
Цель
Дать высокоуровневый обзор ключевых шагов, необходимых для перехода от необработанных данных к развёрнутому приложению машинного обучения.
После того как вы посмотрите этот обзор, выберите интересующую вас тему, найдите данные, засучите рукава и постарайтесь создать собственное приложение машинного обучения, от подготовки данных до развертывания.
Ключевые шаги
- Обработка данных с помощью Pandas и хранение данных с помощью SQLite.
- Машинное обучение (нейронная сеть) с помощью Keras.
- Разработка веб-приложения с помощью Flask (и немного CSS и HTML).
- Развёртывание приложения с помощью Docker и Heroku.
Код доступен на GitHub, приложение в действии можно посмотреть здесь. Обратите внимание, что этот код не обязательно соответствует уровню производственного, он предназначен, чтобы показать, что можно сделать, как отправная точка. Работающее приложение использует моментальный снимок данных в определённый момент.
1. Работа с данными и их хранение с помощью Pandas и SQLite
Специалисты по Data Science тратят около 45 % своего времени просто на подготовку данных для разработки модели.
Работа с данными включает очистку, структуризацию и обогащение данных таким образом, чтобы они были подготовлены для модели ML.
Если вы не используете уже очищенный набор данных (что редко бывает в реальном мире), чтобы лучше понять профиль данных, вам потребуется выполнить их исследовательский анализ.
Pandas-profiling — отличный модуль для EDA. Он генерирует отчёты профилирования фреймов данных, включая квантильную и описательную статистику, корреляции, отсутствующие значения и гистограммы.

Для этого проекта мне потребовались данные из ESPN Scrum. Вы можете найти подробные инструкции по очистке в файле data_prep.py, например, определение формата даты матча с помощью метода
to_datetime(). Я также обогатил данные с помощью World Rugby Rankings и оценки навыков при помощи Microsoft TrueSkill рейтинговая система. Если для начала вам нужны наборы данных, репозиторий UC Irvine’s Machine Learning и Kaggle хорошие источники. В качестве альтернативы можно воспользоваться BeautifulSoup. Я сохранил фреймы данных в виде таблиц в базе данных SQLite. Это легкая база данных и она наиболее широко распространена в мире. Конечно, можно использовать простые файлы csv, это даже дает возможность изучить о SQLite. Приведенный ниже код подключается к базе данных matchresults и в виде таблицы записывает в нее DataFrame lateststats.conn = sqlite3.connect ('match_results.db') latest_stats.to_sql ('latest_stats', conn, if_exists = 'replace')Теперь у нас есть данные — пора протестировать и обучить модель.
2. Машинное обучение — нейронные сети с Keras
Тестирование
Среднеквадратичная ошибка (MSE) использовалась как функция потерь для минимизации. Была выполнена настройка гиперпараметров (у Джейсона Браунли есть руководство), я экспериментировал с широкими (один слой с большим количеством нейронов) и глубокими (больше слоев, но меньше нейронов на слой) сетями, пока MSE не улучшилась значительно. Хочется, чтобы модель могла хорошо работать с данными, которых не видела. Если переобучить модель, у вас может быть низкая ошибка в обучающих данных, но высокая ошибка в тестовых ( которые модель не видела ранее). Когда это происходит, это означает, что модель слишком хорошо усвоила обучающие данные и не может обобщить их на новые данные. Есть разные способы избежать переобучения. Ниже видно, что MSE быстро снижается до ~25 эпох, а затем остаётся относительно стабильным как для данных обучения, так и для данных тестирования.
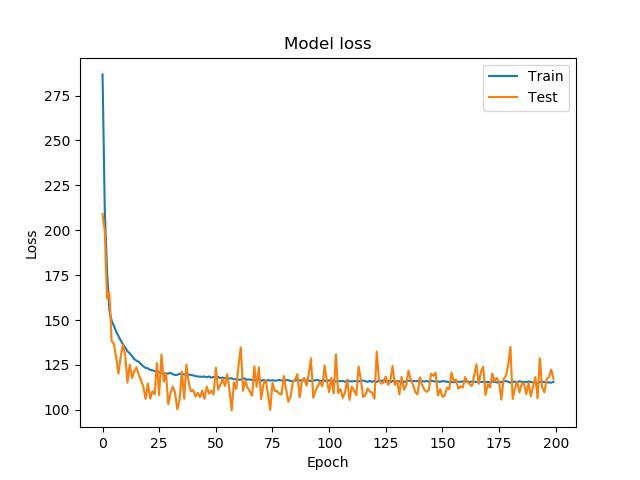
Обучение
У последней модели первый слой состоит из 15 нейронов, второй слой — из 8 нейронов, оба с усечённым линейным преобразованием (ReLU). Она собиралась с помощью алгоритма оптимизации Adam, эффективного алгоритма градиентного спуска.
model = Sequential () model.add (Dense (15, input_dim = 5, kernel_initializer = 'normal', activate = 'relu')) model.add (Dense (8, kernel_initializer = 'normal', activate = 'relu') ) model.add (Dense (2, kernel_initializer = 'normal')) model.compile (loss = 'mse', optimizer = 'adam')Сохранение модели
Функция save() применяется для сохранения окончательной модели Keras. Она сохраняет архитектуру модели и её веса и позже позволит загрузить модель в приложение, чтобы делать прогнозы на основе новых данных.
