Что не так с современным машинным обучением. Расшифровка подкаста с Дмитрием Ветровым
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-01-25 18:30

В этом выпуске мы обсуждали:
- Почему современное машинное обучение стоит «примерно на уровне естественных наук XVIII века»?
- Могут ли нейросети начать закреплять внутри себя выученные знания?
- Почему опасно игнорировать необъяснимые «странности» нейросетей?
Оглавление выпуска
- 01:32 — Что такое байесовские методы и зачем они в машинном обучении
- 07:45 — Машинное обучение как «недонаука»: современное состояние ИИ
- 10:18 — Вредят ли корпорации поиску новых методов машинного обучения
- 12:29 — GPT-3, мультидоменный ИИ, «сильный» ИИ
- 18:29 — Когда можно доверить ИИ судьбоносные решения
- 20:57 — Смена технологической парадигмы в разработке ИИ
- 22:28 — Стоит ли помнить про онтологии и возможны ли гибриды нейросетей и символьного ИИ
- 25:19 — Как открыть «черный ящик»: проблема интерпретируемости нейросетей
- 28:06 — Пересадка из Яндекс.Такси в Яндекс.Толоку: разметка данных для машинного обучения
- 31:08 — Должен ли ИИ быть похож на мозг, а его разработчики — следовать за открытиями нейрофизиологов?
- 33:33 — Чем заменить тест Тьюринга.
- 40:42 — Блиц: самые крутые книжки и самые эпичные провалы в области ИИ
В выпуске были упомянуты
книги, ссылки, термины, персоналии
- 01:32 — байесовские методы в машинном обучении
- 08:27 — Ричард Фейнман и подход «shut up and calculate»
- 12:29 — GPT-3
- 13:29 — Residual Network
- 14:07 — Кайминг Хэ, датасаентист из Facebook AI Research
- 23:33 — Михаил Бурцев и рассказ о будущем искусственного интеллекта
- 23:49 — понятие “knowledge graph”
- 40:57 — Книги
Ссылки и полезная информация
Текстовая версия выпуска
Интро
Даниил Скоринкин: Привет, друзья! Это очередной выпуск подкаста “Неопознанный искусственный интеллект или сокращенно НИИ от издания “Системный блокъ”. Подкаста, в котором мы пытаемся разобраться, что называют искусственным интеллектом сегодня, не зря ли там присутствует слово интеллект, и в какую сторону будет развиваться эта область завтра. Сегодня у нас в студии как обычно двое ведущих: это я Даниил Скоринкин — главный редактор Системного Блока…
Анатолий Старостин: И я, Анатолий Старостин — руководитель службы развития технологий медиасервисов Яндекса.
Даниил Скоринкин: Ну а в гостях у нас Дмитрий Ветров — профессор-исследователь факультета компьютерных наук Высшей школы экономики. Дмитрий, расскажите немного о себе.
Дмитрий Ветров: Основное, чем я занимаюсь, это руковожу исследовательской группой байесовских методов, сокращенно байес-группой, которой уже лет 14, сейчас в ней примерно 30-40 человек, немножко цифры меняются от года к году. Ну а основную сферу деятельности я бы определил как научные исследования в сфере технологий искусственного интеллекта.
Что такое байесовские методы и зачем они в машинном обучении
01:32 Даниил Скоринкин: Расскажите,что такое байесовские методы и чем они лучше, перспективнее, интереснее других методов машинного обучения, почему это так важно.
Анатолий Старостин: И вообще, наверное для наших слушателей было бы здорово услышать, чем они отличаются от методов глубокого обучения, о которых сейчас говорят везде.
Дмитрий Ветров: Байесовские методы основаны на так называемом байесовском подходе к теории вероятности мат статистики. Чем вообще занимается статистика? Неважно, байесовская или не байесовская. Вообще машинное обучение, как справедливо было сказано одним из сотрудников Яндекса — это просто применение методов математической статистики на компьютере. Статистика занимается обработкой данных и попыткой по наблюдаемым данным оценить какие-то неизвестные параметры, представляющие для нас интерес. Например. если мы говорим про современное глубокое или глубинное обучение, наблюдаемые данные — собственно нашей обучающей выборки, а параметры, которые для нас интерес представляют — это веса нейронной сети, настроив которые мы дальше уже можем новые объекты, новые объемы данных обрабатывать и какие-то целевые переменные прогнозировать.
информационная вставка
Целевая переменная (также называется «предсказанием» и «зависимой переменной») – это результат процесса, который мы хотим научиться предсказывать на основе имеющихся данных. Например, если мы учим модель находить картинки с котиками и без них, целевая переменная может иметь значение 0, если на картинке нет котика, и 1 – если на картинке котик найден.
Так вот, те классические статистические методы обоснованы теоретически в ситуации, когда объем наблюдаемых данных много больше, чем количество параметров, которые мы пытаемся оценить по наблюдаемым данным. Байесовский подход является обобщением статистики и применим, статистически обоснован в ситуации, когда у нас эти условия не выполнены, то есть, когда объем, количество оцениваемых параметров сопоставим или даже больше, чем объем наблюдаемых данных.
Даниил Скоринкин: Можно как-то пример привести, чтобы людям было понятно?
Дмитрий Ветров: Да, можно, более того, нужно. Пример, собственно, простой. Все современные нейросетевые модели, глубинного обучения содержат в себе сотни тысяч миллионов параметров, а при этом обучаются они по обучающим выборкам размером в десятки сотни тысяч. То есть, размер обучающей выборки существенно меньше, чем число весов нейронной сети, которые мы пытаемся отследить.
Даниил Скоринкин: Условно, у нас есть сотни тысяч картинок с котиками, а параметрами у нас что является.
Дмитрий Ветров: Веса нейронной сети.
Даниил Скоринкин: То есть, некоторые абстрактные цифры, которые как-то кодируют информацию о том, что на этих картинках, да? Можно ли так сформулировать?
Дмитрий Ветров: *вздыхает*
Даниил Скоринкин: Потому что они же действительно, как я понимаю, что эти параметры не очень человеко-интерпретируемы?
Дмитрий Ветров: Они абсолютно человеко- не интерпретируемые.
Даниил Скоринкин: То есть, мы не можем сейчас какой-то пример придумать хороший. Но мы должны сказать, что эти параметры, это извлеченные из фотографий, на которые мы смотрим, какие-то биты информации.
