Pile: открытый датасет для обучения языковых моделей на 825 гигабайт
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-01-29 05:11

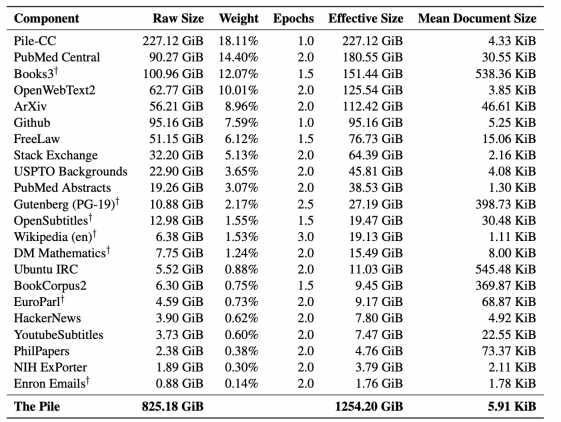
Pile — это датасет с разнообразными текстами на 825 гигабайт для обучения языковых моделей. Датасет состоит из 22 датасетов меньшего размера, которые объединили в один. Кроме датасета, создатели опубликовали бенчмарк для тестирования языковых моделей на качество моделирования.
Преимущества Pile
Для крупных state-of-the-art моделей разнообразие в источниках обучающих данных улучшает общую способность модели к генерализации. По результатам экспериментов, модели, которые предобучали на Pile, показывают более высокие результаты на стандартных бенчмарках для языкового моделирования. Кроме того, они обходят подходы, обученные на других данных, на бенчмарке Pile BPB.
Чтобы получить высокий скор на Pile BPB, модель должна понимать множество разных доменов, включая книги, репозитории на GitHub, веб-страницы, логи чатов и математические, медицинские и физические исследовательские работы. Pile BPB измеряет знания модели разных доменов и то, насколько модель способна к формулированию связных текстов в рамках этих доменах. Это позволяет устойчиво оценивать генеративные модели для текстовых данных. Подробнее данные и бенчмарк описаны в оригинальной статье.
Телеграм: t.me/ainewsline
Источник: neurohive.io