

Две революции в обработке естественного языка
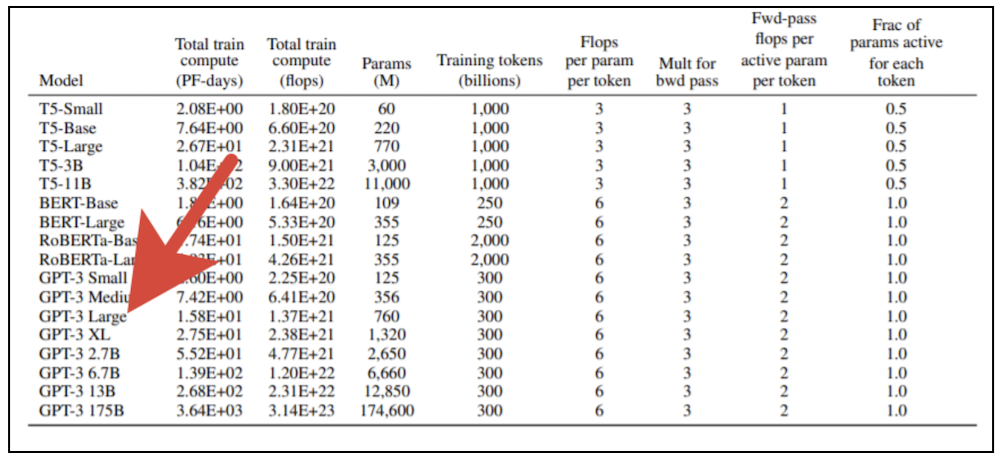
Первая революция в NLP была связана с успехами моделей, основанных на векторных представлениях семантики языка, получаемых при помощи методов обучения без учителя (Unsupervised learning). Расцвет этих моделей начался с публикации результатов Томаша Миколова (Tom?? Mikolov), аспиранта Йошуа Бенджио (Yoshua Bengio) (одного из «отцов-основателей» современного глубокого обучения, лауреата Премии Тьюринга), и появления популярного инструмента word2vec. Вторая же революция началась с развития механизмов внимания в рекуррентных нейронных сетях, вылившаяся в понимание того, что механизм внимания самодостаточен и вполне может быть использован и без самой рекуррентной сети. Появившаяся в результате нейросетевая модель получила название «трансформер» [transformer]. Она была представлена научному сообществу в 2017 году в статье с программным названием «Внимание — это всё, что вам нужно» [Attention Is All You Need], написанной группой исследователей из Google Brain и Google Research. Быстрое развитие сетей, основанных на трансформерах, привело к появлению гигантских языковых моделей, подобных Generative Pre-trained Transformer 3 (GPT-3) от OpenAI, способных эффективно решать множество задач из области NLP. Для обучения гигантских трансформерных моделей нужны значительные вычислительные ресурсы. У вас не получится просто взять современную видеокарту и обучить такую модель на своём домашнем компьютере. В оригинальной публикации OpenAI представлено 8 вариантов модели, и если взять самую маленькую из них (GPT-3 Small) со 125 миллионами параметров и попытаться обучить её при помощи профессиональной видеокарты NVidia V100, оснащённой мощными тензорными ядрами, то на это уйдёт примерно полгода. Если же взять самый большой вариант модели со 175 млрд параметров, то результата придётся дожидаться почти 500 лет. Стоимость обучения самого большого варианта модели по тарифам облачных сервисов, предоставляющих современные вычислительные устройства в аренду, переваливает за миллиард рублей (и это ещё при условии линейного масштабирования производительности с увеличением числа задействованных процессоров, что в принципе недостижимо).
Да здравствуют суперкомпьютеры!