3. Веб-приложение с применением Flask (и немного CSS/HTML)
Flask — это веб-фреймворк, который можно использовать для относительно быстрой разработки веб-приложений. Руководство по быстрой разработке найдется здесь. Код ниже из app.py по существу настраивает домашнюю страницу, предоставляя пользователю страницу index.html:

Для формы используется WTForms, чтобы пользователь мог выбрать две команды по регби. Когда нажимается кнопка, входные данные отправляются в сохранённую модель ML через функцию
model_predict. Полученные прогнозы модели затем отправляются в качестве входных переменных в шаблон prediction.html.@app.route("/", methods=['GET', 'POST']) def home(): form = TeamForm(request.form) # Get team names and send to model if request.method == 'POST' and form.validate(): team1 = request.form['team1'] team2 = request.form['team2'] return render_template('prediction.html', win_prob=model_predict(team1,team2)[0], score=model_predict(team1, team2)[1]) # Send template information to index.html return render_template('index.html', form=form) Шаблон
prediction.html выполняет три ключевые функции:- Получает вероятность выигрыша и счёт, отправленные из выходных данных модели для отображения конечному пользователю (через переменные
win_probиscore). - Отображает пользователю кнопку для возврата на главную страницу.
- Ссылается на файл main.css для стилизации.
<!DOCTYPE html> <head> <title>Prediction</title> <link rel="stylesheet" href="/static/css/main.css"> </head> <body> <div class="container"> <h1> <center>Predictions</center> </h1> {% block content %} <div class="flash">{{win_prob}}</div> <div class="flash">{{score}}</div> <form action="/button" method = "POST"> <p><input type = "submit" value = "Return" /></p> </form> {% endblock %} </div> </body> </html>И это всё! Таким образом, у вас есть:
- Два шаблона, index.html и prediction.html для домашней страницы и страницы результатов прогнозов.
- CSS-файлы для стилизации.
- Сохранённый файл вашей модели для прогнозов.
- Код app.py на фреймворке Flask для определения страниц и их функций, а также для запуска приложения. Разверните свое приложение и поделитесь им с миром.
4. Развёртывание приложений с помощью Docker и Heroku
Контейнер Docker
Я не буду вдаваться в подробности о Docker, но важно знать, что он позволяет упаковать приложение в самодостаточный контейнер, который можно использовать в разных системах, т. е. он создает переносимую упаковку, которая упрощает развёртывание вашего приложения. Подробности можно найти в официальной документации Docker.
- Загрузите Docker Desktop здесь.
- Создайте Dockerfile в каталоге приложения. В нём содержатся инструкции по созданию образа Docker. Лучшие практики для файлов Dockerfile можно посмотреть здесь и здесь. Ниже вы увидите, что я добавил инструкции по запуску файла requirements.txt, содержащего зависимости приложения.
FROM python:3.7.3-stretchRUN mkdir /app WORKDIR /app#Copy all files COPY . .# Install dependencies RUN pip install --upgrade pip RUN pip install -r requirements.txt# Run CMD ["python","./main.py"]- Откройте терминал и перейдите в каталог с вашим Dockerfile и приложением. Воспользуйтесь командой build для создания вашего образа:
docker build -t rugby_prediction. Команда строит образ Docker из файла Docker. - Если вы сталкиваетесь с ошибками при запуске приложения, можно воспользоваться командой
docker logs, чтобы посмотреть журналы отладки. - Вы можете запустить приложение локально, командой run, которая создает контейнер:
docker run --name rugby -p 5000: 5000 -d rugby_prediction. Здесь-pпубликует порт контейнера для хоста, а-dзаставляет контейнер работать в фоновом режиме. Как только всё будет запущено, вы сможете просматривать приложение, работающее в вашем браузере (в Docker Desktop нажмите кнопку открыть в браузере (open in browser)).
Развертывание на Heroku
Для размещения проекта я использовал Heroku, потому что у них хороший уровень для некоммерческих приложений при бесплатности.
- После того как вы создали учетную запись Heroku, создайте новое приложение и выберите Реестр контейнеров (Container Registry) в качестве метода развертывания.
- Загрузите Heroku CLI и войдите в свою учетную запись Heroku:
heroku login - Войдите в реестр контейнеров:
heroku container: login - Перейдите в рабочий каталог своего приложения и отправьте образ Docker:
heroku container: push web --app[НАЗВАНИЕ ПРИЛОЖЕНИЯ] - Разверните свое приложение:
heroku container: release web --app[НАЗВАНИЕ ПРИЛОЖЕНИЯ]
Ну вот и все, теперь вы готовы поделиться своим живым веб-приложением машинного обучения. Надеюсь, проект полезен для начала работы. А если какие-то этапы реализации проекта вызвали у вас вопросы — то заглядывайте на наш курс по машинному обучению. И не забывайте про промокод HABR, который дает +10% к скидке на баннере ниже.