Описание
Глубокие нейронные сети доказали свою эффективность при обработке данных от органов чувств, таких, как изображения и аудио. Однако для табличных данных более популярны древовидные модели. Хорошим свойством древовидных моделей является их естественная интерпретируемость. В этой работе мы представляем Deep Neural Decision Trees (DNDT) –древовидные модели, реализованные нейронными сетями. DNDT внутренне интерпретируем, так как это дерево. Тем не менее, поскольку это также нейронная сеть (NN), ее можно легко реализовать с помощью инструментария NN и обучить по алгоритму градиентного спуска, а не по «жадному» алгоритму (алгоритму «жадного разбиения»). Мы проводим оценку DNDT на нескольких табличных наборах данных, проверяем его эффективность и исследуем сходства и различия между DNDT и обычными деревьями решений. Интересно, что DNDT самообучается как на разделенном, так и на функциональном уровне.
1. Введение
Интерпретируемость прогностических моделей важна, особенно в тех случаях, когда речь идет об этике – правовой, медицинской и финансовой, критически важных приложениях, где мы хотим вручную проверить релевантность модели. Глубокие нейронные сети (Lecun et al., 2015 [18]; Schmidhuber, 2015 [25]) достигли превосходных результатов во многих областях, таких как компьютерное зрение, обработка речи и языковое моделирование. Однако отсутствие интерпретируемости не позволяет использовать в приложениях это семейство моделей как «черный ящик», для которого мы должны знать процедуру прогноза, чтобы верифицировать процесс принятия решения. Более того, в некоторых областях, таких как бизнес-аналитика (BI), часто более важно знать, как каждый фактор влияет на прогноз, а не сам вывод. Методы, основанные на дереве решений (DT), такие как C4.5 (Quinlan, 1993 [23]) и CART (Breiman et al., 1984 [5]), имеют явное преимущество в этом аспекте, поскольку можно легко проследить структуру дерева и точно проверить, как делается прогноз.
В этой работе мы предлагаем новую модель на пересечении этих двух подходов – глубокое нейронное дерево решений (DNDT), исследуем его связи с каждым из них. DNDT- это нейронные сети со специальной архитектурой, где любой выбор весов DNDT соответствует определенному дереву решений и поэтому интерпретируем. Однако, поскольку DNDT реализуется нейронной сетью (NN), она наследует несколько интересных свойств, отличных от традиционных DT: DNDT может быть легко реализован несколькими строками кода в любом программном фреймворке NN; все параметры одновременно оптимизируются с помощью стохастического градиентного спуска, а не более сложной и потенциально неоптимальной процедуры «жадного» расщепления. DNDT готов к крупномасштабной обработке с обучением на основе мини-патчей и ускорением GPU от «коробочного решения», его можно подключить к любой более крупной модели NN в качестве строительного блока для сквозного обучения с обратным распространением (back-propagation).
2. Похожие работы
Модели на основе деревьев решений. Древовидные модели широко используются в обучении под наблюдением, например, в задачах классификации. Они рекурсивно разбивают входное пространство и присваивают метку/оценку конечному узлу. Хорошо известные древовидные модели используют C4. 5 (Quinlan, 1993 [23]) и CART (Breiman et al., 1984 [5]). Ключевым преимуществом древовидных моделей является то, что они легко интерпретируются, поскольку предсказания задаются набором правил. Также часто используется ансамбль из нескольких деревьев, таких как «случайный лес» (Breiman, 2001 [6]) и XGBoost (Chen & Guestrin, 2016 [8]), чтобы повысить производительность за счет интерпретируемости. Такие древовидные модели часто конкурируют или превосходят нейронные сети в задачах прогнозирования с использованием табличных данных.
Интерпретируемые модели. По мере того как предсказания, основанные на машинном обучении, используются повсеместно и затрагивают многие аспекты нашей повседневной жизни, фокус исследований смещается от производительности модели (например, эффективности и точности) к другим факторам, таким как интерпретируемость (Weller, 2017 [26]; Doshi-Velez, 2017 [11]). Это особенно необходимо в приложениях, где существуют проблемы этические (Bostrom & Yudkowsky, 2014 [4]) или безопасности, и предсказания моделей должны быть объяснимы, чтобы проверить правильность процесса рассуждения или обосновать решения для них. В настоящее время предпринимается ряд попыток сделать модели объяснимыми. Некоторые из них являются модельно-агностическими (Ribeiro et al., 2016 [24]), в то время как большинство из них связаны с определенным типом модели, например, классификаторами на основе правил (Dash et al., 2015 [10]; Malioutov et al., 2017 [19]), моделями ближайших соседей (Kim et al., 2016 [15]) и нейронными сетями (Kim et al., 2017 [16]).
