Привет, Хабр.
Довольно интересным направлением "прикладной статистики" и NLP (Natural Languages Processing а вовсе не то что многие сейчас подумали) является анализ текста. Появилось это направление задолго до компьютеров, и имело вполне практическую цель: определить автора того или иного текста. С помощью ПК это впрочем, гораздо легче и удобнее, да и результаты получаются весьма интересные. Посмотрим, какие закономерности можно выявить с помощью совсем простого кода на Python.
Для тех кому интересно, продолжение под катом.
История
Одной из первых практических задач было определение авторства политических текстов The Federalist Papers, написанных в США в 1780 годах. Их авторами было несколько человек, но кто есть кто, окончательно было неизвестно. Первый подход к построению кривой распределения длины слов был предпринят еще в 1851 г, и можно представить, какой это был объем работы. Сейчас, слава богу, всё проще. Я рассмотрю простейший способ анализа с помощью несложных расчетов и пакета Natural Language Toolkit, что в совокупности с matplotlib позволяет получить интересные результаты буквально в несколько строк кода. Мы посмотрим, как все это можно визуализировать и какие закономерности можно увидеть.
Те, кому интересны результаты, главу "код" могут пропустить.
Код
Перейдем к практическому примеру. Возьмем для анализа следующий текст:
s = """Ежик сидел на горке под сосной и смотрел на освещенную лунным светом долину, затопленную туманом. Красиво было так, что он время от времени вздрагивал: не снится ли ему все это?"""Подключим библиотеку nltk:
import nltk nltk.download('punkt') tokens = nltk.word_tokenize(s)Массив tokens содержит все слова и знаки пунктуации строки:
['Ежик', 'сидел', 'на', 'горке', 'под', 'сосной', 'и', 'смотрел', 'на', 'освещенную', 'лунным', 'светом', 'долину', ',', 'затопленную', ...]Отфильтруем массив, удалив из него знаки препинания и переведем слова в нижний регистр:
import string remove_punctuation = str.maketrans('', '', string.punctuation) tokens_ = [x for x in [t.translate(remove_punctuation).lower() for t in tokens] if len(x) > 0]Теперь мы можем получить первый статистический параметр: лексическое разнообразие текста. Это соотношение числа уникальных слов к их общему количеству.
text = nltk.Text(tokens_) lexical_diversity = (len(set(text)) / len(text)) * 100Для данного текста этот параметр равен 96.6%.
Несложно получить среднюю длину слова:
words = set(tokens_) word_chars = [len(word) for word in words] mean_word_len = sum(word_chars) / float(len(word_chars))Множество set(tokens_) дает нам неповторяющийся список слов, далее мы просто вычисляем среднее, разделив сумму на количество. Для этого текста средняя длина слова равна 4.86.
Средняя длина предложения вычисляется с помощью метода sent_tokenize в NLTK, который, как очевидно из названия, разбивает текст на предложения.
import numpy as np sentences = nltk.sent_tokenize(s) sentence_word_length = [len(sent.split()) for sent in sentences] mean_sentence_len = np.mean(sentence_word_length)Для нашего текста длина предложения составляет 15 слов.
И последний параметр - частотность появления различных симолов. У каждого автора может быть свой стиль использования запятых, вопросов и кавычек, разных несклоняемых частей речи ("что", "в"). Для примера посчитаем частоту использования запятых на 1000 символов текста:
fdist = nltk.probability.FreqDist(nltk.Text(tokens)) commas_per_thousand = (fdist[","] * 1000) / fdist.N()Для данного текста параметр составляет 57.14 запятых на 1000 символов.
Последнее, что нам нужно сделать - загружать текст из файла.
import codecs try: doc = codecs.open(file_name, 'r', 'cp1251').read() except: doc = codecs.open(file_name, 'r', 'utf-8').read()Как можно видеть, здесь есть два варианта. Часть файлов, скачанных из онлайн-библиотек, хранятся в кодировке 1251. Другая часть файлов сохранена методом copy-paste в Блокноте, и имеет более современную кодировку UTF-8. Вышеприведенный метод сначала пытается открыть файл как 1251, в случае неудачи мы считаем что это UTF-8, на практике такого подхода оказалось вполне достаточно.
