Простой гид по байесовскому А/B-тестированию на Python
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-01-04 13:40

A/B-тестирование — это неотъемлемая часть работы над продуктом. С его помощью можно проверить гипотезу о том, поменяется ли выбранная продуктовая метрика, если изменить что-то в продукте, — например, увеличится ли количество пользователей, если изменить дизайн страницы регистрации. Для этого сравниваются результаты в тестовой и контрольной группах пользователей: первой выборке показывают новое решение, а у контрольной группы продукт остаётся неизменным.
При этом важно проверить, будет ли изменение статистически значимым: подтвердить, что наблюдаемая разница у тестовой и контрольных групп действительно связана с нововведениями в продукте, а не является случайностью. Для этого можно применять традиционный (частотный) или байесовский подход к A/B-тестированию. У обоих методов есть свои сторонники и противники, но байесовский подход позволяет проще визуализировать данные и интерпретировать результат эксперимента. Академия Яндекса перевела статью из блога Towards Data Science о том, как провести байесовское A/B-тестирование и разобраться в его работе.
Сразу к коду
Здесь приведено решение для байесовского A/B-тестирования — код которого можно сразу применить для своего проекта. Во второй части статьи описываются детали, которые позволят лучше понять его работу и принципы, которые за ним стоят.
В приведенном коде не используются приближения: методы Монте-Карло по схеме марковских цепей (MCMC) или любые другие стохастические процессы. Поэтому для того, чтобы его применить, вам не понадобится вероятностный фреймворк программирования.
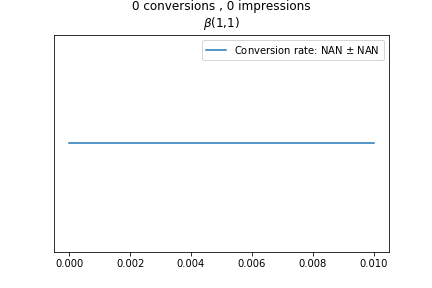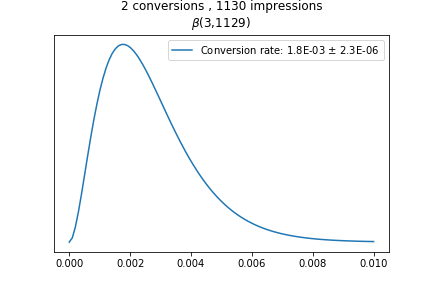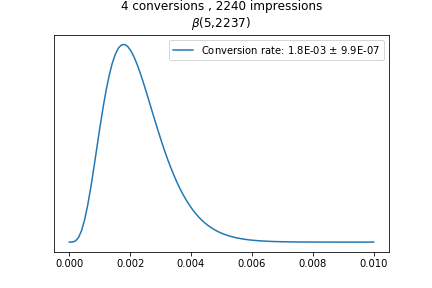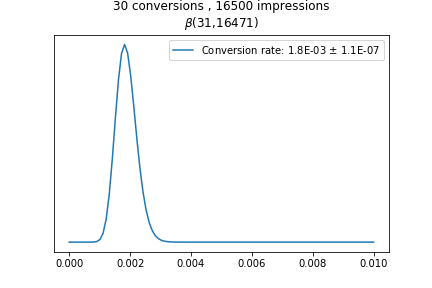
Сперва представим полученные в результате A/B-тестирования данные: например, по конверсии (CR) пользователей веб-страницы, как представлено в таблице:
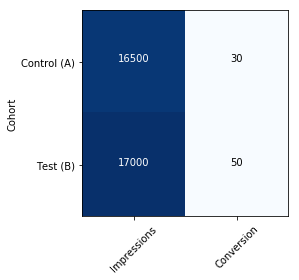
Код для работы приведён ниже. Чтобы воспользоваться им, нужно скачать библиотеку SciPy и компилятор Numba с платформы Anaconda, и подставить числа, полученные в ходе тестирования.
from scipy.stats import beta import numpy as np from calc_prob import calc_prob_between #This is the known data: impressions and conversions for the Control and Test set imps_ctrl,convs_ctrl=16500, 30 imps_test, convs_test=17000, 50 #here we create the Beta functions for the two sets a_C, b_C = convs_ctrl+1, imps_ctrl-convs_ctrl+1 beta_C = beta(a_C, b_C) a_T, b_T = convs_test+1, imps_test-convs_test+1 beta_T = beta(a_T, b_T) #calculating the lift lift=(beta_T.mean()-beta_C.mean())/beta_C.mean() #calculating the probability for Test to be better than Control prob=calc_prob_between(beta_T, beta_C) print (f"Test option lift Conversion Rates by {lift*100:2.2f}% with {prob*100:2.1f}% probability.") #output: Test option lift Conversion Rates by 59.68% with 98.2% probability. Содержание импортируемого модуля calc_prob.py:
from math import lgamma from numba import jit #defining the functions used @jit def h(a, b, c, d): num = lgamma(a + c) + lgamma(b + d) + lgamma(a + b) + lgamma(c + d) den = lgamma(a) + lgamma(b) + lgamma(c) + lgamma(d) + lgamma(a + b + c + d) return np.exp(num - den) @jit def g0(a, b, c): return np.exp(lgamma(a + b) + lgamma(a + c) - (lgamma(a + b + c) + lgamma(a))) @jit def hiter(a, b, c, d): while d > 1: d -= 1 yield h(a, b, c, d) / d def g(a, b, c, d): return g0(a, b, c) + sum(hiter(a, b, c, d)) def calc_prob_between(beta1, beta2): return g(beta1.args[0], beta1.args[1], beta2.args[0], beta2.args[1])
Как видно из кода, в случае с данными из первой таблицы выбор тестовой группы работает лучше, чем выбор контрольной: можно увидеть почти 60% увеличение конверсии с 98% вероятностью.