Дмитрий Ветров: Наверное, так можно сказать, да, что мы извлекаем некоторым образом информацию и сохраняем ее в этих оцениваемых параметрах. Но если оцениваемых параметров больше, чем объем наблюдаемых данных, то методы классической статистики, они не то что бы не применимы, они теоретически не обоснованы, то есть, на них не распространяются теоретические гарантии, из-за чего мы на практике часто наблюдаем эффекты, то, что в машинном обучении называют переобучением. Это как раз прямое следствие того, что мы применяем классические методы в ситуациях, где они теоретически не обоснованы. Так вот, байесовский подход как раз обобщает классическую статистику на ситуацию, когда у нас объем данных сопоставим либо меньше, чем количество оцениваемых параметров. и это собственно все современные нейросетевые модели, они как раз, как говорят, перепараметризованы, или overpаrametrized, то есть параметров у них больше, чем объем данных, по которым они обучаются…
Даниил Скоринкин Как же они тогда работают? Они же работают хорошо.
Дмитрий Ветров Они работают хорошо, ну давайте я такую еще аналогию проведу, которую на лекциях всегда привожу. Предположим, у вас простейшая статистическая модель обработки данных: есть монетка, которую можно подбрасывать, а ваша задача — оценить вероятность выпадения орла у монетки. Вот вы монетку подбросили, допустим, тысячу раз, и у вас восемьсот орлов выпало. Что вам интуиция подсказывает такая вероятность выпадения орла?
Даниил Скоринкин 0,8.
Дмитрий Ветров 0,8, разумно.
Даниил Скоринкин Мне подсказывает, что это какая-то гнутая монетка, честно говоря: тысячу раз кинули, и там восемьсот орлов.
Дмитрий Ветров: Правильно, гнутая монетка, именно поэтому вероятность выпадения орла 0,8, а не 0,5. А теперь представим себе, что монетку подбросили два раза, и у нас два раза выпали орлы. Следуя вашей логике, следует сказать, что вероятность выпадения орла — единица, это ровно то, что диктует классическая статистика, так называемый, метод максимального правдоподобия. При этом интуиция подсказывает, что наверное, преждевременно говорить о том, что у монетки с двух сторон орлы, что вероятность выпадения орла единица. Это вот как раз пример ситуации, когда мы применили статистические методы в ситуации, когд объем наблюдений, в данном случае количество подбрасываний монетки не был сильно больше числа настраиваемых параметров, собственно параметр один — выпадение орла. Если бы монетку подбросили 1000 раз, и была бы 1000 орлов, мы бы уверенно сказали, что монетка бракованная, у нее вероятность выпадения орла — единица. Если монетку два раза подбросили, так сказать нельзя. Точнее, сказать можно, но кажется, что это даже противоречит здравому смыслу так поступать. То есть, вот простая аналогия, где мы применили классические статистические методы в ситуации, где они теоретически не обоснованы. Так вот, в современных задачах машинного обучения по большому объему данных, мы применяем очень большие модели, очень большие нейросети, и поэтому мы выходим за рамки применения классического статистического метода. И вот здесь как раз байесовский подход может быть использован, и собственно это одна из перспективных областей машинного обучения. Мне кажется, еще такая аналогия… мне она, во всяком случае, нравится. Если мы рассмотрим классическую статистику как классическую физику, то байесовские методы — это такая своеобразная квантовая механика в области машинного обучения и в области матстатистики. То есть, это во-первых обобщение классических методов на более интересные случаи. И байесовские методы в пределе, то есть, если мы их будем применять в ситуации, когда у нас объем данных больше, чем количество оцененных параметров, они переходят в более классический метод, то есть, противоречий никаких нет. И в-третьих, при biasовском подходе возникают интересные конструкции, которые прямую аналогию имеют с квантовой механикой. Например, байесовские нейросети можно рассматривать как такую квантовую систему, которая в суперпозиции находится. Она одновременно во многих состояниях находится. И корректное применениебайесовской нейросети нужно по всем этим состояниям ансамблировать. Самое смешное, что это реально помогает. Это реально помогает количество поднять в отличии от других нейросетей.
Современное состояние ИИ; машинлернинг как недонаука, сравнение с квантовой физикой
07:45 Даниил Скоринкин: У нас подкаст про некоторое осмысление термина “искусственный интеллект”, я уже про это говорил немножко. Как вы видите современное состояние этой инженерной области, которая называется “искусственный интеллект”.
Дмитрий Ветров: В мрачноватых цветах я вижу состояние этой области. Есть вероятность, что эта область превратится в уже упомянутую квантовую механику в плохом смысле этого слова. Квантовая механика, с моей точки зрения, настоящей наукой так не стала. Это чуть-чуть недонаука. Во многом потому что в какой-то момент специалисты по квантовой механике сказали: “Ой, вот тут какие-то логические противоречия. Ой, да ну их”. Уравнение шредингера работает — хорошо. Даже лозунг был “Заткнись и считай” печально знаменитый. Нет, серьезно. Этот лозунг приписывают нобелевскому лауреату Ричарду Фейнману. Когда кто-то к нему пришел и “Мистер Фейнман, а вам не кажется, что тут вот какие-то логические противоречия, парадоксальные эффекты наблюдаются”. “Не думай об этом, заткнись и считай”. Тебе нужно что-то рассчитать в квантовой системе, уравнения есть, они какие-то расчеты сделать позволяют. То есть, фактически, специалисты в квантовой механике сознательно отказались от того, чтобы задумываться о некоторых эффектах, которые приводят к вполне конкретным парадоксам. Вроде того, что будущее начинает влиять на прошлое. Кажется, что абсурдно. Но с другой стороны, если немножечко подумать выясняется, что такое даже можно себе представить гипотетически. Важно, что они часть вопросов замели под ковер
Анатолий Старостин: Я могу добавить только, я очень хорошо помню момент, когда нам читали квантовую физику. И я в какой-то момент сломался, я стал ходить на эти лекции. Помню, это еще было в другом здании, и и я в какой-то момент просто понял, что я не могу воспринимать материал, когда у меня нет интуиции. Я как-то ее сдал, как-то это все проехало, но оно не улеглось тогда у меня в голове. Но потом я много раз слышал, что так и должно быть. Что там интуиция не работает.
Даниил Скоринкин: Вопрос в том, тут наука не работает или голова наша не работает, чтобы все воспринимать.
Анатолий Старостин: Голова по-другому устроена, поэтому вот заткнись и считай. Логика перестает работать.
Дмитрий Ветров: Нет, нет, коллеги, погодите. Если интуиция не работает, то она полностью формирует другую интуицию, как уже неоднократно в разных науках такое случалось, это нормально, что нам где-то интуиция начинает отказывать. Но это не повод лапки кверху поднимать, и тем более не повод говорить: “Так, это мы просто рассматривать не будем. Сделаем вид, что проблемы нет”. Так вот, возвращаясь к глубинному обучению. Мне кажется, у нас сейчас ситуация такая с нейросетями… то есть, мы в нейросетях наблюдаем кучу удивительных эффектов, загадочных эффектов, непонятных, контринтуитивных. Но основная масс специалистов говорит: “А, не важно”. Главное, что работают, задачи решить можно. Мне кажется, это плохой путь.