Визуализация
Пока все выглядит довольно скучно. Гораздо интереснее становится тогда, когда эти данные можно увидеть графически. Я взял наугад по одной книге от 4х известных авторов, тексты были взяты со всем известной Библиотеки Максима Мошкова Lib.ru. Каждая книга разбивается на блоки одинаковой длины, для каждого блока параметры вычисляются вышеописанным способом.
Лексическое разнообразие и средняя длина слова не дают какой-либо заметной разницы:
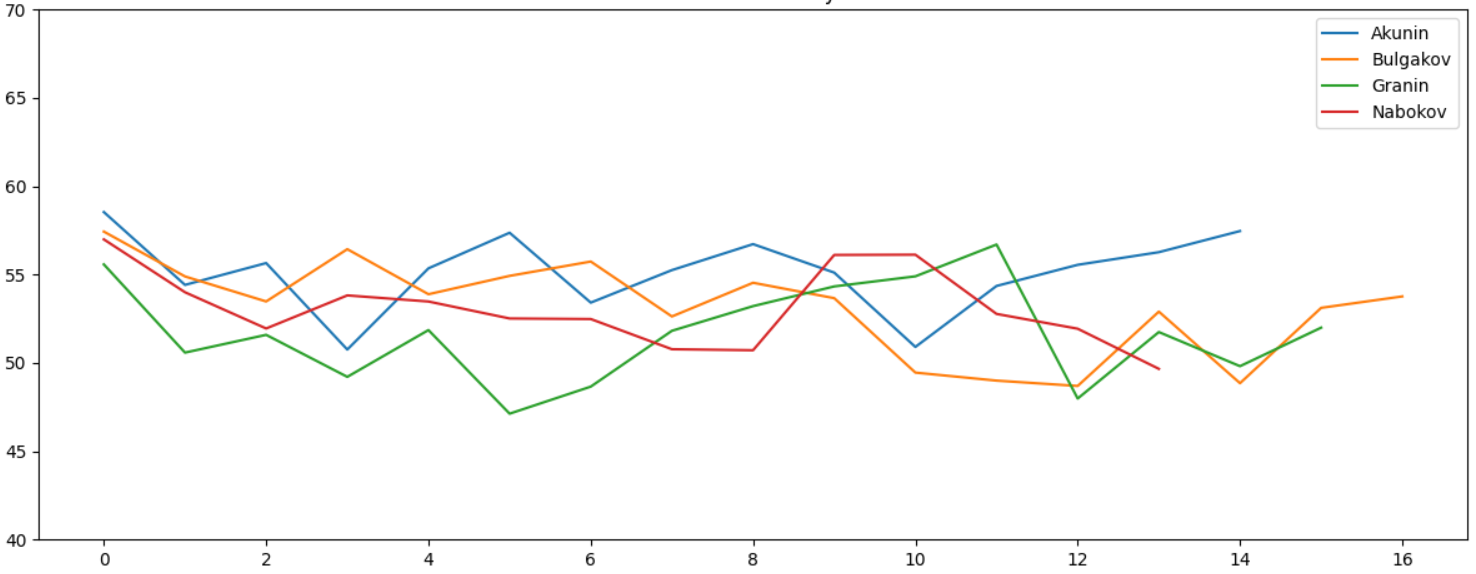
Очевидно, все авторы люди образованные, тексты написаны хорошим и литературным русским