Нейронные сети и деревья решений. В некоторых исследованиях предлагалось унифицировать модели нейронной сети и деревьев решений. Bul & Kontschieder (2014) [7] предложили нейронные «леса решений» ( Neural Decision Forests NDF) как ансамбль нейронных деревьев решений, где расщепленные функции реализуются случайными многослойными персептронами. Deep-NDF (Kontschieder et al., 2015 [17]) использовал стохастическую и дифференцируемую модель дерева решений, которая совместно изучает представления (через CNNs) и классификацию (через деревья решений). Предлагаемый нами DNDT во многом отличается от этих методов. Во-первых, у нас нет альтернативной процедуры оптимизации для изучения структуры (разделения) и обучения параметров (матрица оценок). Вместо этого мы изучаем их все с помощью однопроходного обратного распространения (back propagation). Во-вторых, мы не ограничиваем разбиение двоичным (левым или правым), поскольку мы применяем дифференцируемую функцию разбиения, которая может разбивать узлы на несколько (? 2) листьев. Наконец, что наиболее важно, мы разрабатываем нашу модель специально для интерпретируемости, особенно для приложений к табличным данным, где мы можем интерпретировать каждую входную функцию. Напротив, модели в (Bul & Kontschieder, 2014 [7]; Kontschieder et al., 2015 [17]) предназначены для прогнозирования и применяются к необработанным данным изображения. Некоторые проектные решения делают их непригодными для табличных данных. Например, в Kontschieder et al. (2015 [17]), они используют менее гибкое дерево, в котором структура жестко фиксируется, пока изучается разбиение узла.
Несмотря на похожее название, наша работа кардинально отличается от работы Балестриеро (2017 [2]), которая разработала своего рода «наклонное» дерево решений, реализованное нейронной сетью. В отличие от обычных «одномерных» деревьев решений, каждый узел в «наклонном» дереве решений включает в себя все функции, а не одну функцию, что делает модель не интерпретируемой.
Альтернативные активаторы дерева решений. Обычные DT изучаются рекурсивным «жадным» расщеплением признаков (Quinlan, 1993; Breiman et al., 1984 [23]). Это эффективно и имеет некоторые преимущества для выбора признаков, однако такой «жадный» поиск может быть неоптимальным (Norouzi et al., 2015 [20]). В некоторых недавних работах исследуются альтернативные подходы к обучению деревьев решений, которые направлены на достижение лучшей производительности при менее требовательной оптимизации, например с помощью латентного структурированного прогнозирования переменных (Norouzi et al., 2015 [20]) или обучения контроллера расщепления RNN с использованием обучения с подкреплением (Xiong et al., 2017 [28]). Напротив, наш DNDT намного проще, чем указанные, но все же потенциально может найти лучшие решения, чем обычные индукторы DT, с одновременным поиском структуры и параметров дерева с SGD. Наконец, также отмечаем, что в то время как обычные активаторы DT используют только двоичные расщепления (для простоты), наша модель DNDT может одинаково легко работать с расщеплениями произвольной мощности, что иногда может привести к более интерпретируемым деревьям.
3. Методология
3.1. Функция мягкого контейнера
Основной модуль, который мы здесь реализуем, - это функция мягкой ячейки (Dougherty et al., 1995) или объединения множества точечных объектов в динамические полигоны (бины), которую мы будем использовать для принятия решений о разделении в DNDT. Как правило, функция биннинга принимает в качестве входных данных вещественный скаляр x и выдает индекс ячейки, которой он принадлежит. Жесткое разделение по ячейкам недифференцируемое, поэтому мы предлагаем дифференцируемую аппроксимацию этой функции.
Предположим, что у нас есть непрерывная переменная x, которую мы хотим разбить на N + 1 интервалов. Это приводит к необходимости n точек среза, которые в данном контексте являются обучаемыми переменными. Обозначим точки среза [?1, ?2,…, ?n] как монотонно возрастающие, то есть ?1 < ?2 < · · · < ?n. Во время обучения порядок ? может быть перетасован после обновления, поэтому мы должны сначала сортировать их в каждом прямом проходе. Однако это не повлияет на дифференцируемость, потому что сортировка просто меняет местами позиции ?.
