Распознавание звуков с помощью глубокого обучения
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-01-22 11:09

Вы когда-нибудь просыпались с непонятным ощущением: слышишь какой-то звук, но точно знаешь, что в этом звуке что-то не то?
Распознавание звуков — это один базовых инстинктов, позволявших людям избегать опасности. Это умение помогало нам узнавать о приближении хищника. Да и сейчас звуки продолжают играть большую роль в нашей жизни: мы различаем человеческие голоса, наслаждаемся музыкой и пением птиц…
Поэтому совершенно естественно, что важнейшей задачей стала разработка аудиоклассификаторов. Они необходимы для того, чтобы классифицировать источник звука, и уже широко применяются в различных целях. Так, в музыке существует классификатор музыкальных жанров. В последнее время подобные системы стали использоваться и для классификации звуков, издаваемых птицами. Раньше этим занимались орнитологи. Цель этих систем — распределить птиц по категориям. Задача непростая с учётом того, как сложно уловить звуки, издаваемые птицами в полях или шумных окрестностях.
В последнее время глубокое обучение превратилось в одну из самых популярных технологий для решения множества задач. Произошло это благодаря точности глубокого обучения, а также совершенствованию вычислительных устройств, таких как CPU (центральный процессор) и GPU (графический процессор). На приведённой ниже диаграмме показано, насколько важен рынок глубокого обучения, а также его ожидаемый размер с точки зрения программного обеспечения, аппаратного оборудования и услуг:
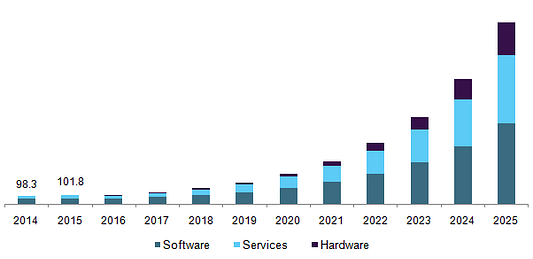
В этой статье наша задача — считывание аудиофайла со звуками, издаваемыми птицами (количество: от нуля до нескольких звуков). Кроме того, мы задействуем глубокое обучение для выявления, какой птице какой звук принадлежит. Будем использовать для этого Cornell Birdcall Identification Challenge, в котором мы получили серебряную медаль (с высоким результатом 2%).
Как обращаться с данными
Обработке аудиоданных с получением спектрограммы посвящено бесчисленное множество статей с объяснениями, как загружать звуковые данные, в том числе переводить их в формат спектрограммы, и почему это важно. Вот спектрограмма звуков, издаваемых птицами, на примере мухоловки ольховой и фотография этой птицы (на случай если вам интересно):
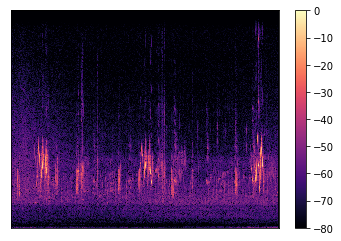
Скорость обработки данных — одно из главных условий для применения модели глубокого обучения. Но в то же время с увеличением вычислительной мощности и задействованием центрального процессора стоимость вычислений, связанных с обработкой аудиосигналов, по-прежнему высока. А вот если для обработки данных выбрать другой вычислительный ресурс, например графический процессор, то можно увеличить скорость от десяти до ста раз! Мы продемонстрируем, как быстро обрабатывать спектрограммы, используя библиотеку torchlibrosa, которая позволяет делать это на графическом процессоре.
Создаём процессор для спектрограммы
torchlibrosa — это библиотека Python, в которой есть несколько функций обработки аудиосигналов, реализованных в PyTorch с возможностью использовать ресурсы графического процессора. PyTorch позволяет запускать алгоритм этой спектрограммы на графическом процессоре. Вот пример извлечения функций спектрограммы с помощью torchlibrosa:
from torchlibrosa.stft import Spectrogram spectrogram_extractor = Spectrogram( win_length=1024, hop_length=320 ).cuda()Загружаем аудиоданные
Аудиоданные загрузим через одну из популярных на Python библиотек обработки аудиосигналов librosa:
import librosa # получаем необработанные аудиоданные example, _ = librosa.load('example.wav', sr=32000, mono=True)Обрабатываем спектрограмму
raw_audio = torch.Tensor(example).unsqueeze(0).cuda() spectrogram = spectrogram_extractor(raw_audio)Скорость обработки при тестировании
Будем обрабатывать аудиоданные на графическом процессоре, используя библиотеку torchlibrosa. Вы спросите: «А насколько графический процессор справится быстрее, чем центральный процессор?». Вот скорость обработки при тестировании на устройстве:
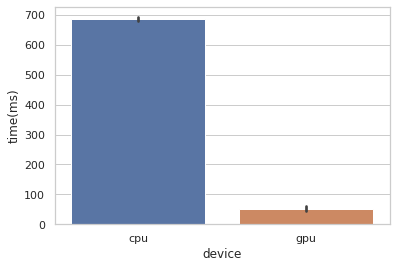
Мы просто взяли аудио из данных, полученных в ходе проведения Cornell Birdcall Identification Kaggle Challenge (всё из открытого доступа), и сравнили, сколько времени она занимает на центральном процессоре и графическом процессоре. Тестировали на Colab с целью воспроизвести производительность. Оказалось, что обработка log-mel спектрограммы из 5 минутного аудио происходит примерно в 15 раз быстрее на графическом процессоре, чем на центральном процессоре.
