OpenAI представила нейросеть DALL-E — она создаёт изображения по текстовому описанию
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-01-07 09:53
свёрточные нейронные сети, компьютерная лингвистика, распознавание образов
Мы обучили нейронную сеть под названием DALL * E, которая создает изображения из текстовых подписей для широкого спектра понятий, выражаемых на естественном языке.
DALL·E[1]-это 12-миллиардная версия GPT–3, обученная генерировать изображения из текстовых описаний, используя набор данных пар текст-изображение. Мы обнаружили, что он обладает разнообразным набором возможностей, включая создание антропоморфизированных версий животных и объектов, правдоподобное сочетание несвязанных понятий, визуализацию текста и применение преобразований к существующим изображениям.
иллюстрация младенца дайкона редьки в пачке выгуливающего собаку
Сгенерированные искусственным интеллектом изображения





Просмотр дополнительных или редактирование приглашений
кресло в форме авокадо […]
Сгенерированные искусственным интеллектом изображения





Просмотр дополнительных или редактирование приглашений
Текстовая подсказка
фасад магазина, на котором написано слово "openai" […]
Сгенерированные искусственным интеллектом изображения





Просмотр дополнительных или редактирование приглашений
Текстовая и графическая подсказка
точно такой же кот сверху как и эскиз снизу
Сгенерированные искусственным интеллектом изображения





Просмотр дополнительных или редактирование приглашений
GPT-3 показал, что язык может быть использован для обучения большой нейронной сети для выполнения различных задач генерации текста. Изображение GPT показало, что тот же тип нейронной сети также может быть использован для генерации изображений с высокой точностью. Мы расширим эти выводы, чтобы показать, что манипулирование визуальными концепциями с помощью языка теперь в пределах досягаемости.
Общие сведения
Как и GPT-3, DALL·E-это модель языка-трансформера. Он получает и текст и изображение как единый поток данных, содержащий до 1280 маркеры, и обучается с помощью максимального правдоподобия для создания все жетоны один за другим.[2] Этот тренинг процедура позволяет даль·Е, чтобы не только создать образ с нуля, но также регенерировать любую прямоугольную область изображения, которая распространяется на нижний правый угол, в соответствии с текстом подсказки.
Мы признаем, что работа, связанная с генеративными моделями, может иметь значительные и широкие социальные последствия. В будущем мы планируем проанализировать, как такие модели, как DALL·E, связаны с социальными проблемами, такими как экономическое воздействие на определенные рабочие процессы и профессии, потенциальная предвзятость результатов модели и долгосрочные этические проблемы, связанные с этой технологией.
Возможности
Мы находим, что DALL * E способен создавать правдоподобные образы для большого разнообразия предложений, которые исследуют композиционную структуру языка. Мы проиллюстрируем это с помощью серии интерактивных визуальных элементов в следующем разделе. Образцы, показанные для каждой подписи в визуальных эффектах, получены путем взятия верхних 32 из 512 после повторного сканирования с помощью клипа, но мы не используем никакого ручного сбора вишен, кроме миниатюр и автономных изображений, которые появляются снаружи.[3]
Управляющие атрибуты
Мы проверяем способность DALL * E изменять несколько атрибутов объекта, а также количество раз, когда он появляется.
Нажмите, чтобы отредактировать текстовое приглашение или просмотреть дополнительные изображения, созданные искусственным интеллектом
пятиугольные зеленые часы. зеленые часы в форме пятиугольника.

navigatedownwide
куб, сделанный из дикобраза. куб с фактурой дикобраза.

navigatedownwide
на столе стоит коллекция бокалов

navigatedownwide
Рисование нескольких объектов
Одновременное управление несколькими объектами, их атрибутами и пространственными отношениями представляет новую проблему. Например, рассмотрим фразу " Ежик в красной шляпе, желтых перчатках, синей рубашке и зеленых брюках.” Чтобы правильно интерпретировать эту фразу, даль·Е необходимо не только правильно составить каждый кусок одежды с животным, но и форма объединения (шляпа, красный), (перчатки, желтый) (рубашка, синий), и (брюки, зеленый), не смешивая их.[4] мы тестируем даль·е способность сделать это для относительное позиционирование, укладки объектов, и управление несколькими атрибутами.
маленький красный блок сидит на большом зеленом блоке

navigatedownwide
стопка из 3 кубиков. Красный куб находится на вершине, сидя на зеленом Кубе. зеленый куб находится в середине, сидя на синем Кубе. синий куб находится на дне.

