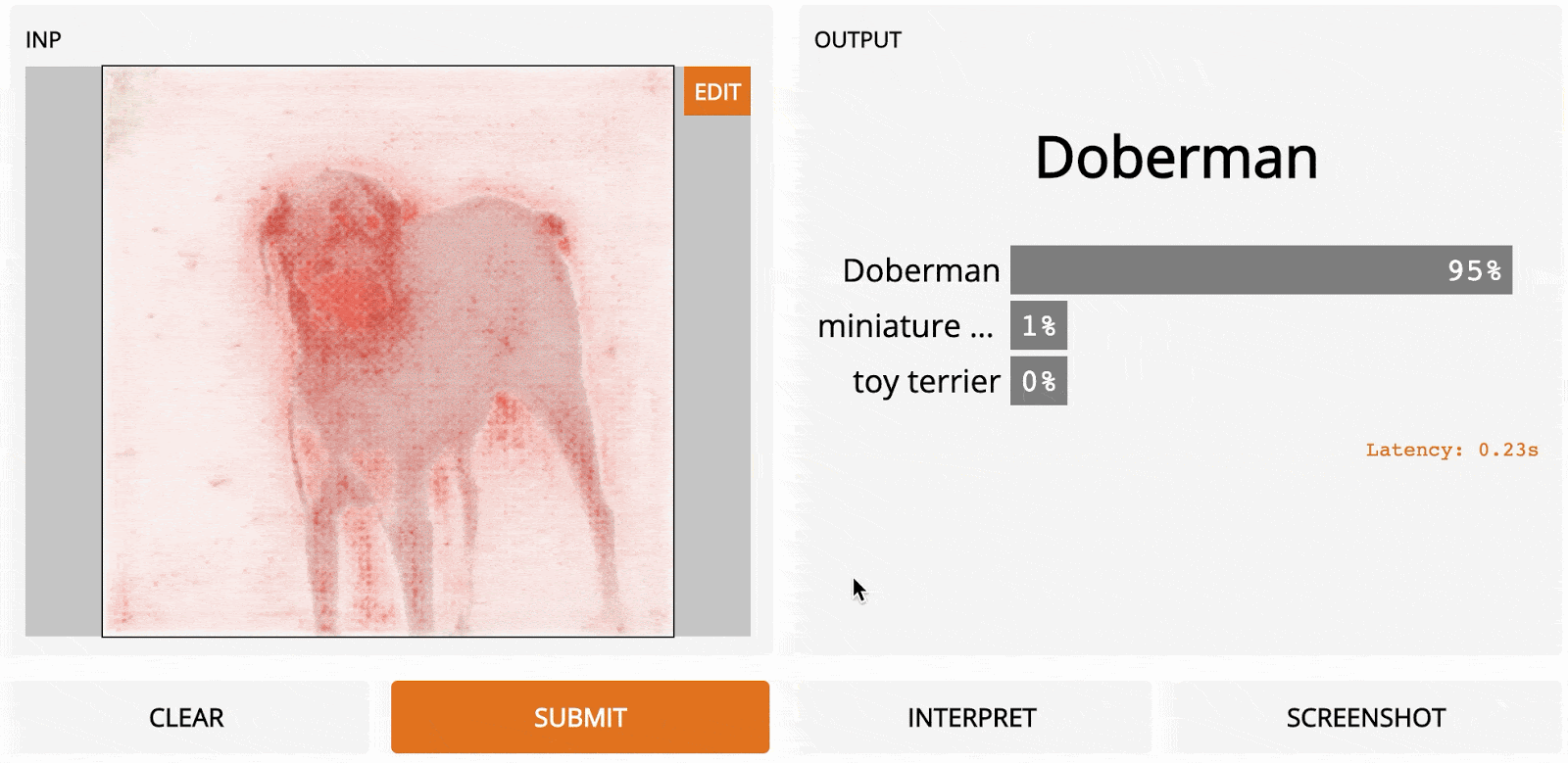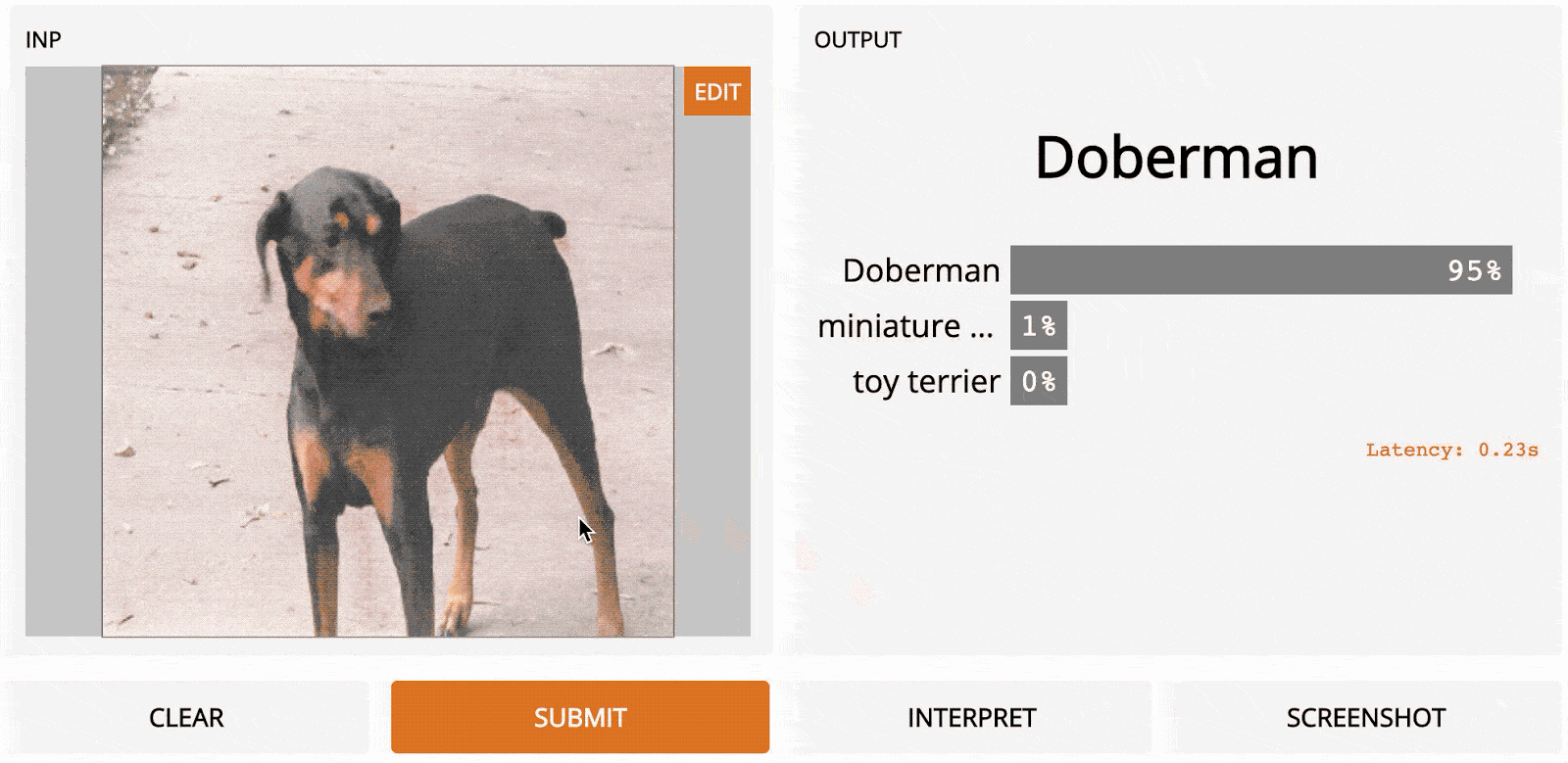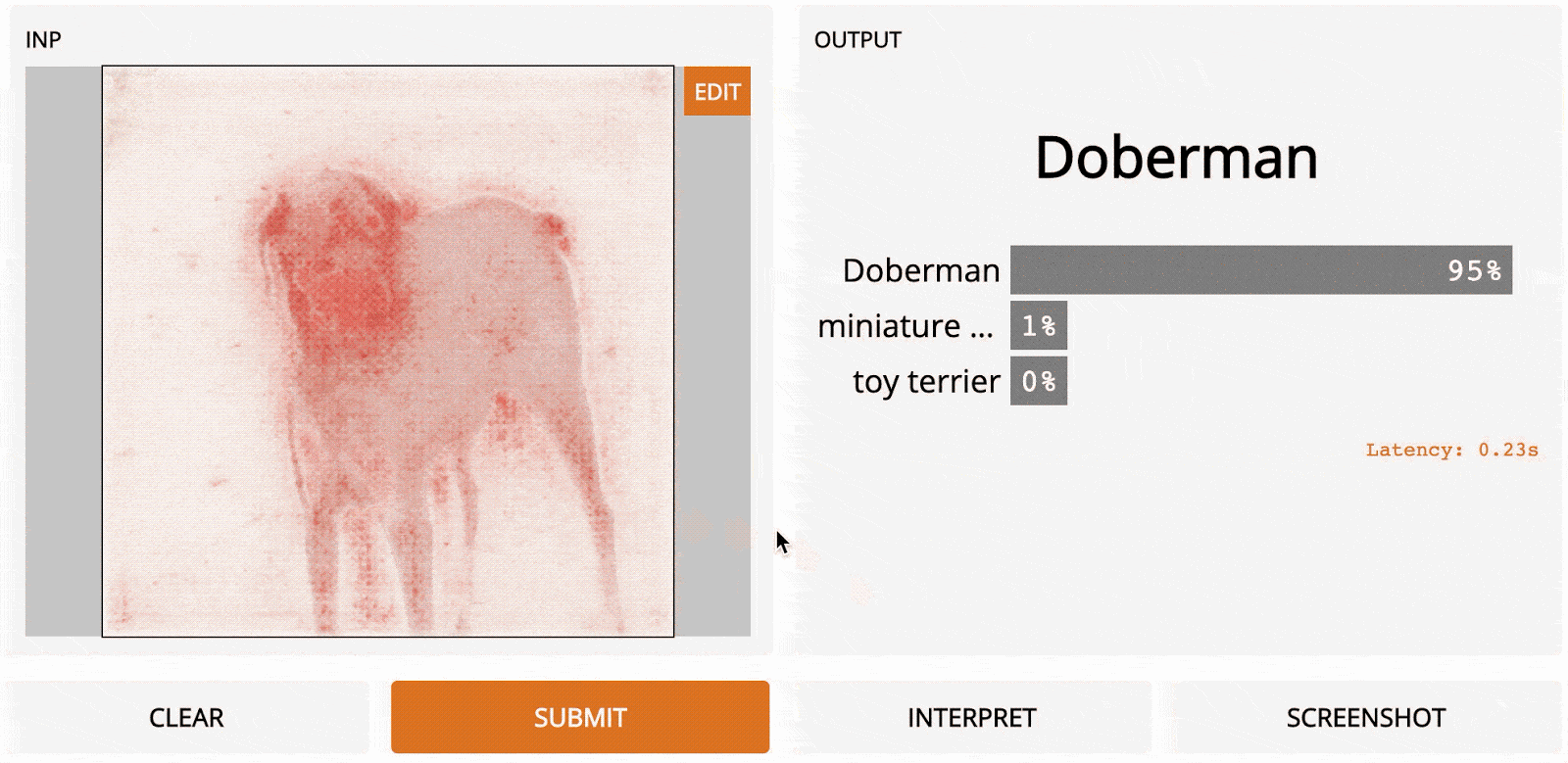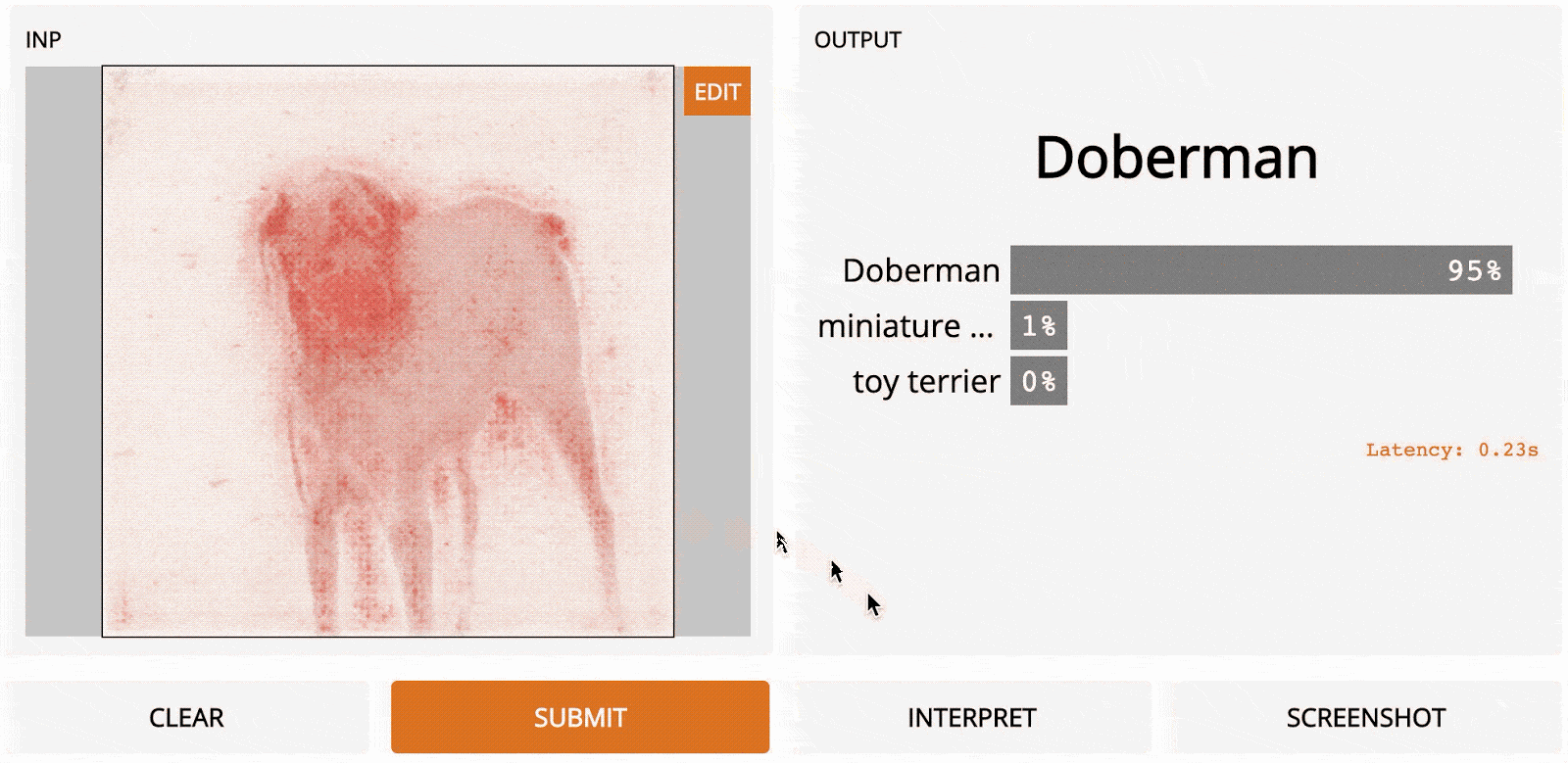
Направленное обратное распространение было опубликовано в Striving for Simplicity: The All Convolutional Net [2014], где авторы предложили добавить дополнительный управляющий сигнал от более высоких уровней к обычному шагу обратного распространения. По сути, этот метод блокирует обратный поток градиентов от нейронов всякий раз, когда выходной сигнал отрицательный, оставляя только те градиенты, которые приводят к увеличению вывода, что в конечном счёте приводит к не столь шумной интерпретации.
