Наиболее полный гайд по работе с SQL в Data Science
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-12-08 04:12

SQL правят в стране Корпоративных Данных. До развития NoSQL это был основной язык запросов для извлечения данных из реляционных БД.
Реляционные базы данных представляют собой коллекции двумерных таблиц наподобие Excel или датасетов. В каждой такой таблице есть фиксированное количество столбцов и любое возможное число строк.
В качестве примера рассмотрим производителей автомобилей. У каждого изготовителя будет база данных, которая состоит из множества таблиц (например, по одной для каждой выпущенной модели автомобиля). В каждой из этих таблиц будут храниться всевозможные показатели продаж конкретной модели автомобиля в разных странах.
High Scalability опросили ИТ-лидеров на DeveloperWeek о тенденциях использования баз данных в 2019 году и обнаружили, что SQL по-прежнему используется в более чем 60% времени. Стратегия разнородных баз данных (SQL + NoSQL) применяется в 75% случаев. Это неудивительно. Отличающиеся типы баз данных предназначаются для неодинаковых целей.
Анализ 300 объявлений о вакансии технических компаний за июнь 2019 года показал, что SQL входит в ТОП-3 требуемых навыков в Data Science, уступая место только Pythonу и R.
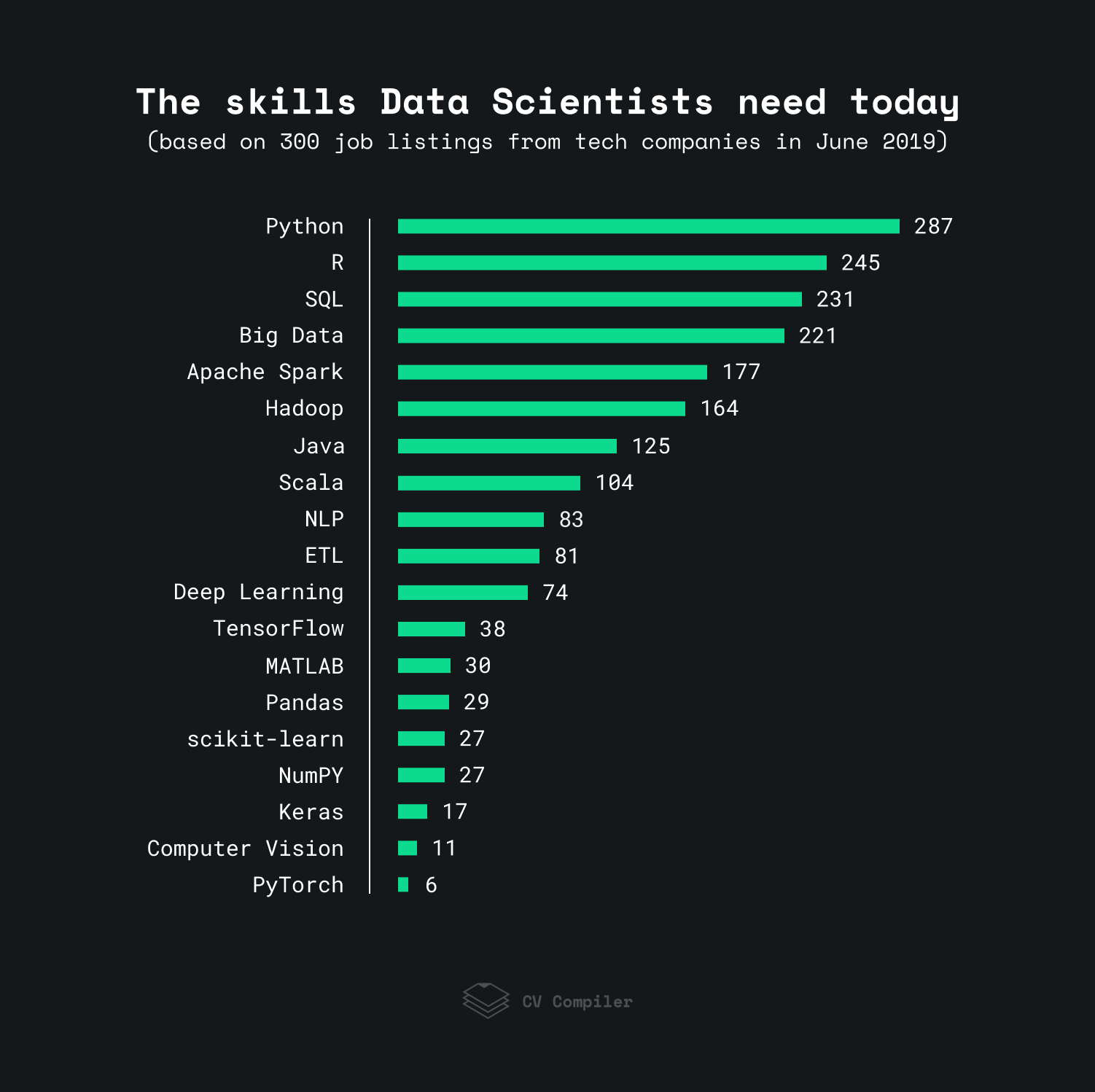
Почему SQL и базы данных так популярны:
- Каждый день появляется 2,5 квинтиллиона байт новой информации. Представьте число с 18 нулями! Чтобы сохранить такое количество, не обойтись без базы данных.