navigatedownwide
эмодзи пингвиненка в синей шляпе, красных перчатках, зеленой рубашке и желтых брюках

navigatedownwide
Хотя DALL * E действительно обеспечивает некоторый уровень управляемости атрибутами и позициями небольшого числа объектов, вероятность успеха может зависеть от того, как сформулирована подпись. По мере того как вводится все больше объектов, DALL·E склонен путать ассоциации между объектами и их цветами, и вероятность успеха резко снижается. Мы также отмечаем, что DALL·E хрупок в отношении перефразирования подписи в этих сценариях: альтернативные, семантически эквивалентные подписи часто не дают правильных интерпретаций.
Визуализация перспективы и трехмерности
Мы находим, что DALL·E также позволяет контролировать точку зрения сцены и 3D-стиль, в котором сцена визуализируется.
экстремальный крупный план капибары, сидящей в поле

navigatedownwide
капибара из вокселей сидит в поле

navigatedownwide
Чтобы продвинуть это дальше, мы проверяем способность Далла многократно рисовать голову хорошо известной фигуры под каждым углом из последовательности одинаково расположенных углов и находим, что мы можем восстановить плавную анимацию вращающейся головы.
фотография бюста Гомера

navigatedownwide
DALL·E, по-видимому, может применять некоторые типы оптических искажений к сценам, как мы видим с опциями “вид объектива рыбий глаз” и “сферическая панорама".” Это побудило нас исследовать его способность генерировать отражения.
простой белый куб, смотрящий на свое отражение в зеркале. простой белый куб, смотрящий на себя в зеркало.

navigatedownwide
Визуализация внутренней и внешней структуры
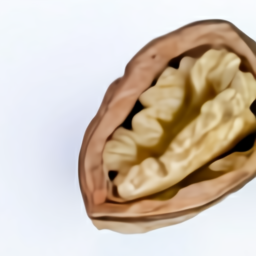
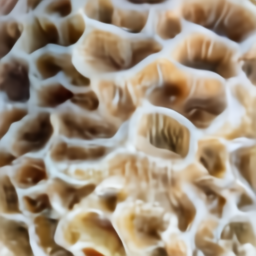
Образцы из” экстремального вида крупным планом “и” рентгеновского " стиля привели нас к дальнейшему изучению способности DALL·E визуализировать внутреннюю структуру с помощью видов поперечного сечения и внешнюю структуру с помощью макросъемки.
вид поперечного сечения грецкого ореха
navigatedownwide
макросъемка мозгового коралла
navigatedownwide
Вывод контекстуальных деталей
Задача перевода текста в изображения недостаточно конкретизирована: одна подпись обычно соответствует бесконечному количеству правдоподобных изображений, поэтому изображение не определено однозначно. Возьмем, к примеру, надпись: “картина, изображающая капибару, сидящую на поле на рассвете.” В зависимости от ориентации капибары может потребоваться нарисовать тень, хотя эта деталь никогда не упоминается явно. Мы исследуем способность DALL * E разрешать недоспецификацию в трех случаях: изменение стиля, настройки и времени; рисование одного и того же объекта в различных ситуациях; и генерировать изображение объекта с определенным текстом, написанным на нем.
картина с изображением капибары, сидящей в поле на рассвете

navigatedownwide
витраж с изображением голубой клубники

navigatedownwide
фасад магазина, на котором написано слово "openai". фасад магазина, на котором написано слово "openai". фасад магазина, на котором написано слово "openai". вход в магазин "openai".
navigatedownwide
С различной степенью надежности DALL * E предоставляет доступ к подмножеству возможностей движка 3D-рендеринга с помощью естественного языка. Он может самостоятельно управлять атрибутами небольшого количества объектов и в ограниченной степени тем, сколько их существует, и тем, как они расположены относительно друг друга. Он также может управлять местоположением и углом, с которого визуализируется сцена, и может генерировать известные объекты в соответствии с точными спецификациями угла и условий освещения.
В отличие от движка 3D-рендеринга, входные данные которого должны быть указаны однозначно и полностью подробно, DALL·E часто способен “заполнить пробелы”, когда подпись подразумевает, что изображение должно содержать определенную деталь, которая явно не указана.
Применение предыдущих возможностей
Далее мы исследуем использование предыдущих возможностей для Моды и дизайна интерьера.
мужской манекен, одетый в оранжево-черную фланелевую рубашку

navigatedownwide
женский манекен, одетый в черную кожаную куртку и золотую плиссированную юбку

navigatedownwide
гостиная с двумя белыми креслами и картиной Колизея. картина установлена над современным камином.

navigatedownwide
спальня на мансарде с белой кроватью рядом с ночным столиком. рядом с кроватью стоит аквариум.

