Polars: быстрая альтернатива Pandas для обработки датасетов
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-12-29 14:44

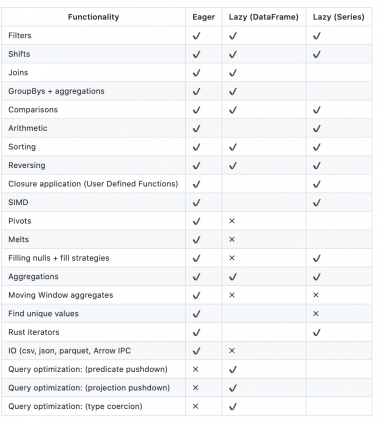
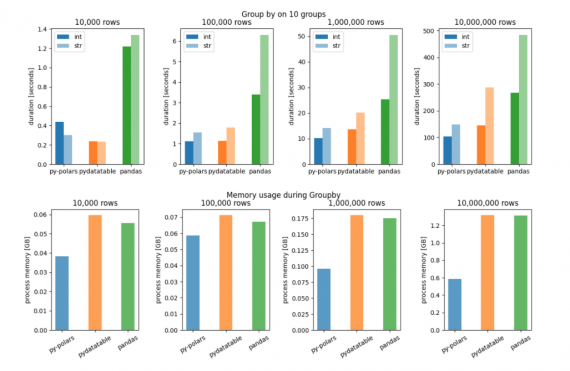
Polars — это открытая библиотека для обработки массивов данных на Python. По скорости работы библиотека обходит самый популярный инструмент для работы с данными, — Pandas. Кроме того, библиотека более эффективно работает с памятью при обработке массивов. Polars написана на Rust.
Подробнее про библиотеку
Цель Polars — стать быстрой библиотекой для работы с табличными данными, которая использует доступные ядра на локальной машине. Библиотека наиболее полезна в случае если данных слишком много для использования pandas и при этом слишком мало для использования spark. Как и spark, Polars состоит из планировщика запросов, которые оптимизирует запрос, чтобы совершать меньше действий и сократить использование памяти. Однако если данные не влезают в память локальной машины, Polars с этим не справится.
Телеграм: t.me/ainewsline
Источник: neurohive.io