языком, какой-либо значимой разницы в объеме используемых слов не видно. Параметр "длина слова" тоже не дает видимых отличий. А вот средняя длина предложения отличается весьма заметно:
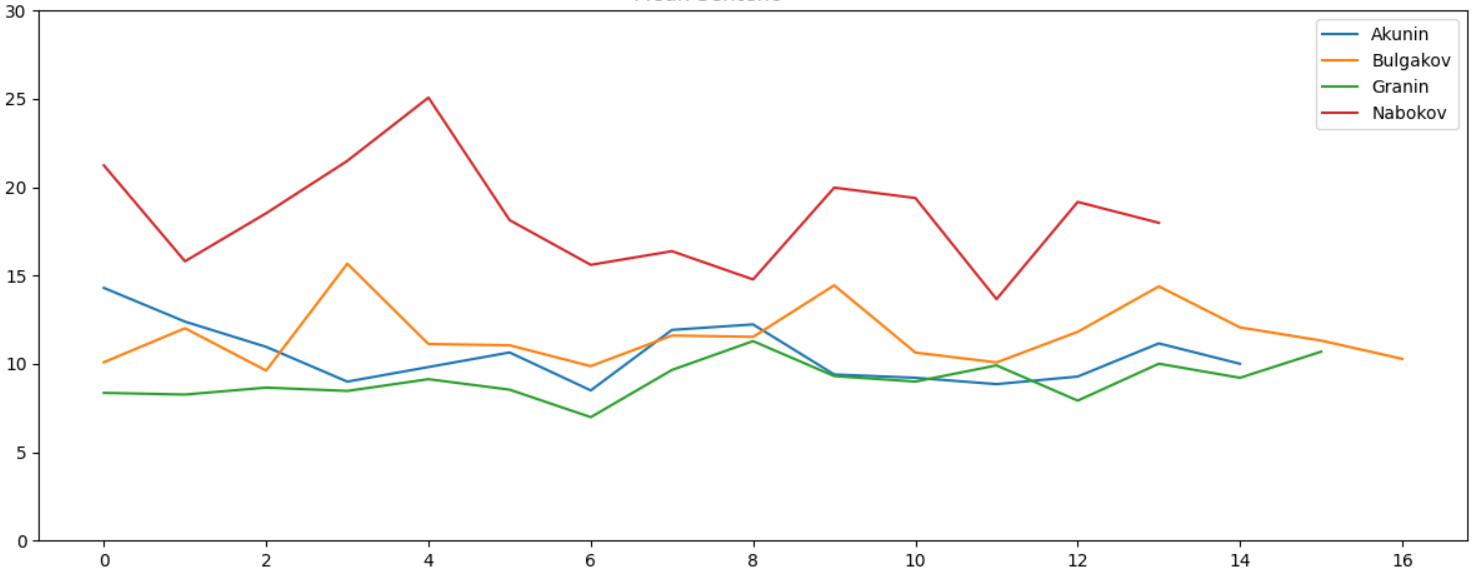
У Набокова стиль, очевидно, отличается, и разница статистически хорошо видна. Это неудивительно - если открыть саму книгу, в тексте встречаются предложения типа таких:
Он боялся, Лужин старший, что, когда сын узнает, зачем так нужны были совершенно безликие Трувор и Синеус, и таблица слов, требующих ять, и главнейшие русские реки, с ним случится то же, что два года