Как классифицировать звук
Таким образом, глубокое обучение показало блестящие результаты в аудиосфере. Оно правильно улавливает многочисленные паттерны целевых классов в данных временных рядов. Более важным представляется окружение, в котором птицы издают звуки, и соответствующие данные. Окружающая обстановка (полевые или горные условия) является источником разнообразных шумов, смешивающихся со звуками, издаваемыми птицами. На продолжительной записи могут быть запечатлены звуки нескольких птиц. Поэтому нужно создать аудиоклассификатор со множеством меток и надёжным распознаванием звуков.
Представим архитектуру глубокого обучения, использованную на конкурсе Cornell Birdcall Identification Kaggle Challenge.
Архитектура
Это принципиально новая архитектура аудиоклассификатора, которая эффективно улавливает характеристики временных рядов за счёт использования CNN (свёрточной нейронной сети), RNN (рекуррентной нейронной сети) и механизмов внимания. Вот небольшая блочная диаграмма архитектуры, которая была представлена на этом конкурсе:
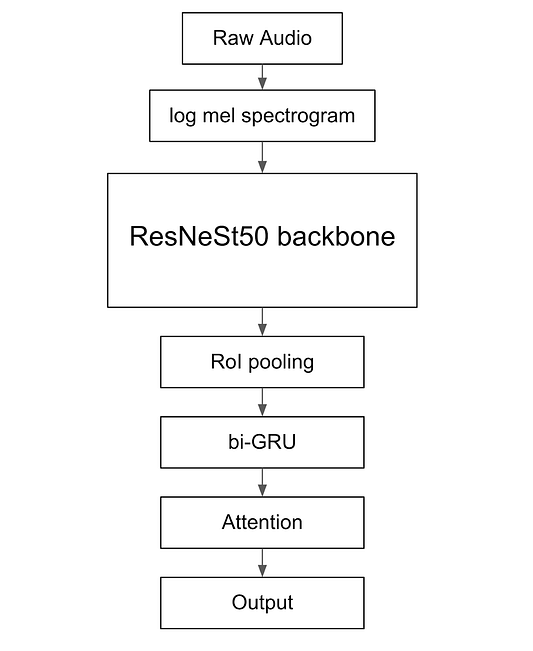
В качестве входных данных архитектуры используем ещё не обработанное аудио с log-mel спектрограммой. Оно проходит через магистральную сеть ResNeSt50, которая является одной из архитектур классификации изображений. После этого доставляем функции, содержащие пространственную и временную информацию, к слоям RoI pooling (области интереса) и bi-GRU (двунаправленным рекуррентным блокам). В этих слоях улавливается информация, касающаяся времени, и уменьшается размер функции. Ведь мы посчитали, что извлечение временных функций имеет решающее значение для классификации количества звуков, издаваемых птицами, в продолжительном аудио. И в заключение передаём данные в механизм внимания, чтобы оценить результаты по каждому временному шагу и выявить, на каком временном шаге проявляют себя птицы.
Обучаем модель
Важно не только создать архитектуру глубокого обучения для представления данных, но и научиться обучать модель (так называемый «рецепт обучения»). Чтобы классифицировать аудио с шумным фоном, в которых есть различные звуки, издаваемые птицами, смешиваем все эти звуки в аудио с шумами, такими как «белый шум». А что касается многочисленных вариаций звуков, издаваемых птицами, увеличиваем высоту звука и маскируем некоторые аудиокадры с помощью SpecAugment.
Вот краткий пример (смешанная версия мухоловки ольховой и американской шилоклювки) тех аугментаций, которые мы применяли.
Заключение
Вы когда-нибудь просыпались с непонятным ощущением: слышишь какой-то звук, но точно знаешь, что в этом звуке что-то не то? С помощью алгоритмов машины смогут избавить вас от непонятных звуков, чтобы вам спалось лучше.
Телеграм: t.me/ainewsline
Источник: codengineering.ru