HateXplain: датасет для интерпретируемого распознавания хейтспича
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-01-15 01:52

HateXplain — это датасет для обучения моделей распознавания оскорблений в тексте. Датасет собирали исследователи из Indian Institute of Technology и University of Hamburg. Датасет разрабатывали так, что бы учитывать метрики интерпретируемости моделей распознавания.
Зачем это нужно
Хейтспич — это комплексная проблема на онлайн социальных площадках. Сейчас фокус исследовательского сообщества часто направлен на разработку новых методов распознавания хейтспича. При этом мало вниманию уделяют исследованию смещений в данных и интерпретируемости моделей. HateXplain призван спровоцировать исследования этих малоизученных аспектов распознавания хейтспича.
Подробнее про датасет
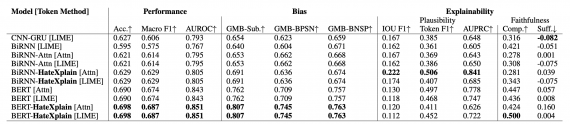
Всего в датасете 20148 текстовых поста. Каждый пост в датасете имеет три типа аннотации:
- Базовая: разметка класса текста (хейт, оскорбление или нейтральный);
- Целевое сообщество для оскорбления;
- Повод: части текста, которые являются основополагающими причинами оскорбления
Тестирование существующих подходов
Исследователи протестировали state-of-the-art модели на датасете. В то время как с задачей классификации тональности текста модели справляются хорошо, они плохо справляются с интерпретацией тональности. В качестве метрик интерпретируемости использовали model plausibility и faithfulness.
Телеграм: t.me/ainewsline
Источник: neurohive.io