Анатолий Старостин: Но это же, причина этого, я думаю, еще в том, что все очень сильно замешалось в индустрию и в коммерцию и все остальное. Везде заработали эти отделы машин-лернеров, которые сидят и дают результаты. Им уже нельзя останавливаться. Они не могут сказать: “Слушайте, все, погодите. Мы сейчас немножко в теорию погрузимся, заморозим проект на полгода, а потом разморозим”. И им приходится все время выдавать результат. Уже очень много денег вложили в область
Дмитрий Ветров: Да, но получается странная ситуация. Пока эти научные группы работали в университете, они могли себе позволить заниматься фундаментальными исследованиями. Потом, как только их какая-нибудь корпорация прямо всем коллективом взяла и перекупила, а эти ситуации сплошь и рядом, не понаслышке знаю. Получилось, что все, нам теперь надо прикладные задачи решать и некогда о фундаментальных категориях думать. Вопрос: тогда все? у нас на этом прогресс остановится? Будем только вот текущими инструментами решать прикладные задачи?
Даниил Скоринкин: Очень понятные опасения, мне кажется. С другой стороны, есть такое мнения, я слышал, и на самом деле его высказал один из гостей нашего подкаста, что не то чтобы мы закрываем глаза на все эти сложности и противоречия, а просто мы находимся в таком феноменологическом этапе развития науки. Как братья Райт увидели, что что-то летит, но еще не теоретизировали это.
Дмитрий Ветров: Во-первых, я полностью согласен. У меня даже слайд есть в одной из презентаций, где я говорю, что современное машинное обучение, глубинное обучение находится примерно на уровне естественных наук века 18. То есть, когда никаких теорий не было, а вот были загадки природы. Значит их нужно было во-первых намерить, то есть, их просто обнаружить, констатировать факты. Потом задуматься, но в итоге, применяя научный метод или дизайн эксперимента, почти все загадки того века удалось понять. У нас сейчас похожая ситуация. То есть, у нас тоже масса загадок природы, если под природой имеются в данном случае нейронные сети. Но вопрос в том, будем ли мы задумываться, будем ли мы пытаться дать им объяснение? Вот ученые 18 века, естественно, испытатели, они задумались. В итоге мы получили, собственном, классическую науку, плоды которой успешно пожинаем. Уже все низковисящие собрали, но приходится повыше забираться. А вот что будем с глубинным учением, я не знаю.
GPT-3, мультидоменность и «сильный» ИИ
12:29 Анатолий Старостин: В этом смысле интересно услышать ваше мнение об упоминавшемся сегодня GPT-3. Вам кажется эта работа важной, прорывной? Или на самом деле раздутой и не такой уж значимой?
Дмитрий Ветров: Ну посмотрим по последствиям. Мне кажется важной. Насколько она на самом деле окажется прорывной узнаем через несколько лет. Но пока кажется, что это один из самых ярких успехов глубинного обучения за последние пару лет, прорыв в области NLP
Анатолий Старостин: Не то что просто вычислительные, а ну так много параметров взяли и вот оно получилось. Компьютеры мощные…
Дмитрий Ветров: Параметров можно по-разному много взять. То есть, тут тоже важно, там же не просто какие-то параметры взяли, там же архитектурное решение найдено. В этом смысле кажется, что все архитектурные прорывы оказываются довольно-таки плодотворными. Как допустим Resnet придумали, тоже был архитектурный прорыв, там не то что сильно больше параметров стало. Просто параметры по-другому играли в вычислении. Построили, и мы до сих пор активно эту конструкцию используем. Сначала это было просто эвристика.
информационная вставка
ResNet или Residual Network (дословно — «остаточная сеть»). Это специальная архитектура сверточной нейронной сети.
При обучении сверточных нейронных сетей часто возникает проблема: с увеличением глубины сети точность предсказаний сначала увеличивается, а затем быстро ухудшается. Это связано со сложностями оптимизации.
Используя ResNet, можно решить эту проблему благодаря увеличению глубины сети при помощи skip connections (пропуск слоев). Затем сеть постепенно восстанавливает пропущенные слои в процессе обучения
То есть, я помню первый доклад, когда Кайминг Хэ (Kaiming He) делал на конференции по компьютерному зрению. Значит, показывают на слайде эту схему, вот тут у нас skip connections добавили и благодаря этому побили state of the art на классификации изображений. И мы вот: “Так, господин Хэ, а почему вы skip connection через два блока перебрасывали а не через один?” Не важно сейчас, что это. В общем, задаем этот вопрос. А он отвечает: “Да, не знаю. Ну, мы через один пробовали, но не получилось, а вот через два заработало”. Все, точка. Ну что это такое? То есть, я понимаю все, это блестящий инженер, хорошая интуиция. Он как бы проинтуичил и догадался как надо пробросить, но ты даже не задумываешься вопросом “а почему это заработало?”. Почему эти skip connections стали так важны.
информационная вставка
Skip Connections — способ обучения нейронных сетей, при котором связь между слоями происходит не последовательно, а с “прыжком” через один (или несколько). Такой подход эффективно ускоряет обучение сети (устраняя проблему исчезающего градиента)Подобный подход наблюдается и в биологических нейронных сетях, например, похожим образом работают нейроны слоя мультиморфных клеток коры больших полушарий мозга млекопитающих
https://habr.com/ru/company/wunderfund/blog/317930/
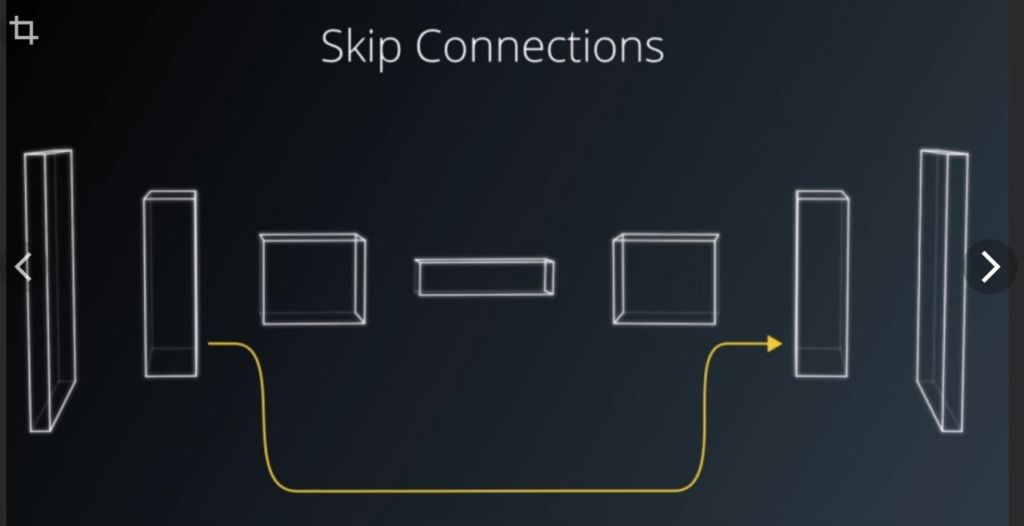
Анатолий Старостин: А кто-нибудь с тех пор уже задумался?
