Кэширование в Python: алгоритм LRU
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-11-17 19:49

Эта публикация – незначительно сокращенный перевод статьи Сантьяго Валдаррама Caching in Python Using the LRU Cache Strategy. Переведенный текст также доступен в виде блокнота Jupyter.
***
Кэширование – один из подходов, который при правильном использовании значительно ускоряет работу и снижает нагрузку на вычислительные ресурсы. В модуле стандартной библиотеки Pythonfunctoolsреализован декоратор@lru_cache, дающий возможность кэшировать вывод функций, используя стратегиюLeast Recently Used(LRU, «вытеснение давно неиспользуемых»). Это простой, но мощный метод, который позволяет использовать в коде возможности кэширования.
В этом руководстве мы рассмотрим:
- какие стратегии кэширования доступны и как их реализовать с помощью декораторов;
- что такое LRU и как работает этот подход;
- как повысить производительность программы с помощью декоратора
@lru_cache; - как расширить функциональность декоратора
@lru_cacheи прекратить кэширование по истечении определенного интервала времени.
Кэширование в Python: в чем польза
Кэширование– это метод оптимизации хранения данных, при котором операции с данными производятся эффективнее, чем в их источнике.
Представим, что мы создаем приложение для чтения новостей, которое агрегирует новости из различных источников. Пользователь перемещается по списку, приложение загружает статьи и отображает их на экране.
Как поступит программа, если читатель решит сравнить пару статей и станет многократно между ними перемещаться? Без кэширования приложению придется каждый раз получать одно и то же содержимое. В этом случае неэффективно используется и система пользователя, и сервер со статьями, на котором создается дополнительная нагрузка.
Лучшим подходом после получения статьи было бы хранить контент локально. Когда пользователь в следующий раз откроет статью, приложение сможет открыть контент из сохраненной копии, вместо того, чтобы заново загружать материал из источника. В информатике этот метод называетсякэшированием.
Реализация кэширования в Python посредством словаря
В Python можно реализовать кэширование, используя словарь. Вместо того, чтобы каждый раз обращаться к серверу, можно проверять, есть ли контент в кэше, и опрашивать сервер только если контента нет. В качестве ключа можно использовать URL статьи, а в качестве значения – ее содержимое:
import requests link = "https://proglib.io/p/vse-chto-nuzhno-znat-o-dekoratorah-python-2020-05-09" cache = dict() def get_article_from_server(url): print("Забираем статью с сервера...") response = requests.get(url) return response.text def get_article(url): print("Получаем статью...") if url not in cache: cache[url] = get_article_from_server(url) return cache[url] get_article(link)[:1000] get_article(link)[:1000] Получаем статью... Забираем статью с сервера... Получаем статью... ' <!DOCTYPE html> <html lang="ru" > ...' Примечание. Для запуска этого примера у вас должна быть установлена библиотека requests:
pip install requests Хотя вызов get_article() выполняется дважды, статья с сервера загружается лишь один раз. После первого доступа к статье мы помещаем ее URL и содержимое в словарь cache. Во второй раз код не требует повторного получения элемента с сервера.
Стратегии кэширования
В этой простой реализации кэширования закралась очевидная проблема: содержимое словаря будет неограниченно расти: чем больше статей открыл пользователь, тем больше было использовано места в памяти.
Чтобы обойти эту проблему, нам нужна стратегия, которая позволит программе решить, какие статьи пора удалить. Существует несколько различных стратегий, которые можно использовать для удаления элементов из кэша и предотвращения превышения его максимального размера. Пять самых популярных перечислены в таблице.
| Стратегия | Какую запись удаляем | Эти записи чаще других используются повторно |
| First-In/First-Out (FIFO) | Самая старая | Новые |
| Last-In/First-Out (LIFO) | Самая недавняя | Старые |
| Least Recently Used (LRU) | Использовалась наиболее давно | Недавно прочитанные |
| Most Recently Used (MRU) | Использовалась последней | Прочитанные первыми |
| Least Frequently Used (LFU) | Использовалась наиболее редко | Использовались часто |
Погружаемся в идею LRU-кэширования
Кэш, реализованный посредством стратегии LRU, упорядочивает элементы в порядке их использования. Каждый раз, когда мы обращаемся к записи, алгоритм LRU перемещает ее в верхнюю часть кэша. Таким образом, алгоритм может быстро определить запись, которая дольше всех не использовалась, проверив конец списка.
На следующем рисунке показано представление кэша после того, как пользователь запросил статью из сети.