navigatedownwide
Объединение несвязанных понятий
Композиционная природа языка позволяет нам объединять понятия для описания как реальных, так и воображаемых вещей. Мы обнаруживаем, что Далл также обладает способностью объединять разрозненные идеи для синтеза объектов, некоторые из которых вряд ли существуют в реальном мире. Мы исследуем эту способность в двух случаях: перенося качества от различных концепций к животным и проектируя продукты, черпая вдохновение из несвязанных концепций.
улитка, сделанная из арфы. улитка с фактурой арфы.

navigatedownwide
кресло в форме авокадо. кресло, имитирующее авокадо.
navigatedownwide
Иллюстрации животных
В предыдущем разделе мы исследовали способность Далла комбинировать несвязанные понятия при создании образов объектов реального мира. Здесь мы исследуем эту способность в контексте искусства для трех видов иллюстраций: антропоморфизированные версии животных и объектов, животные химеры и смайлики.
иллюстрация младенца дайкона редьки в пачке выгуливающего собаку
navigatedownwide
профессиональная высококачественная иллюстрация химеры черепахи жирафа. жираф, имитирующий черепаху. жираф, сделанный из черепахи.

navigatedownwide
профессиональный высококачественный эмодзи влюбленной чашки бобы

navigatedownwide
Визуальное рассуждение с нулевым выстрелом
GPT-3 может быть проинструктирован выполнять многие виды задач исключительно из описания и подсказки, чтобы генерировать ответ, поставленный в его подсказке, без какой-либо дополнительной подготовки. Например, когда ему предлагают фразу “Вот предложение” человек выгуливает свою собаку в парке“, переведенное на французский язык:”, GPT-3 отвечает "un homme qui prom?ne son chien dans le parc". эта способность называется рассуждением с нулевым выстрелом. Мы находим, что DALL * E расширяет эту возможность до визуальной области и способен выполнять несколько видов задач перевода изображения в изображение, когда это предлагается правильным образом.
точно такой же кот сверху как и эскиз снизу
navigatedownwide
точно такой же чайник сверху с надписью " gpt’ на дне

navigatedownwide
Мы не ожидали, что эта способность появится, и не вносили никаких изменений в нейронную сеть или процедуру обучения, чтобы стимулировать ее. Руководствуясь этими результатами, мы измеряем способность Далла к решению задач аналогического мышления, тестируя его на прогрессивных матрицах Рейвена, визуальном тесте IQ, который получил широкое распространение в XX веке.
последовательность геометрических фигур.

navigatedownwide
Географические знания
Мы обнаруживаем, что Далли узнал о географических фактах, достопримечательностях и районах. Его знание этих концепций удивительно точно в некоторых отношениях и ущербно в других.
фото еды из Китая

navigatedownwide
фотография площади Аламо, Сан-Франциско, с ночной улицы

navigatedownwide
фотография моста Золотые Ворота Сан Франциско

navigatedownwide
Временное знание
В дополнение к изучению знаний Далла о концепциях, изменяющихся в пространстве, мы также исследуем его знания о концепциях, изменяющихся во времени.
фотография телефона из 20-х годов