- Вдобавок растёт ценность информации для компаний. Те, кто владеет данными, лучше анализируют и решают бизнес-задачи, прогнозируют тенденции рынка и разбираются в клиентских потребностях.
Главное преимущество использования SQL – ускорение работы благодаря прямому доступу к информации во время операций и отсутствию подготовительного копирования.
Из массы реляционных баз данных – Postgres, SQLite, Oracle, Microsoft SQL Server и MySQL – последняя остаётся самой популярной базой данных для организаций.
Начинающему Data Scientistу, который разобрался в алгоритмах машинного обучения, участвовал в соревнованиях Kaggle и активно манипулировал данными с помощью Pandas, покажется шокирующим собеседование с вопросами по SQL. Но так бывает. В ваших интересах подготовиться.
Немного подробностей
В реальном мире реляционные базы данных интенсивно используются для размещения всех типов корпоративных данных. Информация хранится для лёгкого поиска из всевозможных источников. Знание SQL приводит к простому получению и обработке данных. До появления «шумихи» вокруг Data Science ею занимались статистики в крупных организациях. Data Mining представлял собой пересечение статистики и компьютерных технологий, с которыми работали специалисты. Интеллектуальный анализ данных – процесс, который использует машинное обучение и статистику для обнаружения паттернов в больших наборах данных.
Data Mining избавляет от перемещения или объединения данных перед анализом. Анализ выполняется в массе хранилищ информации на лету.
Для интеллектуального анализа данных в корпоративном программном обеспечении большие наборы данных часто обрабатываются с использованием SAS. Благодаря SAS Data Scientist легко выполняет статистический анализ огромного объёма данных без надобности писать слишком много кода. Встроенные функции в SAS действуют для всех типов анализа данных. SQL легко оборачивается и затем запускается в SAS. Синтаксис команд SAS похож на SQL.
DataMiner от Oracle – другое популярное ПО для интеллектуального анализа баз данных, которое используется в корпоративных технологиях для Data Science. В нём масса алгоритмов анализа данных: классификация, прогнозирование, регрессия, ассоциация, выделение признаков и другие. Все выполняются на больших наборах данных, размещённых в реляционных базах данных.
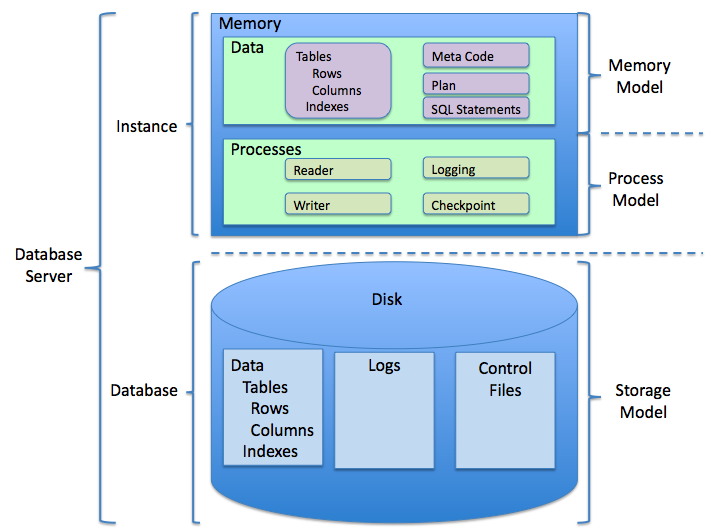
Концепции реляционной базы данных
Прежде чем углубиться в SQL, рассмотрим концепции реляционных систем управления базами данных (РСУБД) для подготовки.