Дмитрий Ветров: Да.Сейчас мы понимаем. То есть, прошло несколько лет. Подключились люди, которые, условно, ученые, а не инженеры. И в итоге удалось понять почему. Благодаря skip connections сильно улучшается рельеф функции потерь и оптимизатору гораздо проще находить глобальный минимум. Но это же нужно понимать, и понимать, к чему это понимание может привести. Ага, значит, дело в рельефе функции потерь, а может надо еще добавить какую-нибудь модификацию архитектуры так, чтобы еще облегчить задачу. Мы теперь понимаем, где искать. То есть, мы не как эти одноглазые циклопы с выколотым глазом на ощупь что-то пытаются определить, а мы уже примерно понимаем, что важно, и в какую сторону надо копать.
Даниил Скоринкин: Все-таки кажется, что GPT-3 не сможет, несмотря на очевидно повысившуюся способность к обобщениям и вообще в какому-то переходу от одной задачи к другой, но все равно остался в каком-то едином домене естественного языка. Хочется какой-то мультимодальность, когда модель, которая научилась у нас отличать котиков от собачек, она может быть поможет нам с другими задачами компьютерного зрения, типо там отличать грузовики от мотоциклов, но она нам не поможет никак с машинным переводом или сортировкой документов у нас во входящих. И кажется, что GPT-3 никакого прорыва в эту сторону не совершила
Дмитрий Ветров: Это и не страшно, то есть, пусть в домене NLP, но в домене NLP с помощью трансформера, с помощью GPT-3 архитектур, там же много подобных задач можно разных решить.
Даниил Скоринкин: Но я к тому, что как бы для некоторых задач было бы очень здорово облегчить вот этот переход между разными типами данных, разными типами объектов.Если мы вернемся к этому пошлому сравнению человеческого и искусственного интеллекта, то все-таки мы, люди, очень хорошо как-то умеем перестраиваться с картинок на тексты, мы можем на картинке увидеть текст и тут же его считать можем легко комбинировать эти вещи. Письмо, в которое вложено несколько изображений, для нас не составляет какого-то когнитивного усилия. И кажется немного грустным, что современные системы, которые решают какие-то интеллектуальные задачи, для кажется очень высоких вот этот барьер между разными типами данных, между разными типами информации.
Дмитрий Ветров: Смотрите, я бы на самом деле не сильно по этому поводу переживал. Да, существующие системы, будем так банально этот термин использовать, искусственного интеллекта, правильнее все-таки сказать машинного обучения, они все узкоспециализированны, но это не минус, это скорее плюс. Мы хорошо знаем из практики, из всей истории человечества, что самые эффективные средства для решения задач — это узкоспециализированные. То есть, средства общего назначения как правило менее эффективны. Ну, условно говоря, берем отвертку, обычную, не крестовую. Я ей в принципе могу закручивать и крестовые болтики и что-нибудь еще, можно даже как стамеску использовать, много чего можно делать. Но не очень эффективно, гораздо эффективнее взять отвертку крестовую или шестигранную, быстрее будет все закручивать. Сейчас мы пытаемся применять технологии искусственного интеллекта для решения конкретных узких задач, поэтому и методы использования и инструменты соответствующие для решения таких задач. Условно говоря, корпораций нужно котиков от собачек отличать, или спам фильтровать, то есть, конкретные задачи, ей не нужно вот все сразу. Кажется, что вот универсальные модели обучения, которые как бы cross-доменные, способные одновременно работать в разных доменах, способные дообучаться на новые задачи, не забывая при этом как решать старые задачи. Это вот, как мне кажется, и будет признаком, ну, одним из признаков сильного искусственного интеллекта.
Когда можно доверить ИИ судьбоносные решения
18:29 Даниил Скоринкин: Мы когда готовились к разговору с вами, мы нашли ваши интервью, сделанные, по-моему в 2017 году, и там вы говорили, что люди никогда не доверят искусственному интеллекту некоторые стратегические решения. Изменилось ли ваше мнение сегодня на эту тему, может быть, не знаю, GPT-10 уже будет не так плоха в этом.
Дмитрий Ветров: Я боюсь даже если будет GPT-20, ситуация не изменится, тут дело не в технологиях, дело скорее в особенностях человеческой психики. У человека должна быть как минимум иллюзия того, что он самостоятельно принимает решения. если мы говорим особенно о принятии решений в каких-то сложных областях — жизни людей зависят или инвестиции миллиардные… я даже позволю себе некую аналогию, мне очень нравится: когда NASA начали использовать первые корабли многоразового использования, то первые корабли Space-шаттлы посадку совершали полностью на автопилоте (это кстати довольно забавно, они садятся сейчас с выключенными двигателями, примерно с грацией топора), значит, компьютеры управляли кораблями, соответственно, шаттл полностью самостоятельно садился. Так вот, потом начались жалобы от экипажей, которые испытывали сильнейший психологический дискомфорт, именно оттого, что компьютер за них делает все, нет даже иллюзии того, что где-то человек участвует. И в итоге, ради психологического комфорта экипажа, командиру корабля доверили в ходе посадки нажать на одну красную кнопочку, когда загорится лампочка. Компьютер зажигает лампочку, нужно нажать на кнопку — это выпуск шасси — после чего жалобы прекратились, чувство психологического комфорта было восстановлено. Мне кажется, здесь похожая ситуация, то есть единственное место, где потенциально мы можем полностью доверить решение искусственному интеллекту, не важно, слабому, сильному, это ситуация, где счет идет на секунды или на доли секунды. Человек может просто не успевать среагировать. Во всех остальных ситуациях, мое глубокое убеждение, что решение будет принимать человек, мы никогда компьютеру не доверим.