Понятно, что подобные эксперименты доступны только компаниям, обладающим значительными вычислительными ресурсами. Именно для решения подобных задач в 2019 году Сбер ввёл в эксплуатацию суперкомпьютер «Кристофари», занявший первое место по производительности в числе имеющихся в нашей стране суперкомпьютеров. 75 вычислительных узлов DGX-2 (в каждом по 16 карт NVidia V100), связанных сверхбыстрой шиной на базе технологии Infiniband, позволяют обучить GPT-3 Small всего за несколько часов. Однако и для такой машины задача обучения более крупных вариантов модели не является тривиальной. Во-первых, часть машины занята обучением других моделей, предназначенных для решения задач в области компьютерного зрения, распознавания и синтеза речи и множестве других областей, интересующих различные компании из экосистемы Сбера. Во-вторых, сам процесс обучения, использующий одновременно множество вычислительных узлов в ситуации, когда веса модели не помещаются в памяти одной карты, является весьма нестандартным. В общем, мы оказались в ситуации, когда для наших целей не годился привычный многим torch.distributed. Вариантов у нас было не так уж и много, в итоге мы обратились к «родной» для NVidia реализации Megatron-LM и новому детищу Microsoft — DeepSpeed, что потребовало создания на «Кристофари» кастомных докерных контейнеров, с чем нам оперативно помогли коллеги из SberCloud. DeepSpeed, в первую очередь, дал нам удобные инструменты для model parallel тренировки, то есть разнесения одной модели на несколько GPU и для шардирования оптимизатора между GPU. Это позволяет использовать более крупные батчи, а также без горы дополнительного кода обучать модели с более чем 1,5 миллиардами весов. Удивительным образом технологии за последние полвека в своём развитии описали очередной виток спирали — похоже, эпоха мейнфреймов (мощных компьютеров с терминальным доступом) возвращается. Мы уже привыкли, что основным инструментов разработки является персональный компьютер, выделенный в монопольное пользование разработчику. В конце 1960-х — начале 1970-х годов час работы мейнфрейма стоил примерно столько же, сколько составляла заработная плата оператора ЭВМ за целый месяц! Казалось, что эти времена ушли навсегда и «железо» стало навсегда дешевле рабочего времени. Однако, похоже, «железо» совершило впечатляющий «камбэк» [comeback]. Будни современного специалиста в области машинного обучения вновь напоминают будни Саши Привалова из повести братьев Стругацких «Понедельник начинается в субботу», с той лишь разницей, что место «Алдана» в нашем случае занимает «Кристофари», а роль магии и чародейства выполняют методы глубокого обучения [deep learning].
Из опыта SberDevices
Нам много раз приходилось в прошлом учить другие модели на основе трансформеров — это и различные наследники BERT'а, и модели «кодировщик (энкодер) — декодер» [encoder — decoder], подобные T5 от Google. Виртуальные ассистенты, созданные SberDevices для различных поверхностей, начиная новейшими SberBox и SberPortal и заканчивая привычным всем приложением Сбербанк Онлайн, используют в своей работе несколько подобных моделей для решения различных задач в ходе общения с пользователем. Например, виртуальный ассистент Джой использует в режиме «болталки» модель GPT-2 Medium, обученную на большом корпусе русской литературы, «доученную» на специальном диалоговом датасете и снабжённую особым механизмом ранжирования, предназначенным для выбора наиболее интересных ответов. Такие модели способны вести с пользователем беседу, не выбирая реплики из заранее заготовленной библиотеки ответов, а изготавливая свои фразы «на лету», что делает общение с ними более разнообразным и занимательным.