Статья сохраняется в последнем слоте кэша перед тем, как будет передана пользователю. На следующем рисунке показано, что происходит, когда пользователь запрашивает следующую статью.

Вторая статья занимает последний слот, перемещая первую статью вниз по списку.
Стратегия LRU предполагает: чем позже использовался объект, тем больше вероятность, что он понадобится в будущем. Алгоритм сохраняет такой объект в кэше в течение максимально длительного времени.
Заглядываем за кулисы кэша LRU
Один из способов реализовать кэш LRU в Python – использовать комбинациюдвусвязного спискаихеш-таблицы. Головной элемент двусвязного списка указывает на последнюю запрошенную запись, а хвостовой – на наиболее давно использовавшуюся.
На рисунке ниже показана возможная структура реализации кэша LRU.
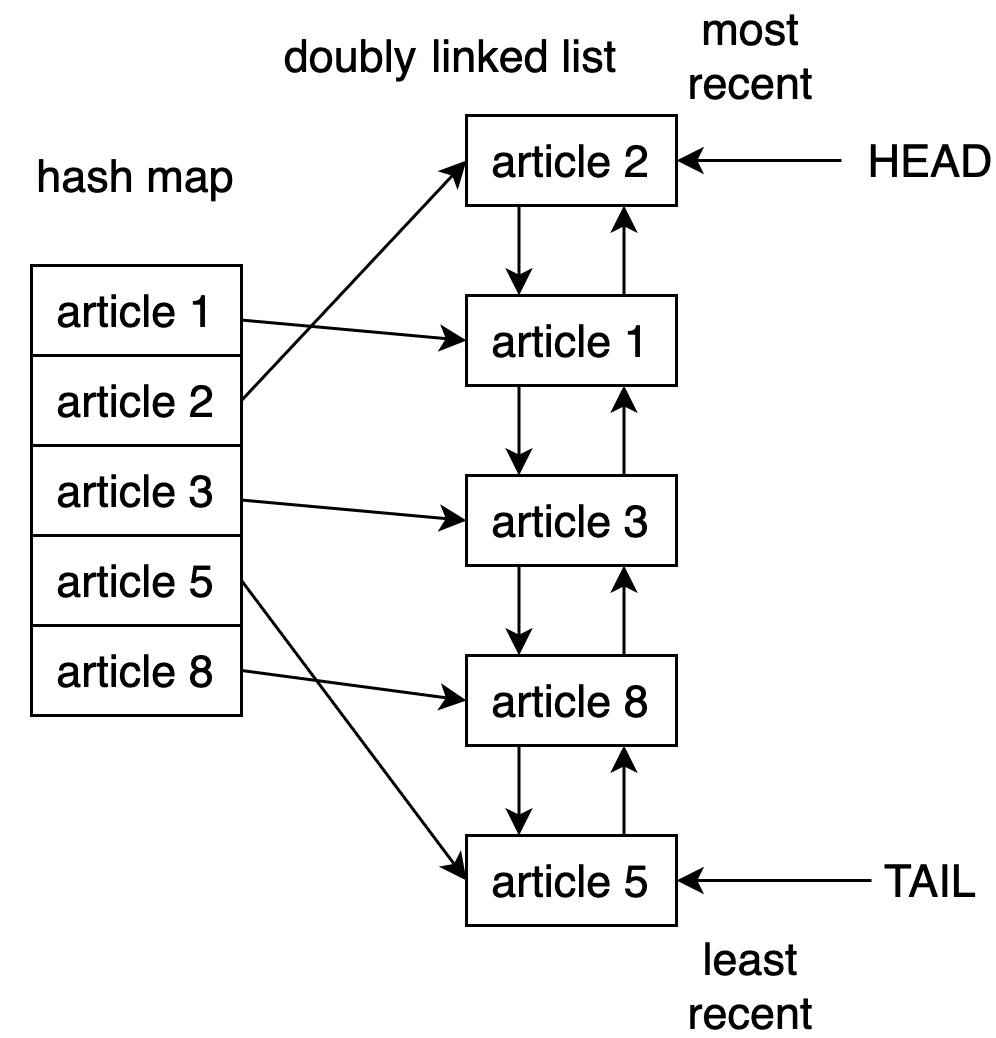
Используя хеш-таблицу, мы обеспечиваем доступ к каждому элементу в кэше, сопоставляя каждую запись с определенным местом в двусвязном списке. При этом доступ к недавно использовавшемуся элементу и обновление кэша – это операции, выполняемые за константное время (то есть свременной сложностьюалгоритма?(1).