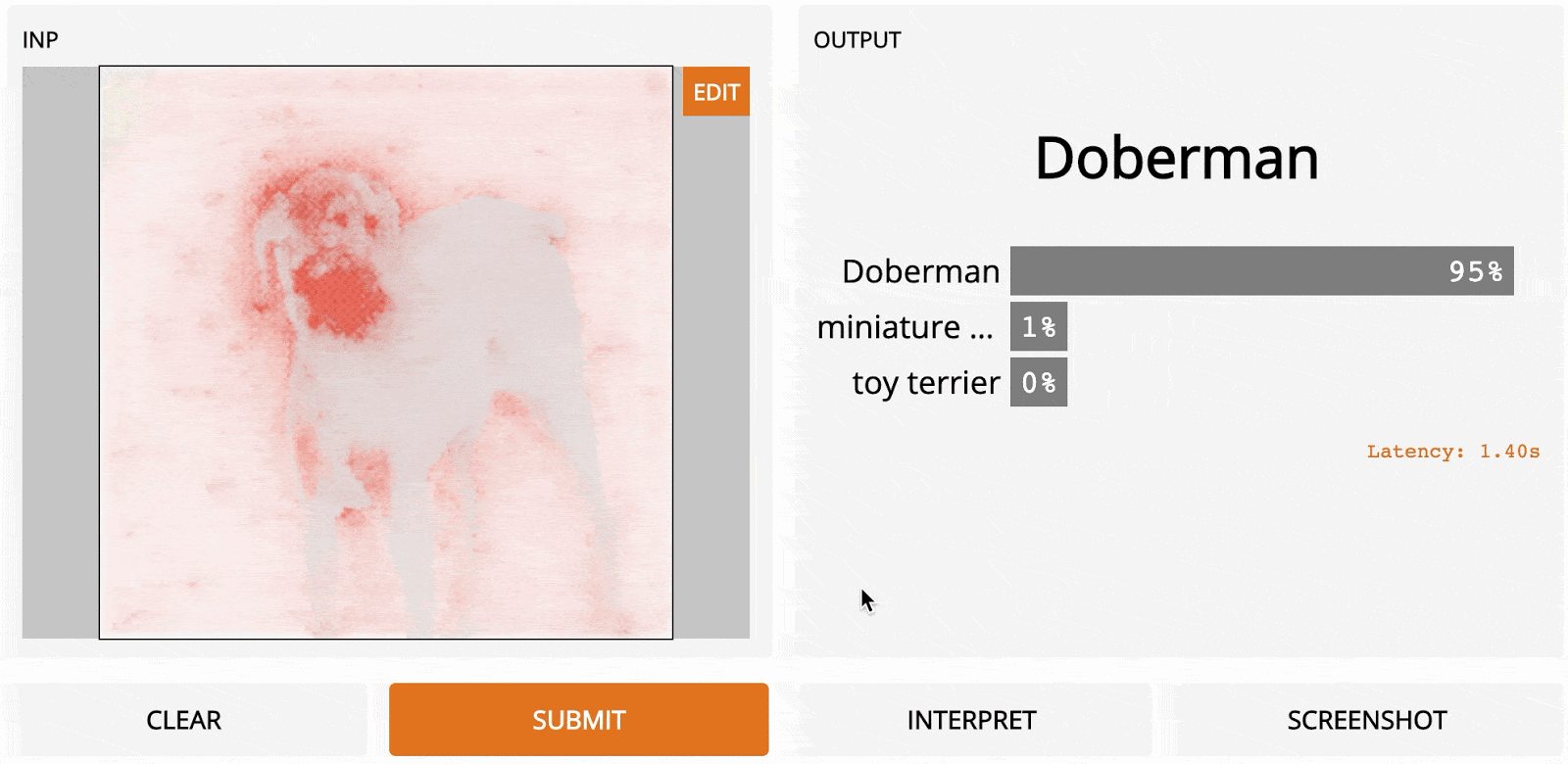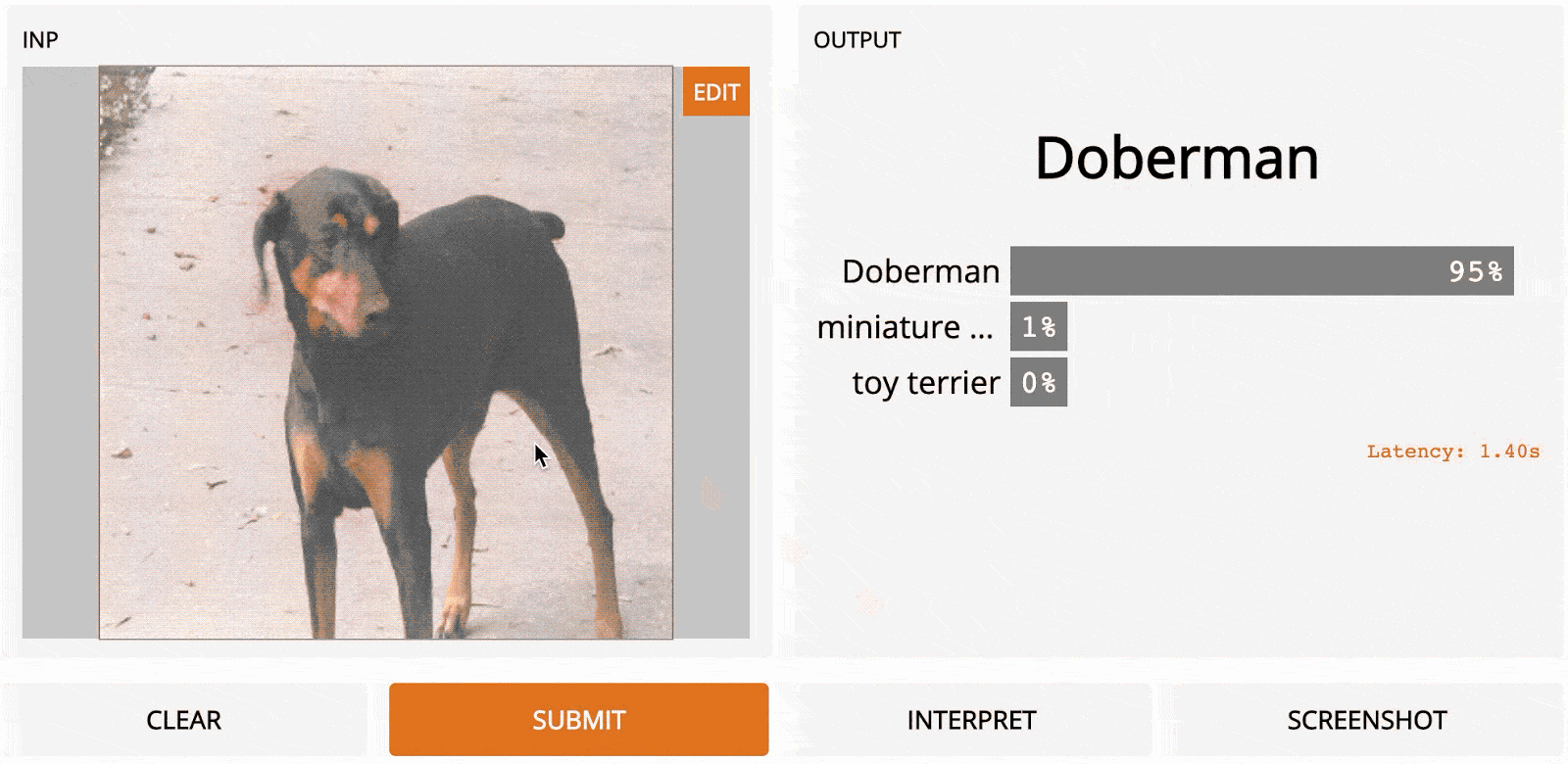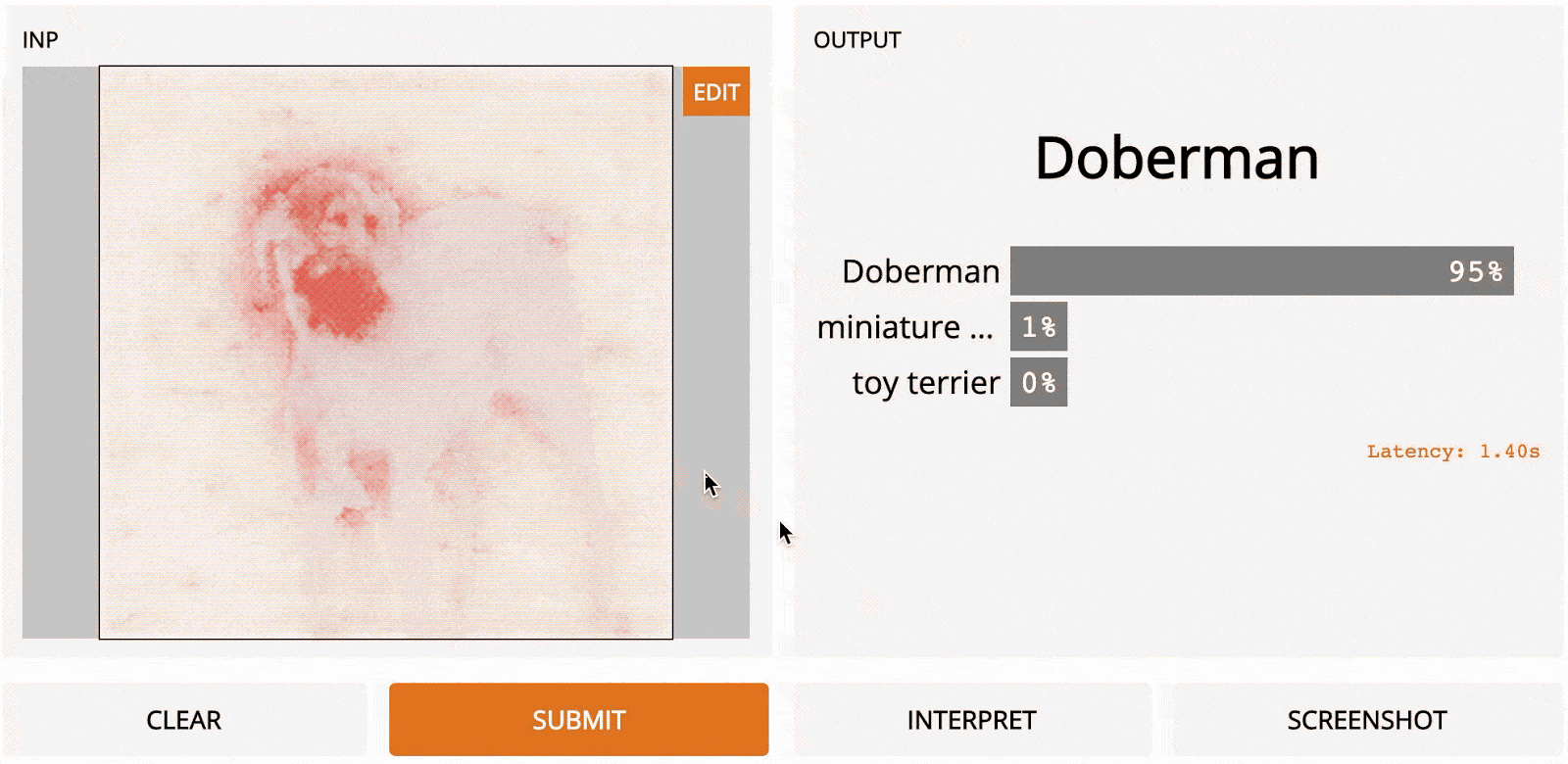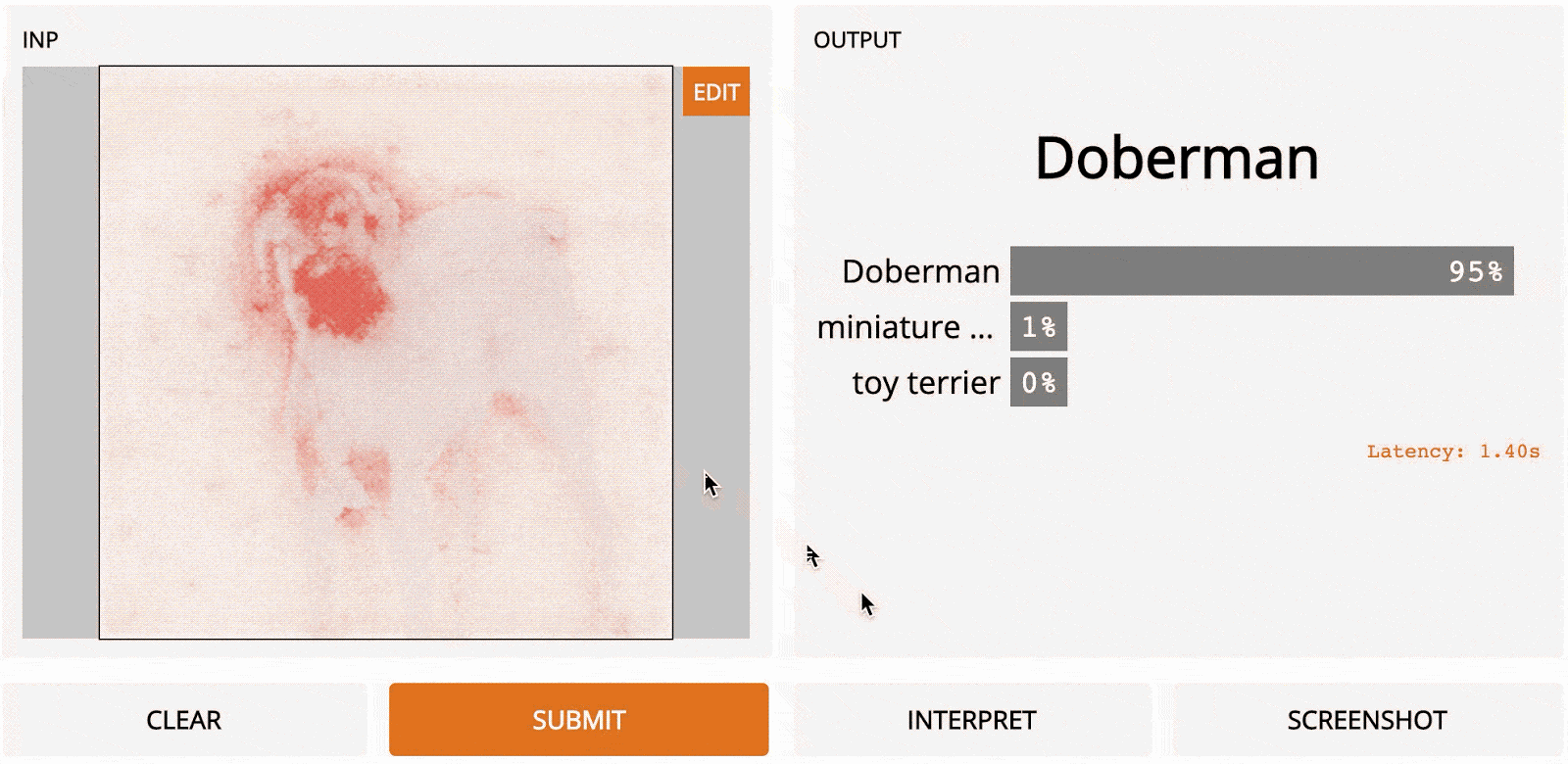
На этом изображении мы показываем градиенты с обратным распространением (слева) для данного слоя, выходные данные которого показаны справа. В верхнем слое – обычные градиенты. В нижнем слое – управляемое обратное распространение, которое обнуляет градиенты всякий раз, когда результат отрицательный (рисунок взят из работы Springenberg et al). Направленное обратное распространение работает примерно так же быстро, как Vanilla Gradient Ascent, поскольку требует только одного прохода по сети, но обычно даёт результат чище, особенно по краям объекта. Этот метод особенно хорошо работает по сравнению с другими методами в нейронных архитектурах, где нет слоёв c уменьшением размеров изображения путём сложения значений блоков пикселей.