Результат легко интерпретировать, не правда ли? А теперь перейдём к деталям.
Объяснение
В приведенном коде инициализируются две бета-функции (по одной для каждого случая), в которые подставляются числа:

Они моделируют данные A/B теста, а поведение функций при разных значениях показано на гифке:
Каждая последующая функция строится с учётом новых данных: и пока данных нет, она выглядит как прямая. А чем больше информации, тем более точный результат мы получаем, и тем более острый пик у распределения.
На этом этапе у вас, скорее всего, возник вопрос: почему существует такая функция, которая как будто создана для A/B-тестов?
Ответ кроется в теореме Байеса. Обычно с её помощью сложно получить точные значения, и поэтому приходится применять различные методы приближения: например, методы Монте-Карло по схеме марковских цепей (MCMC).
Но A/B тесты — это тот удачный случай, в котором есть точное решение, основанное на сопряжённом априорном распределении. Когда это понятие применимо, то апостериорная (после эксперимента) функция всегда принадлежит к тому же семейству, что и априорная (до учёта результатов эксперимента), и можно итеративно прийти к финальной функции.
А/B тесты — это случайные эксперименты с ровно двумя возможными исходами, и по определению они являются испытаниями Бернулли, а cопряжённым априорным распределением для них служит бета-распределение. Поэтому бета-распределение можно использовать таким простым образом, как в приведённом коде. Если у вас остались сомнения, то с деталями математических доказательств можно ознакомиться здесь (примечание Академии — мы заменили исходную ссылку на подробный материал от руководителя Центра глубинного обучения и байесовских методов Дмитрия Ветрова).
Давайте вернёмся к нашему примеру и рассмотрим два распределения:
import matplotlib.pyplot as plt def calc_beta_mode(a, b): '''this function calculate the mode (peak) of the Beta distribution''' return (a-1)/(a+b-2) def plot(betas, names, linf=0, lsup=0.01): '''this function plots the Beta distribution''' x=np.linspace(linf,lsup, 100) for f, name in zip(betas,names) : y=f.pdf(x) #this for calculate the value for the PDF at the specified x-points y_mode=calc_beta_mode(f.args[0], f.args[1]) y_var=f.var() # the variance of the Beta distribution plt.plot(x,y, label=f"{name} sample, conversion rate: {y_mode:0.1E} $pm$ {y_var:0.1E}") plt.yticks([]) plt.legend() plt.show() plot([beta_C, beta_T], names=["Control", "Test"]) 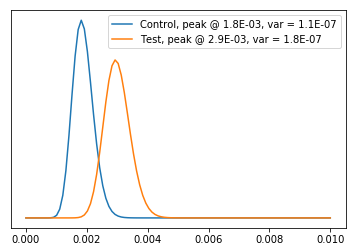
Можно заметить, что пики распределений соответствуют значениям, подсчитанным традиционным способом:
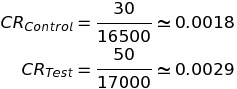
Разница между традиционным (частотным) и байесовским подходом заключается в том, что во втором случае вместо числа мы получаем для конверсии плотность вероятности. И благодаря этому становится просто подсчитать вариацию конверсии, которую тоже можно увидеть на верхнем графике.
Кроме того, можно вычислить, насколько выше конверсия для тестовой группы, чем для контрольной:
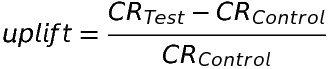
На этом этапе нужно оценить достоверность результата. Как? Подсчитав вероятность того, что одна опция окажется лучше другой.
Заметим, что при традиционном (частотном) подходе так сделать не получится. В этом случае нужно подсчитать p-значение, затем проверить, принадлежит ли оно определённому промежутку (обычно для подтверждения значимости гипотезы p должно быть строго меньше 0,05) и объявить клиенту или менеджеру, что «с 95% доверительным интервалом, мы можем отвергнуть нулевую гипотезу». А потом придётся объяснять, что это не то же самое, что «эта гипотеза лучше предыдущей с вероятностью в 95%», и что они бы на самом деле хотели услышать.