Теперь построим однослойную нейронную сеть с функцией активации softmax.
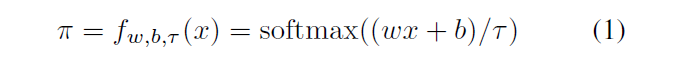
Здесь w-это константа, а не обучаемая переменная, и ее значение задается как w = [1; 2; : : : ; n + 1]. b строится как,
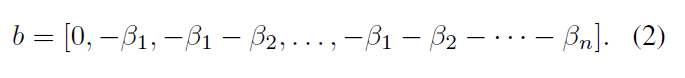
?> 0 - фактор напряженности. При ? ? 0 выход стремится к текущему вектору.
Мы можем проверить это, проверив три последовательных логита
![]()
Когда у нас есть как
![]()
![]()
x должен попасть в интервал
![]()
Таким образом, нейронная сеть в уравнении 1 будет производить почти однократное «горячее» кодирование ячейки x, особенно при более низкой напряженности. При желании, мы можем применить трюк «отжига наклона» (Chung et al., 2017 [9]), который постепенно снижает напряжение при обучении, чтобы, в конце концов, получить более детерминированную модель.
Если кто-то предпочитает фактический «горячий» (текущий кодируемый) вектор, можно применить Straight-Through (ST) Gumbel-Softmax (Jang et al., 2017): для прямого прохода мы сэмплируем однократный вектор, используя хитрость с Gumbel-Max, тогда как для обратного прохода (backward pass) мы используем Gumbel-Softmax при вычислении градиента (см. Bengio (2013 [3]) для более подробного анализа.
На рис.1 показан конкретный пример, где мы имеем скаляр x в диапазоне [0, 1] и две точки среза в 0.33 и 0.66 соответственно. Основываясь на уравнениях 1 и 2, мы имеем три логита o1 = x, o2 = 2x ? 0.33, o3 = 3x ? 0.99.
![Рисунок 1. Конкретный пример нашей функции мягкого биннинга с использованием точек среза в 0.33 и 0.66. Ось x - это значение непрерывной входной переменной x2 [0; 1]. Вверху слева: исходные значения логитов; вверху справа: значения после применения функции softmax с т = 1; Внизу слева: т= 0.1; внизу справа: т = 0.01.](https://habrastorage.org/getpro/habr/upload_files/ab5/1bd/c1f/ab51bdc1f73be966aff6556d810533d3.PNG "Рисунок 1. Конкретный пример нашей функции мягкого биннинга с использованием точек среза в 0.33 и 0.66. Ось x - это значение непрерывной входной переменной x2 [0; 1]. Вверху слева: исходные значения логитов; вверху справа: значения после применения функции softmax с т = 1; Внизу слева: т= 0.1; внизу справа: т = 0.01.")
3.2 Построение прогнозов
Учитывая нашу функцию биннинга, ключевая идея состоит в том, чтобы построить дерево решений с помощью операции Кронекера ?. Предположим, что у нас есть входной экземпляр
![]()
Связывая каждый признак xd со своей собственной нейронной сетью fd (xd), мы можем исчерпывающе найти все конечные узлы с помощью,
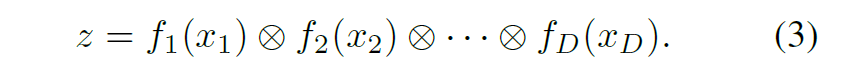
Здесь z теперь также является почти «горячим» вектором, который указывает индекс листового узла, куда поступает экземпляр x. Наконец, мы предполагаем, что линейный классификатор на каждом листе z классифицирует поступающие туда экземпляры. DNDT проиллюстрирован на Рис. 2.
. Вверху: DNDT - показано, где красным шрифтом указаны обучаемые переменные, а черным – константы. Внизу: DT – визуализация той же сети, что и обычное дерево решений. Дроби указывают маршрут случайно выбранных 6 классифицируемых экземпляров.")
3.3 Обучение дерева
С помощью описанного выше метода мы можем направлять входные экземпляры в конечные узлы и классифицировать их. Таким образом, обучение дерева решений теперь становится вопросом обучения в узловых точках среза и листьев классификаторов. Поскольку все шаги нашего прямого прохода дифференцируемы, все параметры (Рис. 2, Красный) теперь могут быть напрямую и одновременно обучены с помощью SGD.