Даниил Скоринкин: Может, какие-то примеры таких ситуаций, где счет идет на секунды, где есть какие-то перспективы для такого полного автономного принятия решений
Дмитрий Ветров: Например, само пилотируемые автомобили или автопилоты в самолетах, то есть, там сейчас такая ситуация возможна. Хуже, если будет такая ситуация, например, какие-нибудь военные беспилотники, которые будут отслеживать лиц, представляющих угрозу, и там может тоже счет идти на секунды, и вот будет неприятно, если тут будет у компьютера право самостоятельно применять оружие, принимать решение об уничтожении того или иного человека. Но, надеюсь, до этого не дойдет, но, потенциально, такая область есть. То есть, опять, если счет будет идти на минуты, решать будет человек, компьютер будет только рекомендовать
Смена технологической парадигмы в разработке ИИ
20:57 Анатолий Старостин: Я позволяю себе в этом подкасте тоже быть немножко философом про будущее, и в этом смысле мне бы очень хотелось смену парадигмы, как я сейчас это вижу: есть несколько понятных типов задач, которые мы решаем. Мы решаем задачи классификации в огромном количестве, регрессии разные, у нас есть отдельный кустик — это обучение с подкреплением, у нас даже рядом лежат эти генетические алгоритмы, про которые иногда вспоминают, они вообще особенные, и, ну, в общем-то не так много самих типов постановок задач. Не кажется ли, что для того, чтобы двигались дальше, мы как бы должны выйти за рамки тех постановок, который есть сейчас, и поставить себе задачу как-то по-новому. Хочется поговорить про постановку задачи, условно говоря, для сильного искусственного интеллекта.
Дмитрий Ветров: Я бы так сказал. Во вы говорите, что набор задач сейчас ограничен сильно. Мне кажется, что у нас ограничен в первую очередь не набор задач. Мы ограничены в первую очередь инструментами. Кажется, что первое, что нужно сделать, это если мы хотим двигаться в сторону, ну, обучения первых моделей сильного искусственного интеллекта — это построить такие технологии, которые способны обучаться на новую задачу, не теряя при этом старые. То есть, способны к накоплению постоянному. И тогда они будут способны, действительно, работать в разных доменах. Проблема в том, что сейчас вот нет таких технологий. То есть сейчас, каждый раз когда мы обучаем на новую задачу, мы старую забываем.
Стоит ли помнить про онтологии и возможны ли гибриды нейросетей и символьного ИИ
22:28 Анатолий Старостин: Продолжаем разговаривать про общий искусственный интеллект и про будущее, но говоря про будущее иногда хочется вспомнить прошлое и есть целый пласт методов, которыми люди очень много увлекались во второй половине XX века различная онтологическая инженерия, экспертные системы, вообще вот это всё, что ты об этом думаешь? Нужно ли про это помнить? Заниматься этим или забыть как страшный сон?
Дмитрий Ветров: То, что я слышал, когда был на следующих конференциях, скажу честно, производило удручающее впечатление, поэтому я бы тут скорее скептически оценил перспективность этого подхода. В целом мне кажется, это очень хороший пример того, что не нужно пытаться обогнать время и пытаться заниматься развитием технологии искусственного интеллекта пока собственно инструментарий не подоспел. Вот это была попытка так вот время обогнать. В итоге всё, что было создано в рамках онтологического подхода, в рамках классической школы искусственного интеллекта, кажется сейчас нигде не используются в промышленных системах для решения конкретных задач, где мы технологии искусство интеллекта применяем.
Анатолий Старостин: Ну это правда. Но при этом я могу сказать, вот сегодня утром за завтраком читаю я пост на Хабре, где Михаил Бурцев рассказывает нам о будущем искусственного интеллекта, и он там довольно четко артикулирует вот какую мысль: он говорит, что в последнее время очень много развиваются разные методы для анализа вот этих “knowledge graphs” разных и он верит гибридизацию в то, что мы можем взять например тоже самое GPT-3 и как-то так его классно научить, что она будет учиться одновременно вместе вот этим knowledge-графом и его как-то вовлекать, и за счёт этого получить буст качества. Мы в такое верим или нет?
Дмитрий Ветров: Скажем так, мы такое не исключаем, то есть вполне возможно что-то действительно придет к успеху. На вопрос “а что мы собственно взяли из старой школы искусств интеллекта?” — понятия knowledge-графа?
Анатолий Старостин: Ну в этом месте наверное действительно мало взяли, согласен.
Дмитрий Ветров: То есть на самом деле как раз использование современных технологий, а вот не тех, которые были разработаны там 60-х годов по нулевые годы то, что называется классический, там классическая школа по искусственному интеллекту. То есть я в этой месте скепсис выражал то, что… Ну хорошо, то есть в knowledge graph можно поверить, можно поверить, что даже компьютер будет в состоянии построить, но методами глубину обучения, а не классическими методами. То есть какие-то концепции, которые у них были типа… условно тот же knowledge graph — это, как я понимаю, как раз вещь, которая придумана была в рамках классической школы искусственного интеллекта.
Анатолий Старостин: Именно, так ну некие фреймовые сети такие вот, в которых есть объекты, у этих объектов есть какие-то свойства, общем это представление информации в виде графов.
Дмитрий Ветров: Ну то есть вот концепцию скорее всего оттуда можно будет заимствовать, но кажется что концепция она в общем на поверхности лежит, а вот никакие там методы построения этого knowledge graphа, который раньше развивались, мы скорее всего использовать не будем будем, то есть будем вот средствами глубинного обучения их строить.
Интерпретируемость
25:19 Анатолий Старостин: У меня все примеры из жизни, то я на рыбалку хожу, то ещё куда-то на разных подкастах, но сегодня утром я играл в баскетбол, и я много в этом смысле разговаривал со спортсменами про конкретные ситуации, и я могу сказать, что очень на самом деле игра распадается на кучу конкретных ситуаций. Тебе говорят, что вот в такого рода ситуации забегай туда, или там открывайся на пас или ещё чего-то. То есть на самом деле в момент общения между тренером и спортсменом, между спортсменами и так далее, как раз происходит вполне себе описание этих ситуаций ,как раз на естественном языке, уже упоминавшимся, и получается что всё это спортивное действо оно как бы интерпретируемо. То есть понятно, что дальше в реальной игре ты всё равно не сделаешь, так как тебе сказали ещё чего-то, но хотя бы у людей появляется возможность это всё обсуждать и интерпретировать, а вот с нейронными моделями, вот в этом ещё сложность. Как мы вообще будем с ними разговаривать? Почему ты делаешь это? Вот почему ты сейчас пошел направо, а не налево? Он должен уметь ответить, а я в ситуации такой-то, в такой ситуации обычно ходят направо.
Дмитрий Ветров: Не, смотри это уже другое, ты сейчас уже говоришь о проблеме интерпретируемости.
Анатолий Старостин: Да, я хочу о ней поговорить, я начал на неё нас выводить.
Дмитрий Ветров: Проблема интерпретируемости, то есть исторически там все последние годы, когда глубинная революция началась в общем никого особо сильно не колыхало, типа работает отлично — “shut up and calculate”. Сейчас по мере того, как технологии начинает проникать во все более широкие сферы народного хозяйства, возникает ряд критических областей, где нам нужны просто компьютер рекомендации выдавал, а ещё и ну как мы понимали на основании чего.
Даниил Скоринкин: Пояснил за свои слова.
