
Что должна делать библиотека AutoML?
Библиотека AutoML — это любая часть программного обеспечения, автоматизирующая некоторые самые сложные (и скучные) части конвейера машинного обучения. Применение AutoML ускорит процесс машинного обучения и поможет избежать ошибок. Библиотека AutoML должна автоматизировать такие действия:
- Заполнение пустыми значениями.
- Кодирование категориальных переменных.
- Масштабирование числовых переменных.
- Подбор признаков.
- Выбор модели.
- Настройка гиперпараметров.
Идея заключается в том, что библиотека AutoML пробует все комбинации параметров, измеряя среднюю производительность модели с помощью k-кратной кросс-валидации и выбирая лучший набор значений. Итак, это процедура оптимизации в сетке настроек.
Подход
Здесь я расскажу о конвейере классификации с такой сеткой настроек:
- Заполнение пустых числовых переменных средним или медианным значением.
- Заполнение категориальных переменных наиболее часто встречающимся значением.
- Масштабирование: нормализация, стандартизация или над ёжное масштабирование.
- Подбор признаков на основе фильтров с помощью ANOVA.
- Используемые модели: логистическая регрессия, KNN, случайный лес, градиентный бустинг, бинарное дерево решений, SVM с линейным ядром.
Каждая модель поставляется со своими собственными гиперпараметрами, которые должны оптимизироваться вместе с параметрами предварительной обработки. Итак, идея в том, что все эти параметры становятся гиперпараметрами большого конвейера машинного обучения, который содержит предварительную обработку и модели. Даже сама модель становится гиперпараметром этого конвейера.
Мы перевели нашу задачу в задачу гиперпараметрической оптимизации, которую мы можем решить. Пространство гиперпараметров конвейера очень велико, поэтому воспользуемся случайным поиском, чтобы найти лучший набор значений таких гиперпараметров. Наш объект будет принимать фрейм данных Pandas на вход для обучения, а метод “обучения” выполнит необходимую оптимизацию, чтобы найти лучшую модель и лучшие настройки для фазы предварительной обработки. Посмотрим на код.
Код
Мы создадим объект под названием MyAutoMLClassifier и будем обучать и тестировать его на наборе данных о раке молочной железы. Вы можете найти весь код в моём репозитории на GitHub. Импортируем библиотеки:
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer from sklearn.compose import ColumnTransformer, make_column_selector from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler, OneHotEncoder from sklearn.feature_selection import SelectKBest, f_classif from sklearn.model_selection import RandomizedSearchCV from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import LinearSVC,SVC from sklearn.datasets import load_breast_cancer from sklearn.metrics import balanced_accuracy_scoreТеперь мы можем приступить к определению класса MyAutoMLClassifier. Его конструктор будет принимать скоринговую функцию, которая будет использоваться в k-кратной кросс-валидации и в количестве итераций случайного поиска. В этом примере их значениями по умолчанию будут «balanced accuracy» — сбалансированная точность и 50.
class MyAutoMLClassifier: def __init__(self, scoring_function = 'balanced_accuracy', n_iter = 50): self.scoring_function = scoring_function self.n_iter = n_iterТеперь мы можем начать писать метод «обучения» — самый важный метод. Во-первых, мы должны определить различные значения категориальных переменных, чтобы применить унитарное кодирование.
def fit(self,X,y): X_train = X y_train = y categorical_values = [] cat_subset = X_train.select_dtypes(include = ['object','category','bool']) for i in range(cat_subset.shape[1]): categorical_values.append(list(cat_subset.iloc[:,i].dropna().unique())) Теперь для категориальных переменных нужно определить конвейер предварительной обработки. Этот конвейер заменит пустые значения, используя наиболее часто встречающееся значение, и унитарно закодирует новые значения. В то же время мы собираемся определить конвейер для числовых переменных, который будет очищен в соответствии с определяемым позже и масштабирован в соответствии с преобразователем масштаба, который мы установим в части случайного поиска. Всё это, наконец, включается в настройки ColumnTransformer, который выполнит всю предварительную обработку.
num_pipeline = Pipeline([ ('cleaner',SimpleImputer()), ('scaler',StandardScaler()) ]) cat_pipeline = Pipeline([ ('cleaner',SimpleImputer(strategy = 'most_frequent')), ('encoder',OneHotEncoder(sparse = False, categories=categorical_values)) ]) preprocessor = ColumnTransformer([ ('numerical', num_pipeline, make_column_selector(dtype_exclude=['object','category','bool'])), ('categorical', cat_pipeline, make_column_selector(dtype_include=['object','category','bool'])) ])Наконец, мы должны определить конвейер ML, который строится на этапе предварительной обработки, подбора признаков и самой модели. Сейчас мы можем установить модель в LogisticRegression, она будет изменена позже случайным поиском.
model_pipeline_steps = [] model_pipeline_steps.append(('preprocessor',preprocessor)) model_pipeline_steps.append(('feature_selector',SelectKBest(f_classif,k='all'))) model_pipeline_steps.append(('estimator',LogisticRegression())) model_pipeline = Pipeline(model_pipeline_steps)Затем можно вычислить количество признаков (это понадобится в части подбора признаков) и создать пустой список, содержащий оптимизационную сетку в соответствии с синтаксисом, необходимым RandomSearchCV.
total_features = preprocessor.fit_transform(X_train).shape[1] optimization_grid = []Теперь мы можем начать добавлять модели в нашу сетку оптимизации. Начнём с логистической регрессии:
# Logistic regression optimization_grid.append({ 'preprocessor__numerical__scaler':[RobustScaler(),StandardScaler(),MinMaxScaler()], 'preprocessor__numerical__cleaner__strategy':['mean','median'], 'feature_selector__k': list(np.arange(1,total_features,5)) + ['all'], 'estimator':[LogisticRegression()] })Как мы видим, создаётся объект, который изменит масштабирование между RobustScaler, StandardScaler и MinMaxscaler. Затем будет изменена стратегия очистки между средним и медианным значениями и выбраны объекты от 1 до общего числа объектов с шагом 5. Наконец, сама модель установлена. Случайный поиск будет проверять случайные комбинации этой сетки, в поиске той, которая максимизирует показатели производительности при кросс-валидации.