Схема
Схема базы данных относится к организации данных. Это план того, как строится база данных. В РСУБД модель базы данных реализуется с помощью схемы. Это модель «сущность – связь».
Таблица
Основная единица схемы – таблица. В РСУБД таблицы организуются и связываются друг с другом различными типами отношений (один к одному, один ко многим, многие ко многим).
Столбцы
Вертикальные разделы таблиц называются столбцами. В РСУБД столбец часто называют атрибутом.
Строки
Горизонтальные разделы таблиц называются строками. В РСУБД строка часто называется кортежем.
Индексы
В РСУБД индекс представляет собой структуру данных, которая улучшает работу таблицы за счёт быстрого поиска данных. В зависимости от типа индекса, формируя его, вы создаёте копии данных, упорядоченных определённым образом на сервере для облегчения поиска. Иногда вместо копий информация упорядочивается особенным образом по индексу, создающимся для оптимизированного получения.
Различают два основных типа индексов: некластеризованные и кластеризованные.
- Некластеризованный индекс – когда данные хранятся в произвольном порядке, но логический порядок определяется индексом.
- Кластеризованный индекс – когда блок, в котором лежат данные, изменяется в соответствии с определённым порядком индекса.
Операторы SQL
SQL – язык структурированных запросов для баз данных РСУБД. Для извлечения данных вы используете операторы SQL и объединяете таблицы, чтобы выбрать только нужные типы данных для конкретных целей, используя операторы SQL.
Хранимая процедура
Вместо выполнения операторов SQL на лету вы создаёте набор программ, называемых «хранимыми процедурами». И передаёте им аргументы так же, как и функциям.
План запроса
План запроса – упорядоченная последовательность шагов для доступа к данным. План запроса определяется оптимизатором запросов – компонентом внутри базы данных. Операторы SQL и хранимая процедура только формулируют ваши намерения о способе получения данных. План запроса, который определяет оптимизатор запросов, последовательно показывает точные шаги выполнения этих SQL-операторов базой данных. Анализ плана запроса – способ оптимизации и настройки хранимых процедур и операторов SQL.
Ограничения
Ограничения обеспечивают целостность данных в РСУБД. Вы настраиваете ограничения, чтобы лимитировать данные и тип. Ограничения устанавливаются либо на уровне столбца, либо на уровне таблицы. Вот некоторые из них: NOT NULL, UNIQUE, PRIMARY KEY и FOREIGN KEY, CHECK, INDEX.
- Первичный ключ – ограничение, которое однозначно идентифицирует каждую запись в таблице. Как правило, это уникальный идентификатор записи.
- Внешний ключ – ограничение, которое устанавливает родительско-дочерние отношения в таблице. Обычно таблица с внешним ключом – дочерняя, а таблица без внешнего – родительская.
Нормализация
Нормализация – процесс эффективной организации данных в РСУБД. Идея состоит в исключении лишней информации. Например, у вас есть таблица ClientInfo, и у клиента три разных адреса. Для нормализации данных вы сохраняете информацию о клиенте в таблице с именем ClientInfo, которая индексируется по ClientId. Затем сохраняете три разных адреса в таблице ClientAddress с ClientId. После этого вы связываете две таблицы по ClientId. Гарантируя «уникальные» данные в каждой таблице, вы сэкономите место на диске и оптимизируете производительность.
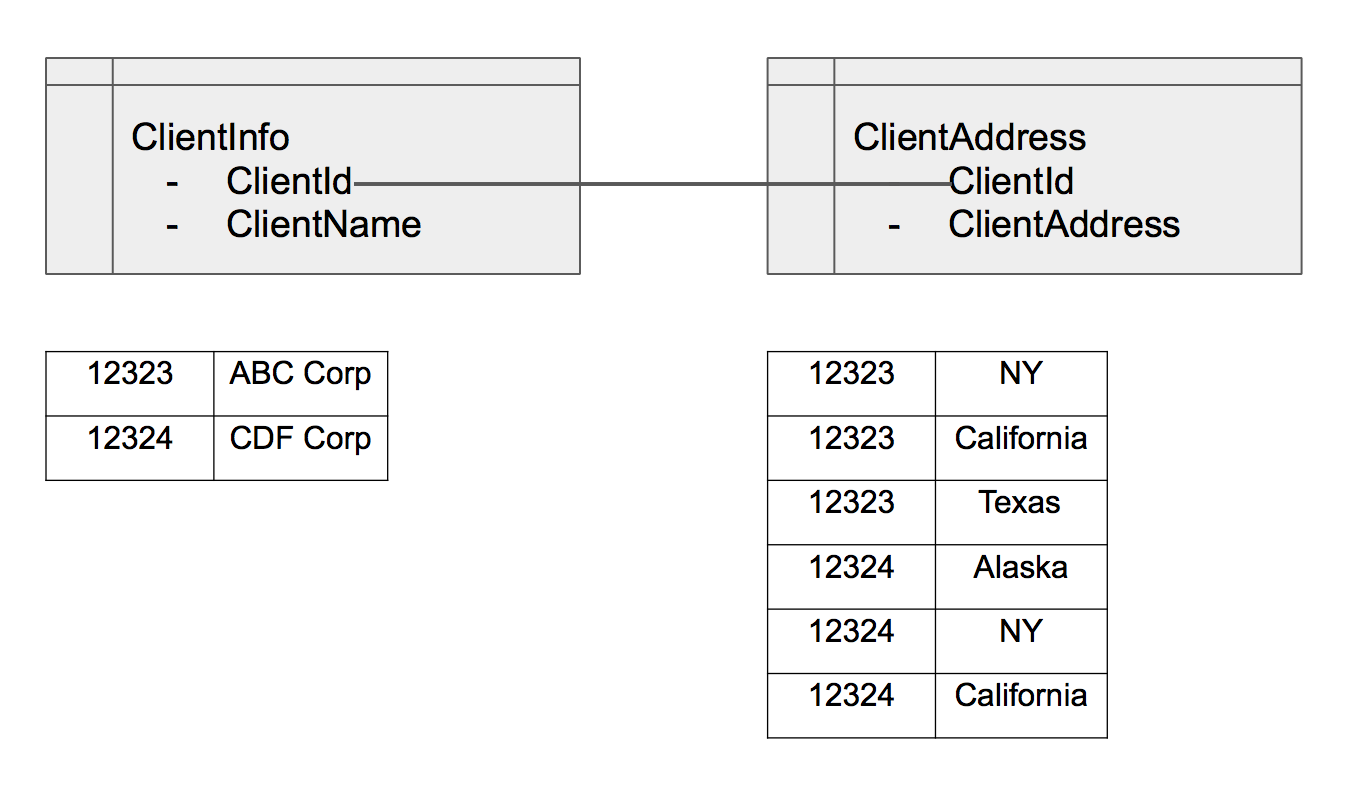
Настройка базы данных MySQL
Настроить базу данных MySQL очень просто. Загрузите исполняемый файл на Mac или ПК и запустите установку. Затем подключитесь к серверу, используя клиент MySQL. Вот инструкции.
Создание таблиц
Следующий запрос создаёт таблицу с первичным ключом.
CREATE TABLE ClientInfo ( ClientId INT NOT NULL ClientName VARCHAR(255) PRIMARY KEY (ClientId) ); Получение данных из таблиц
Этот запрос извлекает данные из одной таблицы.
SELECT * FROM ClientInfo Следующий запрос извлекает данные из двух таблиц путём внутреннего объединения. Выходными данными будут все совпадающие записи из таблиц ClientInfo и ClientAddress.