Примечание
Примеры временной сложности различных функций Python рассматривались на proglib в статье «Сложность алгоритмов и операций на примере Python».
Начиная с версии 3.2, для реализации стратегии LRU Python включает декоратор@lru_cache.
Использование @lru_cache для реализации кэша LRU в Python
Декоратор@lru_cacheза кулисами использует словарь. Результат выполнения функции кэшируется под ключом, соответствующим вызову функции и предоставленным аргументам. То есть чтобы декоратор работал, аргументы должны быть хешируемыми.
Наглядное представление алгоритма: перепрыгиваем ступеньки
Представим, что мы хотим определить число способов, которыми можем достичь определенной ступеньки на лестнице. Сколько есть способов, например, добраться до четвертой ступеньки, если мы можем переступить-перепрыгнуть 1, 2, 3 (но не более) ступеньки? На рисунке ниже представлены соответствующие комбинации.
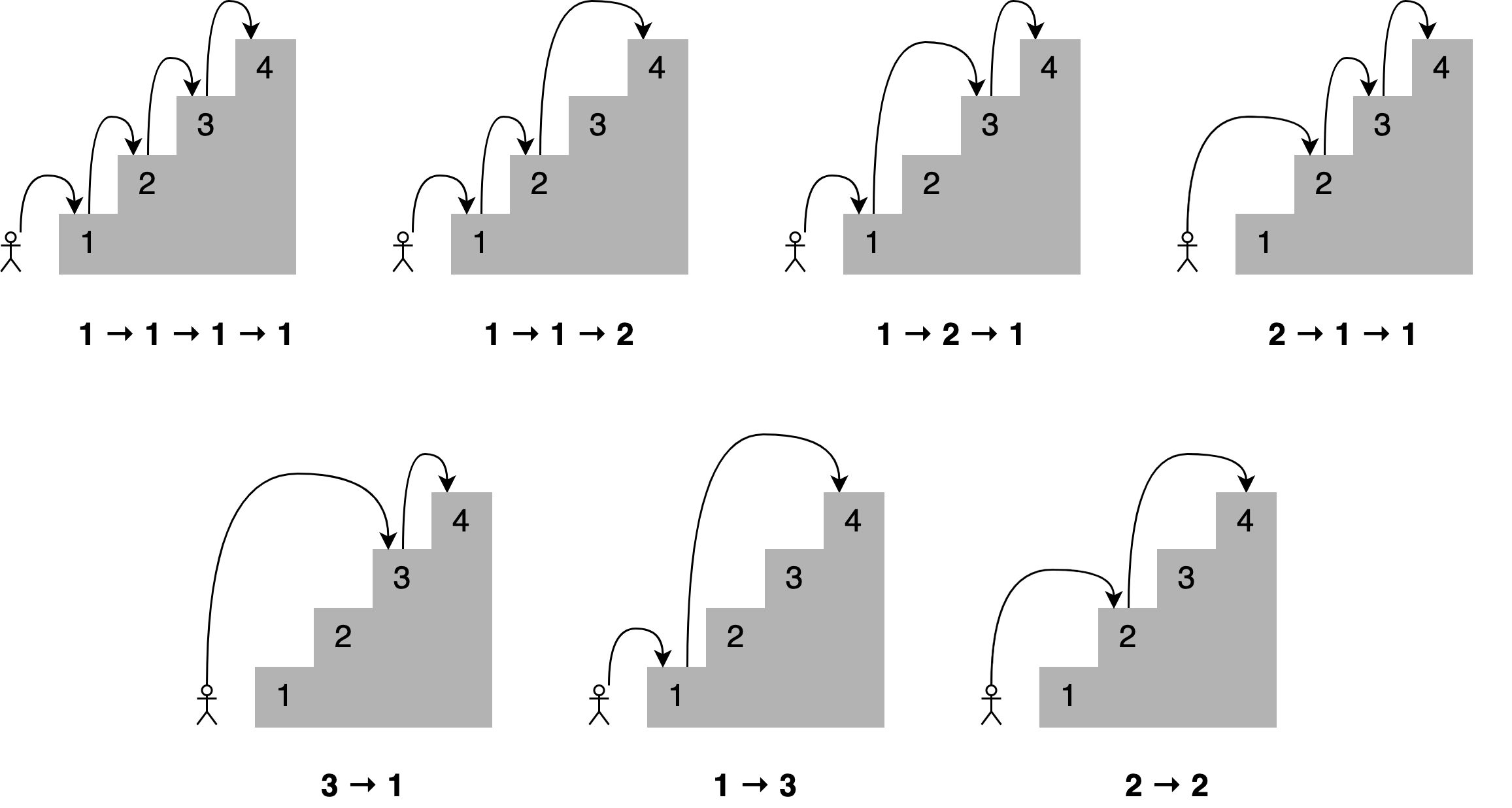
Под каждым из рисунков приведен путь с указанием числа ступенек, преодоленных за один прыжок. При этом количество способов достижения четвертой ступеньки равно общему числу способов, которыми можно добраться до третьей, второй и первой ступенек:
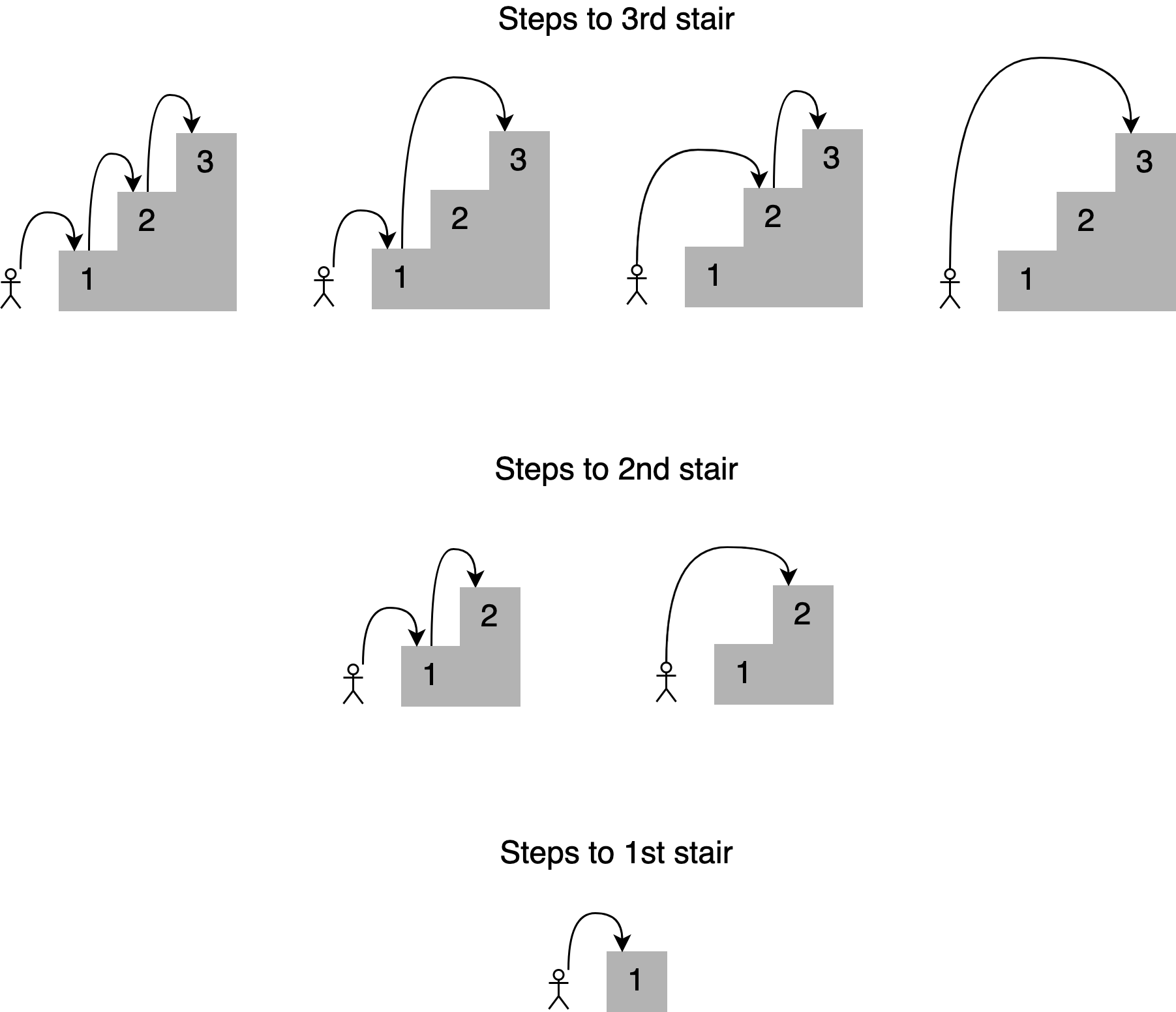
Получается, что решение задачи можно разложить на более мелкие подзадачи. Чтобы определить различные пути к четвертой ступеньке, мы можем сложить четыре способа достижения третьей ступеньки, два способа достижения второй ступеньки и единственный способ для первой. То есть можно использовать рекурсивный подход.