Дмитрий Ветров: Да, да. Но, как я сказал, в принципе даже уже примерно понятно как это делать, выборок нет обучающих. Будут обучающие выборки, то есть обучающая выборка…. Условно говоря, мы можем научить компьютер только тому для чего у нас есть обучающей информации, ну с небольшим исключением в виде модели с латентными переменными, которые могут чуть больше выучить, но тоже не сильно больше. Если у нас обучающая выборка — набор картинок с метками классов, вот мы можем выучить классификатор изображений, он будет работать по принципу черного ящика, если у нас есть набор картинок с метками класс и описанием, почему здесь разметчик поставил ту или иную метку, мы можем выучить нейронную сеть, которая будет непросто классифицировать картинку, а объяснять почему она приняла то или иное решение. Насколько можно верить этому объяснению вопрос сложный, но мне кажется он уже как бы это не предмет научного обсуждения, это скорее философия, для философов. На самом деле нейросеть из-за этого приняла решение или нет, но как минимум объяснения будет выглядеть ну наверное убедительно, если мы такие модели научимся строить. Как их строить примерно понятно. То есть нет самого главного — соответствующих выборок данных, к сожалению, если они будут, мы сможем сделать наши нейросети интерпретировано.
Пересадка из Яндекс.Такси в Яндекс.Толоку (Разметка данных для ML )
27:58 Анатолий Старостин: Не очень понятно только откуда они возникнут, поэтому как раз интересно про это ещё иногда фантазировать и разговаривать про подходы вообще к данным. Ну понятно что мы сейчас умеем размечать данные толокерами, мекеникалтеркерами и прочими такими, нуу то что дешевой рабочей силой, да вот ну как ещё у нас есть некоторое количество естественных датацентров, большие компании там корпорации имеет чуть больше, даже не чуть, а сильно больше, у них есть пользовательский потоки они могут там отслеживать какие-то реакции пользователей на что-то и всё это анонимизированно куда-то там сохранять и дальше на этом на этом обучаться, но … не знаю вот я, как человек разрабатывавший Алису в своё время, да, я могу сказать что уже даже когда делаешь диалоговые системы при том, что у Яндекса много чего есть, всяких разных возможностей, но сам датасет, в котором не просто вот типа документ отметка, как был в поиске, да, а сессия диалоговая, он уже гораздо сложнее и уже пришлось довольно много сделать, чтобы научиться с такими датасетами работать и уже большая работа была проделана,а это всего лишь датасет, в котором есть вот интеракция между двумя участниками да, могут быть датасеты, в которых интеракция между н-участниками и все…а если эти все эти участники еще и делают какие-то действия да, то… и надо логгировать какие они делали действия в какой момент, то датасеты становятся уже совсем сложными и таких датасетов пока не собирает никто нигде. И уж тем более, если собирают только может быть действительно какие-то корпорации, тратят на это большие деньги, но обычным там так сказать ученым из Академической среды эти датасеты точно недоступны, вот вопрос: как мы с этим этим будем жить?
Дмитрий Ветров: Ну так вот первое, что в голову приходит, по мере того как раз будут технологии искусственного интеллекта вытеснять из ряда областей, на рынке труда будет образовываться избыточная рабочая сила, у которой не будет работы. Вот.
Даниил Скоринкин: Вот они и будут делать для нас датасеты?
Дмитрий Ветров: Как бы это не звучало, ну а что? Условно говоря у нас идет трансформация экономики народного хозяйства во всех странах, как бы нашу страну тоже не минует, ряд людей лишится работы, ну условно говоря сейчас вот Сбербанк допустим сильно сокращается колл-центр, там много людей сидит, самопилотируемые автомобили, в том числе Яндекса, приведут к тому, что резко сократит рынок водителей такси и дальнобойщиков.
Дмитрий Ветров: Куда их девать? А с другой стороны у нас параллельно возникает потребность в новых датацентрах всё более и более сложных, которые требуют все большего труда для разметки.
Анатолий Старостин: Из Яндекс Такси человек просто пересаживается в Яндекс Толоку и начинает давить на кнопки вместо того, чтобы давить на педали.
Дмитрий Ветров: Ну условно говоря да.
Даниил Скоринкин: Страшно.
Дмитрий Ветров: Что может нас привести к тому, что появятся гораздо большие датасеты, которые в свою очередь подстегнут прогресс в области новых методов искусственного интеллекта и мы сможем новые задачи решить в том числе сделаем наши любимые нейросети более интерпретируемыми.
Анатолий Старостин: Ты согласен то, что мы просто всех значит заставим всех водителей Яндекс Еды, Яндекс Доставки просто размечать нам данные, тогда все будет нормально.
Дмитрий Ветров: Если что, это скотская работа вообще, ну можно сказать, что и работа водителя так себе, неприятная, ну к тому что…
Даниил Скоринкин: Никто не спорит, это тяжелая работа, тяжело размечать это всё и она монотонная, и и не очень высокооплачиваемая, к сожалению.
Антропоморфность
31:05 Анатолий Старостин: Должен ли искусственный интеллект быть антропоморфным? То есть вот это сравнение самолетов и птиц классическое, как в своё время значит летающие аппараты изобрели совершенно не базируясь на интуицию взятые из природы, а совершенно по-другому.
Как мы будем с искусственным интеллектом действовать? Мы должны прямо свято как-то копировать человека или у нас будут другие пути?
Дмитрий Ветров:Тут давай всё-таки ты пояснишь, что значит антропоморфный, потому что в моем понимании антропоморфный это значит: две руки, две ноги и туловище. Ты видимо что-то другое имеешь в виду.
Анатолий Старостин: Я имею в виду, что должны ли мы… и мы говорим именно про моделирование самого интеллекта, самого сознания чего-то такого. Должны ли мы глубоко разбираться разбираться в том как работает человеческое сознание и пытаться делать всё по аналогии или мы можем воспринимать это как некий блэкбокс и повторять само интеллектуальное поведение любыми методами какие у нас есть? Есть же некая такая аналогия между искусственным, нейронным и естественным. Она такая очень натянутая на самом деле у одного много входов и у другого много входов, и как бы один выход, но всё остальное разное. Да, вот, но всё равно как бы считается, что вот некая аналогия в этом месте есть, и кажется, что даже у методов распознавания изображений есть какая-то такая вот слоистость примерно похожая на то слоистость есть у нас в глазах. Ну и то это всё очень спекулятивно, да. Ну вопрос понятен.