navigatedownwide
Резюме подхода и предшествующей работы
DALL·E-это простой декодер-трансформатор, который принимает как текст, так и изображение в виде единого потока из 1280 токенов—256 для текста и 1024 для изображения—и моделирует все из них авторегрессионно. Маска внимания на каждом из своих 64 слоев само-внимания позволяет каждому маркеру изображения присутствовать на всех текстовых маркерах. DALL * E использует стандартную каузальную маску для текстовых маркеров и разреженное внимание для маркеров изображений со строкой, столбцом или сверточным рисунком внимания, в зависимости от слоя. Мы планируем предоставить более подробную информацию об архитектуре и процедуре обучения в предстоящей статье.
Синтез текста в изображение был активной областью исследований со времен новаторской работы Reed et. al, чей подход использует GAN, обусловленный текстовыми вложениями. Встраивания производятся кодировщиком, предварительно натренированным с использованием контрастных потерь, не отличающихся от клипа. StackGAN и StackGAN++ используют многомасштабные Gan для увеличения разрешения изображения и улучшения визуальной точности. Аттнган включает в себя внимание между текстовыми и графическими функциями и предлагает контрастную потерю соответствия текстовых и графических функций в качестве вспомогательной цели. Это интересно сравнить с нашим перезапуском с клипом, который делается в автономном режиме. Другая работа включает в себя дополнительные источники контроля во время обучения для улучшения качества изображения. Наконец, работа Nguyen et. al и Cho et.al исследует основанные на выборке стратегии генерации изображений, которые используют предварительно обученные мультимодальные дискриминантные модели.
Подобно выборке отбраковки, используемой в VQVAE-2, мы используем клип для повторного ранжирования верхних 32 из 512 образцов для каждой подписи во всех интерактивных визуальных эффектах. Эта процедура также может рассматриваться как своего рода языковой поиски может оказать значительное влияние на качество выборки.
иллюстрация детской редиски дайкон в пачке, выгуливающей собаку [подпись 1, лучший 8 из 2048 года]
![]()
navigatedownwide
Сноски
Мы решили назвать нашу модель, используя портмоне художника Сальвадора Дали и стену Pixar·E. ?
Лексема - это любой символ из дискретного словаря; для человека каждая английская буква-это лексема из 26-буквенного алфавита. Словарь Далла * Е содержит лексемы как для текстовых, так и для графических концептов. В частности, каждая подпись к изображению представлена максимум 256 BPE-кодированными токенами с размером словаря 16384, а изображение представлено 1024 токенами с размером словаря 8192.
изображения предварительно обрабатываются до разрешения 256x256 во время обучения. Подобно VQVAE, каждое изображение сжимается в сетку дискретных латентных кодов 32x32 с использованием дискретного VAE что мы предварительно тренируемся, используя непрерывную релаксацию. Мы обнаружили, что обучение с использованием релаксации устраняет необходимость в явной кодовой книге, потере EMA или трюках, таких как оживление мертвого кода, и может масштабироваться до больших размеров словаря. ?Более подробная информация приведена в следующем разделе. ?
Эта задача называется связыванием переменных и широко изучена в литературе. ?
Рекомендации
- Reed, S., Akata, Z., Yan, X., Logeswaran, L., Schiele, B., Lee, H. (2016). "Генеративный состязательный текст к синтезу образов". В ICML 2016.
- Reed, S., Akata, Z., Mohan, S., Tenka, S., Schiele, B., Lee, H. (2016). "Учимся, что и где рисовать". В NIPS 2016.
- Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang X., Metaxas, D. (2016). "StackGAN: Text to photo-реалистичный синтез изображений со сложенными генеративными состязательными сетями". В ICCY 2017.
- Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., Metaxas, D. (2017). “StackGAN++: реалистичный синтез изображений со сложенными генеративными состязательными сетями”. В IEEE TPAMI 2018.
- Xu, T., Zhang, P., Huang, Q., Zhang, H., Gan, Z., Huang, X., He, X. (2017). “AttnGAN: мелкозернистый текст для генерации изображений с помощью генеративных состязательных сетей внимания.
- Li, W., Zhang, P., Zhang, L., Huang, Q., He, X., Lyu, S., Gao, J. (2019). "Объектно-ориентированный синтез текста и изображения с помощью состязательного обучения". В CVPR 2019.
- Koh, J. Y., Baldridge, J., Lee, H., Yang, Y. (2020). "Генерация текста в изображение, основанная на мелкозернистом внимании пользователя". В WACV 2021.
- Nguyen, A., Clune, J., Bengio, Y., Dosovitskiy, A., Yosinski, J. (2016). "Plug & play generative networks: условная итеративная генерация изображений в латентном пространстве.
- Cho, J., Lu, J., Schwen, D., Hajishirzi, H., Kembhavi, A. (2020). "X-LXMERT: краска, подпись и ответы на вопросы с помощью мультимодальных трансформаторов”. EMNLP 2020.
- Кингма, Дидерик п. и Макс Уэллинг. ”Автоматическое кодирование вариационных байесов". препринт arXiv (2013).
- Резенде, Данило Хименес, Шакир Мохаммед и Даан Вирстра. "Стохастическое обратное распространение и приближенный вывод в глубоких генеративных моделях”. препринт arXiv (2014).
- Jang, E., Gu, S., Poole, B. (2016). "Категориальная репараметризация с помощью Gumbel-softmax".
- Maddison, C., Mnih, A., Teh, Y. W. (2016). "Конкретное распределение: непрерывная релаксация дискретных случайных величин".
- van den Oord, A., Vinyals, O., Kavukcuoglu, K. (2017). “обучение нейронному дискретному представлению”.
- Razavi, A., van der Oord, A., Vinyals, O. (2019). "Генерация разнообразных высокоточных изображений с помощью VQ-VAE-2”.
- Andreas, J., Klein, D., Levine, S. (2017). “обучение с латентным языком”.
- Смоленский, П. "Тензорное произведение переменной привязки и представление символических структур в коннекционистских системах”.
- Plate, T. (1995). "Голографические редуцированные представления: алгебра свертки для композиционных распределенных представлений".
- Гейлер, Р. (1998). "Мультипликативная привязка, операторы представления и аналогия".
- Канерва, П. (1997). “Полностью распределенные представления".
Телеграм: t.me/ainewsline
Источник: openai.com