MichiGAN: нейросеть редактирует прическу на изображении
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-11-23 04:45

MichiGAN — это генеративно-состязательная нейросеть, которая редактирует прическу на изображении. На основе портретного снимка модель позволяет модифицировать прическу персоны по нескольким референсным снимкам. Модель дает возможность редактировать отдельное такие атрибуты прически, как внешний вид, структура и форма. При этом задний фон изображения остается целым. Кроме того, модель может модифицировать несколько атрибутов прически совместно. По результатам экспериментов, MichiGAN обходит альтернативные подходы по степени интерактивности редактирования и по качеству итоговых снимков.
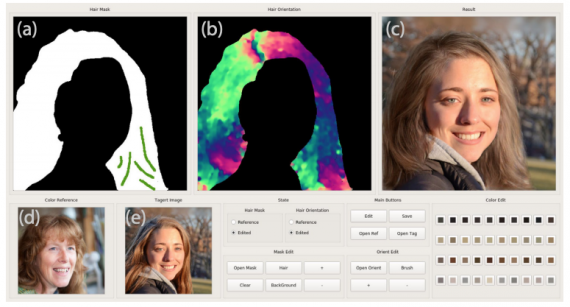
Подробнее про модель
MichiGAN состоит из базовой генеративной сети и трех условных модулей (condition modules): для формы и структуры, внешнего вида и заднего фона. Генератор — это последовательная конкатенация шести апсемплинг остаточных блоков SPADE (ResBlk) и сверточный слой, который выдает итоговое изображение.
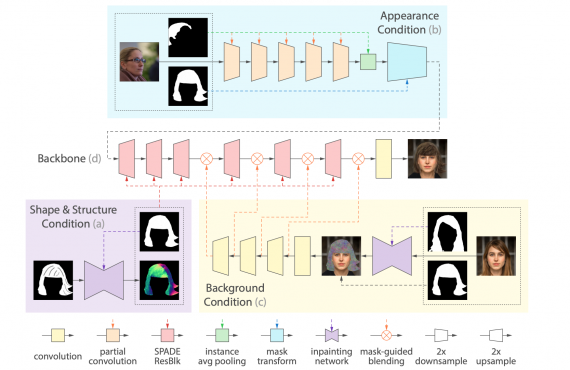
Подробнее условные модули и базовая архитектура описаны в оригинальной статье.
Оценка работы модели
Исследователи сравнивали работу MichiGAN с альтернативными архитектурами. Ниже видно, что модель работает сравнимо или лучше state-of-the-art моделей, в зависимости от разрешения изображений.

Телеграм: t.me/ainewsline
Источник: neurohive.io