назад, когда, медленно и тяжко, при звуке скрипевших ступеней, стрелявших половиц, передвигаемых сундуков, наполнив собою весь дом, появилась француженка.
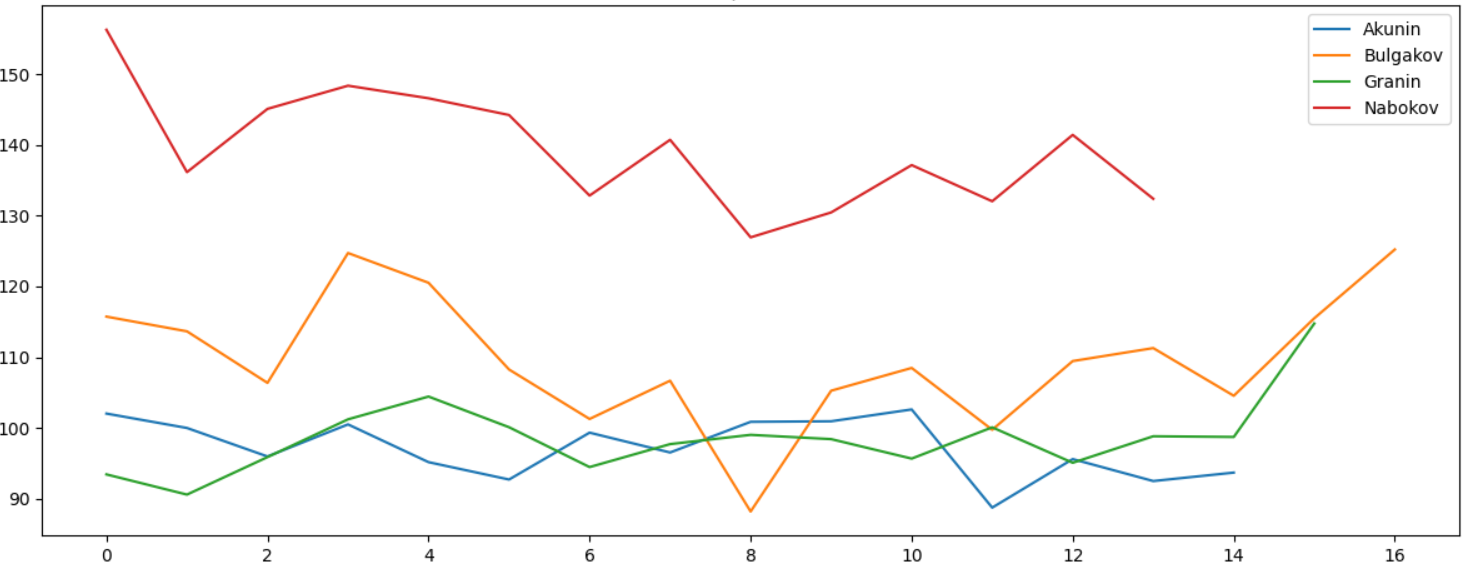
Количество запятых на 1000 слов также отличается, и это очевидно - в длинном предложении их, очевидно, и должно быть больше:
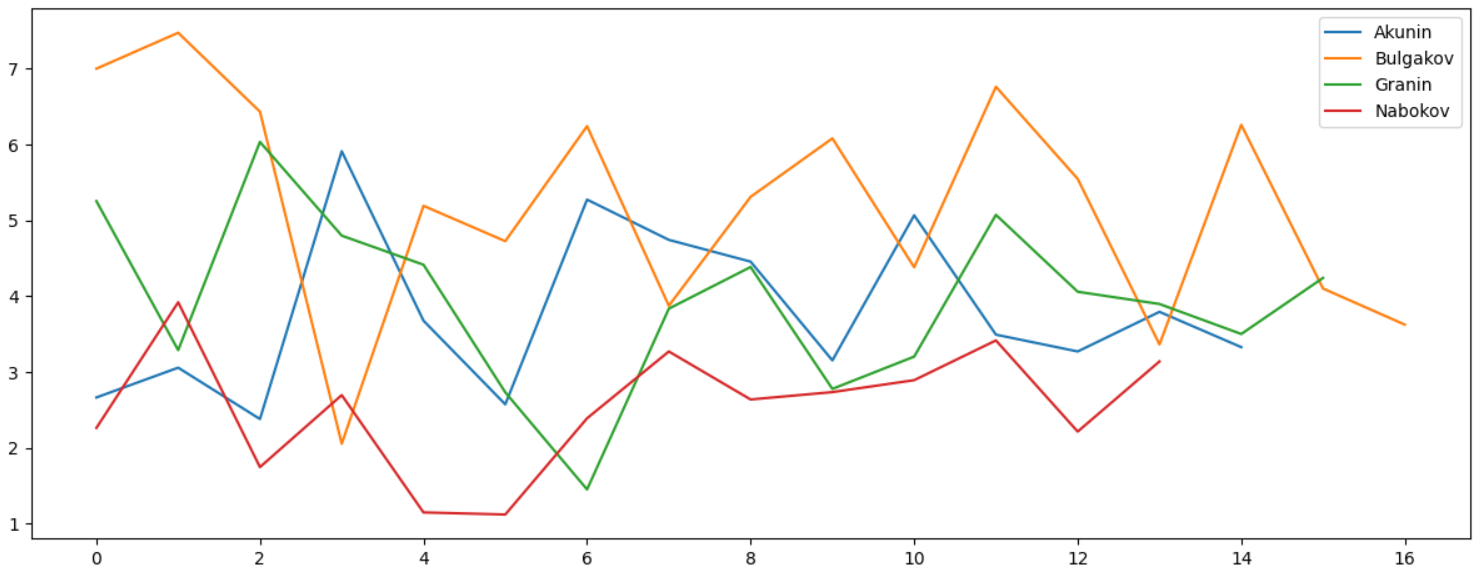
Разумеется, анализ можно делать по любому символу, например, можно сравнить, как часто у разных авторов встречается знак двоеточия ":":
Несложно вывести частоты появления различных символов в виде кривой, взяв по одной книге от каждого автора:
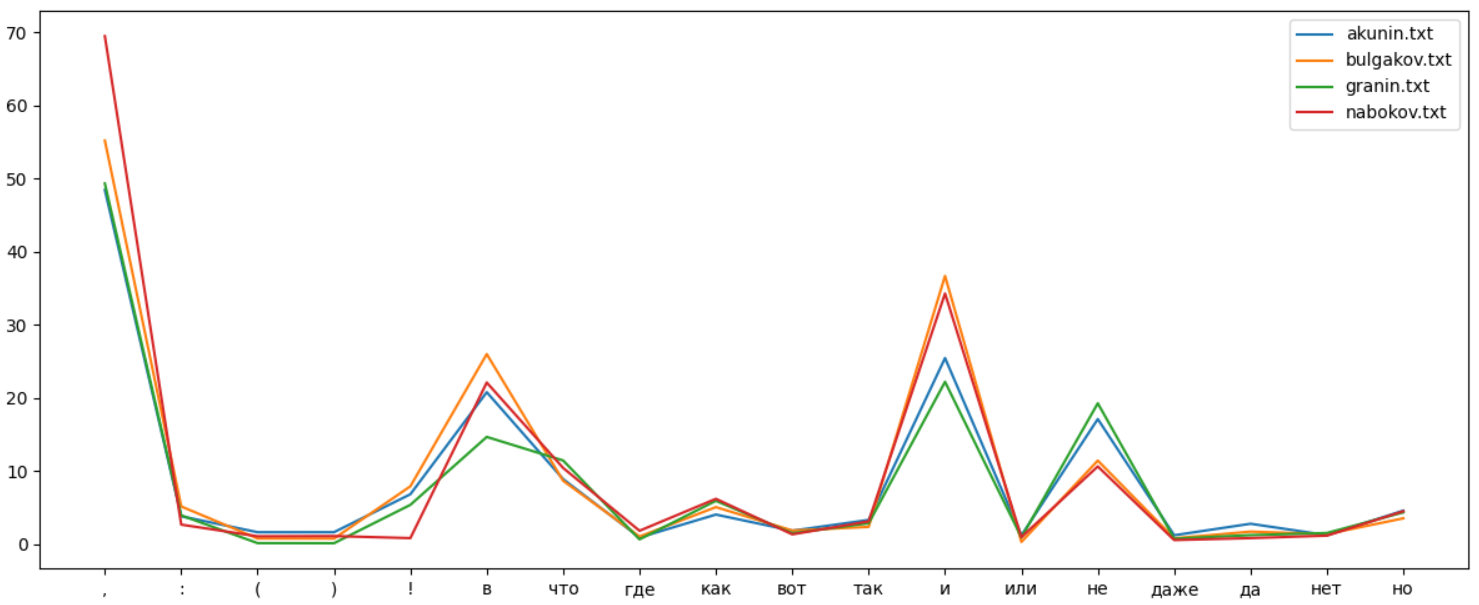
Частоты употребления разных символов в русском языке похожи, но различия в стиле разных авторов все же есть. Для сравнения, вот так выглядит кривая для разных книг одного автора:
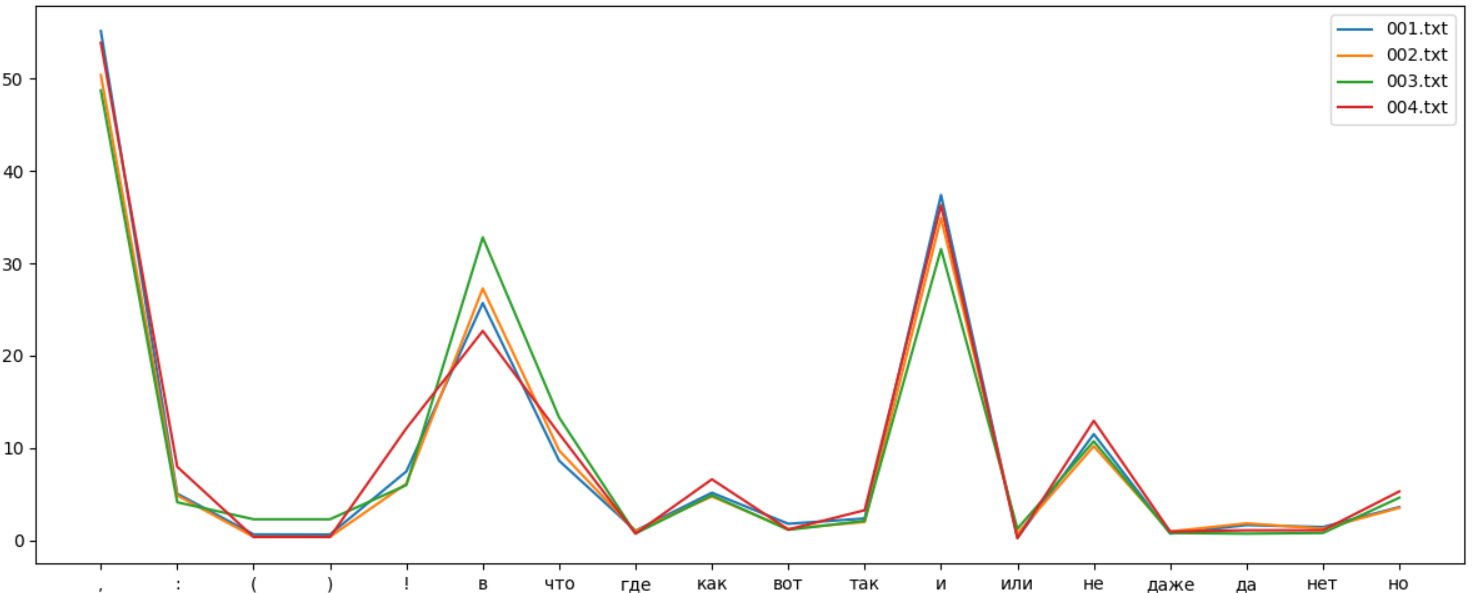
Идея, надеюсь, понятна. "Отпечаток" использования различных символов отличается для разных авторов, и как было показано, технологию можно использовать даже для выявления клонов на популярном англоязычном сайте reddit.com. Впрочем, насколько достоверно это работает для русского языка, автору неизвестно.