Обсуждение. DNDT хорошо масштабируется с количеством экземпляров благодаря мини-пакетному обучению в стиле нейронной сети. Однако ключевым недостатком этого стиля до сих пор является то, что из-за использования продукта Kronecker он не масштабируется по количеству функций. В нашей текущей реализации мы избегаем этой проблемы с "широкими" наборами данных, обучая «лес» случайного подпространства (Ho, 1998 [13]) - за счет нашей интерпретируемости. То есть вводится несколько деревьев, каждое из которых обучается на случайном подмножестве признаков. Лучшим решением, которое не требует не интерпретируемого «леса», является использование разреженности конечного разделения на ячейки во время обучения: количество непустых листьев растет намного медленнее, чем общее количество листьев. Но это несколько усложняет простую в остальном реализацию DNDT.
4. Эксперименты
4.1 Реализация
DNDT концептуально прост и легок в реализации с помощью ? 20 строк кода в TensorFlow или PyTorch. Поскольку он реализован как нейронная сеть, DNDT поддерживает "из коробки" ускорение GPU и мини-пакетное обучение наборов данных, которые не помещаются в память, благодаря современным фреймворкам глубокого обучения.
4.2 Наборы данных и конкуренты
Мы сравниваем DNDT с нейронными сетями (реализованными TensorFlow (Abadi et al., 2015) [1]) и деревом решений (от Scikit-learn (Pedregosa et al., 2011 [22])) на 14 наборах данных, собранных из Kaggle и UCI (подробности набора данных см. В табл. 1).
Для базовой линии дерева решений (DT) мы установили два ключевых критерия гиперпараметров: критерий 'gini' и разделитель – 'best'. Для нейронной сети (NN) мы используем архитектуру из двух скрытых слоев по 50 нейронов в каждом для всех наборов данных. DNDT также имеет гиперпараметр - количество точек среза для каждого объекта (коэффициент ветвления), который мы устанавливаем равным 1 для всех объектов и наборов данных. Подробный анализ эффекта этого гиперпараметра можно найти в разделе 4.4. Для наборов данных с более чем 12 признаками, мы используем ансамбль DNDT, где каждое дерево выбирает 10 признаков случайным образом, и у нас есть 10 уровней в общей сложности. Окончательный прогноз дается большинством голосов.
4.3 Точность
Мы оцениваем производительность DNDT, дерева решений и нейросетевых моделей на каждом из наборов данных в Табл. 1. точность тестового набора представлена в Табл.2.
В целом наиболее эффективной моделью является DT. Хорошая производительность DT неудивительна, поскольку эти наборы данных в основном табличные, а размерность объектов относительно невелика.
) и UCI: количество экземпляров (#inst.), количество объектов (#feat.) и количество классов (#cl.)")
 указывает, что используется ансамблевая версия.")
Условно говоря, нейронные сети не имеют явного преимущества в отношении такого рода данных. Однако DNDT немного лучше, чем «ванильная» нейронная сеть, так как она ближе к дереву решений по построению. Конечно, это только ориентировочный результат, так как все эти модели имеют настраиваемые гиперпараметры. Тем не менее интересно, что ни одна модель не обладает доминирующим преимуществом. Это напоминает теоремы об отсутствии «бесплатного обеда» (Wolpert, 1996[27]).
4.4 Анализ активных точек среза
В DNDT количество точек среза на объект является параметром сложности модели. Мы не связываем значения точек среза, а это значит, что некоторые из них неактивны, например, они либо меньше минимального xd, либо больше максимального xd.
В этом разделе мы исследуем, сколько точек среза фактически используется после обучения DNDT. Точка среза активна, когда по крайней мере один экземпляр из набора данных попадает на каждую ее сторону. Для четырех наборов данных-Car Evaluation, Pima, Iris и Haberman мы устанавливаем количество точек среза на объект от 1 до 5 и вычисляем процент активных точек среза, как показано на рис. 3. Видно, что по мере увеличения числа точек среза их использование в целом уменьшается. Это означает, что DNDT несколько саморегулируется: он не использует все доступные ему параметры.
 активных точек, используемых DNDT.")
Мы можем дополнительно исследовать, как количество доступных точек среза влияет на производительность этих наборов данных. Как видно из Рис. 4, производительность первоначально увеличивается с увеличением числа точек среза, а затем стабилизируется после определенного значения. Это обнадеживает, потому что это означает, что большие DNDT не слишком подходят к данным обучения, даже без явной регуляризации.