Опишем программно рекурсивное решение в точности, как мы его сейчас видим:
def steps_to(stair): if stair == 1: # До первой ступеньки можно добраться с пола # единственным образом return 1 elif stair == 2: # Второй ступеньки можно достингуть, # ступая по одной за раз или преодолев сразу две return 2 elif stair == 3: # Чтобы добраться до третьей ступеньки: # 1. Перепрыгнуть сразу до третьей # 2. Перепрыгнуть две, потом одну # 3. Перепрыгнуть одну потом две # 4. По одной за раз return 4 else: # Все промежуточные шаги это различные # варианты прыжков через 1, 2 или 3 ступеньки, # так что общее число вариантов - это сумма # таких комбинаций return ( steps_to(stair - 3) + steps_to(stair - 2) + steps_to(stair - 1) ) >>> print(steps_to(4)) 7 Код работает для 4 ступенек. Давайте проверим, как он подсчитает число вариантов для лестницы из 30 ступенек.
>>> steps_to(30) 53798080 Получилось свыше 53 млн. комбинаций. Однако когда мы искали решение для тридцатой ступеньки, сценарий мог длиться довольно долго.
Засекаем время выполнения программного кода
Измерим, как долго длится выполнение кода.
Примечание
О различных вариантах работы со временем в Python вы можете прочитать в публикации «Назад в будущее: практическое руководство по путешествию во времени с Python». Эта публикация также адаптирована в виде блокнота Jupyter.
Для этого мы можем использовать модуль Python timeit или соответствующую команду в блокноте Jupyter.
%%timeit >>> steps_to(30) 53798080 4.53 s ± 67.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) Количество секунд зависит от характеристик используемого компьютера. В моей системе расчет занял 3 секунды, что довольно медленно для всего тридцати ступенек. Это решение можно значительно улучшить c помощьюмемоизации.
Примечание
Один из примеров мемоизации рассматривался в статье«Python и динамическое программирование на примере задачи о рюкзаке».
Использование мемоизации для улучшения решения
Наша рекурсивная реализация решает проблему, разбивая ее на более мелкие шаги, которые дополняют друг друга. На следующем рисунке показано дерево для семи ступенек, в котором каждый узел представляет определенный вызовsteps_to():
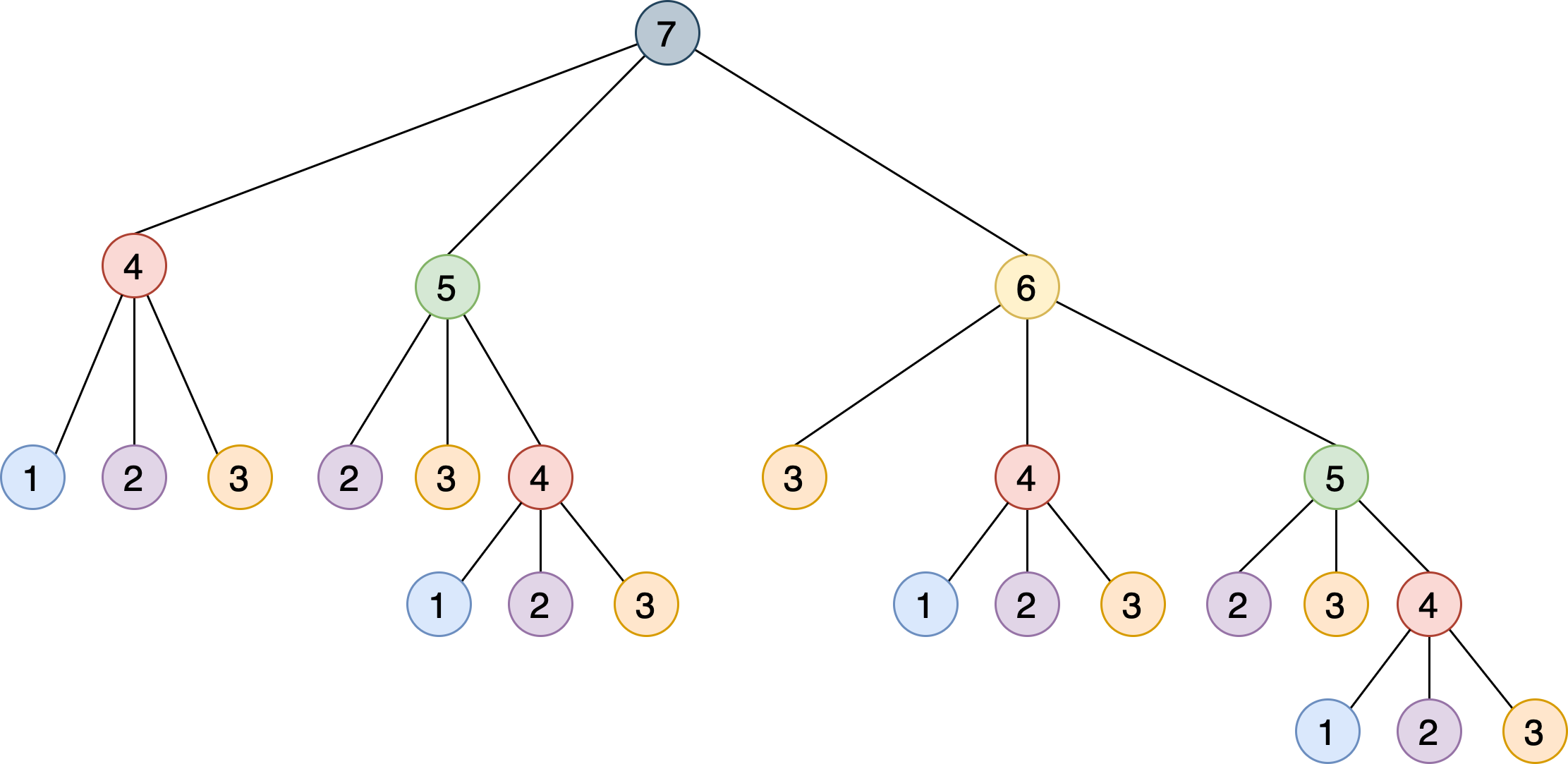