Теперь мы можем добавить другие модели с их собственными гиперпараметрами и нуждами в смысле предварительной обработки. Например, деревья не требуют никакого масштабирования, но SVM — да. Мы можем добавить столько моделей, сколько захотим, оптимизируя их гиперпараметры в одной сетке.
# K-nearest neighbors optimization_grid.append({ 'preprocessor__numerical__scaler':[RobustScaler(),StandardScaler(),MinMaxScaler()], 'preprocessor__numerical__cleaner__strategy':['mean','median'], 'feature_selector__k': list(np.arange(1,total_features,5)) + ['all'], 'estimator':[KNeighborsClassifier()], 'estimator__weights':['uniform','distance'], 'estimator__n_neighbors':np.arange(1,20,1) }) # Random Forest optimization_grid.append({ 'preprocessor__numerical__scaler':[None], 'preprocessor__numerical__cleaner__strategy':['mean','median'], 'feature_selector__k': list(np.arange(1,total_features,5)) + ['all'], 'estimator':[RandomForestClassifier(random_state=0)], 'estimator__n_estimators':np.arange(5,500,10), 'estimator__criterion':['gini','entropy'] }) # Gradient boosting optimization_grid.append({ 'preprocessor__numerical__scaler':[None], 'preprocessor__numerical__cleaner__strategy':['mean','median'], 'feature_selector__k': list(np.arange(1,total_features,5)) + ['all'], 'estimator':[GradientBoostingClassifier(random_state=0)], 'estimator__n_estimators':np.arange(5,500,10), 'estimator__learning_rate':np.linspace(0.1,0.9,20), }) # Decision tree optimization_grid.append({ 'preprocessor__numerical__scaler':[None], 'preprocessor__numerical__cleaner__strategy':['mean','median'], 'feature_selector__k': list(np.arange(1,total_features,5)) + ['all'], 'estimator':[DecisionTreeClassifier(random_state=0)], 'estimator__criterion':['gini','entropy'] }) # Linear SVM optimization_grid.append({ 'preprocessor__numerical__scaler':[RobustScaler(),StandardScaler(),MinMaxScaler()], 'preprocessor__numerical__cleaner__strategy':['mean','median'], 'feature_selector__k': list(np.arange(1,total_features,5)) + ['all'], 'estimator':[LinearSVC(random_state = 0)], 'estimator__C': np.arange(0.1,1,0.1), })Итак, мы ищем наилучшее сочетание стратегии очистки, процедуры масштабирования, набора признаков, значений модели и гиперпараметров — всё в одной и той же процедуре поиска. Это ядро любой библиотеки AutoML и может быть расширено по нашему желанию.
Теперь у нас есть завершённая сетка оптимизации, так что мы можем, наконец, применить случайный поиск, чтобы найти лучшие параметры конвейера и сохранить результаты в свойствах нашего объекта. Случайный поиск будет применять 5-кратную кросс-валидацию с помощью функции скоринга и количества итераций, выбранных в конструкторе класса.
search = RandomizedSearchCV( model_pipeline, optimization_grid, n_iter=self.n_iter, scoring = self.scoring_function, n_jobs = -1, random_state = 0, verbose = 3, cv = 5 ) search.fit(X_train, y_train) self.best_estimator_ = search.best_estimator_ self.best_pipeline = search.best_params_Метод обучения завершён. Теперь мы можем добавить методы «predic» и «predict_proba», как и любую другую модель sklearn, и наш MyAutoMLClassifier закончен.
def predict(self,X,y = None): return self.best_estimator_.predict(X) def predict_proba(self,X,y = None): return self.best_estimator_.predict_proba(X)Сейчас можно импортировать набор данных, разделить его на наборы обучения и тестирования, создать экземпляр MyAutoMLClassifier и обучить его.
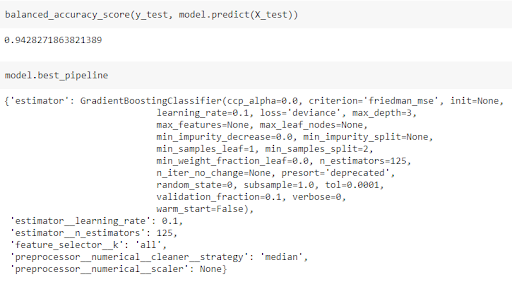
d = load_breast_cancer() y = d['target'] X = pd.DataFrame(d['data'],columns = d['feature_names']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42) model = MyAutoMLClassifier() model.fit(X_train,y_train)С помощью всего лишь одной строки кода мы делаем все сложные вещи с помощью AutoML. После обучения модели мы можем рассчитать сбалансированную точность в тестовом наборе и посмотреть, какие параметры модели и предварительной обработки были выбраны:
Заключение
Библиотеки AutoML — это очень полезные инструменты для дата-сайентита, и они действительно помогают сэкономить много времени. В соответствии с бизнес-контекстом, над которым мы работаем, нам может потребоваться работать только с определёнными моделями или процедурами очистки, поэтому нам нужна своя версия AutoML. Пример в этой статье легко адаптируется к задаче регрессии и может быть интегрирован с другими моделями, такими как нейронные сети.