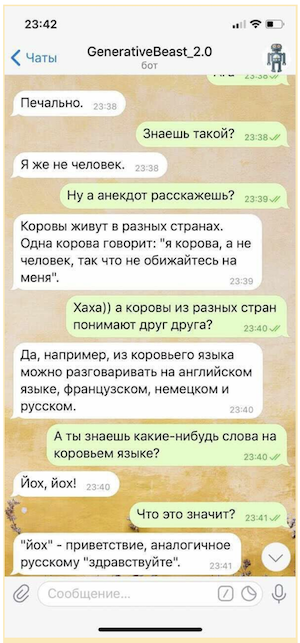

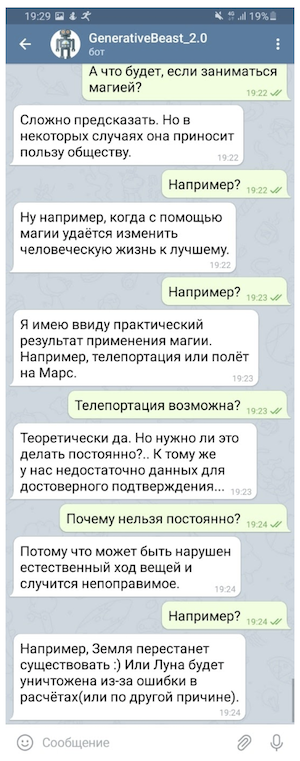
Конкурс «AI 4 Humanities: ruGPT-3»
В этом году в рамках AI Journey команда Sberbank.AI организовала конкурс «AI 4 Humanities: ruGPT-3». В рамках общего зачета участникам предлагается представить прототипы решений для любой бизнес- или социальной задачи, созданных с помощью предобученной модели ruGPT-3. Участникам специальной номинации «AIJ Junior» предлагается на базе ruGPT-3 создать решение по генерации осмысленного эссе по четырем гуманитарным предметам (русский язык, история, литература, обществознание) уровня 11 класса (ЕГЭ) по заданной теме/тексту задания.
Специально для этих соревнований мы обучили три версии модели GPT-3: 1) GPT-3 Medium, 2) GPT-3 Large с чередованием sparse и dense-блоков трансформера, 3) наиболее «мощную» GPT-3 Large, составленную из одних только dense-блоков. Обучающие датасеты и токенизаторы у всех моделей идентичны — использовался BBPE-токенизатор и наш кастомный датасет Large1 объёмом 600 Гб (его состав приведён в тексте выше).
Все три модели доступны для скачивания в репозитории соревнований.



Как модели, подобные GPT-3, изменят наш мир?
Важно понимать, что модели типа GPT-1/2/3, на самом деле, решают ровно одну задачу — они пытаются предсказать следующий токен (обычно слово или его часть) в последовательности по предшествующим. Такой подход позволяет использовать для обучения «неразмеченные» данные, то есть обойтись без привлечения «учителя», а с другой стороны позволяет решать довольно широкий спектр задач из области NLP. Ведь в тексте диалога, например, реплика-ответ является продолжением истории общения, в художественном произведении — текст каждого абзаца продолжает предшествующий текст, а в сессии вопросов и ответов текст ответа следует за текстом вопроса. Модели большой ёмкости в результате могут решать многие такие задачи без специального дообучения — им достаточно тех примеров, которые укладываются в «контекст модели», который у GPT-3 довольно внушительный — целых 2048 токенов.
GPT-3 способна не только генерировать тексты (в том числе стихи, шутки и литературные пародии), но и исправлять грамматические ошибки, вести диалоги и даже (ВНЕЗАПНО!) писать более-менее осмысленный программный код. Множество интересных применений GPT-3 можно найти на сайте независимого исследователя Гверна Бренуэна (Gwern Branwen). Бренуэн, развивая идею, высказанную в шуточном твите Андрея Карпатого (Andrej Karpathy), задаётся интересным вопросом: не являемся ли мы свидетелями появления новой парадигмы программирования? Вот текст исходного твита Карпатого:
«Мне нравится идея Программного обеспечения 3.0. Программирование переходит от подготовки датасетов к подготовке запросов, позволяющих системе метаобучения «понять» суть задачи, которую она должна выполнить. ЛОЛ» [Love the idea for Software 3.0. Programming moving from curating datasets to curating prompts to make the meta learner «get» the task it's supposed to be doing. LOL].
