
Обработка естественного языка (Natural Language Processing, NLP) – это область вычислительной лингвистики, ориентированная на разработку машин, способных понимать человеческие языки. Разработка таких машин – одна из задач, которые решают исследователи и инженеры в команде SberDevices. В современной компьютерной лингвистике понимание смысла написанного или сказанного достигается с помощью векторных моделей естественного языка. Например, в семействе виртуальных ассистентов Салют такая модель применяется для распознавания намерений пользователя, ведения диалога, выделения именованных сущностей и многих других задач. В этой статье мы рассмотрим метод обучения модели естественного языка (NLU) на размеченных данных и реализацию этого метода на python3 и tensorflow 1.15. Ниже вы найдете пошаговое руководство и примеры кода. Код всего эксперимента доступен для воспроизведения на Colab. Помимо этого, мы выкладываем в публичный доступ русскую модель NLU класса BERT-large [427 млн. параметров]: tensorflow, pytorch. Прочитав этот пост, вы узнаете:
- что такое модели NLU и как они применяются в компьютерной лингвистике;
- что такое векторы предложений и как их получить;
- как обучить векторизатор предложений [NLU] на базе архитектуры BERT;
- как можно использовать обученные модели NLU
О NLU и признаковых пространствах
Модели машинного обучения принимают на вход данные в цифровой форме.
При работе с текстом первое, что необходимо сделать, это перейти к его цифровому представлению.
Задача моделей естественного языка – представлять текст в векторной форме. Этот процесс в английской литературе называют «embedding», имея в виду, что смысл слов оцифровывается моделью и записывается в виде упорядоченного набора числовых значений (то есть вектора). Первые модели NLU такие как Word2Vec «понимали» смысл текста только на уровне отдельных слов, без контекста. Последние достижения в компьютерной лингвистике позволили перейти к эффективным векторным представлениям для целых предложений и абзацев текста.

Расположение фраз в векторном пространстве определяется параметрами используемой модели языка. Модели обучают таким образом, что векторы, вычисленные ими, сохраняют смысловые отношения между фразами – похожие по смыслу предложения кодируются в близкие по метрике векторы. Поэтому на их основе удобно применять приемы instance-based learning, например, метод ближайших соседей K-NN. Наиболее эффективным на данный момент способом построения моделей естественного языка является обучение глубоких нейронных сетей на основе архитектуры «трансформер»: BERT, RoBERTa, GPT-3. Эти модели универсальны и способны извлекать из текста признаки, полезные для решения множества задач текстового анализа. По этой причине их иногда называют моделями понимания естественного языка или NLU.
План эксперимента
Для обучения нашей модели мы используем набор данных Stanford Natural Language Inference, содержащий пары предложений с метками, которые указывают на следствие («entailment»), противоречие («contradiction») или отсутствие смысловой связи («neutral») между предложениями. Для этих данных на базе модели BERT мы выучим такое векторное представление, что сходство между соответствующими парами предложений будет больше, чем сходство между противоречащими или нейтральными по отношению друг к другу. План этого эксперимента следующий:
- Подготовка наборов данных.
- Реализация генератора батчей.
- Определение функции потерь.
- Построение модели.
- Подготовка процесса валидации.
- Обучение модели.
- Обсуждение результатов и выводы.
1. Подготовка данных
Для начала загрузим датасеты, необходимые для обучения [SNLI, MNLI] и валидации [STS SICK] нашей модели. Кроме этого нам понадобится предобученная английская модель BERT. К счастью, все это лежит в открытом доступе:
Рассмотрим обучающие данные. Вот небольшой пример из датасета SNLI:

snli_1.0_train.jsonl)Легко видеть, что для каждого уникального предложения в колонке «sentence1» в наборе есть несколько соответствующих ему примеров с метками. Предложения из колонки «sentence1» далее мы будем называть «якорными примерами» (anchor), а соответствующие предложения из «sentence2» – положительными или отрицательными примерами, в зависимости от метки «label».
Чтобы работать с датасетом было удобнее, для каждого уникального якорного примера создадим отдельную запись, содержащую все соответствующие ему примеры с метками. Записи, для которых отсутствуют положительные примеры класса «entailment», мы отфильтруем.
Такая запись могла бы выглядеть следующим образом:
{ anchor: ["Нет, не отвечай."], contradiction: ['Ответьте, пожалуйста.'], entailment: ["Не отвечайте.", "Не говорите ни слова".], neutral: ["Выйдите из машины."]} Преобразуем к такому формату все обучающие данные из датасетов SNLI и MNLI.
2. Батч-генератор
Батч-генератор – это подпрограмма, которая генерирует из датасета пакеты (батчи) данных для обучаемой нейронной сети. Задача нашей сети – «сближать» в векторном пространстве релевантные пары предложений и «раздвигать» нерелевантные (см. Рис. 4).
Обучать модель мы будем на триплетах (a, p, n) где
a — якорный пример, берем из поля «anchor»;
p — положительный пример, выбираем среди тех что с меткой «entailment»;
n — отрицательный пример, берем из «contradiction» и «neutral».

В случае, если размеченного отрицательного примера в датасете не нашлось, вместо него выберем рандомный негативный пример из датасета. Общая логика генерации батча реализована в коде:
3. Функция потерь
Теперь необходимо формально определить функцию потерь, минимизировав которую, мы научим модель лучше работать на наших данных. Для этого задачу «сближения» перефразированных предложений сформулируем как задачу ранжирования.
Положим, что имеется набор из k-пар предложений x и y и нужно выучить функцию, которая оценивает, является ли y перефразировкой x или нет. Для каждого x в наборе есть минимум один положительный пример y и максимум k-1 отрицательных примеров. Такое распределение можно записать как:
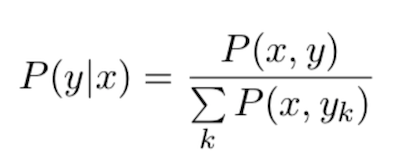
Совместную вероятность P(x, y) — будем оценивать с помощью некоторой скоринговой функции S:
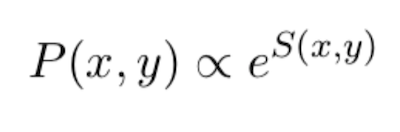

Перейдем к задаче минимизации. Для negative log likelihood-батча размером K запишем:

Важной особенностью этой функции потерь является то, что она использует сразу несколько (K) отрицательных примеров для каждого положительного. Это хорошо влияет на сходимость модели, заставляя ее выучивать более устойчивые векторные представления. Вариант реализации этой функции для триплета (a):
4. Архитектура модели
Архитектура модели представляет собой сиамскую нейронную сеть с тремя входами для триплета «anchor — positive — negative». К каждому из входов применяется модуль BERT, который и будет выполнять роль NLU в этом эксперименте. Модуль содержит в себе wordpiece-токенизатор для преобразования входных строк в BERT-совместимый формат (input_ids, input_mask, token_type_ids), а также саму обучаемую модель BERT для векторизации текста. К выходу последнего encoder-слоя модели применяем операцию masked-mean-pooling, чтобы получить единый вектор для предложения. Векторизованный таким образом триплет далее применяется для вычисления softmax loss и обучения модели.
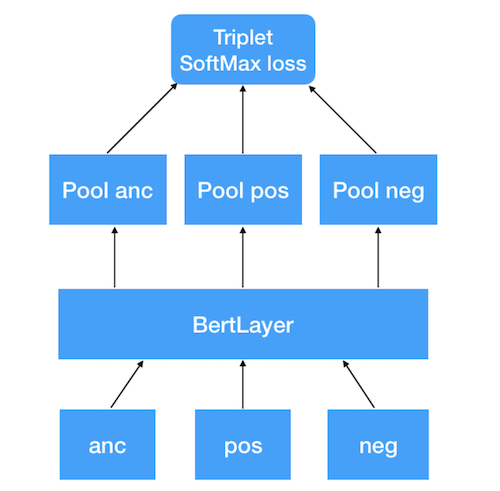
Код для сборки модели:
5. Валидация результатов
Модели NLU обычно оцениваются путем векторизации размеченных пар предложений, измерения степени сходства между парами предложений с помощью тестируемой модели, а затем вычисления корреляции этого сходства с человеческой разметкой. Для оценки английских моделей NLU обычно используются наборы данных STS 2012–2016 и SICK 2014. Вот небольшой пример этих данных:

2012.MSRpar.test.tsvКак и SNLI, данный датасет содержит пары предложений. Оцифруем их моделью и оценим сходство между предложениями, вычислив косинусную близость между их векторами. В качестве метрики будем использовать ранговую корреляцию Пирсона и Спирмена с метками из датасета.
Код Callback, содержащего эту логику:
6. Процесс обучения
Почти все готово: данные, модель и пайплайн валидации. Обсудим теперь некоторые гиперпараметры, которые необходимо настроить перед тем, как мы начнем обучение.
В Colab для обучения в нашем распоряжении будет NVIDIA K80 (12Гб). Чтобы сократить количество необходимой видеопамяти, важно правильно выбрать максимальную длину обрабатываемой последовательности (seq_len). В этом эксперименте мы ограничим ее 24 токенами, что будет достаточно для кодирования большей части данных, используемых при обучении.
Увеличение размера батча крайне положительно влияет на сходимость модели – выберем максимальный, который поместится в память нашего GPU.
В качестве оптимизатора будем использовать старый добрый Adam с небольшим learning rate. Обучать модель будем до схождения, 10 эпох должно хватить. Параметры обучения:
- batch size = 128 для BERT-base;
- max_seq_len = 24;
- Optimizer Adam;
- Learning rate ~1e-5;
- Метрики — [spearmanr];
- Кол-во эпох ~10.
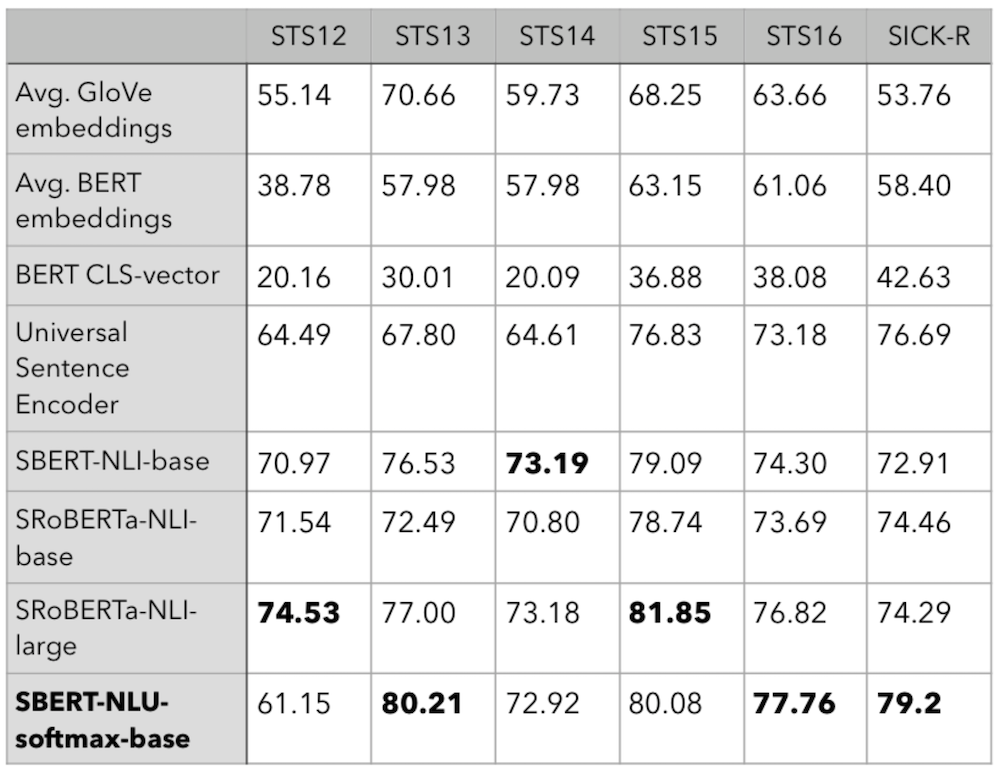
trn_model.fit_generator(tr_gen._generator, validation_data=ts_gen._generator, steps_per_epoch=256, validation_steps=32, epochs=5, callbacks=callbacks) *** New best: STS_spearman_r = 0.5426 *** New best: STS_pearson_r = 0.5481 *** New best: SICK_spearman_r = 0.5799 *** New best: SICK_pearson_r = 0.6069 Epoch 1/10 255/256 [============================>.] - ETA: 1s - loss: 0.6858 ... Epoch 10/10 255/256 [============================>.] - ETA: 1s - loss: 0.2381 256/256 [==============================] - 525s 2s/step - loss: 0.2383 - val_loss: 0.2492 *** New best: STS-2012_spearman_r = 0.6115 *** New best: STS-2013_spearman_r = 0.8021 *** New best: STS-2014_spearman_r = 0.7292 *** New best: STS-2015_spearman_r = 0.8008 *** New best: STS-2016_spearman_r = 0.7776 *** New best: SICK_spearman_r = 0.792 7. Результаты и выводы
Для сравнения рассмотрим результаты ряда моделей из статьи Sentence-BERT, где авторы оценили несколько предварительно обученных систем NLU на датасетах STS и SICK. Лучший результат на сете SICK в этой статье получила модель Universal Sentence Encoder (USE) от Google. Однако после 10 эпох обучения наша модель существенно превосходит ее показатель, достигая 0.792. Также на датасетах STS-2013 и STS-2016 обученная нами модель демонстрирует лучший результат, даже среди моделей серии large:
Качество модели можно улучшать и далее, если, например:
- увеличить размер батча;
- увеличить seq_len, чтобы обрезать меньше предложений по длине;
