В Google Brain обучили Transformer для задач компьютерного зрения
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2020-10-24 16:52

В Google Brain обучили Transformer-модель для задачи распознавания изображений. На датасетах ImageNet, CIFAR-100 и VTAB ViT (Vision Transformer) выдает результаты, сравнимые с state-of-the-art сверточными архитектурами. При этом ViT требует меньшего количества вычислительных ресурсов для обучения.
Transformer для компьютерного зрения
Для задач обработки естественного языка Transformer-архитектуры являются сейчас state-of-the-art. Однако применение таких архитектур для задач компьютерного зрения малоизучено. В компьютерном зрении механизм внимания применяется либо совместно со сверточными сетями, либо заменяет часть компонентов сверточной сети. При этом чаще, в целом, структура сети не меняется и остается сверточная.
Исследователи показали, что использование стандартной Transformer-модели для последовательностей изображений позволяет достичь сравнимых с state-of-the-art результатов на задачах классификации изображений.
Подробнее про архитектуру ViT
Дизайн модели основывается на стандартной архитектуре Transformer (Vaswani et al., 2017). Изображение делится на патчи определенного размера. Каждый патч эмбеддится друг за другом. Затем добавляется эмбеддинг положения (position embedding). Получившаяся последовательность векторов поступает на вход Transformer энкодеру. Чтобы модель выучивалась классифицировать изображения, к последовательности добавляется дополнительный токен классификации.

Тестирование работы нейросети
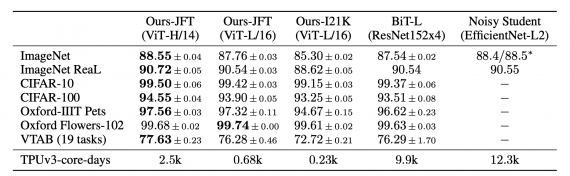
Исследователи сравнили Transformer с state-of-the-art сверточными архитектурами на задаче классификации изображений. Vision Transformer модели, которые предобучали на датасете JFT-300M, обходит модели с ResNet на всех датасетах. При этом предложенные модели требует меньше ресурсов для обучения.
Телеграм: t.me/ainewsline
Источник: neurohive.io