SELECT * from ClientInfo INNER JOIN ClientAddress ON ClientInfo.ClientId = ClientAddress.ClientId А такой запрос извлекает данные из двух таблиц с помощью неявного обозначения «внутреннего» объединения.
Выходные данные будут такими же, как и раньше.
SELECT * from ClientInfo, ClientAddress WHERE ClientInfo.ClientId = ClientAddress.ClientId Следующий запрос извлекает данные из двух таблиц с помощью внешнего объединения.
В результате получаем все записи ClientInfo + совпадение таблиц ClientInfo и ClientAddress.
SELECT * from ClientInfo LEFT OUTER JOIN ClientAddress ON ClientInfo.ClientId = ClientAddress.ClientId Создание индексов
Создадим уникальный индекс для таблицы с помощью следующего запроса:
CREATE UNIQUE INDEX ClientId ON ClientInfo(ClientId) Теперь, когда у вас сложилось представление о том, как взаимодействовать с SQL и получать информацию из таблиц, перейдём к примеру для Data Science.
SQl + Google BigQuery
С помощью SQL специалисты в Data Science предварительно обрабатывают информацию и решают вопросы машинного обучения. Дальнейший код будет на Python. Для достижения высокой скорости обработки больших наборов данных воспользуемся хранилищем корпоративных данных Google BigQuery.
В онлайн-среде Kaggle для работы с Jupyter Notebooks активируйте Google BigQuery. Вам будут доступны ежемесячные бесплатные 5 терабайт на использование веб-сервиса BigQuery. Если объём закончится раньше, подождите следующего месяца.
Для использования BigQuery зарегистрируйте бесплатный аккаунт Google Cloud Platform и создайте экземпляр проекта в Google-сервисе. Смотрите руководство по началу работы.
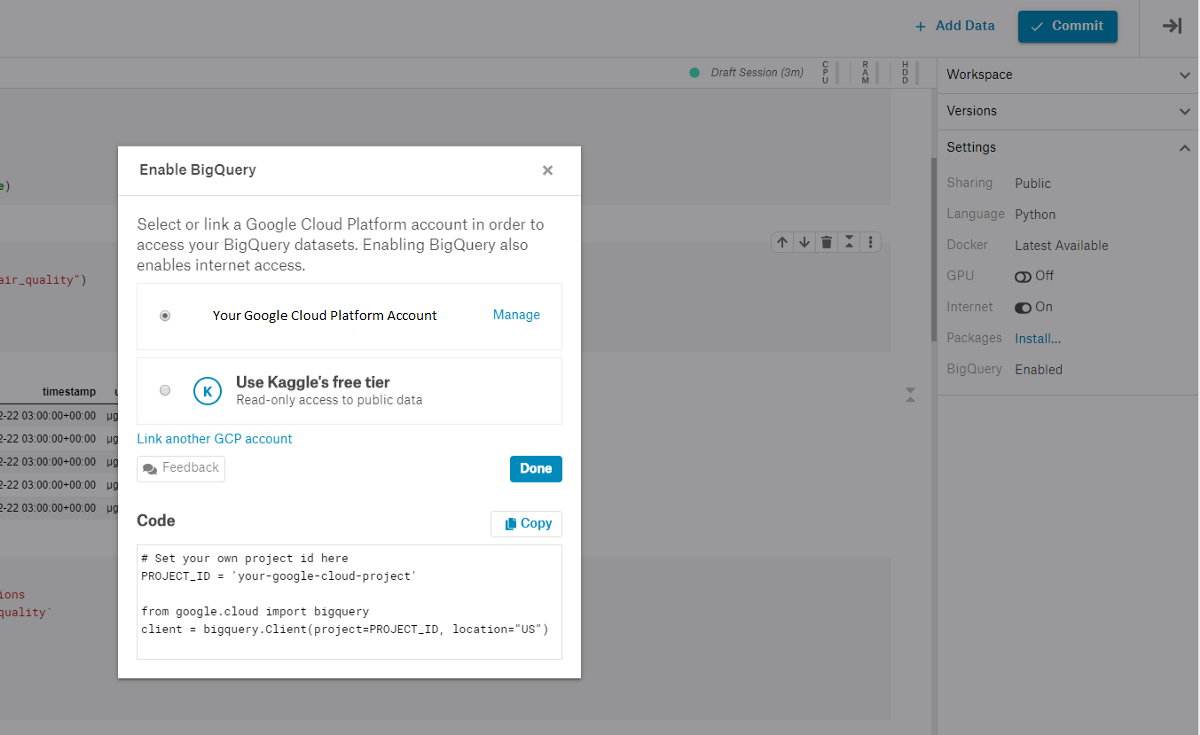
После создания проекта BigQuery в учётной записи вы получите идентификатор, который понадобится, чтобы связать BigQuery с ядром Kaggle. Для этого запустите код:
from google.cloud import bigquery import matplotlib.pyplot as plt import numpy as np # Добавляем ID проекта из Google Cloud Platform PROJECT_ID = 'addyourprojectidhere' client = bigquery.Client(project=PROJECT_ID, location="US") dataset = client.create_dataset('tds_tutorial', exists_ok=True) В примере используется набор данных OpenAQ, который содержит информацию о качестве воздуха в мире.