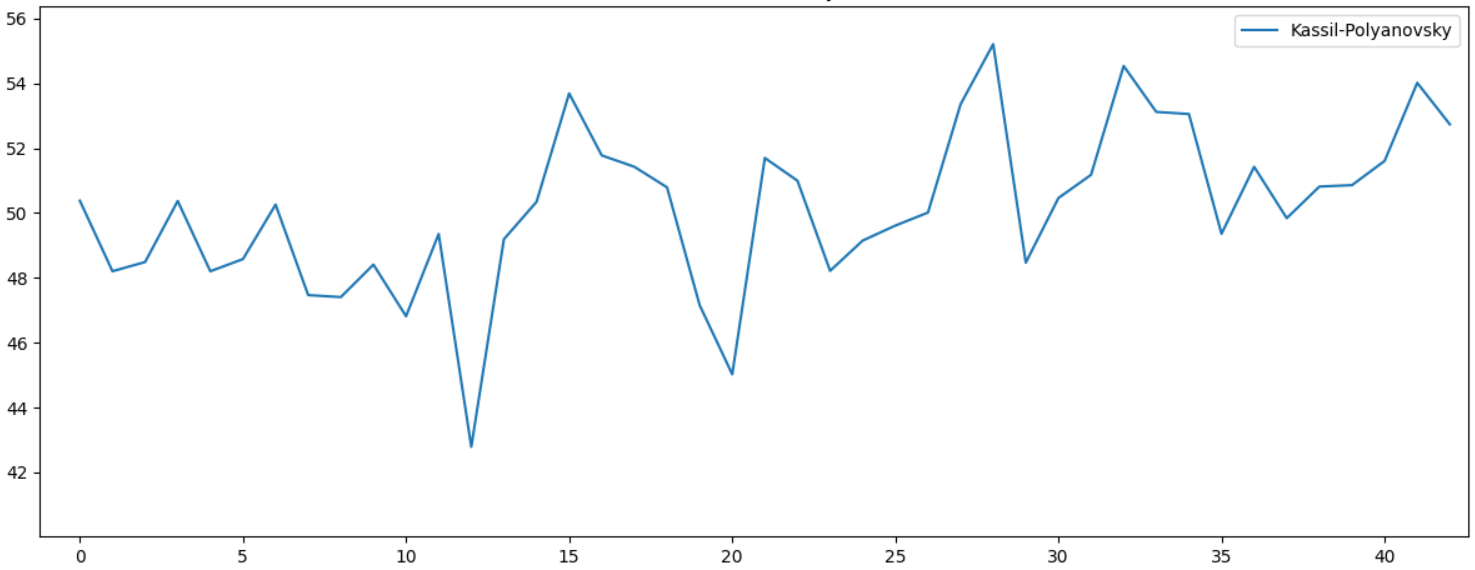
Мы же рассмотрим пример попроще. Популярная в СССР детская книга "Улица младшего сына" имеет двух авторов, Лев Кассиль и Макс Поляновский. На графике хорошо видно статистическое различие по Lexical Diversity. Можно предположить что начало книги писал один автор, а закончил другой:
И последний, наиболее любопытный пример. Ниже приведен график лексического разнообразия для 10 книг одной популярной дамской писательницы, чьи книги одно время продавались буквально на каждой остановке. Ещё тогда я удивлялся, можно ли писать столько книг в таком количестве. Ответ лично для меня стал очевиден, на графике определенно видна статистическая аномалия - стиль как минимум, одной книги заметно отличается от остальных:
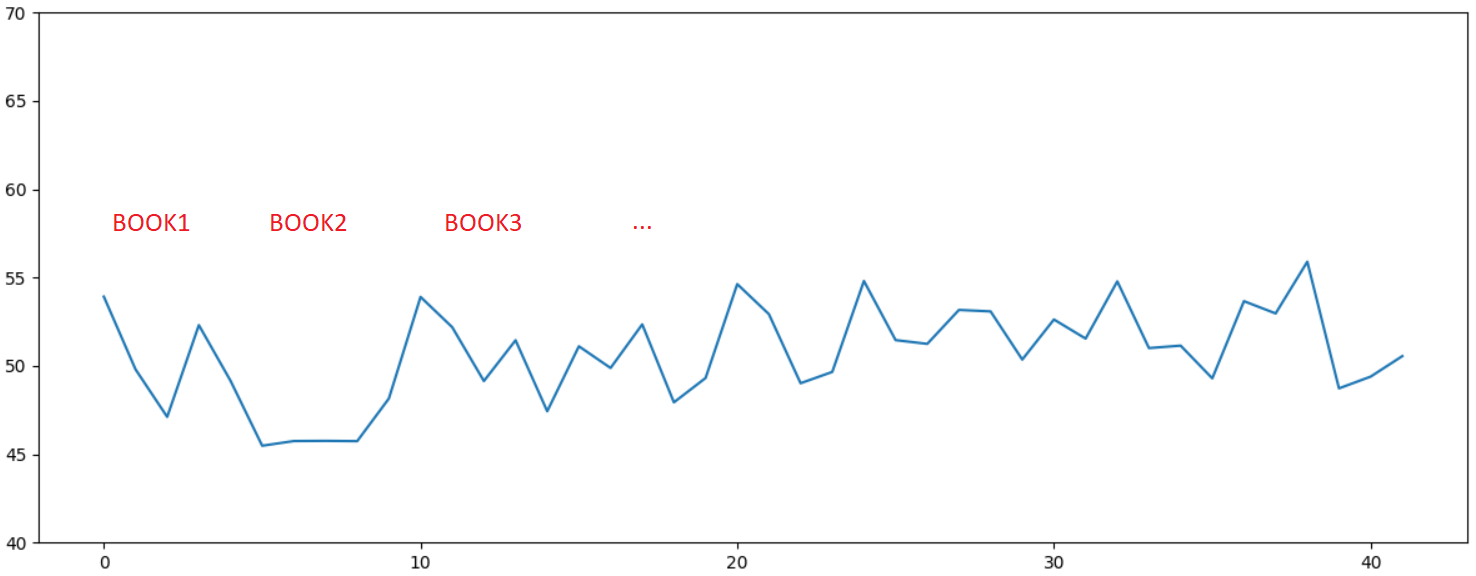
Но разумеется, может это и просто совпадение, теория вероятности такое, в принципе, допускает...
Заключение
Вышеприведенный анализ показался довольно интересным. Используя несложные, практически школьные, формулы, можно получить довольно любопытные результаты. Разумеется, анализ можно и усложнить, например, можно попробовать определить, менялся ли стиль автора с годами, вариантов тут много.