Можно заметить, что алгоритму приходится вызыватьsteps_to()с одним и тем же аргументом несколько раз. Например,steps_to(5)вычисляется два раза,steps_to(4)– четыре раза,steps_to(3)– семь раз и т. д. Вызов одной и той же функции несколько раз запускает вычисления, в которых нет необходимости – результат всегда один и тот же.
Чтобы решить эту проблему, мы можем использовать мемоизацию: мы сохраняем в памяти результат, полученный для одних и тех же входных значений и затем возвращаем при следующем аналогичном запросе. Прекрасная возможность применить декоратор@lru_cache!
Примечание
Если вы незнакомы с концепцией декораторов, но хотите глубже разобраться в вопросе, просто прочитайте материал«Всё, что нужно знать о декораторах Python» (она также адаптирована в форматеJupyterи Colab). Для наших задач достаточно знать, что это функции-обертки, которые позволяют модифицировать поведение функций и классов. Чтобы применить декоратор, достаточно объявить его перед определением функции.
Импортируем декоратор из модуляfunctoolsи применим к основной функции.
from functools import lru_cache @lru_cache() def steps_to(stair): if stair == 1: return 1 elif stair == 2: return 2 elif stair == 3: return 4 else: return (steps_to(stair - 3) + steps_to(stair - 2) + steps_to(stair - 1)) Примечание
В Python 3.8 и выше, если вы не указываете никаких параметров, можно использовать декоратор @lru_cache без скобок. В более ранних версиях необходимо добавить круглые скобки: @lru_cache().
%%timeit >>> steps_to(30) 53798080 82.7 ns ± 3.4 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each) От единиц секунд к десяткам наносекунд – потрясающее улучшение, обязанное тем, что за кулисами декоратор@lru_cacheсохраняет результаты вызоваsteps_to()для каждого уникального входного значения.
Другие возможности @lru_cache
Подключив декоратор@lru_cache, мы сохраняем каждый вызов и ответ в памяти для последующего доступа, если они потребуются снова. Но сколько таких комбинаций мы можем сохранить, пока не иссякнет память?
У декоратора@lru_cacheесть атрибутmaxsize, определяющий максимальное количество записей до того, как кэш начнет удалять старые элементы. По умолчаниюmaxsizeравен 128. Если мы присвоимmaxsizeзначениеNone, то кэш будет расти без всякого удаления записей. Это может стать проблемой, если мы храним в памяти слишком много различных вызовов.