При байесовском же подходе мы можем свободно говорить, что одна гипотеза лучше другой. В самом деле, у нас есть функции плотности вероятности, которые описывают нашу конверсию, а вероятность того, что одна гипотеза лучше другой, задаётся площадью под графиком.
Приведем пример: чтобы найти вероятность того, что конверсия для тестовой группы выше 0,003, нужно подсчитать площать фигуры под графиком на отрезке от 0,003 до 1 (определённый интеграл на этом промежутке).
На Python подсчитать этот интеграл (без использования приближений) можно с помощью библиотеки Mpmath:
from mpmath import betainc p=betainc(a_T, b_T, 0.003,1, regularized=True) #result: 0.4811256685381254
В этом примере мы рассматриваем только одно распределение (для тестовой группы), но для того, чтобы точно оценить прирост в метриках, нужно рассмотреть оба распределения — и для тестовой, и для контрольной группы. Чтобы это визуализировать, нужно добавить ещё одно измерение. Как следствие, вероятность, которую нам нужно измерить, будет описываться уже не площадью, а объёмом. В этом случае — объёмом под совместным распределением для контрольной и тестовой групп.
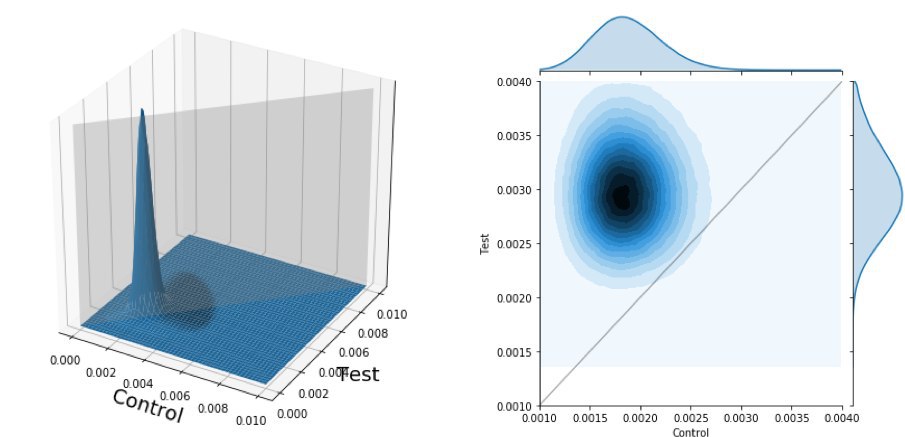
Совместное распределение для двух групп. Слева — 3D-визуализация. Справа — вид сверху. Серая заливка (или линия в случае плоского изображения) отделяет зону, на которой результаты для тестовой группы лучше, чем для контрольной.
Приведённую визуализацию можно представить как изображение горы и её вид со спутника сверху. А серая линия на правом графике может служить как граница между землей, принадлежащей тестовой группе (верхний треугольник), и землей контрольной группы. При этой интерпретации вопрос стоит так: насколько большая часть горы принадлежит одной из групп?
Код для создания похожей визуализации можно взять отсюда:
import seaborn as sns import pandas as pd import numpy as np imps_ctrl,convs_ctrl=16500, 30 imps_test, convs_test=17000, 50 #here we create the Beta functions for the two sets a_C, b_C = convs_ctrl+1, imps_ctrl-convs_ctrl+1 a_T, b_T = convs_test+1, imps_test-convs_test+1 val_C=np.random.beta(a_C, b_C, 1000000) val_T=np.random.beta(a_T, b_T, 1000000) vals=np.vstack([val_C, val_T]).T limit=0.004 df=pd.DataFrame(vals, columns=['Control', 'Test']) df=df[df['Control']<limit] df=df[df['Test']<limit] g=sns.jointplot(x=df.Control, y=df.Test, kind='kde', n_levels=15) g.ax_joint.plot([0.0015, limit], [0.0015, limit])
Чтобы подсчитать площадь фигуры на картинке выше, часто используют методы аппроксимации (например, методы Монте-Карло). Простое решение для нашего случая уже описывалось во второй главе книги Джона Кука в 2005 года. А код в модуле calc_prob.py воспроизводит это решение.
В нашем случае в результате подсчётов мы получим площадь фигуры, равную 0,98, что означает, что результаты тестовой группы с 98% вероятностью лучше, чем результаты контрольной.
Подчеркнем, что если бы в результате построения графиков, «гора» делилась бы ровно пополам, то результаты двух групп были бы равнозначными. А если бы большая часть «горы» принадлежала контрольной группе, то это означало бы, что по результатам А/B-тестирования лучше остановиться на изначальном решении и ничего не менять.
Как видите, несмотря на то, что код для проведения байесовского A/B-тестирования довольно простой, чтобы понять, как и почему он работает, нужно углубляться в детали и ориентироваться в математической статистике.
Телеграм: t.me/ainewsline
Источник: academy.yandex.ru