.")
4.5 Анализ активных признаков
При обучении DNDT также возможно, что для определенного объекта все точки среза неактивны. Это соответствует отключению функции, чтобы она не влияла на прогнозирование, аналогично обычному ученику DT, который никогда не выбирает данную функцию, чтобы задать узел-распознаватель в любом месте дерева. В этом разделе мы анализируем, как DNDT исключает функции таким образом. Мы запускаем DNDT 10 раз и записываем, сколько раз данный объект исключается из-за того, что все его точки среза неактивны.
Учитывая случайность через инициализируемые веса для мини-пакетной выборки, мы наблюдаем, что некоторые функции (например, функция индекса 0 в iris) последовательно игнорируются DNDT (см. табл. 3 для всех результатов). Это говорит о том, что DNDT делает некоторый неявный выбор объектов, выталкивая точки отсечения за границы данных для несущественных объектов. В качестве побочного продукта мы можем получить меру важности (веса) функции из набора функции в течение нескольких запусков: чем больше функция игнорируется, тем менее важной она, вероятно, и будет.
 случаев, когда DNDT игнорирует каждую функцию")
4.6 Сравнение с деревом решений
Используя методы, разработанные в разделе 4.5, мы исследуем, благоприятствуют ли DNDT и DT со сходными характеристиками. Мы сравниваем важность признака через критерий gini (Джини), используемый в дереве решений (Рис. 5), с нашей метрикой скорости отбора (табл.3).
.")
Сравнивая эти результаты, мы видим, что иногда DNDT и DT предпочитают выбор признаков, например, для Iris они оба оценивают Признак 3 как наиболее важный. Но бывает, что они также могут иметь разные взгляды, например, для Хабермана DT выбрал функцию 0 как наиболее важную, тогда как DNDT полностью проигнорировал ее. На самом деле DNDT использует только функцию 2 для прогнозирования, которая занимает второе место по DT. Однако такого рода разногласия не обязательно могут привести к существенным различиям в производительности. Как видно из Табл. 2, для Хабермана точность испытаний DNDT и DT составляет 70,9% и 66,1% соответственно.
Наконец, мы количественно оцениваем сходство ранжирований признаков DNDT и признаков DT, вычисляя Tau критерия Кендалла по двум рейтинговым спискам. Результаты, приведенные в Табл.4, свидетельствуют об умеренной корреляции в целом.

4.7 Ускорение GPU
Наконец, мы проверяем легкость ускорения обучения DNDT с помощью обработки графическим процессором - возможность, которая не является обычной или простой для DT. Увеличивая количество точек отсечения для каждой функции, мы можем получить более крупные модели, для которых режим графического процессора имеет значительно меньшее время работы (см. Рис. 6).

5. Заключение
Мы представили древовидную модель на основе нейронной сети DNDT. Он имеет лучшую производительность, чем NN для определенных наборов табличных данных, при этом обеспечивает интерпретируемое дерево решений. Между тем, по сравнению с обычными DT, DNDT проще в реализации, одновременно выполняет поиск в древовидной структуре и параметрах с помощью SGD и легко ускоряется на GPU. Есть много возможностей для будущей работы. Мы хотим исследовать источник наблюдаемой нами саморегуляции; изучить подключение DNDT как модуля, подключенного к обычному элементу обучения CNN, для сквозного обучения; выяснить, можно ли использовать обучение на основе SGD целого дерева DNDT в качестве постобработки для точной настройки обычных, «жадно» обученных DT и повышения их производительности; выяснить, можно ли использовать многие подходы к адаптивному обучению на основе NN для обеспечения возможности переноса обучения для DT.
Ссылки
-
Abadi, Mart??n, Agarwal, Ashish, Barham, Paul, Brevdo, Eugene, Chen, Zhifeng, Citro, Craig, Corrado, Greg S., Davis, Andy, Dean, Jeffrey, Devin, Matthieu, Ghemawat, Sanjay, Goodfellow, Ian, Harp, Andrew, Irving, Geoffrey, Isard, Michael, Jia, Yangqing, Jozefowicz, Rafal, Kaiser, Lukasz, Kudlur, Manjunath, Levenberg, Josh, Mane, Dandelion, Monga, Rajat, Moore, ? Sherry, Murray, Derek, Olah, Chris, Schuster, Mike, Shlens, Jonathon, Steiner, Benoit, Sutskever, Ilya, Talwar, Kunal, Tucker, Paul, Vanhoucke, Vincent, Vasudevan, Vijay, Viegas, Fernanda, Vinyals, Oriol, Warden, Pete, Wattenberg, Martin, Wicke, Martin, Yu, Yuan, and Zheng, Xiaoqiang. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. URL https://www.tensorflow.org/.
