MeDAL: датасет для расшифровки медицинских аббревиатур
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-01-11 14:02

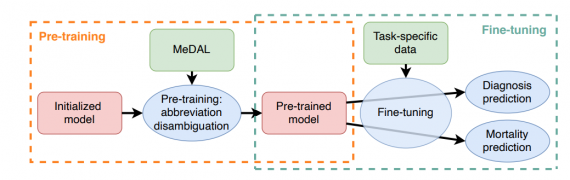
MeDAL — это датасет для расшифровки медицинских аббревиатур. Датасет собирали для предобучения моделей обработки естественного языка для медицинского домена. Данные опубликовали на воркшопе ClinicalNLP на конференции EMNLP.
По результатам экспериментов, предобучение на MeDAL улучшает предсказательную способность моделей на медицинских задачах и ускоряет сходимость на этапе дообучения.
Подробнее про датасет
Medical Dataset for Abbreviation Disambiguation for Natural Language Understanding (MeDAL) состоит из текстов 14,393,619 статей. Среднее количество аббревиатур в статье — 3.
MeDAL собирали из абстрактов статей на PubMed. PubMed — это поисковый сервис, который индексирует научные публикации биомедицинской тематики. Создатели использовали обратную замену для генерации примеров без человеческой разметки. В тексте находили полный термин, для которого была известна аббревиатура, и его заменяли на аббревиатуру. Чтобы не удалять из датасета все полные термины, термины заменяли на аббревиатуры с заданной вероятностью.
Телеграм: t.me/ainewsline
Источник: neurohive.io