- поменять модель NLU на что-то помощнее, например, на BERT-large;
- разметить и добавить больше данных;
- ????
Большинство из этих шагов потребует существенного увеличения требуемой вычислительной мощности. Однако и всего на одной GPU нам удалось обучить довольно сильную модель, превосходящую по качеству SOTA-решение 2018 года. Это говорит о высокой эффективности рассмотренного нами метода обучения.
Эксперименты с русской моделью NLU
Теперь рассмотрим поподробнее опубликованную нами русскую модель NLU. Она уже существенно тяжелее той, что мы обучали выше – это BERT-large, в ней 24 слоя и 426.9 миллионов параметров! За счет большего размера и глубины эта модель может вычислять гораздо более насыщенные векторные представления. Для обучения этой модели был задействован уже целый кластер GPU на базе DGX-2, а обучающий набор данных включает в себя более 16 млрд. токенов и содержит многие публичные и проприетарные датасеты.
Распознавание намерений
Одна из важных задач NLP, которая решается в Ассистентах семейства Салют, это распознавание намерения пользователя по тексту его запроса. Воспользуемся опубликованной русской моделью, чтобы оцифровать и рассмотреть небольшой датасет, используемый нами для распознавания намерений на русском языке.
Датасет состоит из примеров запросов с метками, соответствующими определенным пользовательским намерениям (узнать погоду, послушать сказку, заказать еду и т. п.). Полученные векторные представления отобразим в трехмерном пространстве с помощью инструмента Tensorflow Projector:

Распознавание обсценных запросов
Другой важный use case моделей NLU – применение их в качестве основы для supervised-моделей классификации текста. Такая модель используется в Салюте для распознавания оскорбительных или токсичных запросов. К сожалению, публичных русских датасетов для этой задачи под рукой не оказалось. Однако, мой коллега Andriljo решил оценить модель на данных недавно закончившегося соревнования Mail.ru по поиску токсичных комментариев:

- SBERT NLU в качестве базового BertLayer;
- batch size = 128;
- max_seq_len = 64;
- N_tune_lrs = 12?24;
- Optimizer Adam;
- Learning rate ~5e-5;
- Метрики — [avg F1micro, AvgPrecScore];
- Кол-во эпох ~3.
Схема модели – это классический многослойный перцептрон поверх фичей BERT: применяем mean pooling к последнему encoder-слою, чтобы получить векторы предложений, и добавляем сверху три полносвязных слоя. Model summary представлена ниже:

Ваш вариант
Уверены, что читатели смогут найти множество других интересных применений нашей модели NLU. Модель доступна для скачивания в формате для tensorflow, pytorch, и tf-hub.
Благодарность
За помощь в подготовке поста выражаю благодарность Александру @Andriljo Абрамову и Кристине @Christina29 Лавренюк.