Vanilla Gradient Ascent (слева) по сравнению с направленным обратным распространением (справа) на изображении добермана. Здесь модель – InceptionNet. Однако было обнаружено, что всё ещё существует серьезная проблема с Vanilla Gradient Ascent и управляемым обратным распространением: они не работают так хорошо, когда в изображении присутствуют два или более классов, что часто бывает на естественных изображениях.
Grad-CAM [2016]
Grad-CAM, или Gradient-Weighted Class Activation Mapping, представили в Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization [2016]. Здесь авторы обнаружили, что качество интерпретаций улучшилось, когда градиенты брались на каждом фильтре последнего свёрточного слоя, а не на уровне класса (но всё же по отношению к входным пикселям). Чтобы получить интерпретацию, специфичную для класса, Grad-CAM вычисляет средневзвешенное значение этих градиентов с весом, основанным на вкладе фильтра в оценку класса. Результат, как показано ниже, намного лучше, чем у только управляемого обратного распространения.
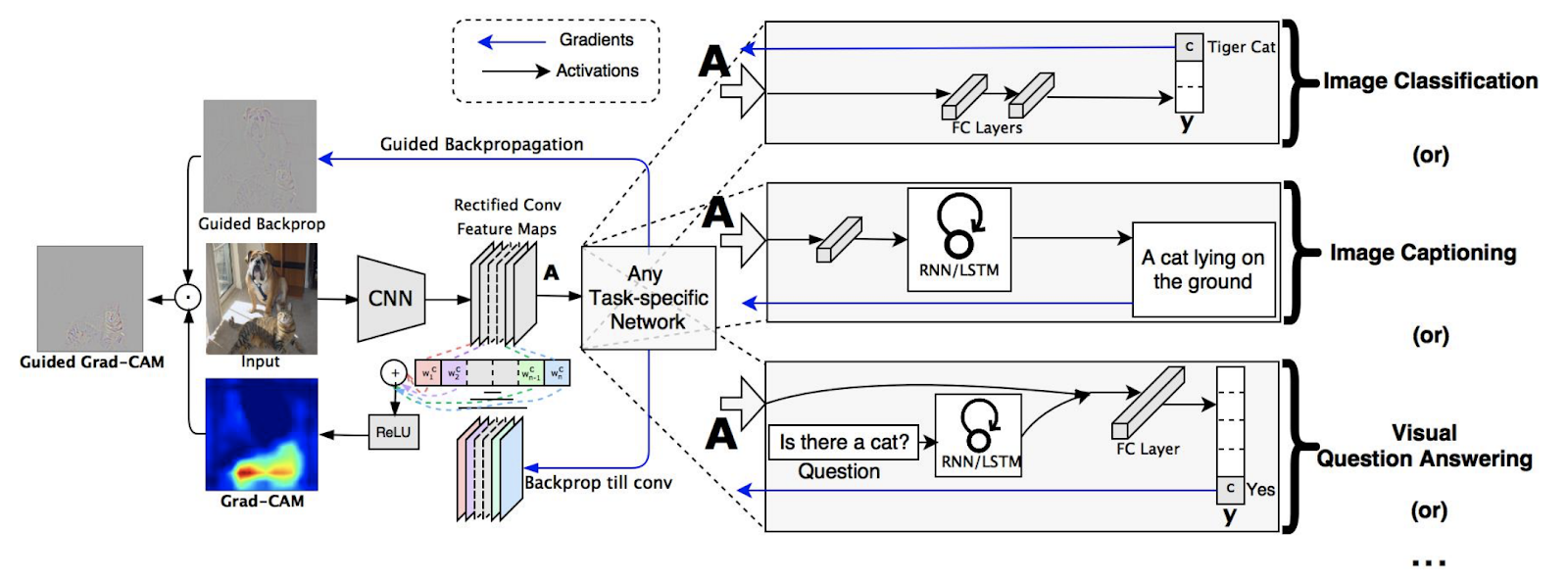
Исходное изображение с двумя классами («Кошка» и «Собака») передаётся через направленное обратное распространение, но полученная тепловая карта выделяет оба класса. Как только Grad-CAM применяется в качестве фильтра, управляемый Grad-CAM создаёт тепловую карту с высокой разрешающей способностью – дискриминативную (рисунок взят из работы Selvaraju et al). Далее авторы обобщили Grad-CAM для работы не только на целевой класс, но и на любую целевую «концепцию». Это означало, что Grad-CAM можно было использовать для интерпретации того, почему модель для подписывания изображений предсказала конкретную подпись, или даже для обработки моделей, которые принимают несколько входов, например модель визуального вопроса-ответа. Благодаря такой гибкости Grad-CAM стал довольно популярным. Ниже представлен обзор его архитектуры.