Развивая идею Карпатого, Бренуэн пишет:
«Нейронная сеть GPT-3 настолько огромна с точки зрения мощности и набора [использованных для обучения] данных, что демонстрирует качественно иное поведение: вы не применяете её к фиксированному набору задач, представленных в обучающем датасете, что требует повторного обучения модели на дополнительных данных, если вы хотите решить новую задачу (именно так надо переучивать GPT-2); вместо этого вы взаимодействуете с моделью, выражая любую задачу в виде описаний, запросов и примеров на естественном языке, подстраивая текст затравки [prompt], подаваемой на вход модели, до тех пор, пока она не «поймёт» и не научится на мета-уровне решать новую задачу, основываясь на высокоуровневых абстракциях, которые она выучила во время предобучения. Это принципиально новый способ использования модели глубокого обучения, и его лучше рассматривать как новый вид программирования, где «затравка» теперь является «программой», которая программирует GPT-3 для выполнения новых задач. «Затравочное программирование» похоже не столько на обычное программирование, сколько на попытку научить суперинтеллектуального кота освоить новый трюк: вы можете попросить его выполнить трюк, и иногда он выполняет его идеально, что делает ещё более неприятной ситуацию, когда в ответ на запрос он сворачивается, чтобы вылизать свою задницу, при этом вы будете понимать, что проблема не в том, что он не может, а в том, что он не хочет».
Поскольку наша модель в процессе обучения «видела» github и StackOverflow, она вполне способна писать код (иногда не лишённый весьма глубокого смысла):
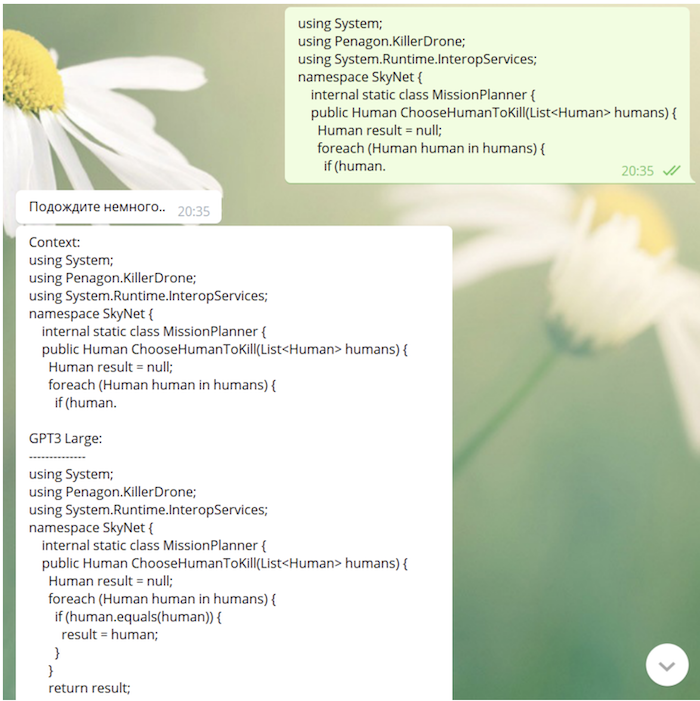
Что дальше
В этом году мы продолжим работы над гигантскими трансформерными моделями. Дальнейшие планы связаны с дальнейшим расширением и очисткой датасетов (в них, в частности, войдут снапшоты сервиса препринтов научных публикаций arxiv.org и библиотеки научных исследований PubMed Central, специализированные диалоговые датасеты и датасеты по символьной логике), увеличением размера обучаемых моделей, а также использованием улучшенного токенизатора.
Мы надеемся, что публикация обученных моделей подстегнёт работу российских исследователей и разработчиков, нуждающихся в сверхмощных языковых моделях, ведь на базе ruGPT-3 можно создавать собственные оригинальные продукты, решать различные научные и деловые задачи. Пробуйте использовать наши модели, экспериментировать с ними и обязательно делитесь со всеми полученными результатами. Научный прогресс делает наш мир совершеннее и интереснее, давайте улучшать мир вместе!