Применим@lru_cacheс использованием атрибутаmaxsizeи добавим вызов методаcache_info():
@lru_cache(maxsize=16) def steps_to(stair): if stair == 1: return 1 elif stair == 2: return 2 elif stair == 3: return 4 else: return (steps_to(stair - 3) + steps_to(stair - 2) + steps_to(stair - 1)) >>> steps_to(30) 53798080 >>> steps_to.cache_info() CacheInfo(hits=52, misses=30, maxsize=16, currsize=16) Мы можем использовать информацию, возвращаемуюcache_info(), чтобы понять, как работает кэш, и настроить его, чтобы найти подходящий баланс между скоростью работы и объемом памяти:
hits=52– количество вызовов, которые@lru_cacheвернул непосредственно из памяти, поскольку они присутствовали в кэше;misses=30– количество вызовов, которые взяты не из памяти, а были вычислены (в случае нашей задачи это каждая новая ступень);maxsize=16– это размер кэша, который мы определили, передав его декоратору;currsize=16– текущий размер кэша, в этом случае кэш заполнен.
Добавление срока действия кэша
Перейдем от учебного примера к более реалистичному. Представьте, что мы хотим отслеживать появление на ресурсе Real Python новых статей, содержащих в заголовке словоpython– выводить название, скачивать статью и отображать ее объем (число символов).
Real Python предоставляетпротокол Atom, так что мы можем использовать библиотекуfeedparserдля анализа канала и библиотекуrequestsдля загрузки содержимого статьи, как мы это делали раньше.
import feedparser # pip install feedparser import requests import ssl import time if hasattr(ssl, "_create_unverified_context"): ssl._create_default_https_context = ssl._create_unverified_context def get_article_from_server(url): print("Получение статьи с сервера...") response = requests.get(url) return response.text def monitor(url): maxlen = 45 while True: try: print(" Проверям ленту...") feed = feedparser.parse(url) for entry in feed.entries[:5]: if "python" in entry.title.lower(): truncated_title = ( entry.title[:maxlen] + "..." if len(entry.title) > maxlen else entry.title ) print( "Совпадение:", truncated_title, len(get_article_from_server(entry.link)), ) time.sleep(5) except KeyboardInterrupt: break Скрипт будет работать непрерывно, пока мы не остановим его, нажав [Ctrl + C] в окне терминала (или не прервем выполнение в Jupyter-блокноте).
>>> monitor("https://realpython.com/atom.xml") Проверям ленту... Получение статьи с сервера... Совпадение: The Real Python Podcast – Episode #35: Securi... 28704 Получение статьи с сервера... Совпадение: PyPy: Faster Python With Minimal Effort 67387 Получение статьи с сервера... Совпадение: Handling Missing Keys With the Python default... 33224 Получение статьи с сервера... Совпадение: Use Sentiment Analysis With Python to Classif... 158401 Получение статьи с сервера... Совпадение: The Real Python Podcast – Episode #34: The Py... 29576 Проверям ленту... Получение статьи с сервера... Совпадение: The Real Python Podcast – Episode #35: Securi... 28704 Получение статьи с сервера... Совпадение: PyPy: Faster Python With Minimal Effort 67389 Получение статьи с сервера... Совпадение: Handling Missing Keys With the Python default... 33224 Получение статьи с сервера... Совпадение: Use Sentiment Analysis With Python to Classif... 158400 Получение статьи с сервера... Совпадение: The Real Python Podcast – Episode #34: The Py... 29576 Код загружает и анализирует xml-файл из RealPython. Далее цикл перебирает первые пять записей в списке. Если словоpythonявляется частью заголовка, код печатает заголовок и длину статьи. Затем код «засыпает» на 5 секунд, после чего вновь запускается мониторинг.
Каждый раз, когда сценарий загружает статью, в консоль выводится сообщение «Получение статьи с сервера...». Если мы позволим скрипту работать достаточно долго, мы увидим, что это сообщение появляется повторно даже при загрузке той же ссылки.
Мы можем использовать декоратор@lru_cache, однако содержание статьи со временем может измениться. При первой загрузке статьи декоратор сохранит ее содержимое и каждый раз будет возвращать одни и те же данные. Если сообщение обновлено, то сценарий мониторинга никогда об этом не узнает. Чтобы решить эту проблему, мы должны установить срок хранения записей в кэше.