Дмитрий Ветров: Вопрос понятен. Я тут, позвольте аналогию с эволюционной биологией привести, мне очень нравится она. Значит у животных на нашей планете трижды независимо развивалась способность летать. Когда, например, начинали летать насекомые они не смотрели как летают птицы, не изучали у них опыт, они как-то вот сами развелись, но при этом независимые линии развития вели к одному и тому же механизму: крылышки, которые вот машешь, с подъемной силы создаешь. Мне кажется, здесь то же самое, я совершенно не вижу никаких… никакой необходимости разбираться в том как функционирует физический интеллект и тем более человеческое сознание, еще более сложная штука для того чтобы нам разработать сильный искусственный интеллект. Я уверен, что мы сможем разработать даже не понимая механизмы работы мозга. Это, кстати, не означает что не надо изучать, как мозг работает. Надо, безусловно. Просто это отдельная область науки, она нас никак к искусственному интеллекту не приблизит, хотя сам по себе тоже важное и интересное. Но я не удивлюсь, что, когда мы построим сильный искусственный интеллект, и когда мы разберемся, как работает мозг, то окажется, что принцип похожий, но это получится только само собой.
Критерии интеллектуальности
33:33 Анатолий Старостин: Вот мы сегодня довольно как-то легко рассуждали про узкий искусственный интеллект и про широкий. В общем как-то стало сразу понятно, что все присутствующие в этой комнате довольно неплохо понимают, что такое одно и что такое другое. Ну как-то мы видимо, потому что много об этом разговариваем и варимся в этом во всём, но всё-таки кажется, что поскольку сильного искусственный интеллект еще не создано, то всегда встает вопрос: “А как мы поймем, что он появился? Как мы его обнаружим? Как мы его познаем? Какие критерии? Какие тесты? Как отличить сильный искусственный интеллект от не сильного?
Дмитрий Ветров: Я могу привести только отдельные косвенные признаки, скорее всего четкой никакой граница не будет между слабым и сильным искусственным интеллектом, он просто будет потихонечку слабый, искусственный интеллект постепенно трансформироваться все сильнее сильнее и сильнее и в какой-то момент мы неожиданно для себя обнаружим: “О, так вроде уже ко всем критериям, которые когда-либо кто-либо предъявлял к сильному искусственному интеллекту, вроде он им обладает. Я не буду говорить банальности типа теста Тьюринга, хотя мне кажется в принципе довольно здравое наблюдение. Я бы не говорил, что это прям критерий, если тест Тьюринга пройден, то это сильный искусственный интеллект, но как некая, как некая важная составляющая. Вторым признаком, с моей точки зрения, будет являться универсальность в смысле решение когнитивных задач. То есть мы как минимум можем текущую некую фиксированную модель, которая умеет решать ряд задач до обучения, чтобы она решила ещё новые задачи, не забыв при этом старые. Вот есть такая универсальность у нас будет причём может быть еще… а третий это по-видимому — тот факт, что для обучения новой задачи модели будет требуется все меньше данных, потому что она будет учитывать опыт решения прошлых задач.
Анатолий Старостин: А вот является ли требованием обязательным, что в момент до обучения мы как бы его должны не выключать, что он должен быть как бы онлайн или это неважно? Ну в смысле, что это всё-таки должен быть уже полноценно функционирующий агент, который вот, условно говорим, мы с ним поговорили говорили, что-то ему объяснили, показали и и он пошёл дальше вот эту новую задачу решать. Или всё-таки можно его выключить? На паузу поставить, поковыряться в мозгах и включить обратно.
Даниил Скоринкин: Ты на ночь тоже отключаешься, у тебя что-то там происходит.
Дмитрий Ветров: Тебя не смущает, что ты восемь часов в сутки в выключенным состоянии находишьсь? А потом включаешься и ничего, нормально.
Даниил Скоринкин: И без этого ты обучаться кстати не сможешь, это понятно. То есть там закрепляется куча всего.
Анатолий Старостин: То есть вы думаете, что ко мне во сне приходит человек и подкручивает мои нейронные сети?
Даниил Скоринкин: Нет, она там сама себя подкручивает, но то, что она себя подкручивает,
Анатолий Старостин: Угу, понятно.
Дмитрий Ветров: Кстати, скорее всего такая стадия будет. То есть то, что биологи называют консолидация памяти, то есть то, что происходит как раз во сне, а потому что первые признаки этого мы наблюдаем уже в современных нейросетях. То есть там тоже происходит некий процесс, когда нейросеть уже настроилась на обучающую выборку, уже там ошибка нулевая, если мы нейросеть дальше продолжаем обучать, у нее нулевая ошибка остается, казалось бы че? Ничего уже не меняется она на месте стоит. Нет, не стоит на месте, а вместе с ней происходят некие очень интересные процессы, о которых мы понимают мало, мы по косвенным признакам только судим.
Анатолий Старостин: Какая-то стабилизация?
Дмитрий Ветров: Да. Ну, собственно мы это назвали это с нашей группой — консолидация. Так и назвали по аналогии. Что вот фаза нумеризации, когда мы просто запомнили объект обучающей выборки, мы переходим к фазе консолидации, когда мы эту же обучающую выборку пытаемся с меньшим количеством закономерностей объяснить, то есть упрощаем то, что мы выучили. И это прямо по косвенным признакам можно численно увидеть. И вот скорее всего, скорее всего…
Анатолий Старостин: Это с обычными нейронными сетями или с байесовскими?
Дмитрий Ветров: Это с обычными нейронными сетями происходит, с байесовскими видимо то же самое будет происходить, но мы пока с обычными играемся. Скорее всего это позволит объяснить эффект двойного спуска, которой вот был обнаружен два года назад в нейросетях. Они очень странно себя ведут, если мы увеличим ширину, а в этом году обнаружили, что даже в рамках одной нейросети, мы просто очень долго ее обучаем, то там происходят очень странные эффекты с тестовой ошибкой, которая сначала падает, потом начинает расти, а потом снова падает — двойной спуск. И вот по видимому это как раз рост и падение связан с тем, чтобы сначала фазе не врезаться, на обучающей выборке всё хорошо при этом, ошибка уменьшается. Что сначала мы уменьшаем объектов обучающей выборки тупым условно в кавычках запоминанием объектов обучающей выборки и при этом у нас подскакивает ошибка на тесте, а потом мы начинаем всё, что мы выучили как-будто упрощать, консолидировать.
Даниил Скоринкин: Нейросеть сначала вызубрила, а потом как бы осознала.
Анатолий Старостин: Это всякое нейросетевой архитектуре свойственно или для того, чтобы так происходило приходится с нейросетями что-то делать?
Дмитрий Ветров: Текущая гипотеза такая, что это происходит всегда просто можно этот эффект усилить. Чтобы его четко наблюдать мы его умышленно усиливаем. Усиливаем каким образом, мы в обучающую выборку подмешиваем там 15% объектов с изучаемой разметкой.
Анатолий Старостин: А, то есть еще ухудшаете выборку еще специально.