-
Balestriero, R. Neural Decision Trees. ArXiv e-prints, 2017.
-
Bengio, Yoshua. Estimating or propagating gradients through stochastic neurons. CoRR, abs/1305.2982, 2013.
-
Bostrom, Nick and Yudkowsky, Eliezer. The ethics of artificial intelligence, pp. 316334. Cambridge University Press, 2014.
-
Breiman, L., H. Friedman, J., A. Olshen, R., and J. Stone, C. Classification and Regression Trees. Chapman & Hall, New York, 1984.
-
Breiman, Leo. Random forests. Machine Learning, 45(1): 5–32, October 2001.
-
Bul, S. and Kontschieder, P. Neural decision forests for semantic image labelling. In CVPR, 2014.
-
Chen, Tianqi and Guestrin, Carlos. Xgboost: A scalable tree boosting system. In KDD, 2016.
-
Chung, J., Ahn, S., and Bengio, Y. Hierarchical Multiscale Recurrent Neural Networks. In ICLR, 2017.
-
Dash, S., Malioutov, D. M., and Varshney, K. R. Learning interpretable classification rules using sequential rowsampling. In ICASSP, 2015.
-
Doshi-Velez, Finale; Kim, Been. Towards a rigorous science of interpretable machine learning. ArXiv e-prints, 2017.
-
Dougherty, James, Kohavi, Ron, and Sahami, Mehran. Supervised and unsupervised discretization of continuous features. In ICML, 1995.
-
Ho, Tin Kam. The random subspace method for constructing decision forests. IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(8):832–844, 1998.
-
Jang, E., Gu, S., and Poole, B. Categorical Reparameterization with Gumbel-Softmax. In ICLR, 20
-
Kim, B., Gilmer, J., Viegas, F., Erlingsson, U., and Wattenberg, M. TCAV: Relative concept importance testing with Linear Concept Activation Vectors. ArXiv e-prints, 2017.
-
Kim, Been, Khanna, Rajiv, and Koyejo, Sanmi. Examples are not enough, learn to criticize! Criticism for interpretability. In NIPS, 2016.
-
Kontschieder, P., Fiterau, M., Criminisi, A., and Bul, S. R. Deep neural decision forests. In ICCV, 2015.
-
Lecun, Yann, Bengio, Yoshua, and Hinton, Geoffrey. Deep learning. Nature, 521(7553):436–444, 5 2015.
-
Malioutov, Dmitry M., Varshney, Kush R., Emad, Amin, and Dash, Sanjeeb. Learning interpretable classification rules with boolean compressed sensing. In Transparent Data Mining for Big and Small Data, pp. 95–121. Springer International Publishing, 2017.
-
Norouzi, Mohammad, Collins, Maxwell D., Johnson, Matthew, Fleet, David J., and Kohli, Pushmeet. Efficient non-greedy optimization of decision trees. In NIPS, 2015.
-
Paszke, Adam, Gross, Sam, Chintala, Soumith, Chanan, Gregory, Yang, Edward, DeVito, Zachary, Lin, Zeming, Desmaison, Alban, Antiga, Luca, and Lerer, Adam. Automatic differentiation in pytorch. In NIPS Workshop on Autodiff, 2017.
-
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
-
Quinlan, J. Ross. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers Inc., 1993.
-
Ribeiro, Marco Tulio, Singh, Sameer, and Guestrin, Carlos. ”why should i trust you?”: Explaining the predictions of any classifier. In KDD, 2016.
-
Schmidhuber, J. Deep learning in neural networks: An overview. Neural Networks, 61:85–117, 2015.
-
Weller, Adrian. Challenges for transparency. In ICML Workshop on Human Interpretability in Machine Learning, pp. 55–62, 2017.
-
Wolpert, David H. The lack of a priori distinctions between learning algorithms. Neural Computation, 8(7):1341–1390, 1996.
-
Xiong, Zheng, Zhang, Wenpeng, and Zhu, Wenwu. Learning decision trees with reinforcement learning. In NIPS Workshop on Meta-Learning, 2017.