# Создаём ссылку на таблицу table = client.get_table("bigquery-public-data.openaq.global_air_quality") # Просматриваем первые пять строк из набора данных client.list_rows(table, max_results=5).to_dataframe() 
Подготовка данных
Посмотрим, какие SQL-запросы используются для предобработки данных.
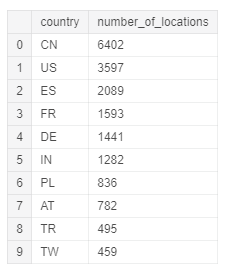
Начнём с определения количества городов в стране, где измерялось качество воздуха. С помощью SQL выбираем столбец country и подсчитываем все отличающиеся значения столбца location. Для удобства сделаем группировку по стране и убывающий порядок.
# Проверяем количество станций измерения для каждой страны query = """SELECT country, COUNT(location) AS number_of_locations FROM `bigquery-public-data.openaq.global_air_quality` GROUP BY country ORDER by number_of_locations DESC""" query_job = client.query(query) query_job.to_dataframe().head(10) Так выглядят первые десять результирующих записей:
Исследуем статистические характеристики столбцов value и averaged_over_in_hours в единицах измерения µg/m?. Это послужит быстрой проверкой на аномалии.
В столбце value хранится последнее измеренное значение для загрязнителей, а в averaged_over_in_hours – время усреднения значения в часах.
# Статистическая сводка query = """SELECT value, averaged_over_in_hours FROM `bigquery-public-data.openaq.global_air_quality` WHERE unit = 'µg/m?' """ query_job = client.query(query) query_job.to_dataframe().describe() 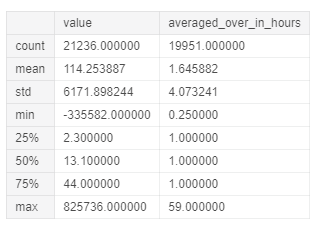
value и averaged_over_in_hoursЧтобы подвести итог нашего анализа, определим среднее количество озона в каждой стране. Для наглядности построим гистограмму с использованием Matplotlib.