Критерии исключения записей из кэша
Мы можем реализовать описанную идею в новом декораторе, который расширяет@lru_cache. Кэш должен возвращать результат на запрос только, если срок кэширования записи еще не истек – в обратном случае результат должен забираться с сервера. Вот возможная реализация нового декоратора:
from functools import lru_cache, wraps from datetime import datetime, timedelta def timed_lru_cache(seconds: int, maxsize: int = 128): def wrapper_cache(func): func = lru_cache(maxsize=maxsize)(func) # инструментирование декоратора двумя атрибутами, # представляющими время жизни кэша lifetime # и дату истечения срока его действия expiration func.lifetime = timedelta(seconds=seconds) func.expiration = datetime.utcnow() + func.lifetime @wraps(func) def wrapped_func(*args, **kwargs): if datetime.utcnow() >= func.expiration: func.cache_clear() func.expiration = datetime.utcnow() + func.lifetime return func(*args, **kwargs) return wrapped_func return wrapper_cache Декоратор@timed_lru_cacheреализует функциональность для оперирования временем жизни записей в кэше (в секундах) и максимальным размером кэша.
Код оборачивает функцию декоратором@lru_cache. Это позволяет нам использовать уже знакомую функциональность кэширования.
Перед доступом к записи в кэше декоратор проверяет, не наступила ли дата истечения срока действия. Если это так, декоратор очищает кэш и повторно вычисляет время жизни и срок действия. Время жизни распространяется на кэш в целом, а не на отдельные статьи.
Кэширование статей с помощью нового декоратора
Теперь мы можем использовать новый декоратор@timed_lru_cacheс функциейmonitor(), чтобы предотвратить скачивание с сервера содержимого статьи при каждом новом запросе. Собрав код в одном месте, получим следующий результат:
import feedparser import requests import ssl import time from functools import lru_cache, wraps from datetime import datetime, timedelta if hasattr(ssl, "_create_unverified_context"): ssl._create_default_https_context = ssl._create_unverified_context def timed_lru_cache(seconds: int, maxsize: int = 128): def wrapper_cache(func): func = lru_cache(maxsize=maxsize)(func) func.lifetime = timedelta(seconds=seconds) func.expiration = datetime.utcnow() + func.lifetime @wraps(func) def wrapped_func(*args, **kwargs): if datetime.utcnow() >= func.expiration: func.cache_clear() func.expiration = datetime.utcnow() + func.lifetime return func(*args, **kwargs) return wrapped_func return wrapper_cache @timed_lru_cache(60) def get_article_from_server(url): print("Получение статьи с сервера...") response = requests.get(url) return response.text def monitor(url): maxlen = 45 while True: try: print(" Проверяем ленту...") feed = feedparser.parse(url) for entry in feed.entries[:5]: if "python" in entry.title.lower(): truncated_title = ( entry.title[:maxlen] + "..." if len(entry.title) > maxlen else entry.title ) print( "Совпадение:", truncated_title, len(get_article_from_server(entry.link)), ) time.sleep(5) except KeyboardInterrupt: break >>> monitor("https://realpython.com/atom.xml") Получение статьи с сервера... Совпадение: The Real Python Podcast – Episode #35: Securi... 28704 Получение статьи с сервера... Совпадение: PyPy: Faster Python With Minimal Effort 67387 Получение статьи с сервера... Совпадение: Handling Missing Keys With the Python default... 33224 Получение статьи с сервера... Совпадение: Use Sentiment Analysis With Python to Classif... 158400 Получение статьи с сервера... Совпадение: The Real Python Podcast – Episode #34: The Py... 29576 Проверяем ленту... Совпадение: The Real Python Podcast – Episode #35: Securi... 28704 Совпадение: PyPy: Faster Python With Minimal Effort 67387 Совпадение: Handling Missing Keys With the Python default... 33224 Совпадение: Use Sentiment Analysis With Python to Classif... 158400 Совпадение: The Real Python Podcast – Episode #34: The Py... 29576 Обратите внимание, как код печатает сообщение «Получение статьи с сервера ...» при первом доступе к соответствующим статьям. После этого, в зависимости от скорости cети, сценарий будет извлекать статьи из кэша несколько раз, прежде чем снова обратится к серверу.
В приведенном примере скрипт пытается получить доступ к статьям каждые 5 секунд, а срок действия кэша истекает раз в минуту.
Заключение
Кэширование – важный метод оптимизации, повышающий производительность любой программной системы. Понимание того, как работает кэширование, является фундаментальным шагом на пути к его эффективному включению в программный код.
В этом уроке мы кратко рассмотрели:
- какие бывают стратегии кэширования;
- как работает LRU-кэширование в Python;
- как использовать декоратор
@lru_cache; - как рекурсивный подход в сочетании с кэшированием помогает достаточно быстро решить задачу.
Следующим шагом к реализации различных стратегий кэширования в ваших приложениях может стать библиотекаcachetools, предоставляющая особые типы данных и декораторы, охватывающие самые популярные стратегии кэширования.
Источники
Телеграм: t.me/ainewsline
Источник: proglib.io