Для желающих поэкспериментировать самостоятельно, исходный код для Python 3.7 приведен под спойлером.
text_process.py
import nltk, codecs import numpy as np import pandas as pd import matplotlib.pyplot as plt from typing import Optional, List import string import glob import sys, os def get_articles_from_blob(folder: str): data = [] for path in glob.glob(folder + os.sep + "*"): print(path) data += get_articles_from_folder(path) return data def get_articles_from_folder(folder: str): data = [] for path in glob.glob(folder + os.sep + "*.txt"): data += get_data_from_file(path) return [(folder.split(os.sep)[-1], data)] def get_data_from_file(file_name: str): print("Get data for %s" % file_name) try: doc = codecs.open(file_name, 'r', 'cp1251').read() except: doc = codecs.open(file_name, 'r', 'utf-8').read() chunk_size = 25000 data = [] for part in [doc[i:i+chunk_size] for i in range(0, len(doc) - (len(doc) % chunk_size), chunk_size)]: data.append(get_data_from_str(part[part.find(' '):part.rfind(' ')])) return data def get_data_from_str(doc: str): tokens = nltk.word_tokenize(doc) remove_punctuation = str.maketrans('', '', string.punctuation) tokens_ = [x for x in [t.translate(remove_punctuation).lower() for t in tokens] if len(x) > 0] text = nltk.Text(tokens_) lexical_diversity = (len(set(text)) / len(text)) * 100 words = set(tokens_) word_chars = [len(word) for word in words] mean_word_len = sum(word_chars) / float(len(word_chars)) sentences = nltk.sent_tokenize(doc) sentence_word_length = [len(sent.split()) for sent in sentences] mean_sentence_len = np.mean(sentence_word_length) fdist = nltk.probability.FreqDist(nltk.Text(tokens)) commas_per_thousand = (fdist[","] * 1000) / fdist.N() return (lexical_diversity, mean_word_len, mean_sentence_len, commas_per_thousand) def plot_data(data): plt.rcParams["figure.figsize"] = (12, 5) fig, ax = plt.subplots() plt.title('Lexical diversity') for author, author_data in data: plt.plot(list(map(lambda val: val[0], author_data)), label=author) plt.ylim([40, 70]) # plt.title('Mean Word Length') # for author, author_data in data: # plt.plot(list(map(lambda val: val[1], author_data)), label=author) # plt.ylim([4, 8]) # plt.title('Mean Sentence Length') # for author, author_data in data: # plt.plot(list(map(lambda val: val[2], author_data)), label=author) # plt.ylim([0, 30]) # plt.title("Commas per thousand") # for author, author_data in data: # plt.plot(list(map(lambda val: val[3], author_data)), label=author) plt.legend(loc='upper right') plt.tight_layout() plt.show() def get_freqs_from_folder(folder: str): freqs_data = [] for path in glob.glob(folder + os.sep + "*.txt"): print("Get data for %s" % path) try: doc = codecs.open(path, 'r', 'cp1251').read() except: doc = codecs.open(path, 'r', 'utf-8').read() symbols, freqs = get_freqs_from_str(doc) freqs_data.append((path.split(os.sep)[-1], symbols, freqs)) return freqs_data def get_freqs_from_str(doc: str): tokens = nltk.word_tokenize(doc) tokens = [x for x in [t.lower() for t in tokens]] fdist = nltk.probability.FreqDist(nltk.Text(tokens)) symbols = [",", ":", "(", ")", "!", "в", "что", "где", "как", "вот", "так", "и", "или", "не", "даже", "да", "нет", "но"] freqs = [] for s in symbols: freq = (fdist[s] * 1000) / fdist.N() if s == ",": freq /= 2 freqs.append(freq) return (symbols, freqs) def plot_freqs(data): plt.rcParams["figure.figsize"] = (12, 5) for author, symbols, freqs in data: plt.plot(symbols, freqs, label=author) plt.legend(loc='upper right') plt.tight_layout() plt.show() if __name__ == "__main__": # Download punkt tokenizer try: nltk.data.find('tokenizers/punkt') except LookupError: nltk.download('punkt') # Process text files # data = get_articles_from_blob("Folder") # Folder/AuthorXX/Text.txt data = get_articles_from_folder("folder_here") # Folder with files plot_data(data) # Process frequency curve data = get_freqs_from_folder("folder_here") plot_freqs(data)