# Рассчитаем среднее количество озона для каждой страны query = """ SELECT country, avg(value) as avg_value FROM `bigquery-public-data.openaq.global_air_quality` WHERE pollutant = 'o3' AND country != 'NL' AND country != 'DK' AND country != 'LT' AND country != 'LU' AND unit = 'µg/m?' GROUP BY country ORDER BY avg_value ASC """ query_job = client.query(query) query_df = query_job.to_dataframe() plt.subplots(figsize=(12,7)) y_pos = np.arange(len(query_df.country)) plt.bar(y_pos, query_df.avg_value, align='center', alpha=0.7) plt.xticks(y_pos, query_df.country.values) plt.ylabel('NO2 values in µg/m?', fontsize=16) plt.xticks(rotation= 60,fontsize=16) plt.xlabel('Country', fontsize=16) plt.title('Ozone gas Average in different countries', fontsize=20) plt.show() 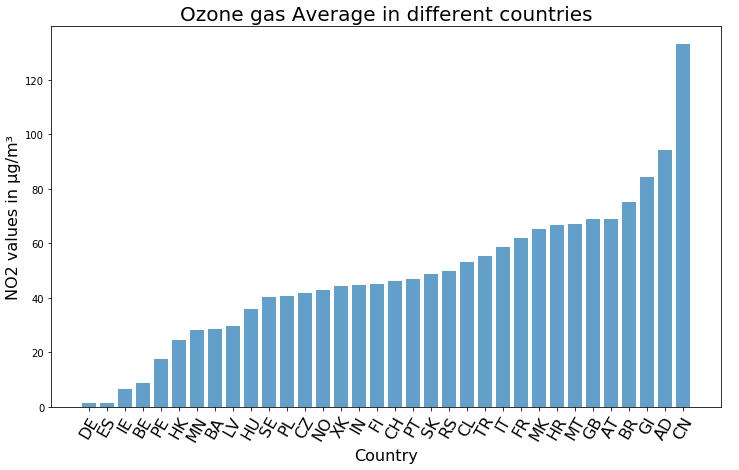
SQL + Machine Learning
Для создания моделей машинного обучения с применением SQL используется Google BigQuery ML. Сервис снижает порог вхождения в Machine Learning и ускоряет процесс благодаря отсутствию перемещения информации.
BigQuery ML избавляет нас от чтения данных в локальной памяти и метания между несколькими языками программирования. Наша модель готова к работе прямо после тренировки.
BigQuery ML поддерживает массу моделей машинного обучения: от линейной и логистической регрессий до метода k-средних и работы с предобученными моделями TensorFlow.
В первую очередь импортируем требуемые зависимости. И добавим команду BigQuery для читабельности.
from google.cloud.bigquery import magics from kaggle.gcp import KaggleKernelCredentials magics.context.credentials = KaggleKernelCredentials() magics.context.project = PROJECT_ID %load_ext google.cloud.bigquery Создадим нашу модель на первых 800 образцах, чтобы сэкономить память. С помощью логистической регрессии предскажем название страны по указанным географическим координатам и уровню загрязнения.
%%bigquery CREATE MODEL IF NOT EXISTS `tds_tutorial.Model` OPTIONS(model_type='logistic_reg') AS SELECT country AS label, latitude, longitude, value FROM `bigquery-public-data.openaq.global_air_quality` LIMIT 800; Чтобы посмотреть итоги обучения модели, выполните:
%%bigquery SELECT * FROM ML.TRAINING_INFO(MODEL `tds_tutorial.Model`) ORDER BY iteration 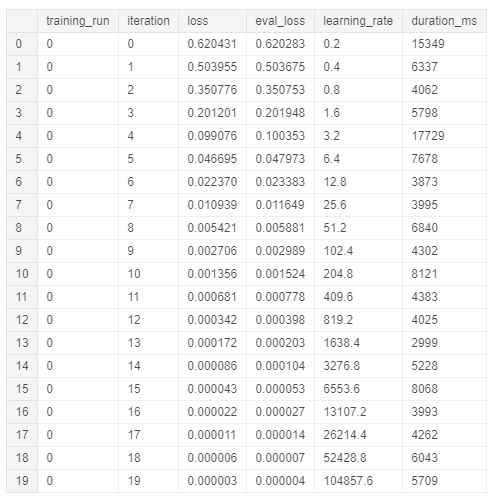
Определим точность модели:
%%bigquery SELECT * FROM ML.EVALUATE(MODEL `tds_tutorial.Model`, ( SELECT country AS label, latitude, longitude, value FROM `bigquery-public-data.openaq.global_air_quality` LIMIT 800)) 
Следующие шаги
Вы прочитали инструкции, поясняющие, как использовать SQL для решения проблем Data Science.
- Теперь создайте простой проект для работы с информацией в базе данных. Самый лёгкий способ – загрузить набор «грязных данных». Затем выполните шаги по очистке данных с использованием SQL вместо Pandas.
- После этого углубите знания – в помощь вам полезные книги по SQL и шпаргалка для разных уровней. Больше информации найдёте в бесплатных курсах Kaggle Intro to SQL и SQLBolt.
А вы используете SQL для решения задач Data Science?
Телеграм: t.me/ainewsline
Источник: proglib.io