Дмитрий Ветров: Ухудшаем выборку, да. Компьютер же не знает, что там ещё какие-то шумовые объекты. И там этот эффект очень четко виден. И если шумовые объекты не подмешивать, этот эффект скорее всего, гипотеза, накладывается просто на другие, поэтому двойного спуска визуально не видно, но процессы тут скорее всего схожие. Просто поняв, что вызывает двойной спуск, мы уже дальше поймем, что происходит в обычных нейросетях, которых этот двойной спуск замаскирован, мы его не видим. То есть там, если на пальцах объяснять, то по-видимому после того, как мы достигли нулевой ошибки на обучении, дальше у нас начинается процесс такого случайного блуждания в многообразии нулевого троеноса? и мы потихонечку дрейфуем от узких минимумов в широкие. Да, за счет этого как раз тест, обучающая ошибка остается неизменно нулевой, а тестовая ошибка уменьшается. Проблема в том, что вот я то, что я говорю на пальцах, тут все тривиально, мы говорим про процессы происходящие в миллион-мерных пространствах, в миллион-мерных пространствах у человека отказывает всяческая интуиция. То есть мы совершенно не так представляем себе…
Анатолий Старостин: У меня уже и в пятимерном отказывает.
Дмитрий Ветров: Я вот могу простейший пример привести, чтобы просто трагизм ситуации понимали. Предположим, я на полянке, а вы по мне из пушки стреляете прицельно, но пушка как-то промахивается по Гаусу промахи, мода — наиболее вероятная точка — это собственно мое местонахождение, и дальше , плотность как бы снарядов падает. В двухмерном пространстве всё понятно, если вы по мне стреляете, допустим у пушки дисперсия, ну корня из дисперсии здесь нет, стандарт отклонения. Ну там где-то поближе ко мне снаряды будут чаще, подальше от меня будут реже, колоколообразная плотность. А теперь представим тоже самое только не двухмерное пространство, а скажем тысячимерное пространство. Ну, я понимаю, сложно представить, тут абстрактно. В тысячемерном пространстве нахожусь я, и вы по мне значит из пушки стреляете всё из той же, те же плюс-минус 10 метров отклонение. Так вот все снаряды всегда будут от меня разрываться на расстоянии 10 метров, не 9, и не 11. Это доказано математически в силу там определенных теорем теории вероятности, и это мы наблюдаем экспериментально. Ну хоть ты тресни. Хотя по-прежнему наиболее вероятная точка, куда попадет снаряд — это я, ну вы в меня целитесь, но все снаряды всегда будут на расстоянии ровно 10 метров от меня рваться. Поэтому если у снаряда боевой радиус поражения 9 метров я вообще могу там сидеть в кресле, газеты читать. А просто по мне будут на одинаковом расстоянии от меня будут снаряды рваться. Это просто как пример того, насколько контринтуитивно процессы происходящие в пространстве большой размерностью. В нейросетях пространства размерности миллион, там ещё меньше интуиции. Именно поэтому мы наблюдаем ряд тех эффектов, которые нам кажутся загадочными и непонятными, и именно поэтому я считаю, что крайне важно понять из-за чего они происходит и в принципе успешно это выяснить.
Анатолий Старостин: Поясню для наших слушателей, что пространства размерности миллион, потому что у сети миллион параметров в миллион весов, которые все надо одновременно обучать.
Блиц
40:45 Анатолий Старостин: Финальная фаза нашего подкаста называется Блиц. Мы просто задаем несколько вопросов, на которые нужно довольно быстро отвечать.
Даниил Скоринкин: Первый вопрос: три хорошие книжки в области машинного обучения обучение искусственного интеллекта.
Дмитрий Ветров: Бишоп, Мерфи и Маккай, название конкретное я могу только текстом сказать, я не запоминаю их.
Анатолий Старостин: Отлично, потом тогда скинешь нам, мы их поместим в комментарий. Несколько выдающихся ученых в области искусственного интеллекта по твоему мнению.
Дмитрий Ветров:Ну опять же я не хочу тут банально повторять какие гениев глубинного обучения, хотя с моей точки вполне заслужили как минимум тем, что они занимались нейросетями, когда весь мир считал, что это там тупиковое направление. Но я бы хотел назвать собственно уже упомянутого в предыдущем ответе Дэвида Маккайя, это британский статистический физик, который с моей точки зрения очень много именно парадигмального привнес в машинное обучение, в частности вот предложил байесовский метод использовать. У него очень интересно книжка доступно… 4 издания выдержала, рекомендую всем интересующимся почитайте там много всего не только про машинное обучение.
Даниил Скоринкин: Какой вот самый может вдохновляющий проект или интеллектуально сложный и интересный проект в области машинного обучения вы знаете?
Дмитрий Ветров: Я думаю то, что связано с экспериментами Дипмаинда по применению методов обучения с подкреплением компьютерных играх. Типа Альфа Го, Старкрафт, вот для этого. Мне кажется, это крайне любопытно. Я бы единственное еще бы добавил к этому разрешил фишечку, разрешил бы агентам обычаем вести между собой переговоры на любом языке, на птичьем, пусть он будет непонятен человеку. Кажется, что это то, что пока современные технологии с обучением с подкреплением почему-то избегают, мультиагентная система, в которых агенты не просто взаимодействуют, они еще коммуницируют, решают обмениваться информацией.
Анатолий Старостин: Мне кажется, мы точно увидим эти работы скоро.
Дмитрий Ветров: Я тоже думаю.
Даниил Скоринкин: Боятся, что сговорятся против экспериментаторов и что-то нехорошее сделают, поймут, что испытывают…
Анатолий Старостин: Хорошо, а если вдруг ты встретишь в будущем сильный искусственный интеллект, что ты ему скажешь?
Дмитрий Ветров: Как долго мы тебя ждали.
Даниил Скоринкин: Какой-нибудь самый эпичный провал в области искусственного интеллекта.
Дмитрий Ветров: Это провалы конечно двух предыдущих попыток нейросеть использовать в машину обучения. То есть провал в 50-60 годов и провал восьмидесятых годов и в девяностых. То есть надежда были, казалось, что клёвая модель должна хорошо учиться, в итоге вот оба раза эпик фейл. И как хорошо, что всё-таки с третьей попытки нам удалось их привнести.
Финал
Анатолий Старостин: Друзья, это был очередной выпуск подкаста Неопознанный Искусственный Интеллект, у нас в гостях был Дмитрий Ветров.
Даниил Скоринкин: Профессор-исследователь факультета компьютерных наук и заведующий центром байесовских методов методов вышки. Дмитрий, спасибо большое за разговор.
Дмитрий Ветров: Спасибо за то, что позвали, очень было интересно.
Даниил Скоринкин: Пока.
Анатолий Старостин: Пока.
Дмитрий Ветров: Счастливо!
Системный Блокъ
Телеграм: t.me/ainewsline
Источник: sysblok.ru