Обзор Grad-CAM: сначала мы продвигаем изображение вперёд. Градиенты устанавливаются на ноль для всех классов, кроме желаемого (тигровый кот), для которого установлено значение 1. Затем этот сигнал обратно распространяется на ректифицированные свёрточные карты признаков, представляющих интерес, которые мы комбинируем, чтобы вычислить грубую локализацию Grad-CAM (синяя тепловая карта), которая показывает, куда должна смотреть модель, чтобы принять конкретное решение. Наконец, мы точечно умножаем тепловую карту на направленное обратное распространение, чтобы получить визуализации направленного Grad-CAM как с высоким разрешением, так и специфичные для концепции (рисунок и описание взяты из работы Selvaraju et al).
SmoothGrad [2017]
Тем не менее вы могли заметить, что при использовании всех предыдущих методов результаты всё ещё не очень чёткие. SmoothGrad, представленный в SmoothGrad: removing noise by adding noise [2017] ], является модификацией предыдущих методов. Идея довольно проста: авторы заметили, что если входное изображение сначала возмущается шумом, то возможно вычислить градиенты один раз для каждой версии возмущённого ввода, а затем усреднить карты чувствительности вместе. Это приводит к гораздо более чёткому результату, хотя выполняется дольше. Вот как направленное обратное распространение выглядит в сравнении с SmoothGrad:
Стандартное направленное обратное распространение (слева) и SmoothGrad (справа) на изображении добермана. Здесь модель – InceptionNet. Когда вы сталкиваетесь со всеми этими методами интерпретации, какой из них выбрать? Или, когда методы противоречат друг другу, существует ли один метод, который теоретически может быть лучше других? Давайте посмотрим на интегрированные градиенты.
Интегрированные градиенты [2017]
В отличие от предыдущих статей авторы Axiomatic Attribution for Deep Networks [2017] исходят из теоретической основы интерпретации. Они сосредоточены на двух аксиомах: чувствительности и инвариантности реализации, которым, по их мнению, должен удовлетворять хороший метод интерпретации. Аксиома чувствительности означает, что, если два изображения отличаются ровно одним пикселем (но все остальные пиксели у них являются общими) и дают разные прогнозы, алгоритм интерпретации должен давать ненулевую атрибуцию этому пикселю. Аксиома инвариантности реализации означает, что основная реализация алгоритма не должна влиять на результат метода интерпретации. Учёные используют эти принципы для разработки нового метода атрибуции, называемого интегрированными градиентами (IG). IG начинается с базового изображения (обычно это полностью затемнённая версия входного изображения) и увеличивает яркость до тех пор, пока исходное изображение не будет восстановлено. Градиенты оценок классов по отношению к входным пикселям вычисляются для каждого изображения и усредняются, чтобы получить глобальное значение важности для каждого пикселя. Помимо теоретических свойств IG, таким образом, также решает другую проблему с Vanilla Gradient Ascent: насыщенные градиенты (saturated gradient). Поскольку градиенты являются локальными, они отражают не глобальную важность пикселей, а только чувствительность в определённой точке ввода. Изменяя яркость изображения и вычисляя градиенты в разных точках, IG может получить более полную картину важности каждого пикселя.
Стандартное управляемое обратное распространение (слева) и интегрированные градиенты (справа) на изображении добермана, оба сглаженные с помощью SmoothGrad. Здесь модель – InceptionNet. Хотя при этом обычно получаются более точные карты чувствительности, метод работает медленнее и вводит два новых дополнительных гиперпараметра: выбор базового изображения и количество шагов, через которые создаются интегрированные градиенты. Можем ли мы обойтись без этих параметров?
Размытые интегрированные градиенты [2020]
Это то, к чему стремится последний метод интерпретации – размытые интегрированные градиенты. Метод, представленный в работе Attribution in Scale and Space [2020], был предложен для решения конкретных проблем с интегрированными градиентами, включая устранение параметра 'baseline' и удаление некоторых визуальных артефактов, которые имеют тенденцию появляются в интерпретациях. Метод размытых интегрированных градиентов работает, измеряя градиенты по серии всё более размытых версий исходного входного изображения (а не затемнённых версий изображения, как это делают интегрированные градиенты). Хотя это может показаться незначительной разницей, авторы утверждают, что такой подход теоретически более оправдан, поскольку размытие изображения не может внести новые артефакты в интерпретацию, как это может сделать выбор базового изображения.
Стандартные интегрированные градиенты (слева) и размытые интегрированные градиенты (справа) на изображении добермана, оба сглажены с помощью SmoothGrad. Здесь модель – InceptionNet.
Заключение
2010-е годы были плодотворным десятилетием для методов интерпретации машинного обучения, и теперь у нас есть богатый набор методов, объясняющих поведение нейронных сетей. Мы сравнили их в этом посте и обязаны нескольким замечательным библиотекам, в частности Gradio, для создания интерфейсов, которые вы видите на GIF и PAIR-коде реализаций алгоритмов из работ на TensorFlow. Для всех интерфейсов используется классификатор изображений Inception Net . Весь код вставки этого поста в блог находится в этом блокноте Jupyter и в Google Colab . Попробуйте интерактивный интерфейс с управляемым обратным распространением здесь. Также если вы хотите узнать больше о сфере машинного обучения и на что оно способно — приходите учиться, а промокод HABR, дающий +10% к скидке на баннере, вам в этом поможет.